Kafka_深入探秘者(3):kafka 消费者
一、kafka 消费者、消费组
1、Kafka 消费者是消费组的一部分,当多个消费者形成一个消费组来消费主题时,每个消费者会收到不同分区的消息。假设有一个 T1 主题,该主题有4个分区;同时我们有一个消费组 G1,这个消费组只有一个消费者 C1。那么消费者 C1 将会收到这 4 个分区的消息,如下所示:
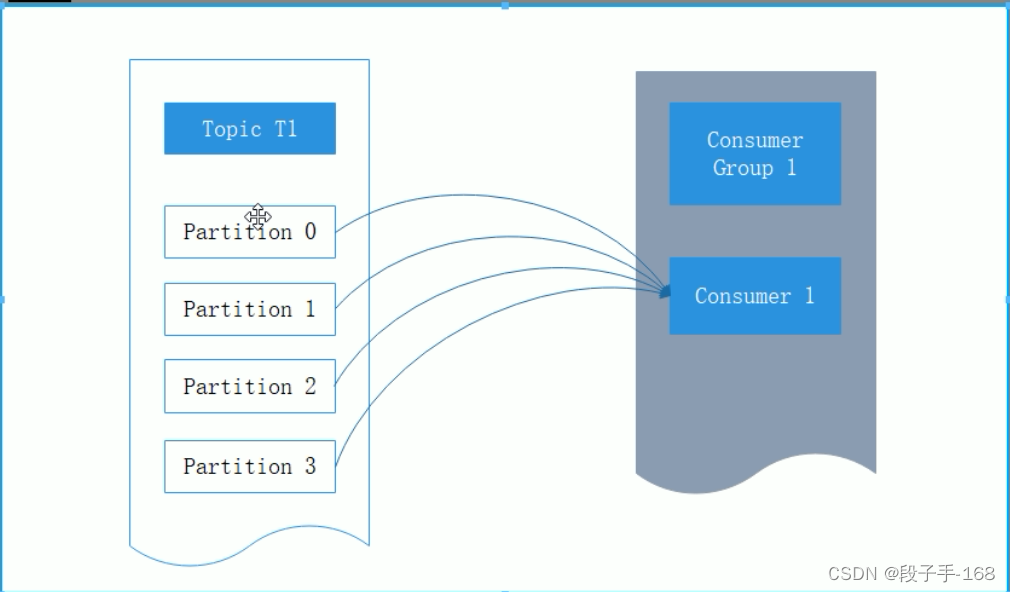
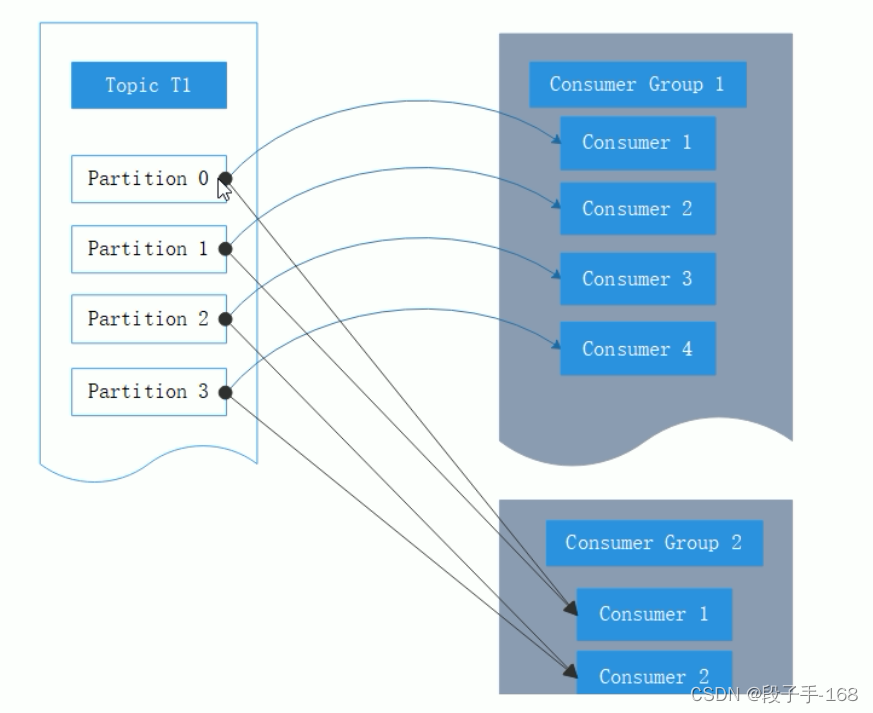
2、Kafka 一个很重要的特性就是,只需写入一次消息,可以支持任意多的应用读取这个消息。换句话说,每个应用都可以读到全量的消息。为了使得每个应用都能读到全量消息,应用需要有不同的消费组。
对于上面的例子,假如我们新增了一个新的消费组G2,而这个消费组有两个消费者,那么会是这样的:
二、kafka 消息接收参数设置
1、kafka 消息接收 必要参数设置
- 1)(生产者 和 消费者的 key , value 保持一致)
- 2)制定连接 Kafka 集群所需的 broker 地址清单,可以设置一个或者多个的名称,生产者 和 消费者的 bootstrap 保持一致。
- 3)消费者隶属于的消费组 group.id,默认为空,如果设置为空,则会抛出异常,这个参数要设置成具有一定业务含义。
- 4)指定 Kafkaconsumer 对应的客户端 client.id,默认为空,如果不设置 Kafkaconsumer 会自动生成一个非空字符串。
2、示例代码:
java
public static Properties initconfig(){
Properties props =new Properties();
//1)与 KafkaProducer 中设置保持一致(生产乾消费者保持一致)
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.stringDeserializer");
//2)必填参数,该参数和 KafkaProducer 中的相同,制定连接 Kafka 集群所需的 broker 地址清单,可以设置一个或者多个的名称
props.put("bootstrap.servers",brokerList);
//3)消费者隶属于的消费组,默认为空,如果设置为空,则会抛出异常,这个参数要设置成具有一定业务含义
props.put("group.id",groupId);
//4)指定 Kafkaconsumer 对应的客户端 ID,默认为空,如果不设置 Kafkaconsumer 会自动生成一个非空字符串
props.put("client.id","consumer.client.id.demo");
return props;
}三、kafka 订阅主题和分区
1、kafka 订阅主题和分区
创建完消费者后我们便可以订阅主题了,只需要通过调用 subscribe() 方法即可,这个方法接收一个主题列表
java
KafkaConsumer<String, String>consumer = new Kafkaconsumer<>(props);
consumer.subscribe(Arrays.asList(topic));2、另外,我们也可以使用正则表达式来匹配多个主题,而且订阅之后如果又有匹配的新主题,那么这个消费组会立即对其进行消费。正则表达式在连接 Kafka 与其他系统时非常有用。比如订阅所有的测试主题:
java
//订阅所有以 heima 开头的主题
