目录
- 1.MADDPG算法简介
- 2.实验环境搭建
- 3.实验代码
-
- [3.1 maddpg.py](#3.1 maddpg.py)
- [3.2 distribution.py](#3.2 distribution.py)
- [3.3 args_config.py](#3.3 args_config.py)
- [3.4 train_maddpg.py](#3.4 train_maddpg.py)
- 4.实验结果
- 5.参考文章
1.MADDPG算法简介
MADDPG是多智能体强化学习算法中的经典算法,它使用CTDE框架。
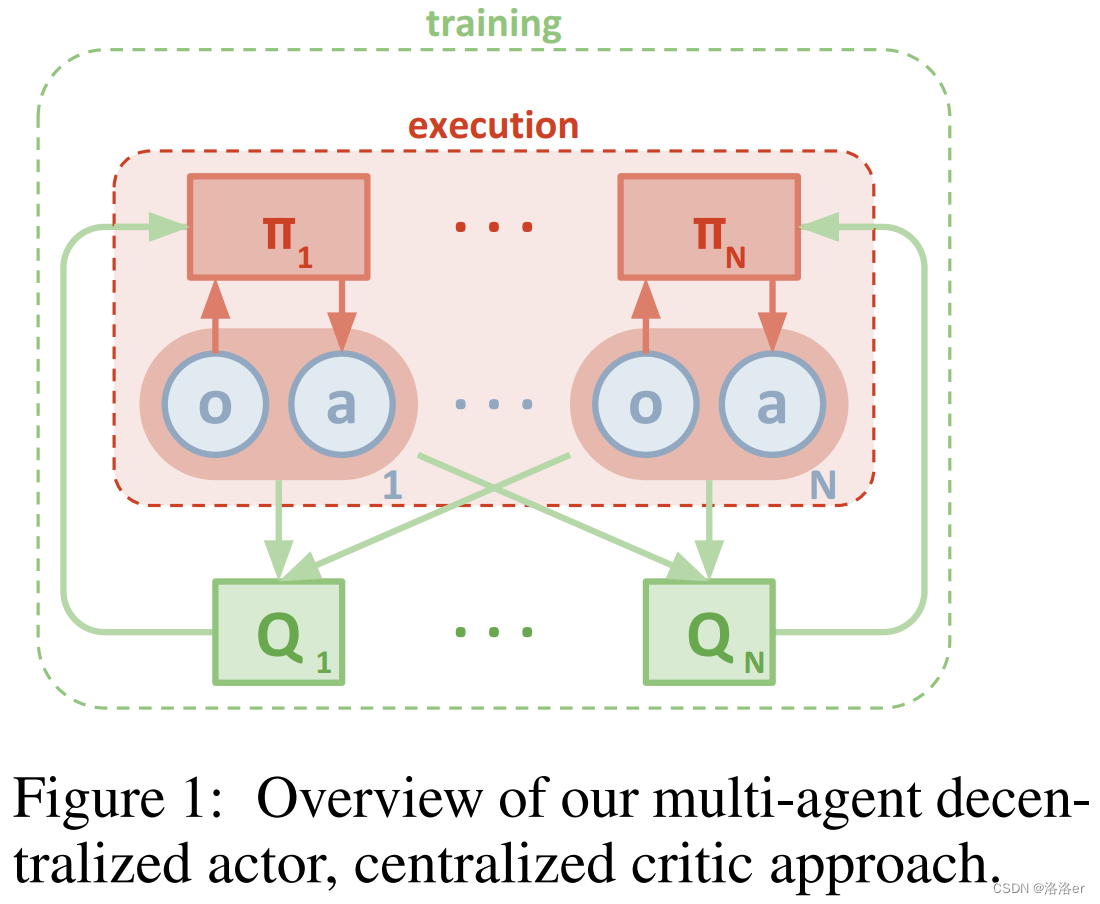
本文从代码实现的角度,解释算法中重要的代码为什么这样写,或许能对MADDPG算法有更深的理解,而不只是停留在看懂论文做实验却无从下手。
但是源码都是tensorflow-v1版本的,理解和调试都比较困难,并且不利于后续作为其他强化学习算法实现的基础,所以我在文章中使用tensorflow-v2版本来实现MADDPG算法,整体而言比源码tensorlfow-v1更好理解。
2.实验环境搭建
Windows11+conda环境
python==3.7tensorflow-gpu==2.5.0tensorflow_tensorflow_probability==1.14.0gym==0.10.0
仿真游戏环境 multiagent-particle-envs
仿真游戏环境github链接,下载到工程文件夹内,在上述建立的conda环境中,cd multiagent-particle-envs使用pip install -e .安装multiagent-particle-envs。
完整的代码见: white-bubbleee/MADDPG-tf2: 使用tensorflow2实现多智能体强化学习算法MADDPG
3.实验代码
代码分为四个文件:
- maddpg.py 主要算法文件
- distribution.py 其他接口函数定义文件
- args_config.py 参数文件
- train_maddpg.py 训练用的文件
如果只需要运行代码做实验的话,完整的代码链接附在文章的4.实验结果部分,仅供参考。
3.1 maddpg.py
1.导入一些要使用的包以及函数
python
# -*- coding: utf-8 -*-
import tensorflow as tf
from tensorflow.keras.layers import Dense, Input, Concatenate
from tensorflow.keras.models import Model
from base.replaybuffer import ReplayBuffer
from base.trainer import ACAgent, Trainer
import numpy as np
import gym
from ..common.distribution import gen_action_for_discrete, gen_action_for_continuous
from utils.logger import set_logger
logger = set_logger(__name__, output_file="maddpg.log")
DATA_TYPE = tf.float64 # 定义所有tensorflow变量的类型是tf.float64,保证变量类型一致性,否则会出错2.MADDPG中单个智能体的结构基类
(1)单个智能体的有关参数
- 动作维度
act_dim - 状态(观测维度)
obs_dim - 当前智能体在maddpg所有智能体内的索引
agent_index
超参数部分:
- 智能体网络隐层的大小
num_units - 是否要使用局部q网络,即是否是ddpg
local_q_func
全局参数部分:
- 参数包
args,在train_maddpg.py文件中也是args_list - 全部agent的动作维度参数
action_dim - 全部agent的观测维度参数
obs_dim - 学习率
args.lr
参照openAI,以上这些超参数及其其他有关参数的取值,全部定义在args_config.py 参数文件
(2)单个智能体的有关网络的结构
单个智能体各有四个网络:actor critic target_actor target_critic

actor 的网络结构
根据maddpg算法伪代码展示,仅看圆圈1 部分, μ θ i \mu_{\theta_{i}} μθi代表智能体i的actor网络;
显然该actor输入为当前智能体的观测值 o i o_{i} oi,输出为当前智能体的动作值 a i a_{i} ai;
因此,该网络的输入维度是(batch_size, obs_dim),输出维度是(batch_size, act_dim);
或者也可以是(1,obs_dim)===>(1, act_dim);
所以在这里,参照openai的maddpg的源代码,定义actor网络的结构为如下:

最后,定义一个actor创建函数如下:
python
def build_actor(self, action_bound=None):
obs_input = Input(shape=(self.obs_dim,))
out = Dense(self.num_units, activation='relu')(obs_input)
out = Dense(self.num_units, activation='relu')(out)
out = Dense(self.act_dim, activation=None)(out)
out = tf.cast(out, DATA_TYPE)
actor = Model(inputs=obs_input, outputs=out)
return actorcritic的网络结构
根据maddpg算法伪代码展示,仅看圆圈2 部分, Q i μ Q_{i}^{\mu} Qiμ代表智能体i的critic网络;
显然该critic输入为当前智能体的状态值 x i x_{i} xi和所有智能体的联合动作值 a 1 , a 2 , ... , a N a_1,a_2, \dots, a_{N} a1,a2,...,aN,输出为当前所有智能体critic网络参数下的 q i q_{i} qi;
论文中关于 x x x的解释如下:


可见,源码中critic的输入形式(maddpg算法)是(batch_size, 所有智能体的obs+所有智能体的act);
因此,我在critic网络中,定义其输入维度是(batch_size, sum(obs_dim)+sum(act_dim)),输出维度是(batch_size, 1)。

最后,定义一个critic创建函数如下:
python
def build_critic(self):
# ddpg or maddpg
if self.local_q_func: # ddpg,critic的输入是自己的(obs, act)
obs_input = Input(shape=(self.obs_dim,))
act_input = Input(shape=(self.act_dim,))
concatenated = Concatenate(axis=1)([obs_input, act_input])
if not self.local_q_func: # maddpg
obs_input_list = [Input(shape=(self.obs_dim,)) for _ in range(self.nums_agents)]
act_input_list = [Input(shape=(self.act_dim,)) for _ in range(self.nums_agents)]
concatenated_obs = Concatenate(axis=1)(obs_input_list)
