说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解 ),如需数据+代码+文档+视频讲解可以直接到文章最后获取。

1 . 项目背景
随着经济的发展和人民生活水平的提高,汽车消费在居民消费中所占比例逐渐增加,汽车金融公司也因此得到了快速发展。然而,在这个过程中,车贷违约风险的问题也逐渐凸显。如何有效识别和预测车贷违约风险,成为汽车金融公司急需解决的问题。
金融机构因车辆贷款违约而蒙受重大损失。这导致汽车贷款承保收紧,汽车贷款拒绝率上升。通过分析汽车贷款违约情况,利用多种机器学习模型进行预测。
本项目通过逻辑回归模型、决策树模型、LightGBM模型和XGBoost模型进行车辆贷款违约预测。
2 . 数据获取
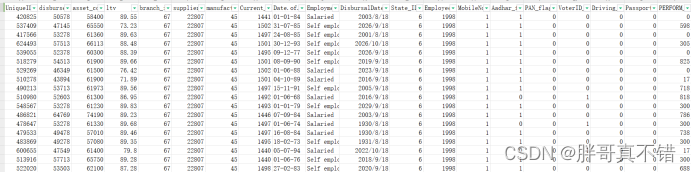
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
|------------|-------------------------------------|-----------------------|
| 编号 | 变量名称 | 描述 |
| 1 | UniqueID | 客户标识符 |
| 2 | loan_default | 到期日第一次的付款违约 |
| 3 | disbursed_amount | 已发放贷款 |
| 4 | asset_cost | 资产成本 |
| 5 | ltv | 资产贷款价值比 |
| 6 | branch_id | 发放贷款的分行 |