consumer.subscribe(Pattern.compile("heima*"));3、指定订阅的分区
java
//指定订阅的分区
consumer.assign(Arrays.asList(new TopicPartition("topic",0)));4、kafka 反序列化
java
//与 KafkaProducer 中设置保持一致(生产者消费者保持一致)
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");四、kafka 重复消费、消息丢失
1、位移提交
对于 Kafka 中的分区而言,它的每条消息都有唯一的 offset,用来表示消息在分区中的位置。
当我们调用 poll() 时,该方法会返回我们没有消费的消息。当消息从 broker 返回消费者时,broker 并不跟踪这些消息是否被消费者接收到; Kafka 让消费者自身来管理消费的位移,并向消费者提供更新位移的接口,这种更新位移方式称为提交 (commit)。
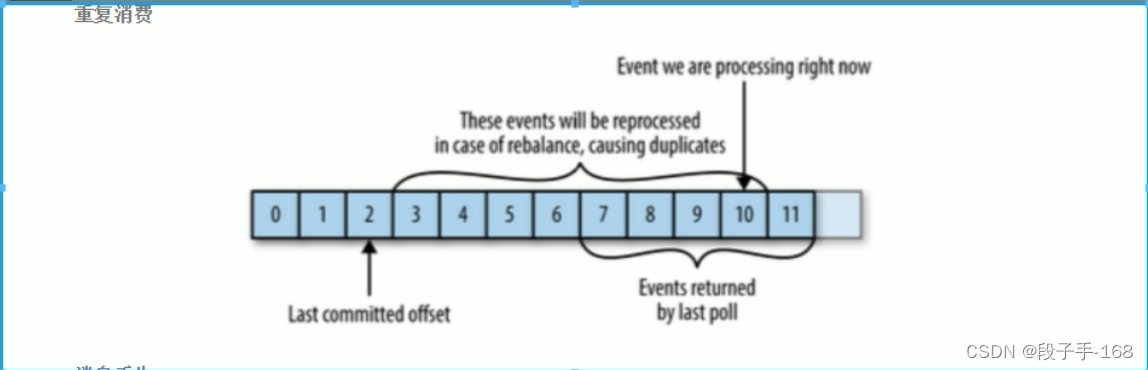
2、kafka 消息 重复消费
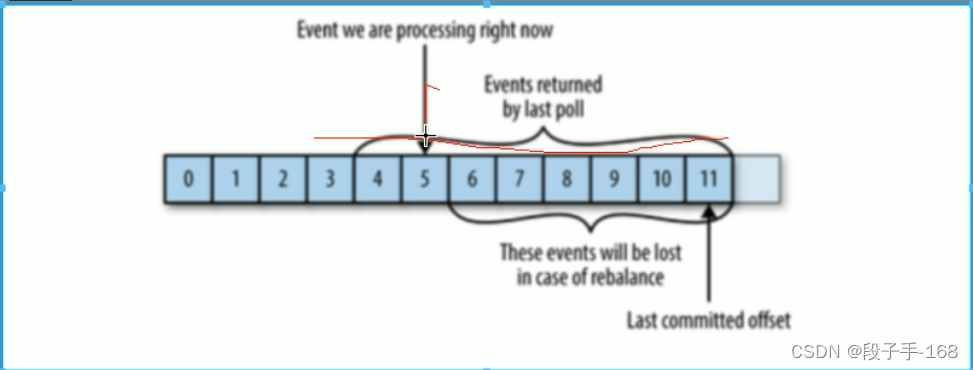
3、kafka 消息丢失
五、kafka 同步、异步提交
1、kafka 消息 自动提交
这种方式让消费者来管理位移,应用本身不需要显式操作。当我们将 enable.auto.commit 设置为 true,那么消费者会在 poll 方法调用后每隔 5 秒 (由 auto.commit.interval.ms 指定) 提交一次位移。和很多其他操作一样,自动提交也是由 poll() 方法来驱动的;在调用 poll() 时,消费者判断是否到达提交时间,如果是则提交上一次 poll 返回的最大位移。
需要注意到,这种方式可能会导致消息重复消费。假如,某个消费者 poll 消息后,应用正在处理消息,在 3 秒后 Kafka 进行了重平衡,那么由于没有更新位移导致重平衡后这部分消息重复消费。
2、kafka 消息 同步提交
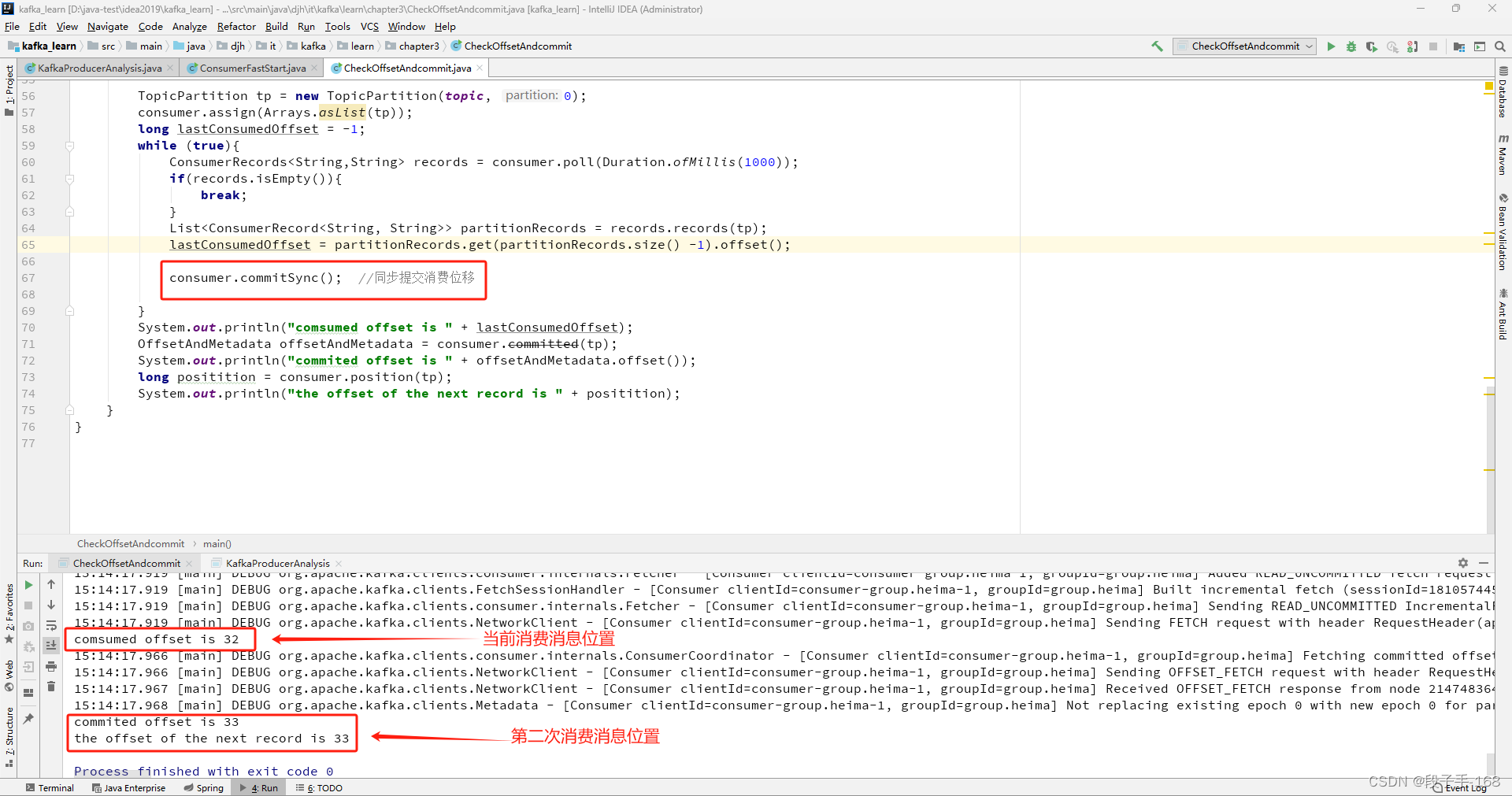
在 kafka_learn 工程中,创建 CheckOffsetAndcommit.java 类,进行 同步提交 测试。
java
/**
* kafka_learn\src\main\java\djh\it\kafka\learn\chapter3\CheckOffsetAndcommit.java
*
* 2024-6-22 创建 CheckOffsetAndcommit.java 类 测试同步提交
*/
package djh.it.kafka.learn.chapter3;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class CheckOffsetAndcommit {
//private static final String brokerList = "localhost:9092";
private static final String brokerList = "172.18.30.110:9092";
private static final String topic = "heima";
private static final String groupId = "group.heima";
private static AtomicBoolean running = new AtomicBoolean(true);