concatenated_act = Concatenate(axis=1)(act_input_list)
concatenated = Concatenate(axis=1)([concatenated_obs, concatenated_act])
out = Dense(self.num_units, activation='relu')(concatenated)
out = Dense(self.num_units, activation='relu')(out)
out = Dense(1, activation=None)(out)
out = tf.cast(out, DATA_TYPE)
critic = Model(inputs=obs_input_list + act_input_list if not self.local_q_func else [obs_input, act_input],
outputs=out)
return critictarget_actor和target_critic 和上面两个的结构分别一模一样。
(3)优化器部分
actor网络:self.actor_optimizer = tf.keras.optimizers.Adam(args.lr),学习率args.lr
critic网络:self.critic_optimizer = tf.keras.optimizers.Adam(args.lr), 学习率args.lr
target_actor和target_critic这两个网络的参数不需要被优化,它们的参数分别由actor网络和critic网络的参数来更新得到,因此没有对应的优化器。
(4)MADDPGAgent完整代码
python
class MADDPGAgent(ACAgent):
def __init__(self, name, action_dim, obs_dim, agent_index, args, local_q_func=False):
super().__init__(name, action_dim, obs_dim, agent_index, args)
self.name = name + "_agent_" + str(agent_index) # 当前智能体的索引,在maddpg中有多个agent
self.act_dim = action_dim[agent_index] # 当前智能体的动作维度
self.obs_dim = obs_dim[agent_index][0] # 当前智能体的观测维度
self.act_total = sum(action_dim)
self.obs_total = sum([obs_dim[i][0] for i in range(len(obs_dim))])
self.num_units = args.num_units
self.local_q_func = local_q_func
self.nums_agents = len(action_dim)
self.actor = self.build_actor()
self.critic = self.build_critic()
self.target_actor = self.build_actor()
self.target_critic = self.build_critic()
self.actor_optimizer = tf.keras.optimizers.Adam(args.lr)
self.critic_optimizer = tf.keras.optimizers.Adam(args.lr)
def build_actor(self, action_bound=None):
obs_input = Input(shape=(self.obs_dim,))
out = Dense(self.num_units, activation='relu')(obs_input)
out = Dense(self.num_units, activation='relu')(out)
out = Dense(self.act_dim, activation=None)(out)
out = tf.cast(out, DATA_TYPE)
actor = Model(inputs=obs_input, outputs=out)
return actor
def build_critic(self):
# ddpg or maddpg
if self.local_q_func: # ddpg
obs_input = Input(shape=(self.obs_dim,))
act_input = Input(shape=(self.act_dim,))
concatenated = Concatenate(axis=1)([obs_input, act_input])
if not self.local_q_func: # maddpg
obs_input_list = [Input(shape=(self.obs_dim,)) for _ in range(self.nums_agents)]
act_input_list = [Input(shape=(self.act_dim,)) for _ in range(self.nums_agents)]
concatenated_obs = Concatenate(axis=1)(obs_input_list)
concatenated_act = Concatenate(axis=1)(act_input_list)
concatenated = Concatenate(axis=1)([concatenated_obs, concatenated_act])
out = Dense(self.num_units, activation='relu')(concatenated)
out = Dense(self.num_units, activation='relu')(out)
out = Dense(1, activation=None)(out)
out = tf.cast(out, DATA_TYPE)
critic = Model(inputs=obs_input_list + act_input_list if not self.local_q_func else [obs_input, act_input],
outputs=out)
return critic
@tf.function(input_signature=[tf.TensorSpec(shape=[None, None], dtype=DATA_TYPE)])
def agent_action(self, obs):
return self.actor(obs)
@tf.function
def agent_critic(self, obs_act):
return self.critic(obs_act)
@tf.function(input_signature=[tf.TensorSpec(shape=[None, None], dtype=DATA_TYPE)])
def agent_target_action(self, obs):
return self.target_actor(obs)
@tf.function
def agent_target_critic(self, obs_act):
return self.target_critic(obs_act)
def save_model(self, path):
actor_path = f"{path}_{self.name}_actor.h5"
critic_path = f"{path}_{self.name}_critic.h5"
self.actor.save(actor_path)
self.critic.save(critic_path)