| 7 | supplier_id | 发放贷款的车辆经销商 |
| 8 | manufacturer_id | 汽车制造商(英雄、本田、TVS等) |
| 9 | Current_pincode | 客户的当前密码 |
| 10 | Date.of.Birth | 客户的出生日期 |
| 11 | Employment.Type | 客户的就业类型(带薪/自雇) |
| 12 | DisbursalDate | 支付日期 |
| 13 | State_ID | 付款状态 |
| 14 | Employee_code_ID | 记录支出的组织的员工 |
| 15 | MobileNo_Avl_Flag | 如果客户共享手机号码,则标记为1 |
| 16 | Aadhar_flag | 如果客户共享了aadhar,则将其标记为1 |
| 17 | PAN_flag | 如果pan由客户共享,则标记为1 |
| 18 | VoterID_flag | 如果投票者由客户共享,则标记为1 |
| 19 | Driving_flag | 如果DL由客户共享,则标记为1 |
| 20 | Passport_flag | 如果客户共享护照,则标记为1 |
| 21 | PERFORM_CNS.SCORE | 局分数 |
| 22 | PERFORM_CNS.SCORE.DESCRIPTION | 局分数说明 |
| 23 | PRI.NO.OF.ACCTS | 客户在支付时获得的贷款总额 |
| 24 | PRI.ACTIVE.ACCTS | 客户在支付时获得的活跃贷款数 |
| 25 | PRI.OVERDUE.ACCTS | 支付时的违约账户数 |
