240622_昇思学习打卡-Day4-5-ResNet50迁移学习
我们对事物的认知都是一点一点积累出来的,往往借助已经认识过的东西,可以更好地理解和认识新的有关联的东西。比如一个人会骑自行车,我们让他去骑摩托车他也很快就能学会,比如已经学会C++,现在让他去学python他也很容易就能理解。这种情况我们一般称为举一反三。反言之,我们从原始部落找出来一个人(仅作举例),指着摩托车让他骑,可能是一件特别难的事,因为他对这个领域没有丝毫的认知和理解,在实现这件事上就会特别困难。
映射到神经网络上也是一样的道理,如果我们在训练时不导入预训练权重,他就像一个没有见过现代社会的原始人,学任何东西都特别慢,学习成本特别高,但如果我们导入了相似模型结构下针对别的任务的训练权重(比如训练识别自行车),用来训练识别摩托车,我们只需要改变网络最后的分类层,即可得到比较好的训练效果,可以大大缩小模型训练的时间。
原理是我在这么多层神经网络的训练下,已经明白了轱辘(车轮)长什么样,把手长什么样,最后的分类层只是区分出来什么是自行车,你现在给我一堆摩托的照片,我就可以去寻找两者的相似处,我对轱辘和把手的认知就不用从0开始重新学习,只需要进行微调,比如摩托车的轱辘比自行车大一点,摩托车的车把手比自行车大一点。基于以前已经学习到的东西,可以大大缩小训练成本。
迁移学习就是这个道理。我们在神经网络技术的发展中,针对不同的任务,不可能每个网络都从0开始训练,那样需要的数据集及成本都是不可承受的。
本文以ResNet50迁移学习为例展开讲解,在MindSpore架构下运行。
文章目录
数据准备
下载数据集
本文用到狗与狼分类数据集,使用download接口下载,也可自行下载放在项目当前目录下
python
from download import download
dataset_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/intermediate/Canidae_data.zip"
download(dataset_url, "./datasets-Canidae", kind="zip", replace=True)数据目录结构如下:
text
text
datasets-Canidae/data/
└── Canidae
├── train
│ ├── dogs
│ └── wolves
└── val
├── dogs
└── wolves首先定义一些超参数:
python
batch_size = 18 # 批量大小
image_size = 224 # 训练图像空间大小
num_epochs = 5 # 训练周期数
lr = 0.001 # 学习率
momentum = 0.9 # 动量
workers = 4 # 并行线程个数加载数据集以及做一些数据增强(本文所用的狼狗数据集属于ImageNet数据集,其典型mean和std值分别为0.485, 0.456, 0.406和0.229, 0.224, 0.225,所以代码中直接使用):
python
# 导入MindSpore库,用于深度学习框架
import mindspore as ms
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
# 定义训练数据集和验证数据集的路径
# 数据集目录路径
data_path_train = "./datasets-Canidae/data/Canidae/train/"
data_path_val = "./datasets-Canidae/data/Canidae/val/"
# 定义函数,用于创建Canidae分类任务的训练集或验证集
# 参数dataset_path: 数据集路径,usage: 数据集的用途,"train"或"val"
# 返回处理后的数据集
# 创建训练数据集
def create_dataset_canidae(dataset_path, usage):
"""数据加载"""
# 初始化ImageFolderDataset,使用多线程并打乱数据顺序
# 使用mindspore.dataset.ImageFolderDataset接口来加载数据集
data_set = ds.ImageFolderDataset(dataset_path,
num_parallel_workers=workers,
shuffle=True,)
# 定义数据预处理的参数
mean = [0.485 * 255, 0.456 * 255, 0.406 * 255]
std = [0.229 * 255, 0.224 * 255, 0.225 * 255]
scale = 32
# 根据数据集的用途(训练或验证)选择不同的数据增强操作
if usage == "train":
# 训练集的数据增强操作,包括随机裁剪、水平翻转、归一化等
# Define map operations for training dataset
trans = [
vision.RandomCropDecodeResize(size=image_size, scale=(0.08, 1.0), ratio=(0.75, 1.333)),
vision.RandomHorizontalFlip(prob=0.5),
vision.Normalize(mean=mean, std=std),
vision.HWC2CHW()
]
else:
