近日,小编看到一篇关于大普微在6月刚刚发表的CXL技术方案论文,名为《LMB: Augmenting PCIe Devices with CXL-Linked Memory Buffer》,论文深度探讨了现代数据中心中关键PCIe设备如SSD、GPU面临的板载DRAM短缺问题,并提出了一种创新解决方案------Linked Memory Buffer (LMB),该方案利用Compute Express Link (CXL)内存扩展器技术有效应对这一挑战。

本文小编将结合论文内容进行学习解读,以供各位读者参考!由于水平有限,如有错误之处,欢迎在本文底部留言或者私信交流,感谢支持!
扩展阅读:
在大数据检索、人工智能和近数据处理等应用场景中,SSD、GPU和DPU等PCIe设备发挥着核心作用。然而,这些高性能设备受限于内部空间,难以搭载足够的DRAM以满足日益增长的数据处理需求。特别是对于高密度QLC SSD,由于DRAM不足,被迫采用更大的页大小,导致写放大效应加剧。同时,KV-SSD的索引效率因内存不足而受限,影响其广泛应用;内存语义SSD的研发进一步加剧了内存短缺问题。此外,大型AI模型所需的GPU DRAM超出板载容量,迫使依赖外部SSD存储,牺牲了性能。因此,如何高效补充板载DRAM成为亟待解决的问题。
在现有的SSD设计架构下,没有更多空间来增加DDR(DRAM)内存。这里提到的"旅馆"(Inn)是一种形象化的比喻,用来描述SSD内部空间有限,如同旅馆房间已满,无法再接纳更多的住客(即DDR内存模块)一样。
具体来说,SSD的结构限制在于以下几个方面:
-
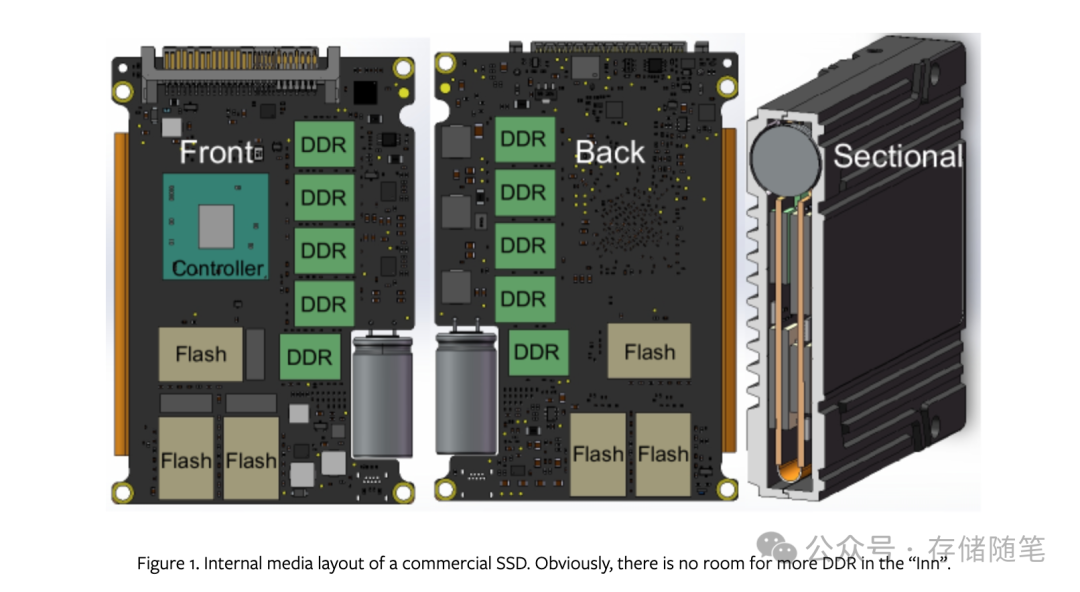
空间约束:SSD的物理设计要求DRAM必须紧邻SSD控制器放置,类似于服务器内存需要靠近CPU插槽以减少延迟。这种布局上的限制意味着,随着SSD内其他组件(如闪存芯片)的增加,用于安置DRAM的空间变得非常紧张。图1通过直观展示说明了这一点,可以看到在SSD的前后板设计中,四周靠近控制器的位置已经被各种组件占据,几乎没有多余空间可以用来安装额外的DRAM模块。
-
标准配置限制:企业级SSD通常遵循一个标准配置,即为4KB页面映射分配的DRAM仅占总容量的0.1%。主流DRAM技术的限制进一步加剧了这一问题,导致SSD内部内存容量上限大约为32GB。然而,随着QLC技术的应用,单个U.2规格的SSD就能提供超过32TB的存储空间,这之间的巨大差距使得板载DRAM成为了瓶颈。
-
DRAM与闪存密度不匹配:DRAM的密度增长速度落后于闪存,这意味着即便有技术手段能够克服物理空间的限制,DRAM的增加也无法与快速扩增的闪存容量保持同步,进一步加剧了SSD内部DRAM不足的问题。
-
性能与成本考量:由于DRAM成本较高,且对提高SSD性能至关重要(比如用于缓存和映射表),因此即使有空间添加更多DRAM,也可能因为成本效益比不高而不被采纳。
因为基于当前SSD设计中DRAM扩展的物理局限性,突出了在不重新设计SSD架构或采用新技术的情况下,无法简单增加DRAM来提升性能或存储效率的问题 。这也正是引入如CXL(Compute Express Link)内存扩展器技术的LMB(Linked Memory Buffer)方案的意义所在,它通过外部连接的方式,绕过了SSD内部空间的限制,有效扩大了可用的DRAM资源,从而解决了板载DRAM短缺的难题。