print(f"Actor model saved at {actor_path}")
print(f"Critic model saved at {critic_path}")
def load_model(self, path):
actor_path = f"{path}_{self.name}_actor.h5"
critic_path = f"{path}_{self.name}_critic.h5"
self.actor = tf.keras.models.load_model(actor_path)
self.critic = tf.keras.models.load_model(critic_path)
print(f"Actor model loaded from {actor_path}")
print(f"Critic model loaded from {critic_path}")3.MADDPG中单个智能体的训练基类
(0)replaybuffer

replaybuffer存储的是四元组(联合state, 联合action, reward, 联合next_state)
代码部分的小细节:
每个智能体都有自己的replaybuffer,但是每次训练,所有智能体从replaybuffer取出来的的数据,应该都是一个索引,所以使用self.replay_sample_index记录所有智能体的raplaybuffer索引序列。
实际在代码中存入每个智能体的replaybuffer是(state, action, reward, next_state),故取数据函数会对所有智能体取出的state和action,分别做拼接。
最后,存和取的代码如下:
python
def experience(self, state, action, reward, next_state, done, terminal):
self.replay_buffer.add(state, action, reward, next_state, float(done))
def sample_batch_for_pretrain(self, trainers):
"""
trainers是所有智能体trainer实例列表,因为这里需要拼接其他智能体的replaybuffer存入的act和obs
"""
if self.replay_sample_index is None:
self.replay_sample_index = self.replay_buffer.make_index(self.batch_size)
obs_n, action_n, next_obs_n = [], [], []
reward_i, done_i = None, None
for i, trainer in enumerate(trainers):
obs, act, rew, next_obs, done = trainer.replay_buffer.sample_index(self.replay_sample_index)
obs_n.append(obs)
action_n.append(act)
next_obs_n.append(next_obs)
if self.agent_index == i:
done_i = done
reward_i = rew
return obs_n, action_n, reward_i[:, np.newaxis], next_obs_n, done_i[:, np.newaxis](1)actor网络参数的更新

红框框出部分,是有关智能体i的critic网络的更新
- 从replaybuffer中取出
batch_size大小的四元组(state, action, reward, next_state) - 对
state,利用智能体i的actor求出action_hat - 将
(state,action_hat)输入到智能体i的critic网络,计算得到q - 使用critic的优化器,对损失函数q最大化,即对-q最小化,来优化智能体i的
critic网络的参数
以下是OPENAI源码关于actor网络训练部分的代码

最后,actor网络的训练代码如下:
python
# ========================= train actor ===========================
with tf.GradientTape() as tape:
_action_n = []
for i, trainer in enumerate(trainers):
_action = trainer.get_action(obs_n[i])
_action_n.append(_action)
q_input = obs_n + _action_n
if self.local_q_func:
q_input = [obs_n[self.agent_index], _action_n[self.agent_index]]
p_reg = tf.reduce_mean(tf.square(_action_n[self.agent_index])) # regularization
actor_loss = -tf.reduce_mean(self.agent.agent_critic(q_input)) + p_reg * 1e-3
actor_grads = tape.gradient(actor_loss, self.agent.actor.trainable_variables)
self.agent.actor_optimizer.apply_gradients(zip(actor_grads, self.agent.actor.trainable_variables))(2)critic网络参数的更新

红框框出部分,是有关智能体i的critic网络的更新
- 首先从replaybuffer中取出
batch_size大小的四元组(state, action, reward, next_state) - 然后,计算对于state和action的y_target,即对next_state,利用智能体i的
target_actor求出target_action,将(next_state,target_action)输入到智能体i的target_critic网络,计算得到y_target,即 y ^ \hat{y} y^,图中是 y j y^{j} yj, j j j代表batchsize中的第j个元组数据 - 将
(state,action)输入到智能体i的critic网络,计算得到y - 智能体i的
critic网络损失函数定义为: ( y ^ − y ) 的均值 (\hat{y}-y)的均值 (y^−y)的均值 - 使用critic的优化器,对损失函数最小化,来优化critic网络的参数
最后,critic网络的训练代码如下:
python
# ======================== train critic ==========================
with tf.GradientTape() as tape:
target_actions = [trainer.get_target_action(next_obs_n[i]) for i, trainer in enumerate(trainers)]
# ============= target ===========
target_q_input = next_obs_n + target_actions # global info
if self.local_q_func:
target_q_input = [next_obs_n[self.agent_index], target_actions[self.agent_index]]
target_q = self.agent.agent_target_critic(target_q_input)