# 验证集的数据增强操作,主要包括解码、缩放、中心裁剪、归一化等
# Define map operations for inference dataset
trans = [
vision.Decode(),
vision.Resize(image_size + scale),
vision.CenterCrop(image_size),
vision.Normalize(mean=mean, std=std),
vision.HWC2CHW()
]
# 对数据集应用预处理操作
# 数据映射操作
data_set = data_set.map(
operations=trans,
input_columns='image',
num_parallel_workers=workers)
# 将数据集分批处理,指定批大小
# 批量操作
data_set = data_set.batch(batch_size)
return data_set
# 创建训练数据集和验证数据集,并获取每个数据集的步长(即数据集的大小)
dataset_train = create_dataset_canidae(data_path_train, "train")
step_size_train = dataset_train.get_dataset_size()
dataset_val = create_dataset_canidae(data_path_val, "val")
step_size_val = dataset_val.get_dataset_size()数据集可视化
从mindspore.dataset.ImageFolderDataset接口中加载的训练数据集返回值为字典,用户可通过 create_dict_iterator 接口创建数据迭代器,使用 next 迭代访问数据集。前面 batch_size 设为18,所以使用 next 一次可获取18个图像及标签数据。
python
# 获取训练数据集的第一个批次数据,是18张图像及标签数据。
data = next(dataset_train.create_dict_iterator())
images = data["image"]
labels = data["label"]
print("Tensor of image", images.shape)
print("Labels:", labels)
'''
执行结果为
Tensor of image (18, 3, 224, 224) # 意思是这一批有18张3通道(RGB通道)的长224宽224的图像
Labels: [1 1 0 1 1 0 1 0 0 0 0 0 0 0 0 1 0 1] # 因为该任务是一个二分类任务,所以类别只有简单的0和1
'''目前拿到的数据我们可以先看看长什么样,展示图像及标题,标题为对应的label名称
python
# 导入matplotlib.pyplot库用于绘图
import matplotlib.pyplot as plt
# 导入numpy库用于处理数组
import numpy as np
# 定义一个字典,映射类别编号到类别名称
# class_name对应label,按文件夹字符串从小到大的顺序标记label
class_name = {0: "dogs", 1: "wolves"}
# 创建一个5x5大小的画布
plt.figure(figsize=(5, 5))
# 循环遍历4个图像
for i in range(4):
# 获取当前图像的数据和标签
# 获取图像及其对应的label
data_image = images[i].asnumpy()
data_label = labels[i]
# 将图像数据从HWC格式转换为RGB格式
# 处理图像供展示使用
data_image = np.transpose(data_image, (1, 2, 0))
# 对图像进行预处理,包括归一化和颜色空间转换
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
data_image = std * data_image + mean
data_image = np.clip(data_image, 0, 1)
# 在画布上创建子图,并显示当前图像
# 显示图像
plt.subplot(2, 2, i+1)
plt.imshow(data_image)
# 设置子图标题为图像的类别名称
plt.title(class_name[int(labels[i].asnumpy())])
# 关闭子图的坐标轴显示
plt.axis("off")
# 显示画布上的所有图像
plt.show()
训练模型
本文使用ResNet50模型进行训练,传统的卷积神经网络都是将一系列的卷积层和池化层堆叠得到的,每一层都是从前一层提取特征,所以随着层数增加一般会出现退化等问题。结构比如
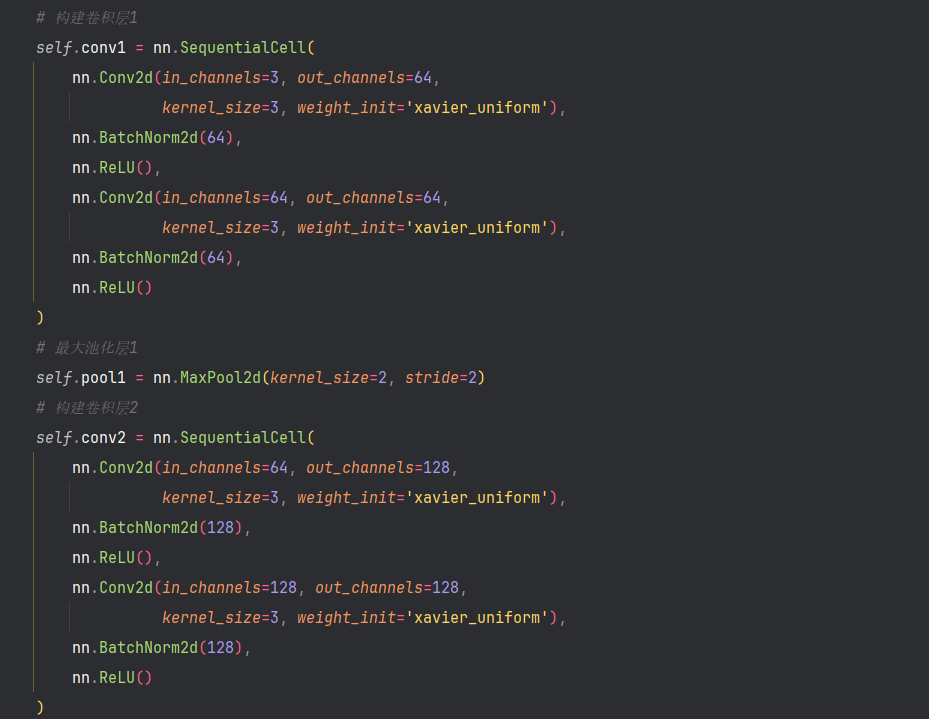
ResNet网络提出了残差网络结构(Residual Network)来减轻退化问题,每一层的输入不仅会传递给下一层,还会通过跳跃连接(skip connection)直接传递给更深的层次。这就涉及到一个残差块的概念:
每个残差块包含两到三个卷积层,以及一个跨层的直接连接,比如
输入x,经过卷积a,卷积b,然后得到一个输出x1,此时不把x1直接给下一层,而是和x统筹学习一下,再交给下一层。
以下是代码示例:
python
from typing import Type, Union, List, Optional