在面对SSD板载DRAM短缺问题时,研究人员和工程师们已经探索了多种策略和技术来应对和缓解这一挑战。
-
Flash支持的二级索引:一种方法是将索引迁移到NAND闪存中,例如,基于需求的FTL(DFTL)在DRAM中缓存频繁使用的逻辑到物理(L2P)映射条目,而将剩余索引保留在闪存中。空间局部感知FTL(SFTL)利用严格顺序访问的局部特性来压缩L2P条目。这些方法由于闪存与DRAM之间的延迟差异,容易导致性能下降。
-
使用主机内存缓冲区(HMB)补充设备内存 :NVMe 1.2标准允许通过PCIe的DMA功能利用主机DRAM增强SSD内存。对于移动应用中的L2P索引受限于SRAM性能退化的情况,主机性能增强器(HPB)将L2P条目放入主机内存中。然而,HMB方案对主机内存的扩展性构成挑战,仅适用于DRAM需求不大的场景。(探究NVMe SSD HMB应用场景与影响)
-
减少索引占用空间:随着高密度QLC SSD的普及,对更大板载DRAM的需求增加,以支持更精细的L2P映射表。比如QLC SSD通过引入16KB间接单元(IU)粗粒度映射表来降低DRAM消耗,但这种方法可能导致读改写和写放大问题。LeaFTL通过分段线性回归最小化LPA-PPA映射的索引内存开销,但在处理随机写入时存在问题,且DRAM减小效果无法保证。(SSD寻址单元IU对寿命的影响有多大?)
-
键值和内存语义SSD:虽然KV-SSD等方案优化了系统性能和软件效率,但面临DRAM开销过大的挑战。内存语义SSD结合了成本效益高的字节寻址DRAM和SSD,用作CPU可访问的缓存,但受限于DRAM容量和缓存命中率,未命中的情况会导致延迟问题。
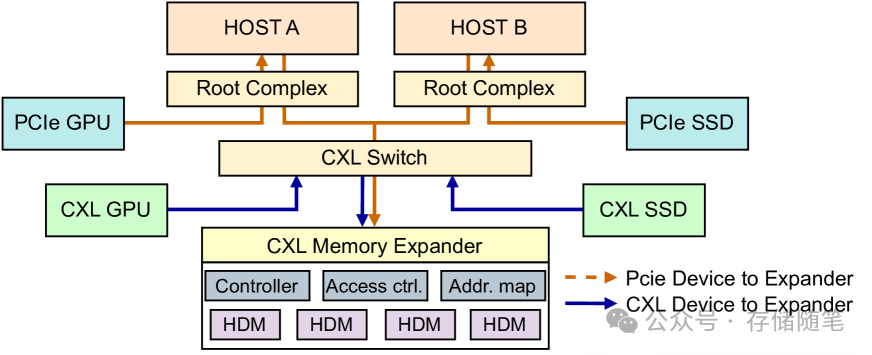
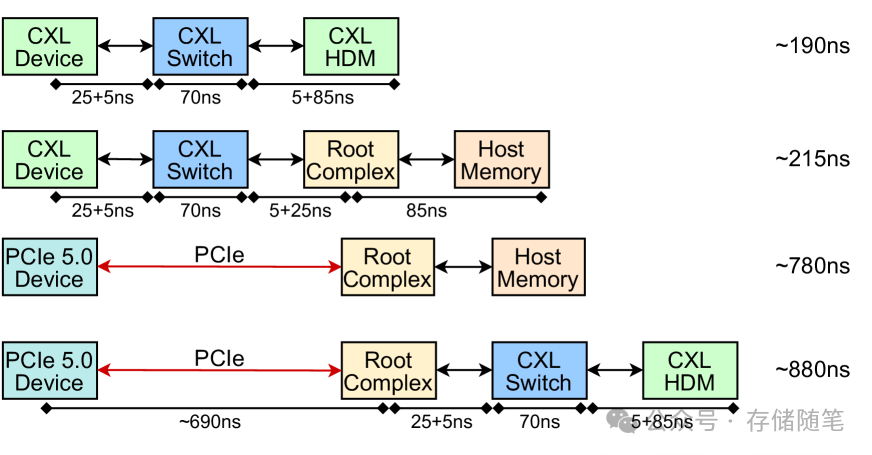
CXL被提出用于解决主机内存扩展性限制,通过PCIe构建了分散式内存,克服了CPU内存通道和DIMM插槽的限制。CXL的可扩展性和分散性内存架构不仅可用于增强NVMe HMB,还能扩展统一内存基础设施。CXL支持高效互联,允许设备通过直接P2P访问绕过主机,减少了数据访问延迟,下图展示了相关估计延迟,CXL在缩短延迟方面显示出了巨大潜力,对于跨越内存障碍具有重要意义。
CXL技术为Host-to-Device和Device-to-Device的高效互联提供了基础。其工作原理如下:
-
Port Based Routing (PBR) ID获取:CXL允许主机或设备通过连接到基于CXL的PBR交换机的Edge Port来获取PBR ID。这个过程简化了设备间的直接通信路径设置,提升了数据传输效率。PBR机制使得设备能够直接定位和访问网络中的目标资源,无需经过复杂的路由查找。
-
访问Global Fabric-Attached Memory (GFAM):一旦获得PBR ID,设备就可以直接访问GFAM。GFAM是一种超越传统主机内存界限的分布式内存架构,它通过CXL协议打破了CPU内存通道和DIMM插槽的局限。这意味着设备能够利用全局范围的内存资源,而不受制于单一主机的内存限制,从而显著扩展了可用内存容量,减轻了主机应用程序对设备内存的干扰,并促进了由设备驱动的性能提升。
