汽车之家基于Paimon的实践
摘要:本文分享自汽车之家的王刚、范文、李乾⽼师。介绍了汽车之家基于 Paimon 的一些实践,和一些背景。内容主要为以下四部分:
一、背景
二、业务实践
三、paimon 优化实践
四、未来规划
一、背景
在使用Paimon之前,之家的实时/离线数仓分别使用不同的技术方案:
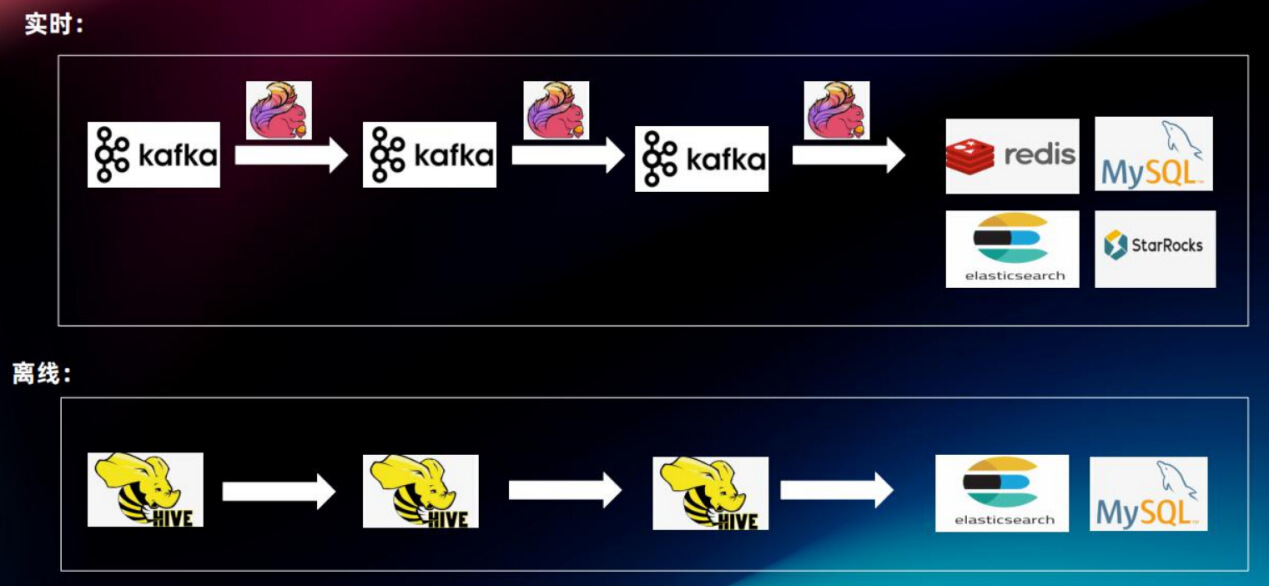
- 离线数仓的方案是使用Hive将数据加工成天/小时级别的表
这个方案非常成熟,几乎所有数据仓库团队成员都能熟练掌握。对于业务方而言,其开发和维护成本较低。但是这种方案生成的表通常会有较长时间的数据延迟(如天或小时),数据新鲜度相对较低。此外,在夜间可能还会出现大量的ETL任务竞争资源,导致资源紧张。
- 实时数仓采用的方案是基于Flink、Kafka,关系型数据库和Redis等技术栈,并结合StarRocks做实时OLAP
由于数据都是实时处理,因此可以保证数据的新鲜度,一般情况下延迟能做到秒级。然而,当SQL比较复杂时,尤其是存在多个Group by, Join算子时,会导致Flink处理的回撤流翻倍,Flink状态体积非常庞大,使用大量的计算存储资源。这种场景在任务的开发和维护方面可能会带来较大的挑战。任务的开发周期也因此会较离线的方案长很多。
在20年底,我们开始调研Iceberg通过流式湖仓的方式在存储上作为实时和离线数据的统一存储方案。Iceberg架构非常的简洁健壮、集成Flink可以做到分钟级别的数据延迟、并且通过自身维护元数据减少了Hive MetaStore的压力、可以灵活且高效地处理表结构变更、支持排序索引等功能可以有效地提升查询效率等优点非常多。但是经过一段时间的使用后,我们发现Iceberg更适合批处理场景,在流场景的一些必要功能的缺失比如增量且有序读取,实时任务在线schema变更,缺少部分更新导致无法满足我们流式湖仓的需求。

我们在23年开始调研Apache Paimon,Paimon提供了类似于Iceberg的简洁健壮的架构,并且功能非常强大。与Flink也集成得非常完善,提供了增量且有序的数据读取、部分更新等能力,结合Flink CDC可以实现整库同步,在线Schema变更等,满足了我们对于流式湖仓的需求。而且Paimon作为一个相对较新的数据湖,没有太多的历史负担,这对于其他数据湖来说这一点有着非常巨大的优势。