from mindspore import nn, train
from mindspore.common.initializer import Normal
# 初始化卷积层得权重
weight_init = Normal(mean=0, sigma=0.02)
gamma_init = Normal(mean=1, sigma=0.02)
python
class ResidualBlockBase(nn.Cell):
"""
Residual Block基类。
该类定义了残差块的基本结构,包括两个卷积层、批量归一化和激活函数。子类可以通过重写来扩展其功能。
Attributes:
expansion: int,通道扩张率,默认为1,表示输出通道数与输入通道数相等。
"""
expansion: int = 1 # 最后一个卷积核数量与第一个卷积核数量相等
def __init__(self, in_channel: int, out_channel: int,
stride: int = 1, norm: Optional[nn.Cell] = None,
down_sample: Optional[nn.Cell] = None) -> None:
"""
初始化ResidualBlockBase。
参数:
in_channel(int): 输入通道数。
out_channel(int): 输出通道数。
stride(int): 步长,默认为1。
norm(Optional[nn.Cell]): 批量归一化层,默认为None,如果None,则使用默认的批量归一化层。
down_sample(Optional[nn.Cell]): 下采样层,默认为None,如果需要下采样,则通过该参数指定下采样层。
"""
super(ResidualBlockBase, self).__init__()
if not norm:
self.norm = nn.BatchNorm2d(out_channel)
else:
self.norm = norm
self.conv1 = nn.Conv2d(in_channel, out_channel,
kernel_size=3, stride=stride,
weight_init=weight_init)
self.conv2 = nn.Conv2d(in_channel, out_channel,
kernel_size=3, weight_init=weight_init)
self.relu = nn.ReLU()
self.down_sample = down_sample
def construct(self, x):
"""
构建残差块的前向传播。
参数:
x: 输入数据。
返回:
经过残差块处理后的输出数据。
"""
"""ResidualBlockBase construct."""
identity = x # shortcuts分支
out = self.conv1(x) # 主分支第一层:3*3卷积层
out = self.norm(out)
out = self.relu(out)
out = self.conv2(out) # 主分支第二层:3*3卷积层
out = self.norm(out)
if self.down_sample is not None:
identity = self.down_sample(x)
out += identity # 输出为主分支与shortcuts之和
out = self.relu(out)
return out
python
# 定义ResidualBlock类,用于实现残差块
class ResidualBlock(nn.Cell):
# 定义扩张率,用于计算输出通道数
expansion = 4 # 最后一个卷积核的数量是第一个卷积核数量的4倍
# 初始化函数,设置输入通道数、输出通道数、步长和下采样函数
def __init__(self, in_channel: int, out_channel: int,
stride: int = 1, down_sample: Optional[nn.Cell] = None) -> None:
super(ResidualBlock, self).__init__()
# 初始化第一个1x1卷积层,用于减少输入通道数
self.conv1 = nn.Conv2d(in_channel, out_channel,
kernel_size=1, weight_init=weight_init)
# 初始化第一个批量归一化层
self.norm1 = nn.BatchNorm2d(out_channel)
# 初始化第二个3x3卷积层,用于增大特征图尺寸
self.conv2 = nn.Conv2d(out_channel, out_channel,
kernel_size=3, stride=stride,
weight_init=weight_init)
# 初始化第二个批量归一化层
self.norm2 = nn.BatchNorm2d(out_channel)
# 初始化第三个1x1卷积层,用于增加输出通道数
self.conv3 = nn.Conv2d(out_channel, out_channel * self.expansion,
kernel_size=1, weight_init=weight_init)
# 初始化第三个批量归一化层
self.norm3 = nn.BatchNorm2d(out_channel * self.expansion)