-
Direct Peer-to-Peer (P2P) 通信 :CXL的一个关键特性是支持设备间的直接P2P通信(浅析CXL P2P DMA加速数据传输的原理)。这使得CXL设备能够在无需主机介入的情况下,通过交换机内的快捷路径直接相互通信。这种直接互联模式减少了数据传输的延迟,提高了设备间数据交换的效率,特别适合于那些需要频繁高速数据交换的应用场景,如GPU之间的协作运算。(浅析英伟达GPU NCCL P2P与共享内存)
-
延迟性能:CXL技术在延迟性能上表现出色,其中CXL端口本身的延迟仅为25纳秒,即使是通过PBR交换机的延迟也控制在70纳秒(包括访问Host-Managed Device Memory, HDM的时间)。相比之下,使用PCIe 5.0接口的设备访问主机内存的延迟则高达780纳秒。
综合以上特点,CXL为克服内存瓶颈提供了强大的解决方案。它不仅通过扩展的内存资源池和高效的互联机制提升了系统整体的内存容量和访问效率,还通过减少数据传输延迟,为高性能计算、大数据处理、人工智能等对内存和数据传输速度有极高要求的应用提供了强有力的支持。因此,CXL技术有望成为未来数据中心和高性能计算架构中解决内存扩展和数据交互难题的关键技术。
LMB(Linked Memory Buffer)面临诸多挑战,这些问题在内存管理、资源优化、资源共享隔离、访问控制、跨设备迁移以及数据安全等方面尤为突出,对于构建稳定、高效且可靠的内存扩展方案至关重要。下面是对这些挑战的详细解析:
-
动态内存分配:LMB需要设计一个灵活的机制,能够在运行时根据不同的应用需求动态地分配内存。这要求系统能够快速响应内存需求变化,同时避免碎片化,确保内存的有效利用。
-
资源优化:优化内存使用是另一个挑战,特别是在有限的资源条件下,如何最大化内存利用率,减少浪费,同时保持良好的性能,是LMB设计的关键。
-
共享资源隔离:在多设备共享CXL内存扩展器提供的内存时,如何保证不同设备间的数据隔离,防止数据混淆,是一个复杂的任务。这要求有严格的访问控制机制和数据隔离策略。
-
访问控制:有效地管理内存访问权限,确保只有授权的设备或进程能够读写特定的内存区域,是保障系统安全和稳定性的基本要求。
-
跨设备迁移:在不同设备之间移动数据时,如何高效地进行内存数据迁移,同时最小化对系统性能的影响,是实现资源灵活调度的关键问题。
-
数据安全与单点故障:内存扩展器作为所有设备共享的资源,其稳定性直接影响整个系统的可靠性。任何单点故障都可能导致所有依赖于它的设备不可用,因此需要采取措施确保数据安全并减少单点故障的风险。
为了解决以上挑战,LMB提出了基于CXL协议的内存扩展框架和内核模块 。该方案利用CXL内存扩展器作为物理DRAM源,旨在提供一个统一的内存分配接口,使PCIe和CXL设备都能方便地访问扩展的内存资源。通过这个接口,NVMe驱动和CUDA的统一内存内核驱动可以直接高效地访问CXL内存扩展器,让SSD和GPU设备能够像使用板载内存一样轻松地利用LMB提供的内存资源。这一设计旨在消除内存短缺问题,同时保持高性能和灵活性,是解决现代高性能计算和数据中心内存需求增长的有效途径。