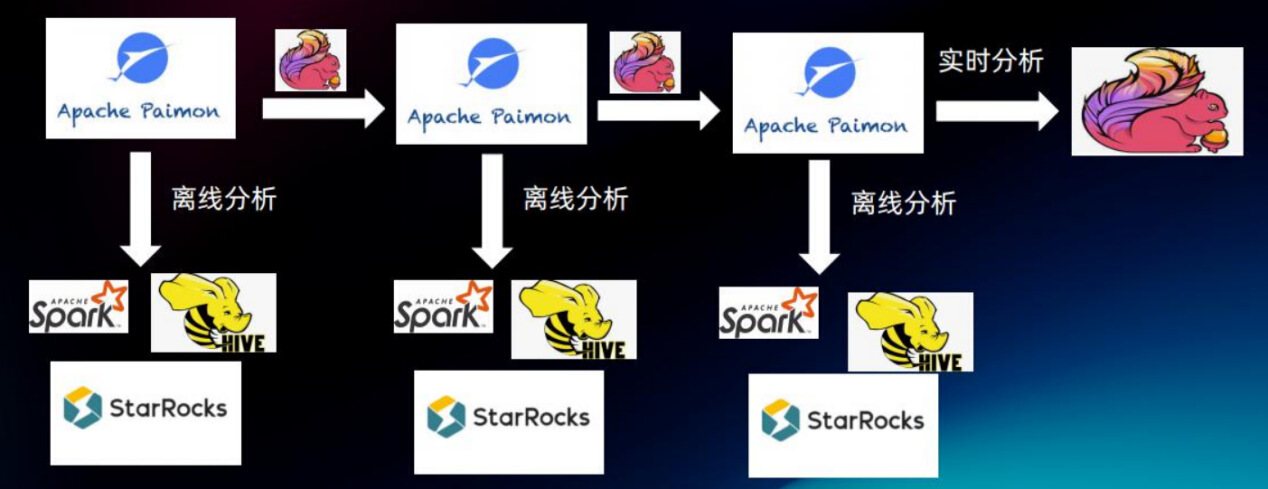
我们最终使用了Paimon作为存储流批一体的解决方案。实时和离线数据共享同一份存储,这样做降低了开发和维护的难度,提高了数据仓库的整体数据新鲜度。此外,我们还通过使用StarRocks建立物化视图和使用Sort Compaction功能等技术手段来进一步提升查询效率,节省计算资源。
二 、业务实践
在下文中将给大家分享之家基于Paimon的业务实践:
- 新用户转化分析
(1)使用Paimon主键表的部分更新功能
(2)使用StarRocks建物化视图加速Paimon表的查询
- 流量日志入湖
(1)使用Paimon的Append表
(2)使用Paimon的Sort Compaction功能加速Paimon表的查询,提升查询效率,减少资源消耗
- 资源入湖
使用Paimon主键表的Upsert功能
2.1 新用户转化分析
新用户转化分析是一种对新用户在产品中行为变化的分析方法,通过观察新用户在其首次进入APP的行为,分析他们在后续阶段的转化过程。这种分析对于理解产品的用户采用情况、改进用户体验、提高用户留存率等方面具有重要的意义。为了实时获取新用户进入之家APP后在同步落地页的转化情况,需将用户的行为路径和订单数据关联,通过综合分析新用户在产品或服务中的行为,可以更加全面地改进产品体验,并制定更具针对性的策略,从而提高用户转化率。在这个场景中,我们使用到了Paimon的部分更新功能,按照用户ID部分更新对应主题的数据。
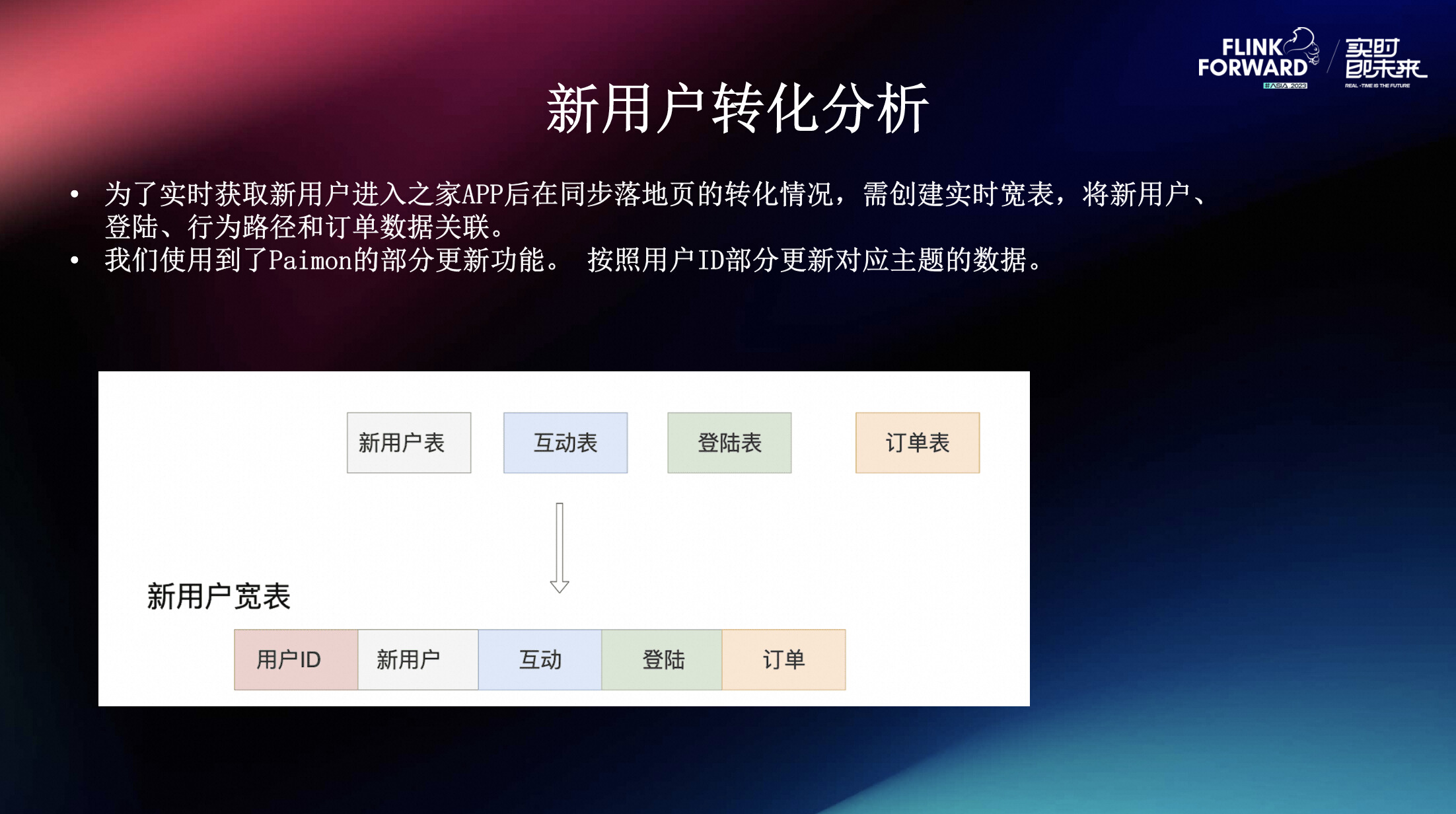
2.1.1 实现
(1)构建新用户宽表
js
CREATE TABLE if not exists new_user_transform (
user_id String,
new_user_type String,
channel_name String,
land_page String,
....
primary key (deviceid,dt) not enforced