# 初始化激活函数为ReLU
self.relu = nn.ReLU()
# 初始化下采样函数,用于当输入和输出尺寸不同时进行下采样
self.down_sample = down_sample
# 构造函数,输入特征图x,输出残差学习后的特征图
def construct(self, x):
# 初始化identity为输入x,用于残差学习
identity = x # shortscuts分支
# 经过第一个卷积层和批量归一化层
out = self.conv1(x) # 主分支第一层:1*1卷积层
out = self.norm1(out)
out = self.relu(out)
# 经过第二个卷积层和批量归一化层
out = self.conv2(out) # 主分支第二层:3*3卷积层
out = self.norm2(out)
out = self.relu(out)
# 经过第三个卷积层和批量归一化层
out = self.conv3(out) # 主分支第三层:1*1卷积层
out = self.norm3(out)
# 如果存在下采样函数,则对输入x进行下采样
if self.down_sample is not None:
identity = self.down_sample(x)
# 将主分支输出和identity相加,实现残差学习
out += identity # 输出为主分支与shortcuts之和
out = self.relu(out)
# 返回残差学习后的特征图
return outmake_layer层就是把多个残差块拼起来
python
def make_layer(last_out_channel, block: Type[Union[ResidualBlockBase, ResidualBlock]],
channel: int, block_nums: int, stride: int = 1):
"""
创建一个由多个残差块组成的层。
该函数根据输入参数构建一个包含指定数量残差块的层。如果当前层的步长不为1或输入通道数与输出通道数不同,
则会添加一个下采样层。下采样层用于将输入特征图的尺寸调整到与残差块输出相同的尺寸,以保持维度匹配。
参数:
last_out_channel: 前一层的输出通道数。
block: 残差块的类型。
channel: 当前层的输出通道数。
block_nums: 本层中残差块的数量。
stride: 当前层的步长,默认为1。
返回:
一个由多个残差块组成的 SequentialCell 实例。
"""
down_sample = None # shortcuts分支
# 当步长不为1或输入输出通道数不一致时,配置下采样层
if stride != 1 or last_out_channel != channel * block.expansion:
down_sample = nn.SequentialCell([
nn.Conv2d(last_out_channel, channel * block.expansion,
kernel_size=1, stride=stride, weight_init=weight_init),
nn.BatchNorm2d(channel * block.expansion, gamma_init=gamma_init)
])
# 初始化第一个残差块,可能包含下采样操作
layers = []
layers.append(block(last_out_channel, channel, stride=stride, down_sample=down_sample))
in_channel = channel * block.expansion
# 堆叠残差网络
for _ in range(1, block_nums):
# 添加剩余的残差块,这些块不包含下采样
layers.append(block(in_channel, channel))
# 将所有残差块组合成一个 SequentialCell 返回
return nn.SequentialCell(layers)定义ResNet网络类
python
from mindspore import load_checkpoint, load_param_into_net
# 定义ResNet网络类
class ResNet(nn.Cell):
"""
ResNet网络结构。
参数:
block: 残差块的类型。这里的Type[Union[ResidualBlockBase, ResidualBlock]]意味着参数block是一个类型
,这个类型是ResidualBlockBase和ResidualBlock这两个类中的任何一个
layer_nums: 每个阶段的残差块数量列表。
num_classes: 分类的类别数。
input_channel: 输入通道数。
"""
def __init__(self, block: Type[Union[ResidualBlockBase, ResidualBlock]],
layer_nums: List[int], num_classes: int, input_channel: int) -> None:
super(ResNet, self).__init__()
self.relu = nn.ReLU()