| 26 | PRI.CURRENT.BALANCE | 发放时活跃贷款的未偿本金总额 |
| 27 | PRI.SANCTIONED.AMOUNT | 发放时所有贷款的批准总额 |
| 28 | PRI.DISBURSED.AMOUNT | 发放时为所有贷款发放的总金额 |
| 29 | SEC.NO.OF.ACCTS | 客户在支付时获得的贷款总额 |
| 30 | SEC.ACTIVE.ACCTS | 客户在支付时获得的活跃贷款数 |
| 31 | SEC.OVERDUE.ACCTS | 支付时的违约账户数 |
| 32 | SEC.CURRENT.BALANCE | 发放时活跃贷款的未偿本金总额 |
| 33 | SEC.SANCTIONED.AMOUNT | 发放时所有贷款的批准总额 |
| 34 | SEC.DISBURSED.AMOUNT | 发放时为所有贷款发放的总金额 |
| 35 | PRIMARY.INSTAL.AMT | 主要贷款金额 |
| 36 | SEC.INSTAL.AMT | 二次贷款金额 |
| 37 | NEW.ACCTS.IN.LAST.SIX.MONTHS | 客户在支出前的最后6个月内获得的新贷款 |
| 38 | DELINQUENT.ACCTS.IN.LAST.SIX.MONTHS | 最近6个月内拖欠的贷款 |
| 39 | AVERAGE.ACCT.AGE | 平均贷款期限 |
| 40 | CREDIT.HISTORY.LENGTH | 自首次贷款以来的时间 |
| 41 | NO.OF_INQUIRIES | 客户办理的贷款手续 |