) partitioned by (dt)
WITH (
'bucket-key' ='deviceid',
'bucket' = 'xx',
'full-compaction.delta-commits'='5',
'merge-engine' ='partial-update',
'partial-update.ignore-delete'='true',
)(2)处理数据写入到Paimon
1)通过Flink的interval window 计算新用户在5分钟内进入过的承接页
js
CREATE TEMPORARY VIEW new_user_view AS
select
l.deviceid,
r.page_id as land_page
from
(select time_ltz, deviceid, channelid, proctime
from new_user) l
left join
(select page_id, deviceid, time_ltz
from user_page_view_log) r
on upper(l.deviceid) = upper(r.deviceid)
and r.time_ltz > l.time_ltz and r.time_ltz < l.time_ltz + INTERVAL '5' MINUTE2)通过Paimon的部分拼接功能将数据拼接到Paimon表
宽表字段由多个数据源提供,直接使用 Union All 的方式进行拼接, 数据在存储层进行 Join 拼接,与计算引擎无关,不需要保留join算子的状态,节省资源。
js
insert into new_user_transform
select user_id ,user_info,CAST(NULL AS STRING),CAST(NULL AS STRING) from new_user_view
union all
select user_id,case(NULL AS STRING),order_info,case(NULL AS STRING) from order
union all
....3)在StarRocks构建Paimon物化视图