# 初始化第一个卷积层
# 第一个卷积层,输入channel为3(彩色图像),输出channel为64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, weight_init=weight_init)
self.norm = nn.BatchNorm2d(64)
# 初始化最大池化层
# 最大池化层,缩小图片的尺寸
self.max_pool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode='same')
# 通过make_layer函数构建每个阶段的残差块
# 各个残差网络结构块定义,
self.layer1 = make_layer(64, block, 64, layer_nums[0])
self.layer2 = make_layer(64 * block.expansion, block, 128, layer_nums[1], stride=2)
self.layer3 = make_layer(128 * block.expansion, block, 256, layer_nums[2], stride=2)
self.layer4 = make_layer(256 * block.expansion, block, 512, layer_nums[3], stride=2)
# 初始化全局平均池化层
# 平均池化层
self.avg_pool = nn.AvgPool2d()
# 初始化展平层
# flattern层
self.flatten = nn.Flatten()
# 初始化全连接层
# 全连接层
self.fc = nn.Dense(in_channels=input_channel, out_channels=num_classes)
# 定义前向传播方法
def construct(self, x):
x = self.conv1(x)
x = self.norm(x)
x = self.relu(x)
x = self.max_pool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avg_pool(x)
x = self.flatten(x)
x = self.fc(x)
return x
# 构建并返回指定ResNet模型
def _resnet(model_url: str, block: Type[Union[ResidualBlockBase, ResidualBlock]],
layers: List[int], num_classes: int, pretrained: bool, pretrianed_ckpt: str,
input_channel: int):
"""
根据给定参数构建ResNet模型。
参数:
model_url: 预训练模型的URL。
block: 残差块的类型。
layers: 每个阶段的残差块数量列表。
num_classes: 分类的类别数。
pretrained: 是否使用预训练模型。
pretrianed_ckpt: 预训练模型的文件路径。
input_channel: 输入通道数。
返回:
构建的ResNet模型。
"""
model = ResNet(block, layers, num_classes, input_channel)
if pretrained:
# 下载并加载预训练模型
# 加载预训练模型
download(url=model_url, path=pretrianed_ckpt, replace=True)
param_dict = load_checkpoint(pretrianed_ckpt)
load_param_into_net(model, param_dict)
return model
# 提供ResNet50模型的构造函数
def resnet50(num_classes: int = 1000, pretrained: bool = False):
"""
构建ResNet50模型。
参数:
num_classes: 分类的类别数,默认为1000。
pretrained: 是否使用预训练模型,默认为False。
返回:
构建的ResNet50模型。
"""
"ResNet50模型"
resnet50_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/models/application/resnet50_224_new.ckpt"
resnet50_ckpt = "./LoadPretrainedModel/resnet50_224_new.ckpt"
# 调用_resnet函数构建ResNet50模型
return _resnet(resnet50_url, ResidualBlock, [3, 4, 6, 3], num_classes,
pretrained, resnet50_ckpt, 2048)固定特征进行训练
这里就是因为我们使用的是预训练模型,所以在实际投入训练时需要对模型做一点微调,以适应我们自己的分类需求
使用固定特征进行训练的时候,需要冻结除最后一层之外的所有网络层。通过设置 requires_grad== False 冻结参数,以便不在反向传播中计算梯度。
python
# 导入MindSpore库,用于深度学习模型训练
import mindspore as ms
# 导入matplotlib库,用于数据可视化
import matplotlib.pyplot as plt