数据详情如下(部分展示):
3. 数据预处理
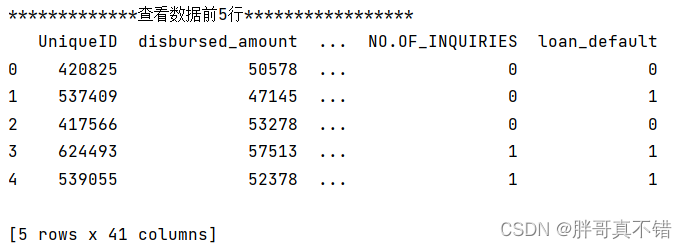
3.1 用P andas 工具查看数据
使用Pandas工具的head()方法查看前五行数据:
关键代码:

3.2 数据缺失查看
使用Pandas工具的info()方法查看数据信息:
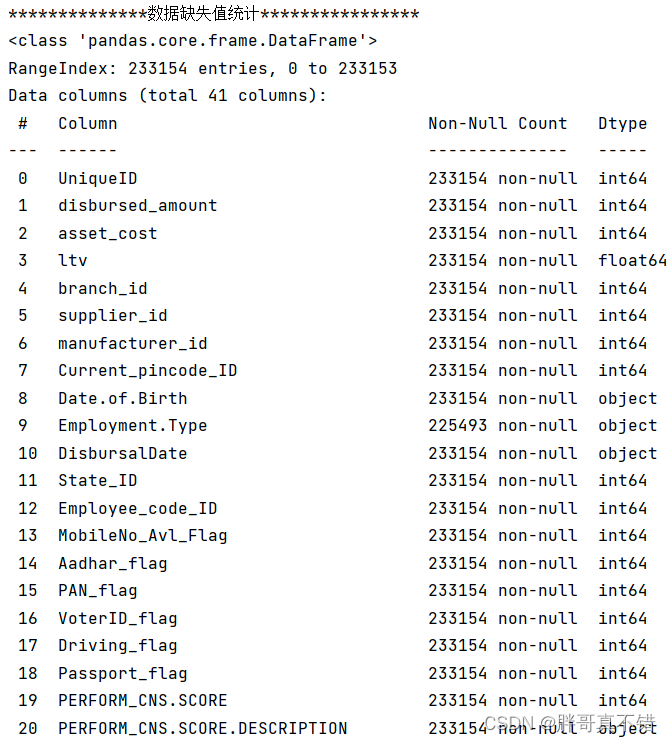
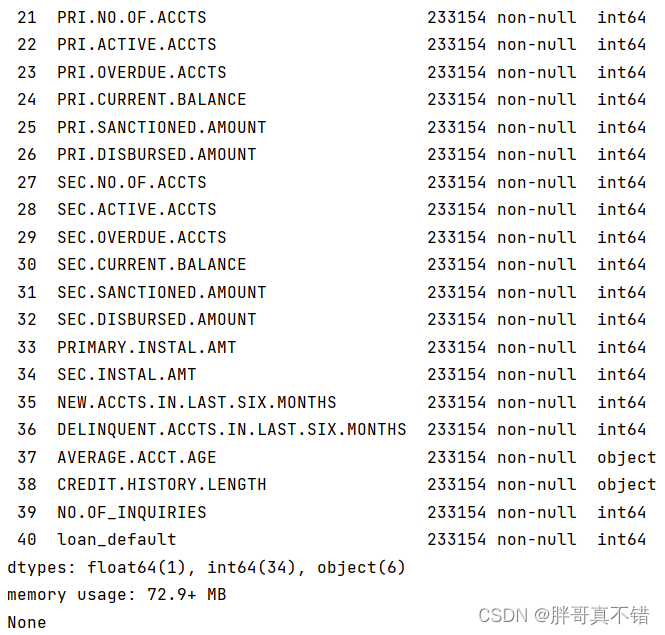
从上图可以看到,总共有41个变量,数据中无缺失值,共233154条数据。
关键代码:

3. 3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
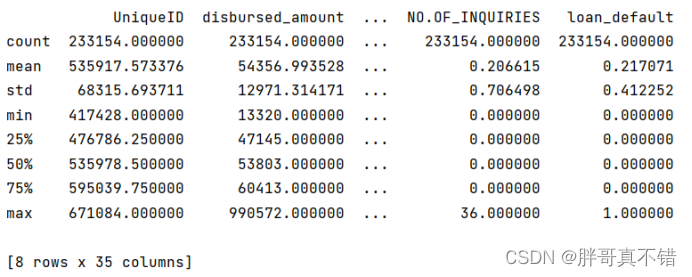
关键代码如下:

4. 探索性数据分析
4.1 loan_default变量柱状图
用Matplotlib工具的plot()方法绘制柱状图:

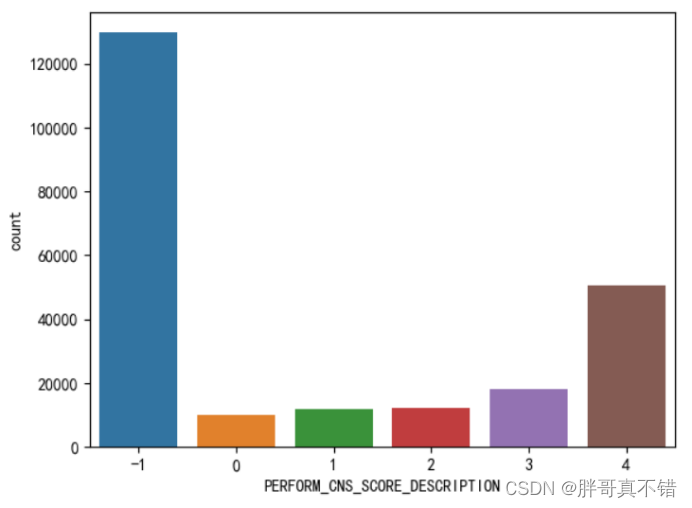
4. 2 数据项空值统计
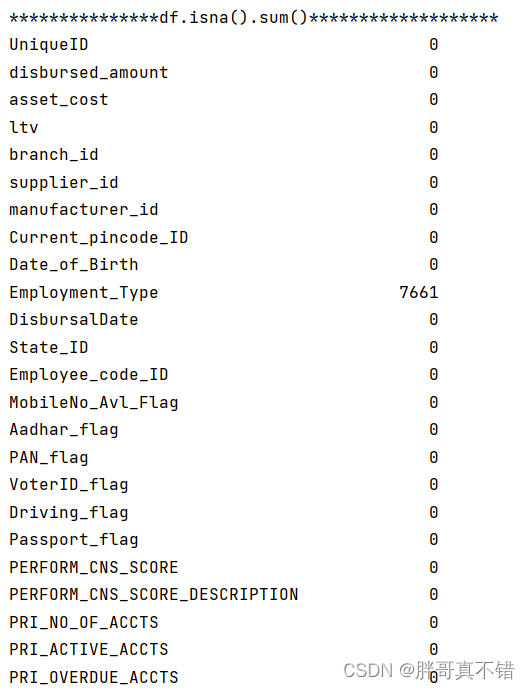
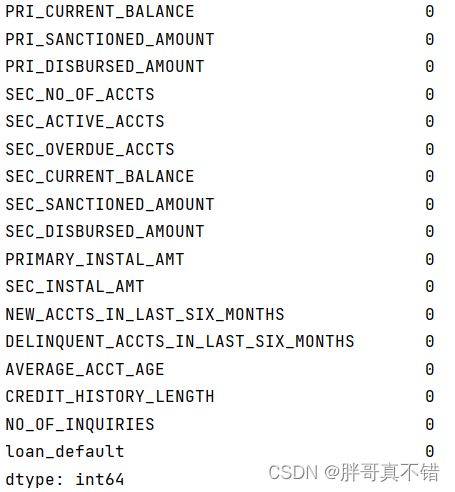
从上图可以看到,Employment_Type变量有空值,数量为7661。
4 .3 相关性分析
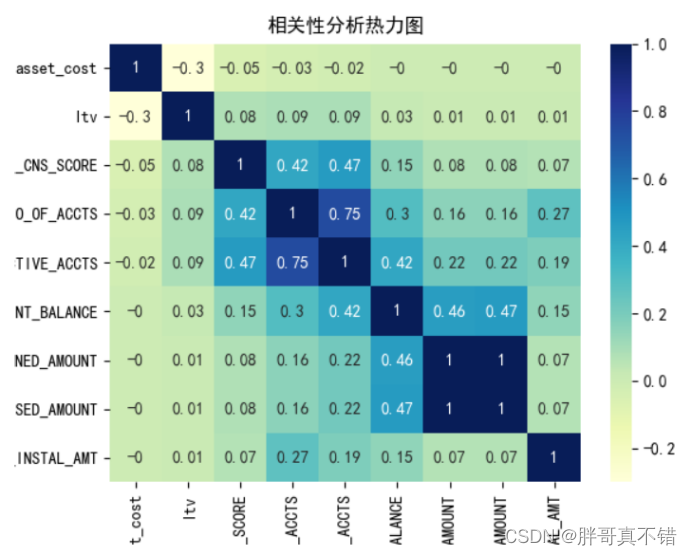
从上图中可以看到,对部分特征进行了相关性分析,数值越大相关性越强,正值是正相关、负值是负相关。