# ============= current =========== q_input = obs_n + action_n # global info
if self.local_q_func: # local info
q_input = [obs_n[self.agent_index], action_n[self.agent_index]]
q = self.agent.agent_critic(q_input)
critic_loss = tf.reduce_mean(tf.square(y - q))
critic_grads = tape.gradient(critic_loss, self.agent.critic.trainable_variables)
self.agent.critic_optimizer.apply_gradients(zip(critic_grads, self.agent.critic.trainable_variables))(3)target_actor和target_critic网络的参数更新
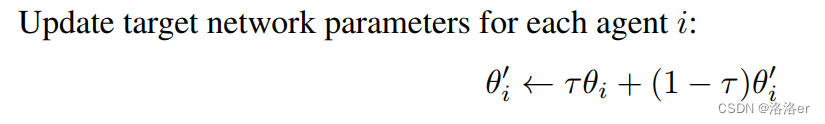
python
# ======================= update target networks ===================
self.update_target(self.agent.target_actor.variables, self.agent.actor.variables, self.tau)
self.update_target(self.agent.target_critic.variables, self.agent.critic.variables, self.tau)
def update_target(self, target_weights, weights, tau):
for (target, weight) in zip(target_weights, weights):
target.assign(weight * tau + target * (1 - tau))(4)MADDPGTrainer完整代码
python
class MADDPGTrainer(Trainer):
def __init__(self, name, obs_dims, action_space, agent_index, args, local_q_func=False):
super().__init__(name, obs_dims, action_space, agent_index, args, local_q_func)
self.name = name
self.args = args
self.agent_index = agent_index
self.nums = len(obs_dims)
# ======================= env preprocess =========================
self.action_space = action_space
if isinstance(action_space[0], gym.spaces.Box):
self.act_dims = [self.action_space[i].shape[0] for i in range(self.nums)]
self.action_out_func = gen_action_for_continuous
elif isinstance(action_space[0], gym.spaces.Discrete):
self.act_dims = [self.action_space[i].n for i in range(self.nums)]
self.action_out_func = gen_action_for_discrete
# ====================== hyperparameters =========================
self.local_q_func = local_q_func
if self.local_q_func:
logger.info(f"Init {agent_index} is using DDPG algorithm")
else:
logger.info(f"Init {agent_index} is using MADDPG algorithm")
self.gamma = args.gamma
self.tau = args.tau
self.batch_size = args.batch_size
self.agent = MADDPGAgent(name, self.act_dims, obs_dims, agent_index, args, local_q_func=local_q_func)
self.replay_buffer = ReplayBuffer(args.buffer_size)
self.max_replay_buffer_len = args.batch_size * args.max_episode_len
self.replay_sample_index = None
# ====================initialize target networks====================
self.update_target(self.agent.target_actor.variables, self.agent.actor.variables, tau=self.tau)
self.update_target(self.agent.target_critic.variables, self.agent.critic.variables, tau=self.tau)
def train(self, trainers, t):
if len(self.replay_buffer) < self.max_replay_buffer_len: # replay buffer is not large enough
return
if not t % 100 == 0: # only update every 100 steps
return
obs_n, action_n, reward_i, next_obs_n, done_i = self.sample_batch_for_pretrain(trainers)
# ======================== train critic ==========================
with tf.GradientTape() as tape:
target_actions = [trainer.get_target_action(next_obs_n[i]) for i, trainer in enumerate(trainers)]
# ============= target ===========
target_q_input = next_obs_n + target_actions # global info
if self.local_q_func:
target_q_input = [next_obs_n[self.agent_index], target_actions[self.agent_index]]
target_q = self.agent.agent_target_critic(target_q_input)
# done_i = tf.convert_to_tensor(done_i[:, np.newaxis])
# done_i = done_i[:, np.newaxis]
# reward_i = reward_i[:, np.newaxis]
# reward_i = tf.convert_to_tensor(reward_i[:, np.newaxis])
y = reward_i + self.gamma * (1 - done_i) * target_q # target