此外,为了提升拼接后的宽表的查询效率,我们开发了基于Paimon外表的StarRocks的物化视图功能。目前基于Paimon外表的物化视图功能已经贡献给了StarRocks社区,会在StarRocks 3.2版本发布
js
CREATE MATERIALIZED VIEW new_user_trans_mv COMMENT "laxin_toufang_by_loudou_mv" DISTRIBUTED BY RANDOM PARTITION BY (`pdt`) REFRESH DEFERRED MANUAL PROPERTIES( "replication_num" ="5", "storage_medium"="HDD") as
select str2date(dt,'%Y-%m-%d') pdt, hour, COALESCE(new_user_type,'all'),
COALESCE(channel_type,'all'),
COALESCE(new_channel_name,'all'),
COALESCE(land_page,'all'),
count(distinct deviceid) as uv,
count(distinct case when entry_show = '1' then deviceid else null end) as entry_show,
count(distinct case when entry_click = '1' then deviceid else null end) as entry_click,
count(distinct case when page_show = '1' then deviceid else null end) as page_show,
count(distinct case when page_click = '1' then deviceid else null end) as page_click,
count(distinct case when is_login = '1' then deviceid else null end) as is_login
FROM paimon_catalog_fdm.rt_feature_db.laxin_toufang_by_loudou where
new_user_type is not null and channel_type is not null
and new_channel_name is not null and land_page is not null
group by grouping sets((dt,hour), (dt,hour,new_user_type), (dt,hour,channel_type),
(dt,hour,new_channel_name), (dt,hour,land_page),
(dt,hour, new_user_type, channel_type, new_channel_name, land_page),
(dt,hour,new_user_type, channel_type, new_channel_name),
(dt,hour, new_user_type, channel_type, land_page),
(dt,hour,channel_type, new_channel_name,land_page),
(dt,hour,new_user_type, channel_type),
(dt,hour, new_user_type, new_channel_name),
(dt,hour, new_user_type, land_page),
(dt,hour, channel_type, new_channel_name),
(dt,hour,channel_type, land_page),
(dt,hour,new_channel_name, land_page));4)手动刷新物化视图
除了自动按增量分区刷新物化视图,用户还可以选择手动刷新物化视图。
js
REFRESH MATERIALIZED VIEW new_user_trans_mv
partition start ("2023-11-10") end ("2023-11-11")
WITH SYNC MODE;5)最终效果:
-
1天的宽表在10秒左右刷新完成
-
查询每天的物化视图效率在亚秒级
(3)收益
-