# 导入os库,用于操作系统相关功能
import os
# 导入time库,用于时间相关功能
import time
# 初始化ResNet50模型,并使用预训练的权重
net_work = resnet50(pretrained=True)
# 获取全连接层的输入通道数
# 全连接层输入层的大小
in_channels = net_work.fc.in_channels
# 定义新的全连接层,用于分类任务,输出类别数为2
# 输出通道数大小为狼狗分类数2
head = nn.Dense(in_channels, 2)
# 替换原模型的全连接层
# 重置全连接层
net_work.fc = head
# 定义平均池化层,用于对特征图进行全局平均池化
# 平均池化层kernel size为7
avg_pool = nn.AvgPool2d(kernel_size=7)
# 替换原模型的平均池化层
# 重置平均池化层
net_work.avg_pool = avg_pool
# 遍历模型参数,冻结除最后一层外的所有参数的梯度更新
# 冻结除最后一层外的所有参数
for param in net_work.get_parameters():
if param.name not in ["fc.weight", "fc.bias"]:
param.requires_grad = False
# 定义优化器和损失函数
# 定义优化器和损失函数
opt = nn.Momentum(params=net_work.trainable_params(), learning_rate=lr, momentum=0.5)
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
# 定义前向传播函数,用于计算损失
def forward_fn(inputs, targets):
logits = net_work(inputs)
loss = loss_fn(logits, targets)
return loss
# 定义梯度计算函数,用于同时计算损失和梯度
grad_fn = ms.value_and_grad(forward_fn, None, opt.parameters)
# 定义训练步骤函数,用于执行一次训练迭代
def train_step(inputs, targets):
loss, grads = grad_fn(inputs, targets)
opt(grads)
return loss
# 实例化训练模型
# 实例化模型
model1 = train.Model(net_work, loss_fn, opt, metrics={"Accuracy": train.Accuracy()})训练和评估
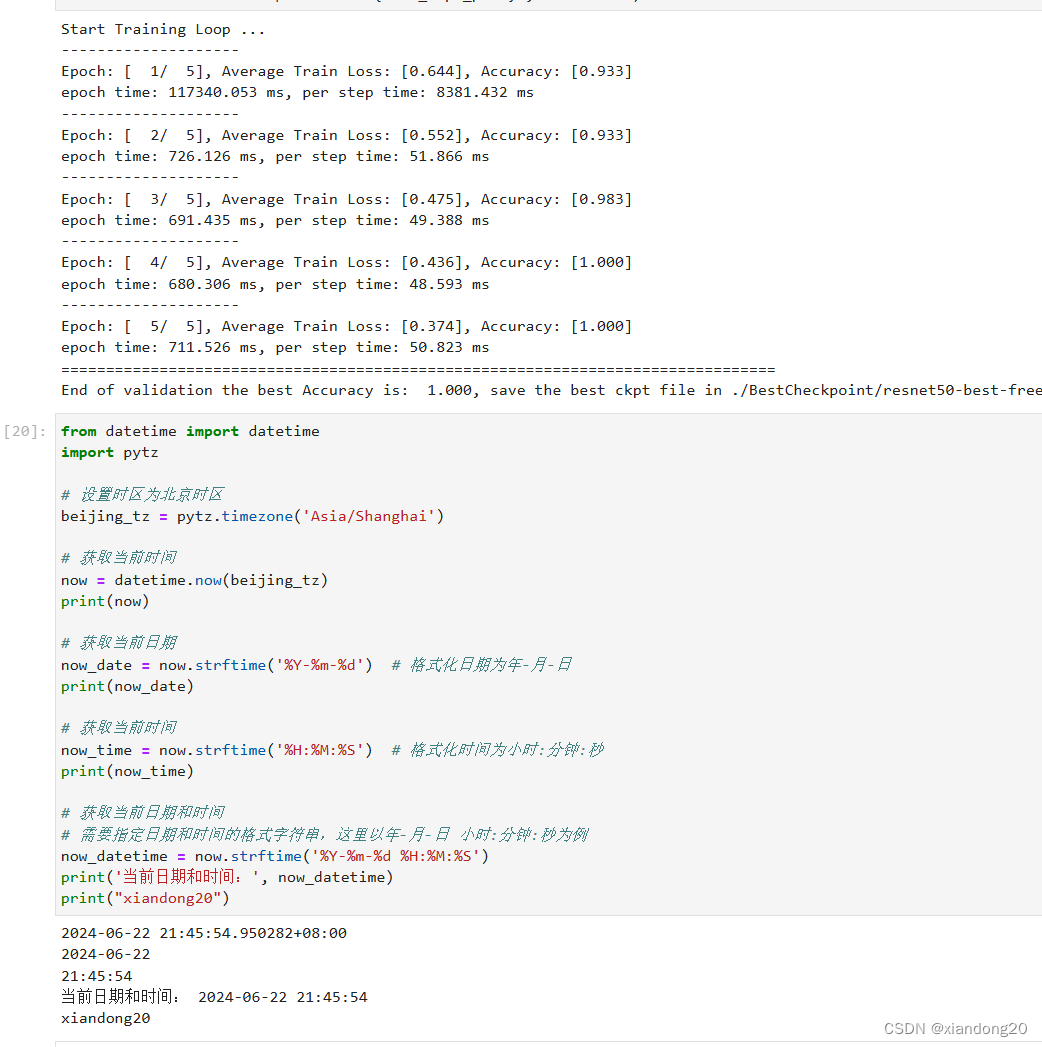
开始训练模型,与没有预训练模型相比,将节约一大半时间,因为此时可以不用计算部分梯度。保存评估精度最高的ckpt文件于当前路径的./BestCheckpoint/resnet50-best-freezing-param.ckpt
python
# 导入MindSpore库,用于构建深度学习模型
import mindspore as ms
# 导入matplotlib库,用于可视化数据
import matplotlib.pyplot as plt
# 导入os库,用于操作文件系统
import os
# 导入time库,用于时间相关的操作
import time
# 加载训练数据集
dataset_train = create_dataset_canidae(data_path_train, "train")
# 获取训练数据集的步长(样本数量)
step_size_train = dataset_train.get_dataset_size()
# 加载验证数据集
dataset_val = create_dataset_canidae(data_path_val, "val")
# 获取验证数据集的步长(样本数量)
step_size_val = dataset_val.get_dataset_size()
# 定义训练的轮数
num_epochs = 5
# 创建训练数据集的迭代器,设置迭代轮数
# 创建迭代器
data_loader_train = dataset_train.create_tuple_iterator(num_epochs=num_epochs)
# 创建验证数据集的迭代器,设置迭代轮数
data_loader_val = dataset_val.create_tuple_iterator(num_epochs=num_epochs)
# 定义最佳模型检查点的保存目录
best_ckpt_dir = "./BestCheckpoint"
# 定义最佳模型检查点的文件路径
best_ckpt_path = "./BestCheckpoint/resnet50-best-freezing-param.ckpt"
python
# 导入mindspore模块,用于构建和训练神经网络
import mindspore as ms
# 导入matplotlib.pyplot,用于绘制图像
import matplotlib.pyplot as plt
# 导入os模块,用于操作文件系统
import os
# 导入time模块,用于测量时间
import time
# 开始循环训练
print("Start Training Loop ...")