public static Properties initConfig() {
Properties properties = new Properties();
//1)设置 key 序列化器 -- 优化代码
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//3)设置值序列化器 -- 优化代码
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//4)设置集群地址 -- 优化代码
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
properties.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 手动提交开启
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
return properties;
}
public static void main( String[] args ) {
Properties props = initConfig();
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
TopicPartition tp = new TopicPartition(topic, 0);
consumer.assign(Arrays.asList(tp));
long lastConsumedOffset = -1;
while (true){
ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(1000));
if(records.isEmpty()){
break;
}
List<ConsumerRecord<String, String>> partitionRecords = records.records(tp);
lastConsumedOffset = partitionRecords.get(partitionRecords.size() -1).offset();
consumer.commitSync(); //同步提交消费位移
}
System.out.println("comsumed offset is " + lastConsumedOffset);
OffsetAndMetadata offsetAndMetadata = consumer.committed(tp);
System.out.println("commited offset is " + offsetAndMetadata.offset());
long positition = consumer.position(tp);
System.out.println("the offset of the next record is " + positition);
}
}
3、kafka 消息 异步提交
手动提交有一个缺点,那就是当发起提交调用时应用会阻塞。当然我们可以减少手动提交的频率,但这个会增加消息重复的概率(和自动提交一样)。另外一个解决办法是,使用异步提交的 API。
但是异步提交也有个缺点,那就是如果服务器返回提交失败,异步提交不会进行重试。相比较起来,同步提交会进行重试直到成功或者最后抛出异常给应用。异步提交没有实现重试是因为,如果同时存在多个异步提交,进行重试可能会导致位移覆盖。