4 . 4 绘制 直方图
用Matplotlib工具的hist()方法绘制直方图:
从上图可以看出,对部分特征进行直方图绘制。
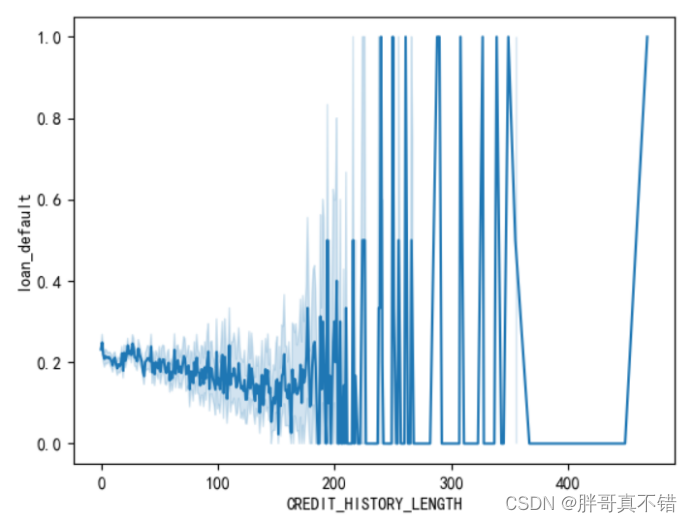
4 . 5 绘制折线图
如下是两个变量和因变量的折线图:
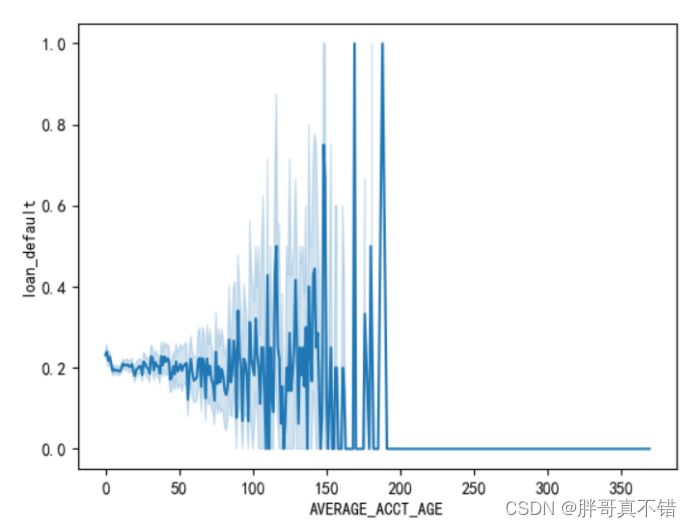
4 . 6 绘制柱状图
4 . 7 绘制散点图
5. 特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5.2 数据均衡化
如下所示,为数据均衡化后的数据:

5. 3 数据标准化
数据标准化关键代码如下:

5. 4 数据集拆分
通过train_test_split()方法按照90%训练集、10%测试集进行划分,关键代码如下:

6. 构建分类模型
主要使用逻辑回归分类算法、决策树分类算法、LightGBM分类算法和XGBoost分类算法,用于目标分类。
6. 1 构建模型
|------------|--------------|------------------|
| 编号 | 模型名称 | 参数 |
| 1 | 逻辑回归分类模型 | 默认参数值 |
| 2 | 决策树分类模型 | 默认参数值 |
| 3 | 决策树分类模型 | random_state=123 |
| 4 | LightGBM分类模型 | 默认参数值 |
| 5 | LightGBM分类模型 | random_state=42 |
| 6 | XGBoost分类模型 | 默认参数值 |