# ============= current ===========
q_input = obs_n + action_n # global info
if self.local_q_func: # local info
q_input = [obs_n[self.agent_index], action_n[self.agent_index]]
q = self.agent.agent_critic(q_input)
critic_loss = tf.reduce_mean(tf.square(y - q))
critic_grads = tape.gradient(critic_loss, self.agent.critic.trainable_variables)
self.agent.critic_optimizer.apply_gradients(zip(critic_grads, self.agent.critic.trainable_variables))
# ========================= train actor ===========================
with tf.GradientTape() as tape:
_action_n = []
for i, trainer in enumerate(trainers):
_action = trainer.get_action(obs_n[i])
_action_n.append(_action)
q_input = obs_n + _action_n
if self.local_q_func:
q_input = [obs_n[self.agent_index], _action_n[self.agent_index]]
p_reg = tf.reduce_mean(tf.square(_action_n[self.agent_index])) # regularization
actor_loss = -tf.reduce_mean(self.agent.agent_critic(q_input)) + p_reg * 1e-3
actor_grads = tape.gradient(actor_loss, self.agent.actor.trainable_variables)
self.agent.actor_optimizer.apply_gradients(zip(actor_grads, self.agent.actor.trainable_variables))
# ======================= update target networks ===================
self.update_target(self.agent.target_actor.variables, self.agent.actor.variables, self.tau)
self.update_target(self.agent.target_critic.variables, self.agent.critic.variables, self.tau)
def pretrain(self):
self.replay_sample_index = None
def save_model(self, path):
checkpoint = tf.train.Checkpoint(agents=self.agent)
checkpoint.save(path)
def locd_model(self, path):
self.agent.load_model(path)
@tf.function
def get_action(self, state):
# return tf.cond(
# tf.rank(state) == 1,
# lambda: self.action_out_func(self.agent.agent_action(state.squeeze(axis=0))[0]),
# lambda: self.action_out_func(self.agent.agent_action(state))
# )
# if state.ndim == 1:
# state = np.expand_dims(state, axis=0)
# action_re = self.action_out_func(self.agent.actor(state)[0])
# else:
# action_re = self.action_out_func(self.agent.actor(state))
return self.action_out_func(self.agent.actor(state))
@tf.function(input_signature=[tf.TensorSpec(shape=[None, None], dtype=DATA_TYPE)])
def get_target_action(self, state):
return self.action_out_func(self.agent.target_actor(state))
def update_target(self, target_weights, weights, tau):
for (target, weight) in zip(target_weights, weights):
target.assign(weight * tau + target * (1 - tau))
def experience(self, state, action, reward, next_state, done, terminal):
self.replay_buffer.add(state, action, reward, next_state, float(done))
def sample_batch_for_pretrain(self, trainers):
if self.replay_sample_index is None:
self.replay_sample_index = self.replay_buffer.make_index(self.batch_size)
obs_n, action_n, next_obs_n = [], [], []
reward_i, done_i = None, None
for i, trainer in enumerate(trainers):
obs, act, rew, next_obs, done = trainer.replay_buffer.sample_index(self.replay_sample_index)
# obs = tf.convert_to_tensor(obs, dtype=tf.float64) # (self.batch_size, 18)
# act = tf.convert_to_tensor(act, dtype=tf.float64) # (self.batch_size, 5)
# rew = tf.convert_to_tensor(rew, dtype=tf.float64) # (self.batch_size, 1)
# next_obs = tf.convert_to_tensor(next_obs, dtype=tf.float64) # (self.batch_size, 18)
# done = tf.convert_to_tensor(done, dtype=tf.float64) # (self.batch_size, 1)
# obs = np.array(obs) # (self.batch_size, 18)
# act = np.array(act) # (self.batch_size, 5)
# rew = np.array(rew) # (self.batch_size, 1)
# next_obs = np.array(next_obs) # (self.batch_size, 18)
# done = np.array(done) # (self.batch_size, 1)
obs_n.append(obs)