举个例子,假如我们发起了一个异步提交 commitA,此时的提交位移为 2000,随后又发起了一个异步提交 commitB 且位移为 3000; commitA 提交失败但 commitB 提交成功,此时 commitA 进行重试并成功的话,会将实际上将已经提交的位移从 3000 回滚到 2000,导致消息重复消费。
六、kafka 指定位移消费
1、kafka 指定位移消费
消息的拉取是根据 poll() 方法中的逻辑来处理的,但是这个方法对于普通开发人员来说就是个黑盒处理,无法精确掌握其消费的起始位置。
seek() 方法正好提供了这个功能,让我们得以追踪以前的消费或者回溯消费,
2、在 kafka_learn 工程中,创建 SeekDemo.java 类,进行 指定位移消费 测试。
java
/**
* D:\java-test\idea2019\kafka_learn\src\main\java\djh\it\kafka\learn\chapter3\SeekDemo.java
*
* 2024-6-22 创建 SeekDemo.java 类,进行 指定位移消费 测试。
*/
package djh.it.kafka.learn.chapter3;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
import java.util.Set;
public class SeekDemo extends ConsumerClientConfig{
public static void main(String[] args){
Properties props = initConfig();
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
//timeout参数设置多少合适?太短会使分区分配失败,太长又有可能造成一些不必要的等待
consumer.poll(Duration.ofMillis(2000));
//获取消费者所分配到的分区
Set<TopicPartition> assignment= consumer.assignment();
System.out.println(assignment);
for(TopicPartition tp : assignment){
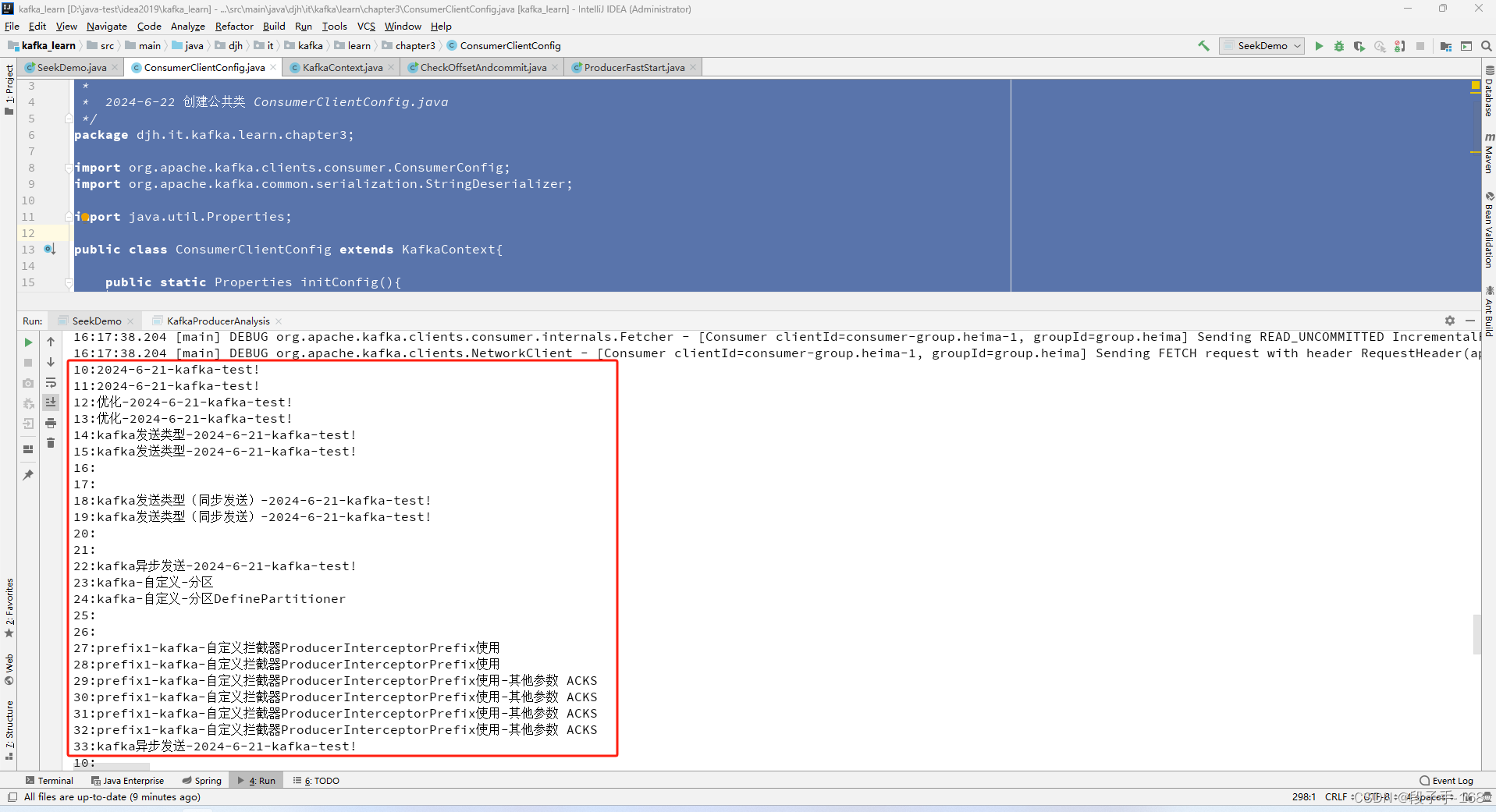
//参数partition表示分区,offset表示指定从分区的哪个位置开始消费
consumer.seek(tp,10);
}
//consumer.seek(new TopicPartition(topic,0), 10);
while(true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
//consume the record.
for(ConsumerRecord<String, String> record :records){
System.out.println(record.offset()+ ":" + record.value());
}
}
}
}3、在 kafka_learn 工程中,创建 公共类 KafkaContext.java
java
/**
* D:\java-test\idea2019\kafka_learn\src\main\java\djh\it\kafka\learn\chapter3\KafkaContext.java
*
* 2024-6-22 创建公共类 KafkaContext.java
*/
package djh.it.kafka.learn.chapter3;