| 7 | XGBoost分类模型 | random_state=42 |
7 . 模型评估
7 .1 评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
|--------------|--------------|-------------|
| 模型名称 | 指标名称 | 指标值 |
| 测试集 |||
| 逻辑回归分类模型 | 准确率 | 0.6642 |
| 逻辑回归分类模型 | 查准率 | 0.6592 |
| 逻辑回归分类模型 | 查全率 | 0.6807 |
| 逻辑回归分类模型 | F1分值 | 0.6698 |
| 决策树分类模型 | 准确率 | 0.7693 |
| 决策树分类模型 | 查准率 | 0.7641 |
| 决策树分类模型 | 查全率 | 0.7795 |
| 决策树分类模型 | F1分值 | 0.7717 |
| LightGBM分类模型 | 准确率 | 0.8498 |
| LightGBM分类模型 | 查准率 | 0.9925 |
| LightGBM分类模型 | 查全率 | 0.705 |
| LightGBM分类模型 | F1分值 | 0.8244 |
| XGBoost分类模型 | 准确率 | 0.8512 |
| XGBoost分类模型 | 查准率 | 0.9879 |
| XGBoost分类模型 | 查全率 | 0.7112 |
| XGBoost分类模型 | F1分值 | 0.827 |
从上表可以看出,LightGBM分类模型和XGBoost分类模型 F1分值分别为0.8244和0.827,说明这2个模型效果较好。