# 初始化最佳准确率变量
best_acc = 0
# 遍历每个训练轮次
for epoch in range(num_epochs):
# 初始化训练损失列表
losses = []
# 设置网络为训练模式
net_work.set_train()
# 记录当前epoch的开始时间
epoch_start = time.time()
# 遍历训练数据集
# 为每轮训练读入数据
for i, (images, labels) in enumerate(data_loader_train):
# 将标签转换为int32类型
labels = labels.astype(ms.int32)
# 执行一个训练步骤,计算损失并更新网络参数
loss = train_step(images, labels)
# 将当前步骤的损失添加到损失列表中
losses.append(loss)
# 在验证集上评估模型准确率
# 每个epoch结束后,验证准确率
acc = model1.eval(dataset_val)['Accuracy']
# 记录当前epoch的结束时间
epoch_end = time.time()
# 计算当前epoch的总耗时(毫秒)
epoch_seconds = (epoch_end - epoch_start) * 1000
# 计算平均每个训练步骤的耗时(毫秒)
step_seconds = epoch_seconds / step_size_train
# 打印训练信息,包括epoch号、平均损失、准确率以及训练耗时
print("-" * 20)
print("Epoch: [%3d/%3d], Average Train Loss: [%5.3f], Accuracy: [%5.3f]" % (
epoch + 1, num_epochs, sum(losses) / len(losses), acc
))
# 打印每个步骤的耗时
print("epoch time: %5.3f ms, per step time: %5.3f ms" % (
epoch_seconds, step_seconds
))
# 如果当前epoch的准确率高于之前的最佳准确率,则更新最佳准确率并保存模型参数
if acc > best_acc:
best_acc = acc
# 如果最佳模型保存目录不存在,则创建该目录
if not os.path.exists(best_ckpt_dir):
os.mkdir(best_ckpt_dir)
# 保存模型参数到最佳模型保存路径
ms.save_checkpoint(net_work, best_ckpt_path)
# 打印训练结束信息,包括最佳准确率和保存的模型路径
print("=" * 80)
print(f"End of validation the best Accuracy is: {best_acc: 5.3f}, "
f"save the best ckpt file in {best_ckpt_path}", flush=True)可视化模型预测
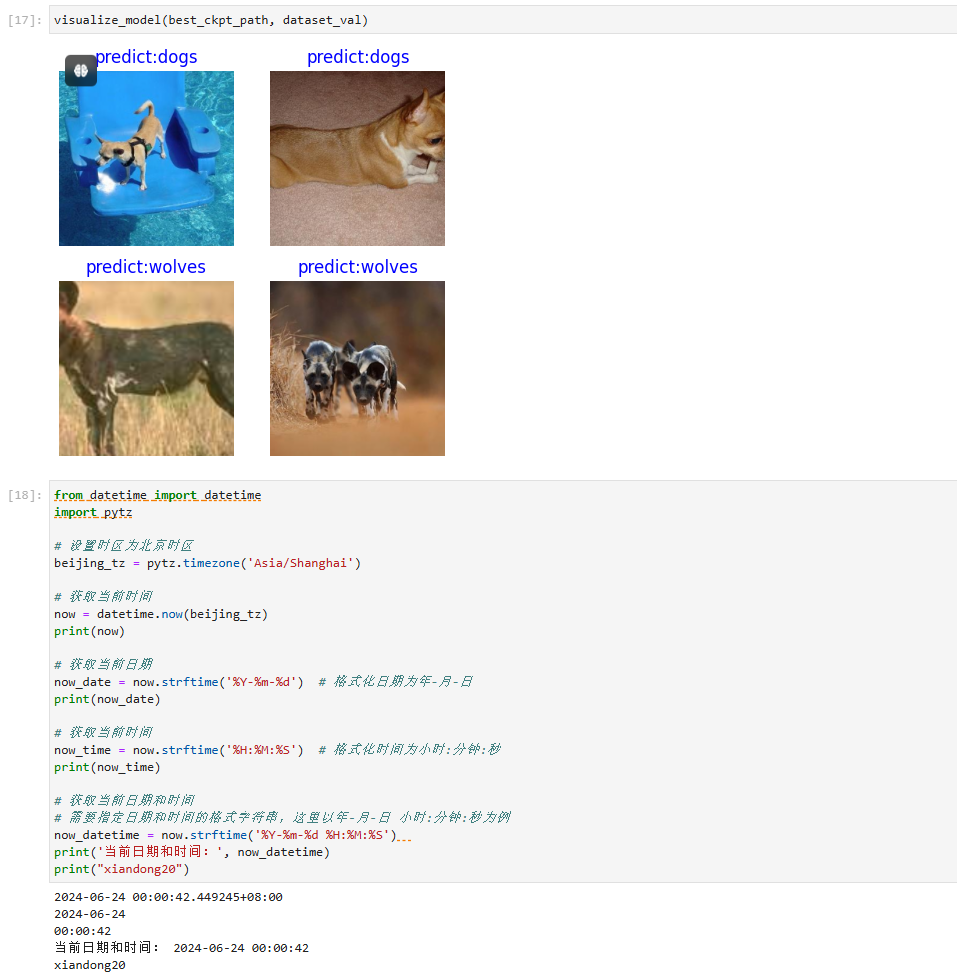
使用固定特征得到的best.ckpt文件对对验证集的狼和狗图像数据进行预测。若预测字体为蓝色即为预测正确,若预测字体为红色则预测错误。这里编写一个方法直接调用
python
# 导入matplotlib.pyplot库用于图像展示
import matplotlib.pyplot as plt