public class KafkaContext {
// 172.18.30.110:9092 填写你自己的 虚拟机 IP 地址和端口号
public static String brokerList = "172.18.30.110:9092";
public static String topic = "heima";
public static String groupId = "group.heima";
}4、在 kafka_learn 工程中,创建 公共类 ConsumerClientConfig.java
java
/**
* kafka_learn\src\main\java\djh\it\kafka\learn\chapter3\ConsumerClientConfig.java
*
* 2024-6-22 创建公共类 ConsumerClientConfig.java
*/
package djh.it.kafka.learn.chapter3;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Properties;
public class ConsumerClientConfig extends KafkaContext{
public static Properties initConfig(){
Properties props = new Properties();
//1)设置 key 序列化器 -- 优化代码
//properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//2)设置值序列化器 -- 优化代码
//properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//3)设置集群地址 -- 优化代码
//properties.put("bootstrap.servers", brokerList);
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
//4)消费组
//properties.put("group.id", groupId);
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
//kafka 消费者找不到消费的位移时,从什么位置开始消费,默认:latest :末尾开始消费 earliest : 从头开始
//props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
//是否启用自动位移提交
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
return props;
}
}5、在 kafka_learn 工程中,运行 SeekDemo.java 类,进行 指定位移消费 测试
七、kafka 再均衡
1、再均衡是指分区的所属从一个消费者转移到另外一个消费者的行为,它为消费组具备了高可用性和伸缩性提供了保障,使得我们既方便又安全地删除消费组内的消费者或者往消费组内添加消费者。不过再均衡发生期间,消费者是无法拉取消息的。
2、在 kafka_learn 工程中,创建 再均衡监听器 类 CommitSyncInRebalance.java
java
/**
* D:\java-test\idea2019\kafka_learn\src\main\java\djh\it\kafka\learn\chapter3\CommitSyncInRebalance.java