action_n.append(act)
next_obs_n.append(next_obs)
if self.agent_index == i:
done_i = done
reward_i = rew
return obs_n, action_n, reward_i[:, np.newaxis], next_obs_n, done_i[:, np.newaxis]3.2 distribution.py
python
import tensorflow as tf
@tf.function
def gen_action_for_discrete(actions):
u = tf.random.uniform(tf.shape(actions), dtype=tf.float64)
return tf.nn.softmax(actions - tf.math.log(-tf.math.log(u)), axis=-1)
@tf.function
def gen_action_for_continuous(actions):
mean, logstd = tf.split(axis=1, num_or_size_splits=2, value=actions)
std = tf.exp(logstd)
return mean + std * tf.random.normal(tf.shape(mean))3.3 args_config.py
该函数定义的所有变量,在train_maddpg.py文件中,将会赋值给变量arglist
python
def parse_args_maddpg():
parser = argparse.ArgumentParser("Reinforcement Learning experiments for multiagent environments")
# Environment
parser.add_argument("--scenario", type=str, default="simple_spread", help="name of the scenario script")
parser.add_argument("--max-episode-len", type=int, default=25, help="maximum episode length")
parser.add_argument("--num-episodes", type=int, default=60000, help="number of episodes")
parser.add_argument("--num-adversaries", type=int, default=0, help="number of adversaries")
parser.add_argument("--good-policy", type=str, default="maddpg", help="policy for good agents")
parser.add_argument("--adv-policy", type=str, default="maddpg", help="policy of adversaries")
# Core training parameters
parser.add_argument("--lr", type=float, default=1e-2, help="learning rate for Adam optimizer")
parser.add_argument("--gamma", type=float, default=0.95, help="discount factor")
parser.add_argument("--batch-size", type=int, default=1024, help="number of episodes to optimize at the same time")
parser.add_argument("--num-units", type=int, default=64, help="number of units in the mlp")
parser.add_argument("--tau", type=float, default=0.01, help="target smoothing coefficient")
# Checkpointing
parser.add_argument("--buffer-size", type=int, default=1000000)
parser.add_argument("--exp-name", type=str, default="maddpg", help="name of the experiment")
parser.add_argument("--save-dir", type=str, default="../models/",
help="directory in which training state and model should be saved")
parser.add_argument("--save-rate", type=int, default=1000,
help="save model once every time this many episodes are completed")
parser.add_argument("--load-dir", type=str, default="",
help="directory in which training state and model are loaded")
# Evaluation
parser.add_argument("--restore", action="store_true", default=False)
parser.add_argument("--display", action="store_true", default=False)
parser.add_argument("--benchmark", action="store_true", default=False)
parser.add_argument("--benchmark-iters", type=int, default=100000, help="number of iterations run for benchmarking")
parser.add_argument("--benchmark-dir", type=str, default="./benchmark_files/",
help="directory where benchmark data is saved")
parser.add_argument("--plots-dir", type=str, default="../results/maddpg/learning_curves/",
help="directory where plot data is saved")
parser.add_argument("--show-plots", type=bool, default=True, help="show plots")
args = parser.parse_args()
# Log the parsed arguments
logger.info("============================== MADDPG Global arguments===============================")
for arg, value in vars(args).items():