# 导入mindspore库用于深度学习模型训练和加载
import mindspore as ms
def visualize_model(best_ckpt_path, val_ds):
"""
可视化模型预测结果。
参数:
best_ckpt_path: 字符串,最佳模型的检查点文件路径。
val_ds: 数据集对象,用于从中获取验证数据。
返回:
无返回值,直接展示预测结果的图像。
"""
# 加载预训练的resnet50模型
net = resnet50()
# 定义新的分类头部,用于从resnet的输出调整到两个类别的预测
# 全连接层输入层的大小
in_channels = net.fc.in_channels
# 输出通道数大小为狼狗分类数2
head = nn.Dense(in_channels, 2)
# 重置全连接层
net.fc = head
# 调整平均池化层的设置以适应新的输出尺寸
# 平均池化层kernel size为7
avg_pool = nn.AvgPool2d(kernel_size=7)
# 重置平均池化层
net.avg_pool = avg_pool
# 加载最佳模型的参数
# 加载模型参数
param_dict = ms.load_checkpoint(best_ckpt_path)
ms.load_param_into_net(net, param_dict)
# 创建模型对象,用于进行预测
model = train.Model(net)
# 从验证数据集中获取一个批次的数据
# 加载验证集的数据进行验证
data = next(val_ds.create_dict_iterator())
images = data["image"].asnumpy()
labels = data["label"].asnumpy()
# 定义类别名称映射
class_name = {0: "dogs", 1: "wolves"}
# 对数据进行预测
# 预测图像类别
output = model.predict(ms.Tensor(data['image']))
pred = np.argmax(output.asnumpy(), axis=1)
# 展示预测结果
# 显示图像及图像的预测值
plt.figure(figsize=(5, 5))
for i in range(4):
plt.subplot(2, 2, i + 1)
# 根据预测结果和真实标签设置标题颜色
# 若预测正确,显示为蓝色;若预测错误,显示为红色
color = 'blue' if pred[i] == labels[i] else 'red'
plt.title('predict:{}'.format(class_name[pred[i]]), color=color)
# 调整图像颜色空间并展示
picture_show = np.transpose(images[i], (1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
picture_show = std * picture_show + mean
picture_show = np.clip(picture_show, 0, 1)
plt.imshow(picture_show)
plt.axis('off')
plt.show()
python
# 调用预测可视化方法
visualize_model(best_ckpt_path, dataset_val)效果:

打卡图片(因内容较多,分两天打卡):