时效性: 宽表时效性从天级别提升到分钟级别
-
开发效率:开发效率提升5倍以上
-
使用资源:因为Join的数据不再需要维护在状态中,Flink写入任务使用的资源节省了60%
2.2 流量日志入湖
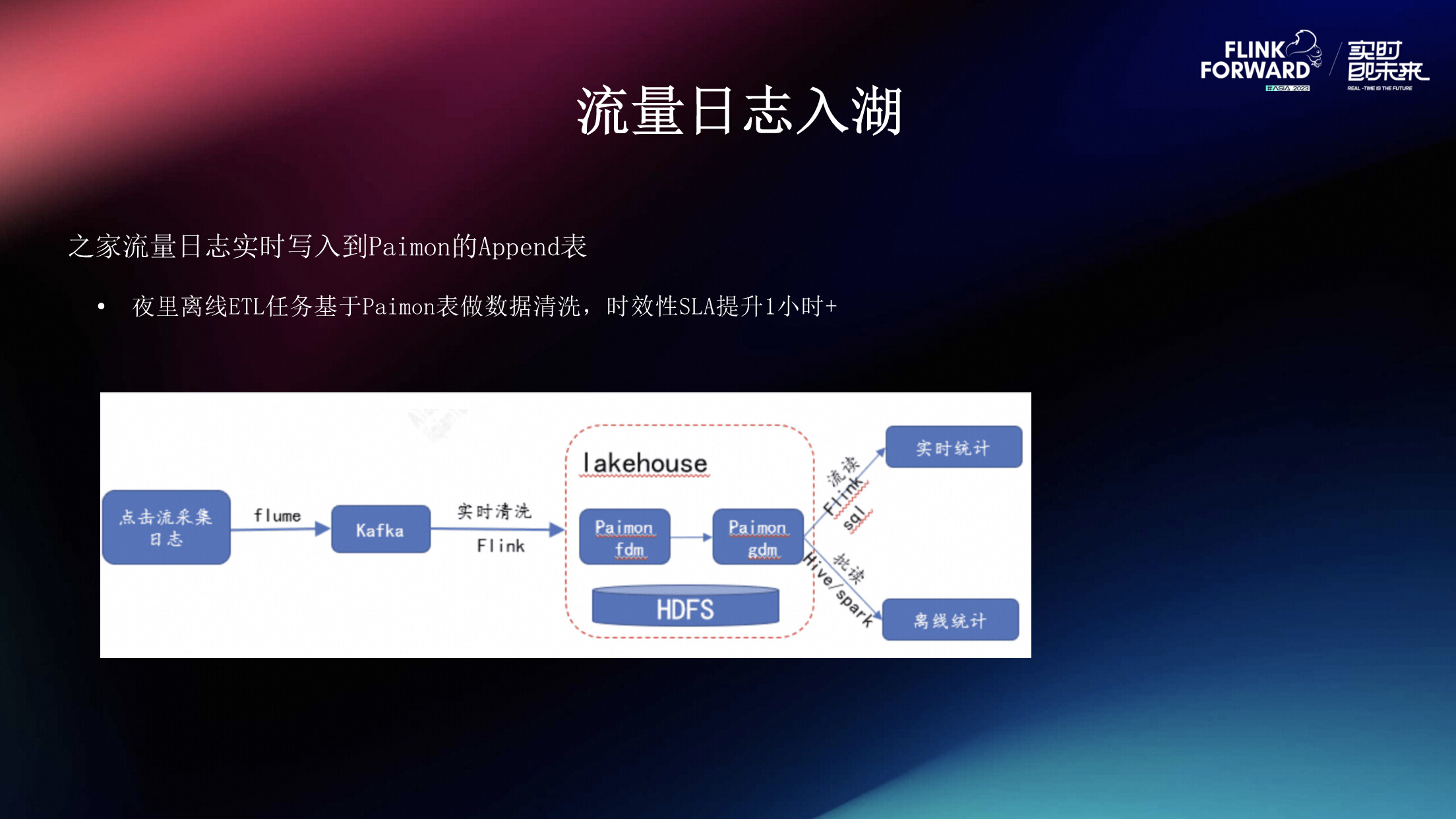
将之家的流量日志基表打宽入湖,可以提升数仓日志清洗的时效性SLA。在提升数据时效性的同时,为提升特定事件的分析查询效率,通过Paimon的排序合并(Sort Compaction)功能,可以根据统计信息快速定位event_id所在的数据数据文件,排序后,不用读取分区所有的数据文件,可减少计算引擎的使用资源, 极大提升查询效率。这里使用了Paimon的append only表近实时追加流量日志。
2.2.1 Sort Compaction
这里因为event_id存在热点问题,为了保证排序分桶均匀,使用event_id,device_id两个字段排序。因为使用的最左匹配策略,所以不会影响基于event_id字段的查询效率
js
./bin/flink run-application -t yarn-application -D execution.runtime-mode=batch paimon-flink-action.jar \
compact \
--warehouse viewfs://xxxx\
--database pmon_dw \
--table pmon_user_log \
--partition dt=2023-11-10,hour=23 \
--order-strategy order \
--order-by event_id,device_id \
--table-conf read.batch-size=2048 在Paimon的元数据中会维护event_id的统计信息,如下图所示:在按照event_id排序后,会根据统计信息判断出 evnet_id = 'sight_b'的数据只存在File1、File2中,所以只查询数据文件File1,File2即可。在查询Paimon表的plan阶段可以根据统计信息很高效的命中文件,Hive不用查询分区内的所有文件,从而节省查询使用的资源、提高查询效率。