logger.info(f"{arg}: {value}")
logger.info("=====================================================================================")
return args3.4 train_maddpg.py
大致流程是:
- 定义环境,使用
make_env() - 定义所有智能体的trainer,使用
get_trainers() - 训练函数,
train()
python
import argparse
import numpy as np
import time
import pickle
import datetime
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from maddpg.trainer.maddpg import MADDPGTrainer
from base.trainer import MultiTrainerContainer
from base.args_config import get_config
from utils.utils import save_model, load_model, load_data2_plot
from utils.logger import set_logger
logger = set_logger(__name__, output_file="train_maddpg.log")
# 在任何使用到的地方
# logger.info("Start training")
def make_env(scenario_name, arglist, benchmark=False):
from multiagent.environment import MultiAgentEnv
import multiagent.scenarios as scenarios
# load scenario from script
scenario = scenarios.load(scenario_name + ".py").Scenario()
world = scenario.make_world()
if benchmark:
env = MultiAgentEnv(world, scenario.reset_world, scenario.reward, scenario.observation, scenario.benchmark_data)
else:
env = MultiAgentEnv(world, scenario.reset_world, scenario.reward, scenario.observation)
return env
def get_trainers(env, num_adversaries, obs_shape_n, arglist):
trainers = []
trainer = MADDPGTrainer
for i in range(num_adversaries):
trainers.append(trainer(
"agent_%d" % i, obs_shape_n, env.action_space, i, arglist,
local_q_func=(arglist.adv_policy == 'ddpg')))
for i in range(num_adversaries, env.n):
trainers.append(trainer(
"agent_%d" % i, obs_shape_n, env.action_space, i, arglist,
local_q_func=(arglist.good_policy == 'ddpg')))
return trainers
def train(arglist):
# Create environment
logger.info("=====================================================================================")
curtime = datetime.datetime.now()
cur_dir = f"{curtime.strftime('%Y-%m-%d-%H-%M-%S')}"
logger.info(f"Training start at {cur_dir}")
arglist.save_dir = arglist.save_dir + arglist.exp_name + '/' + arglist.scenario + '/' + cur_dir
logger.info(f"Save dir: {arglist.save_dir}")
if not os.path.exists(arglist.save_dir):
os.makedirs(arglist.save_dir)
env = make_env(arglist.scenario, arglist, arglist.benchmark)
# Create agent trainers
obs_shape_n = [env.observation_space[i].shape for i in range(env.n)]
num_adversaries = min(env.n, arglist.num_adversaries)
trainers = get_trainers(env, num_adversaries, obs_shape_n, arglist)
logger.info('Using good policy {} and adv policy {}'.format(arglist.good_policy, arglist.adv_policy))
# 定义检查点,包含多个模型
# 创建MultiAgentContainer对象
multi_agent_container = MultiTrainerContainer(trainers)
checkpoint = tf.train.Checkpoint(multi_agent_container=multi_agent_container)
# Load previous results, if necessary
if arglist.load_dir == "":
arglist.load_dir = arglist.save_dir
checkpoint_manager = tf.train.CheckpointManager(checkpoint, arglist.load_dir, max_to_keep=5)
if arglist.display or arglist.restore or arglist.benchmark:
logger.info('Loading previous state...')
checkpoint.restore(checkpoint_manager.latest_checkpoint)
episode_rewards = [0.0] # sum of rewards for all agents
agent_rewards = [[0.0] for _ in range(env.n)] # individual agent reward
final_ep_rewards = [] # sum of rewards for training curve
final_ep_ag_rewards = [] # agent rewards for training curve
agent_info = [[[]]] # placeholder for benchmarking info
obs_n = env.reset()
episode_step = 0
train_step = 0
t_start = time.time()
logger.info('Starting iterations...')