7. 2 分类报告
逻辑回归分类模型:
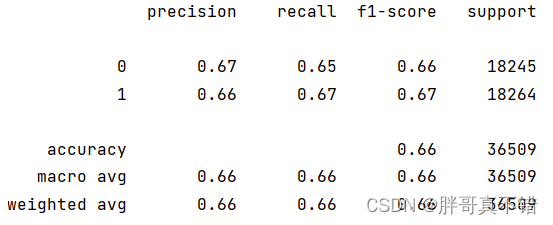
从上图可以看出,分类为0的F1分值为0.66;分类为1的F1分值为0.67。
决策树分类模型:
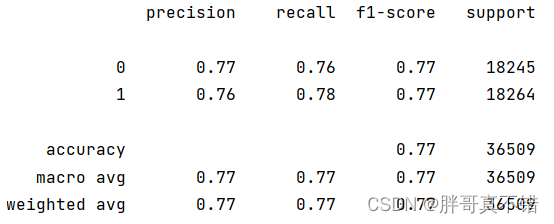
从上图可以看出,分类为0的F1分值为0.77;分类为1的F1分值为0.77。
LightGBM分类模型:
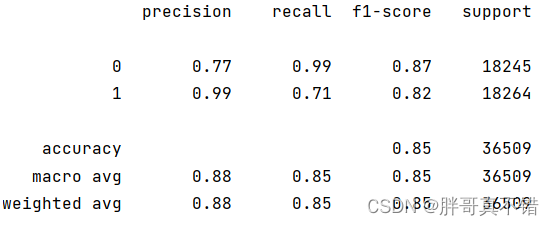
从上图可以看出,分类为0的F1分值为0.87;分类为1的F1分值为0.82。
XGBoost分类模型:
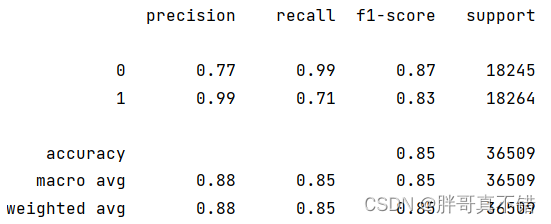
从上图可以看出,分类为0的F1分值为0.87;分类为1的F1分值为0.83。
7. 3 混淆矩阵
逻辑回归分类模型:
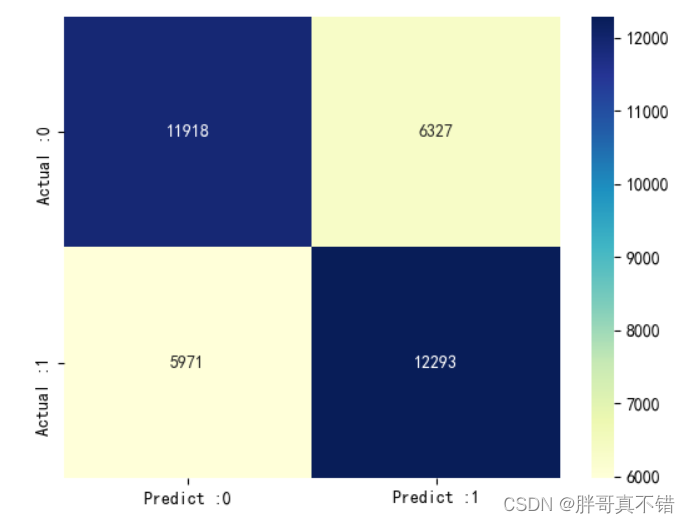
从上图可以看出,实际为0预测不为0的 有6327个样本;实际为1预测不为1的 有5971个样本。
决策树分类模型:
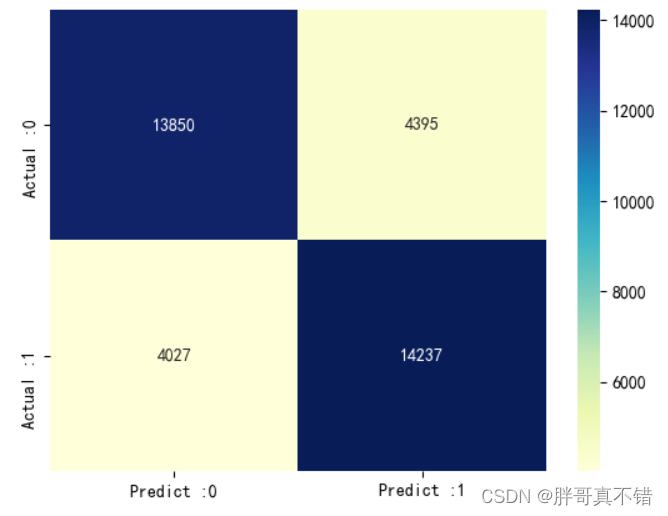
从上图可以看出,实际为0预测不为0的 有4395个样本;实际为1预测不为1的 有4027个样本。
LightGBM分类模型:
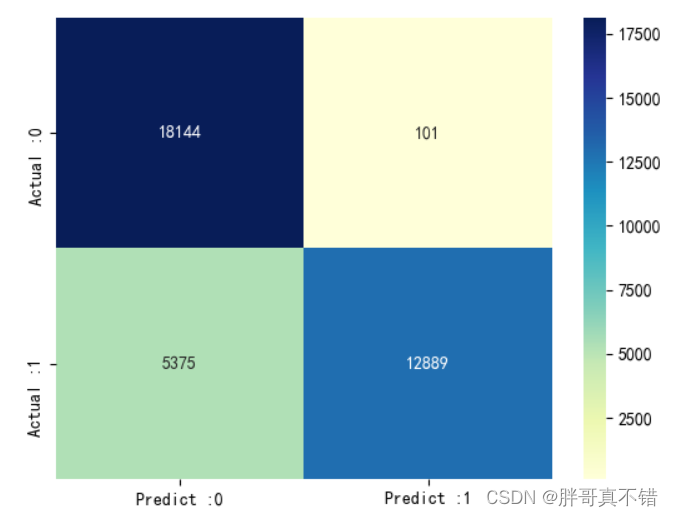
从上图可以看出,实际为0预测不为0的 有101个样本;实际为1预测不为1的 有5375个样本。
XGBoost分类模型:
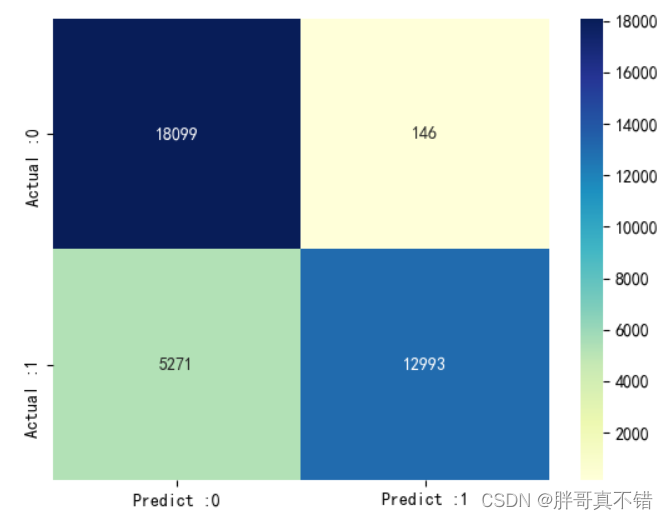
从上图可以看出,实际为0预测不为0的 有146个样本;实际为1预测不为1的 有5271个样本。
7. 4 ROC曲线
逻辑回归分类模型:
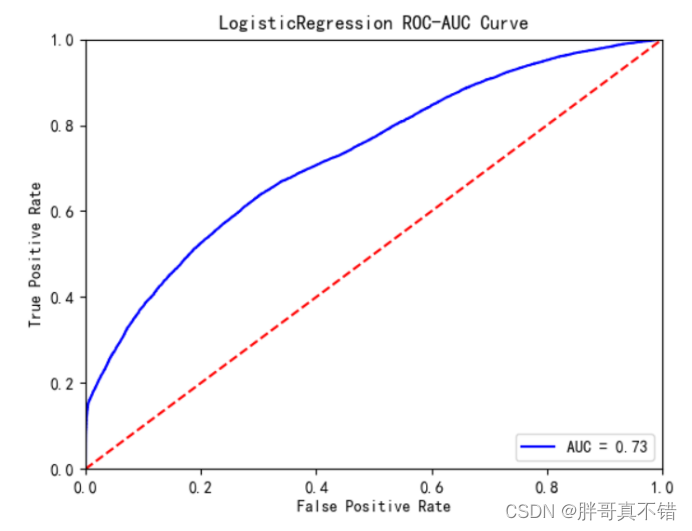
从上图可以看出,逻辑回归分类模型的AUC值为0.73。
决策树分类模型:
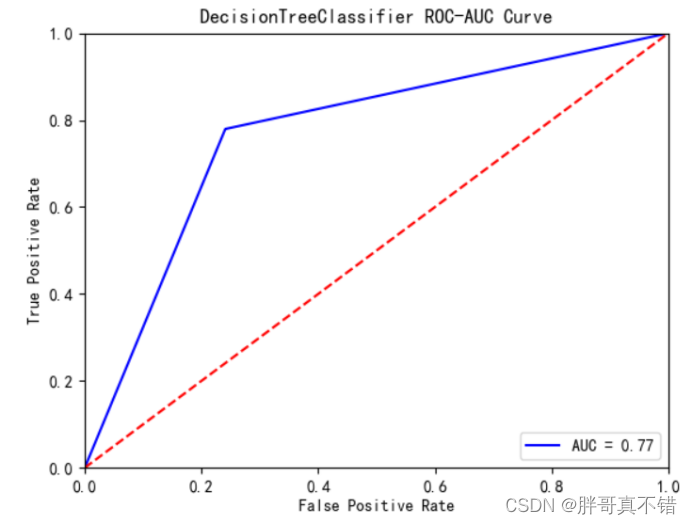
从上图可以看出,决策树分类模型的AUC值为0.77。
LightGBM分类模型:
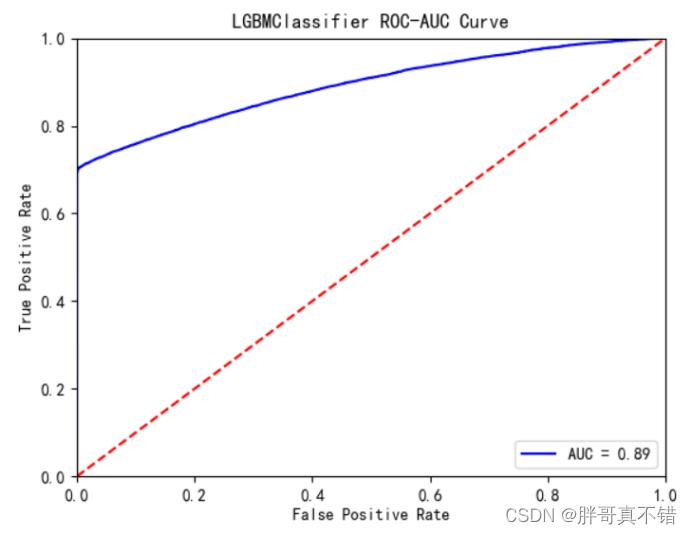
从上图可以看出,LightGBM分类模型的AUC值为0.89。
XGBoost分类模型:
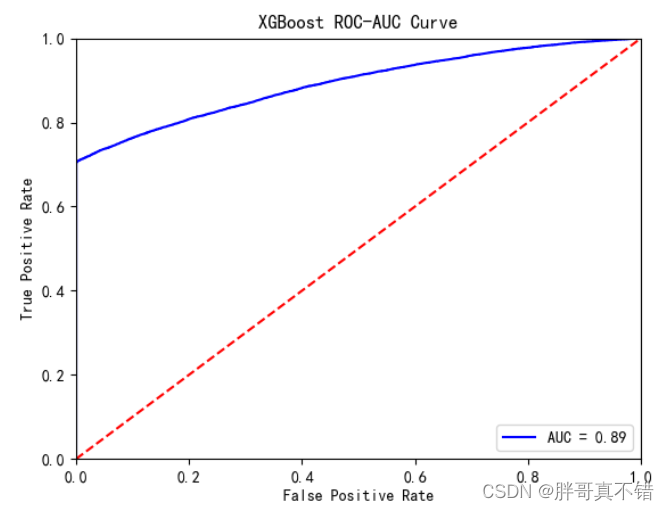
从上图可以看出,XGBoost分类模型的AUC值为0.89。
8. 结论与展望
综上所述,本文采用了逻辑回归、决策树、LightGBM和XGBoost算法来构建分类模型,最终证明了LightGBM和XGBoost模型效果良好。此模型可用于日常产品的预测。
python
# 本次机器学习项目实战所需的资料,项目资源如下:
# 项目说明:
# 获取方式一:
# 项目实战合集导航:
https://docs.qq.com/sheet/DTVd0Y2NNQUlWcmd6?tab=BB08J2
# 获取方式二:
链接:https://pan.baidu.com/s/1SKKxNs2aWQyqe5Yrvp-gdw
提取码:tlvp