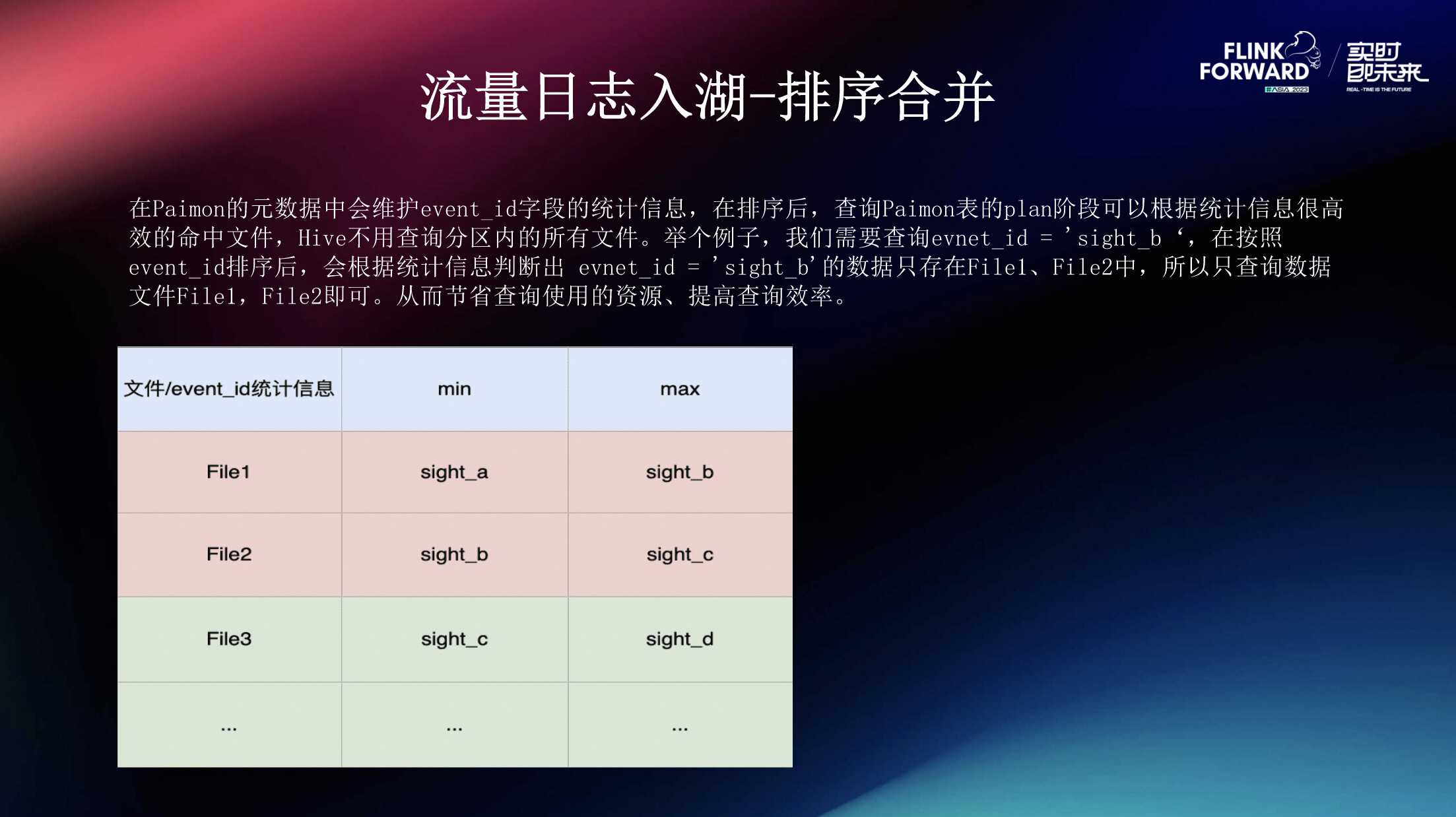
**(1) 收益 **
1)数仓流量日志清洗SLA提升1小时+;
2)天分区的数据使用Hive通过查询不同数量级的event_id,资源节省再显著降低的同时,查询效率也得到显著提升。
| 排序前 | 排序后(根据event_id的量级范围测试) | |
|---|---|---|
| mapper数 | 33045 | 24-1367 |
| 查询效率(分钟) | 20 | 3到6分钟 |
2.3 资源入湖
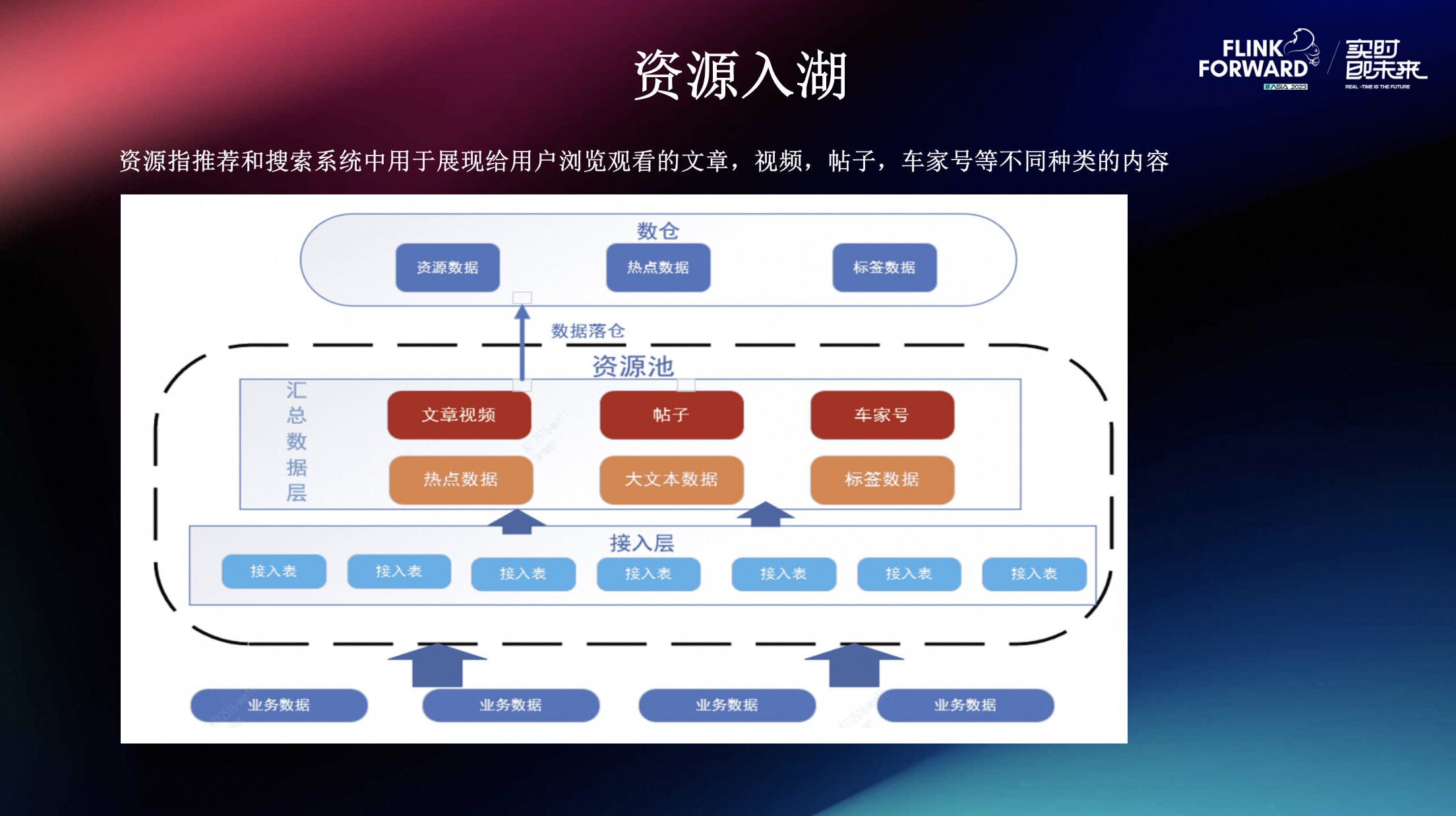
2.3.1 背景
资源指在推荐和搜索系统中用于展现给用户浏览观看的文章,视频,帖子,车家号等不同种类的内容。这些内容分别来自不同的生产方,不同的数据源。在传统的数仓处理流程汇中,我们采用常规的离线同步业务数据的方式,形成ODS接入层数据。而后,针对接入层的各类来源信息,通过hive,spark等离线计算引擎,完成数据的归总,最终形成资源数据模型。这种传统的方式受限于整套组件的机制,形成常规的天级数据更新模式。这种方式可以获取昨日数据,单也不可避免的无法满足获取当日数据的需求。
为了解决这类问题,我们通过使用Flink的实时处理数据,结合paimon的数据湖近实时存储。使用到Paimon表upsert的功能,近实时以分钟级别的方式更新实时数据。以数湖的方式,既可以满足离线昨日数据,也可以满足当日新增数据获取的目的。
2.3.2 业务规模
资源数据来源8套不同业务线的内容生产方,每套业务线数据平均包含200余个属性字段,合计超过1500个不同属性的逻辑处理。
2.3.3 实现逻辑
(1)通过参考数仓宽表层的处理模式,将大量数据进行合并,形成50个核心属性,其余属性通过可扩展json的形式进行存储,完成整体数据落地。保证业务方可以根据需求获取到每一个参数。
(2)主键由业务表主键与业务类型拼接生成,保证不同业务之间不会互相倍覆盖。
js
CREATE TABLE if not exists resource_extend_info (
pk string
biz_id string,
biz_typle string,
...