while True:
# get action
action_n = [trainer.get_action(np.expand_dims(obs, axis=0))[0] for trainer, obs in zip(trainers, obs_n)]
# environment step
new_obs_n, rew_n, done_n, info_n = env.step(action_n)
episode_step += 1
done = all(done_n)
terminal = (episode_step >= arglist.max_episode_len)
# collect experience
for i, agent in enumerate(trainers):
agent.experience(obs_n[i], action_n[i], rew_n[i], new_obs_n[i], done_n[i], terminal)
obs_n = new_obs_n
for i, rew in enumerate(rew_n):
episode_rewards[-1] += rew
agent_rewards[i][-1] += rew
if done or terminal:
obs_n = env.reset()
episode_step = 0
episode_rewards.append(0)
for a in agent_rewards:
a.append(0)
agent_info.append([[]])
# increment global step counter
train_step += 1
# for benchmarking learned policies
if arglist.benchmark:
for i, info in enumerate(info_n):
agent_info[-1][i].append(info_n['n'])
if train_step > arglist.benchmark_iters and (done or terminal):
file_name = arglist.benchmark_dir + arglist.exp_name + '.pkl'
logger.info('Finished benchmarking, now saving...')
with open(file_name, 'wb') as fp:
pickle.dump(agent_info[:-1], fp)
break
continue
# for displaying learned policies
if arglist.display:
time.sleep(0.1)
env.render()
continue
# update all trainers, if not in display or benchmark mode
loss = None
for agent in trainers:
agent.pretrain()
for agent in trainers:
loss = agent.train(trainers, train_step) # sample index is same.
# save model, display training output
if terminal and (len(episode_rewards) % arglist.save_rate == 0):
checkpoint_manager.save()
# print statement depends on whether or not there are adversaries
if num_adversaries == 0:
logger.info("steps: {}, episodes: {}, mean episode reward: {}, time: {}".format(
train_step, len(episode_rewards), np.mean(episode_rewards[-arglist.save_rate:]),
round(time.time() - t_start, 3)))
else:
logger.info(
"steps: {}, episodes: {}, mean episode reward: {}, agent episode reward: {}, time: {}".format(
train_step, len(episode_rewards), np.mean(episode_rewards[-arglist.save_rate:]),
[np.mean(rew[-arglist.save_rate:]) for rew in agent_rewards], round(time.time() - t_start, 3)))
t_start = time.time()
# Keep track of final episode reward
final_ep_rewards.append(np.mean(episode_rewards[-arglist.save_rate:]))
for rew in agent_rewards:
final_ep_ag_rewards.append(np.mean(rew[-arglist.save_rate:]))
# saves final episode reward for plotting training curve later
if len(episode_rewards) > arglist.num_episodes:
file_dir = arglist.plots_dir + cur_dir + '/'
if not os.path.exists(file_dir):
os.makedirs(file_dir)
rew_file_name = file_dir + arglist.exp_name + '_rewards.pkl'
with open(rew_file_name, 'wb') as fp:
pickle.dump(final_ep_rewards, fp)
agrew_file_name = file_dir + arglist.exp_name + '_agrewards.pkl'
with open(agrew_file_name, 'wb') as fp:
pickle.dump(final_ep_ag_rewards, fp)
logger.info('...Finished total of {} episodes.'.format(len(episode_rewards)))
if arglist.show_plots:
load_data2_plot(rew_file_name, "reward", False)
load_data2_plot(agrew_file_name, "agreward", False)
break
if __name__ == '__main__':
arglist = get_config('maddpg')
train(arglist)4.实验结果
训练环境:simple_spread,episode的step长度25。
其他参数全在args_config.py的parse_args_maddpg()函数,没有更改。
最后,训练60000episode的结果如下: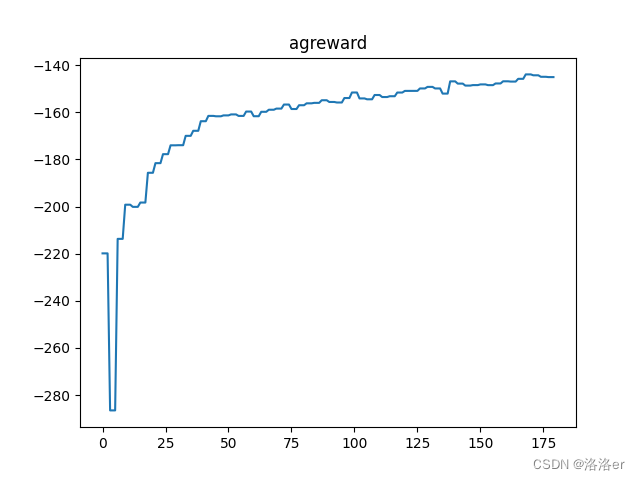
5.参考文章
原文链接:
github的源码(tensorflow的v1):https://github.com/openai/maddpg