*
* 2024-6-22 创建 再均衡监听器 类 CommitSyncInRebalance.java
*/
package djh.it.kafka.learn.chapter3;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import java.time.Duration;
import java.util.*;
import java.util.concurrent.atomic.AtomicBoolean;
public class CommitSyncInRebalance extends ConsumerClientConfig {
public static final AtomicBoolean isRunning = new AtomicBoolean(true);
public static void main( String[] args ) {
Properties props = initConfig();
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
Map<TopicPartition, OffsetAndMetadata> currentoffsets = new HashMap<>();
consumer.subscribe(Arrays.asList(topic), new ConsumerRebalanceListener(){
@Override
public void onPartitionsRevoked( Collection<TopicPartition> partitions){
//尽量避免重复消费
consumer.commitSync(currentoffsets);
}
@Override
public void onPartitionsAssigned( Collection<TopicPartition> partitions){
//do nothing.
}
});
try{
while (isRunning.get()) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.offset() + ":" + record.value());
//异步提交消费位移,在发生再均衡动作之前可以通过再均衡临听器的 onPartitionsRevoked 回调执行 commitsvnc 方法同步提交位移。
currentoffsets.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1));
}
//异步提交
consumer.commitAsync(currentoffsets, null);
}
} finally {
consumer.close();
}
}
}八、kafka 消费者拦截器
1、消费者拦截器
消费者也有相应的拦截器概念,消费者拦截器主要是在消费到消息或者在提交消费位移时进行的一些定制化的操作。
2、消费者拦截器 使用场景:
对消费消息设置一个有效期的属性,如果某条消息在既定的时间窗口内无法到达,那就视为无效,不需要再被处理。
3、在 kafka_learn 工程中,创建 消费者拦截器 类 ConsumerInterceptorTTL.java
java
/**
* D:\java-test\idea2019\kafka_learn\src\main\java\djh\it\kafka\learn\chapter3\ConsumerInterceptorTTL.java