extinfo string
primary key (pk) not enforced
)
WITH (
'bucket' = 'xx',
'bucket-key' ='pk',
'full-compaction.delta-commits'='5',
'target-file-size'='256 mb',
)将不同类型的资源数据写入到Paimon业务库
js
insert into resource_extend_info
select pk ...,extinfo from article
union all
select pk ..., extinfo from post
union all
.....2.3.4 收益
(1)数据新鲜度从天级提升到分钟级别
通过数据实时接入和宽表层的实时入湖,数据使用方从原有的天级离线模式,可以提升到分钟级数据新鲜度,这是之前数仓场景无法比拟的。湖仓模式打破了原有离线的工作模式,让下游算法在模型计算的时候可以取到最新的样本,提升模型的时效。
(2)下游业务方平滑过渡,无需业务大量开发调整
基于paimon的数据湖可以直接让下游开发者,无需脱离现有的hive离线数仓环境,直接使用hive环境读取paimon数据表,就可以获取到最新的当日的数据。这让下游算法,数据分析人员,可以0成本的过渡到数湖,无需学习成本。
三、 Paimon 优化实践
3.1 支持代理用户
在之家实时计算平台,目前是使用同一个Haoop用户Flink去提交Flink任务,Checkpoint也通过一些规则被同一用户管理。为了能让平台的Flink用户将数据写到其他团队的数据集市,我们在Paimon的Catalog添加了代理用户的配置。
sql
CREATE CATALOG my_catalog WITH (
'type' = 'paimon',
'warehouse'='xxx',
'metastore' = 'hive',
'uri' ='xxx',
'proxyUser'='xxx'
)3.1.1 实现
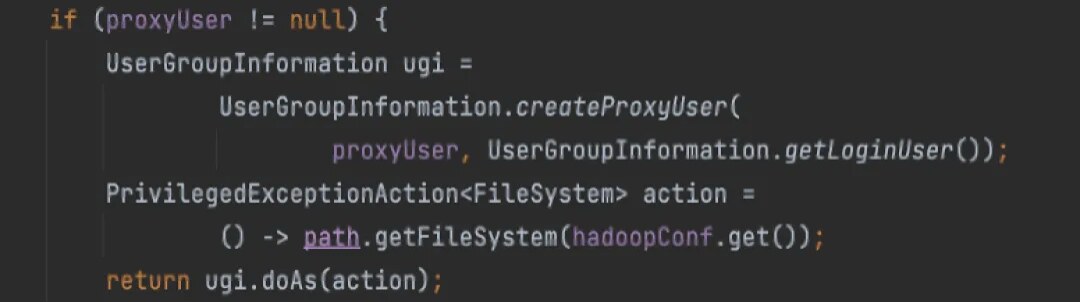
(1)HDFS: 直接通过ugi代理即可
(2)Hive客户端
可以参考Spark的org.apache.spark.deploy.security.HiveDelegationTokenProvider实现,动态代理Hive的客户端。
3.2 优化写入任务内存占用
3.2.1 Writer算子
(1)关闭较大列的数据字典
(2)调低orc文件的读/写 batch size
(3)在checkpoint阶段如果文件数量到达阈值,先等待合并任务完成,避免大量小文件堆积到L0层
3.2.2 Commiter算子
(1)Manifest添加Full Compaction机制
(2)截断Manifest统计信息
(3)单独设置committer 算子内存
3.2.3 JobManager
修复由于writer状态未及时更新,导致Jobmanager中的list state膨胀导致mom
3.2.4 最终收益
(1)目前Paimon在之家的部分更新场景最大的主键表每天增量数据10个TB,单字段大小2-4MB的主键表
(2)线上写入Paimon的Flink任务稳定性显著提升
(3)在使用了社区在内存方面的优化同时,我们提出的在内存方面的优化已经全部被社区采纳,在Paimon 0.5以上版本开箱即用,目前0.5以上的版本已经是非常稳定的版本
四 、未来规划
1. 之家实时计算平台集成 Paimon Web 项目
目前在之家,我们通过实时计算平台实现了Paimon表的写入集成工作。接下来,我们计划将这一部分功能提取出来,通过将社区的Paimon Web项目集成到之家实时计算平台,来管理 Paimon 表和写入任务。
2. 支持StarRocks基于Paimon外表的增量数据构建物化视图 (目前是基于变更分区)
我们计划实现基于Paimon的增量数据刷新物化视图,相比于目前基于Paimon的增量分区的方案,可以缩短物化视图的刷新时间,提升刷新效率。
3. 使用Paimon 定期生成标签功能替换离线拉链表的加工流程
在之家每天夜里会有上万个拉链表的加工任务,占用两个小时的加工时间。Paimon定期生成标签功能相较于加工拉链表会更加轻量,我们计划使用Paimon定期生成标签功能去缩短夜里加工任务的耗时,提升夜里加工任务的时效性SLA。
作者简介
1. 王刚
■ 汽车之家高级大数据开发工程师
■ 主要负责之家实时计算,Kafka,数据湖,向量检索平台及引擎的开发维护工作。
2. 李乾
■ 汽车之家高级大数据开发工程师
■ 主要从事数据仓库领域的开发工作。目前负责之家实时数仓相关数据建设工作。
3. 范文
■ 汽车之家高级大数据开发工程师
■ 主要负责数仓建设,业务数据开发,数仓数据治理,数据湖开发,资源内容特征等工作。