前言
在node.js实现语音实时转文字。获取麦克风实时语音转文字。
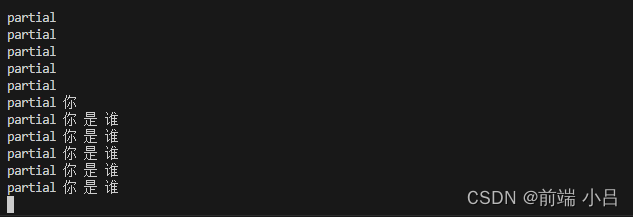
下面是用vosk的效果。注意踩坑要及时评论哦,坑还是挺多的。
在探索后发现本地模型对设备还是有一定要求的,最总无奈采用百度语音识别的方案。
探索结果分享给大家,希望能在项目中提供帮助
deepspeech方案
注意:node 版本14才可运行
npm i deepspeech
npm i node-record-lpcm16
模型资源下载地址
bash
英文模型地址
wget https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deepspeech-0.9.3-models.pbmm
wget https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deepspeech-0.9.3-models.scorer
中文模型地址
wget https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deepspeech-0.9.3-models-zh-CN.pbmm
wget https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deepspeech-0.9.3-models-zh-CN.scorer
js
const DeepSpeech = require("deepspeech");
const record = require("node-record-lpcm16");
const MODEL_PATH = "./deepspeechmodel/deepspeech-0.9.3-models-zh-CN.pbmm"; // 替换为实际模型路径
const SCORER_PATH = "./deepspeechmodel/deepspeech-0.9.3-models-zh-CN.scorer"; // 替换为实际 scorer 文件路径
const SAMPLE_RATE = 16000;
// 加载 DeepSpeech 模型
const model = new DeepSpeech.Model(MODEL_PATH);
model.enableExternalScorer(SCORER_PATH);
const BEAM_WIDTH = 1024;
const LM_ALPHA = 0.75;
const LM_BETA = 1.85;
model.setBeamWidth(BEAM_WIDTH);
model.setScorerAlphaBeta(LM_ALPHA, LM_BETA);
// 开始录音
const mic = record.record({
sampleRateHertz: SAMPLE_RATE,
threshold: 0, // 录音的阈值
verbose: false, // 是否打印详细信息
recordProgram: "sox", // 或 "arecord" 根据你的操作系统选择
});
mic.stream().on("data", (chunk) => {
// 将录音数据转换为模型所需的格式(此处假设数据已经是16位整数,如果是其他格式可能需要转换)
const buffer = Buffer.from(chunk);
// 使用模型的stt方法进行语音识别
const text = model.stt(buffer);
// 打印识别的文字结果
if (text) {
console.log("识别结果:", text);
} else {
console.log("未识别到有效语音");
}
});
mic.stream().on("error", (err) => {
console.error("Error in Input Stream:", err);
});
mic.stream().on("startComplete", () => {
console.log("startComplete =========");
});
mic.stream().on("stopComplete", () => {
console.log("stopComplete =========");
});
mic.start();
process.on("SIGINT", () => {
mic.stop();
process.exit();
});
console.log("监听录音,按Ctrl+C停止.");vosk方案(推荐)
node-record-lpcm16
npm i vosk
中文模型下载地址 https://alphacephei.com/vosk/models
js
const fs = require("fs");
const record = require("node-record-lpcm16");
const vosk = require("vosk");
// 设置模型路径
const MODEL_PATH = "./vosk-model-cn-0.22"; // 替换为你的模型路径
const SAMPLE_RATE = 16000;
// 初始化 Vosk 模型
if (!fs.existsSync(MODEL_PATH)) {
console.error("Model path does not exist.");
process.exit(1);
}
vosk.setLogLevel(0);
const model = new vosk.Model(MODEL_PATH);
// 处理音频数据
const recognizer = new vosk.Recognizer({
model: model,
sampleRate: SAMPLE_RATE,
});
// 开始录音
const mic = record.record({
sampleRateHertz: SAMPLE_RATE,
threshold: 0, // 录音的阈值
verbose: false, // 是否打印详细信息
recordProgram: "sox", // 或 "arecord" 根据你的操作系统选择
});
mic.stream().on("data", (data) => {
if (recognizer.acceptWaveform(data)) {
const result = recognizer.result();
// console.log("结果", JSON.stringify(result, null, 4));
console.log("结果", result.text);
} else {
const partialResult = recognizer.partialResult();
// console.log("partial", JSON.stringify(partialResult, null, 4));
console.log("partial", partialResult.partial);
}
});
mic.stream().on("error", (err) => {
console.error("Error in Input Stream: " + err);
});
mic.stream().on("startComplete", () => {
console.log("Microphone started.");
});
mic.stream().on("stopComplete", () => {
console.log("Microphone stopped.");
});
mic.start();
// 在进程退出时进行清理
process.on("SIGINT", () => {
console.log("Exiting...");
recognizer.free();
model.free();
mic.stop();
process.exit();
});