*
* 2024-6-22 创建 消费者拦截器 类 ConsumerInterceptorTTL.java
*/
package djh.it.kafka.learn.chapter3;
import org.apache.commons.collections.map.HashedMap;
import org.apache.kafka.clients.consumer.ConsumerInterceptor;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class ConsumerInterceptorTTL implements ConsumerInterceptor<String, String> {
private static final long EXPIRE_INTERVAL = 10 * 1000;
@Override
public ConsumerRecords<String, String> onConsume( ConsumerRecords<String, String> records ) {
System.out.println("before" + records);
long now = System.currentTimeMillis();
Map<TopicPartition, List<ConsumerRecord<String, String>>> newRecords = new HashedMap();
for(TopicPartition tp : records.partitions()){
List<ConsumerRecord<String, String>> tpRecords = records.records(tp);
List<ConsumerRecord<String, String>> newTpRecords = new ArrayList<>();
for(ConsumerRecord<String, String> record : tpRecords){
//设置一个发送时间戳,超过一分钟的消息,超时,不能收到此消息
if(now - record.timestamp() < EXPIRE_INTERVAL){
newTpRecords.add(record);
}
}
if(!newTpRecords.isEmpty()){
newRecords.put(tp, newTpRecords);
}
}
return new ConsumerRecords<>(newRecords);
}
@Override
public void onCommit( Map<TopicPartition, OffsetAndMetadata> offsets ) {
offsets.forEach((tp, offset) -> System.out.println(tp + ":" + offset.offset()));
}
@Override
public void close() {
}
@Override
public void configure( Map<String, ?> configs ) {
}
}4、在 kafka_learn 工程中,创建 消费者 KafkaConsumerAnalysis.java 类,自定义分区器、自定义拦截器 分析,进行消费消息测试
java
/**
* kafka_learn\src\main\java\djh\it\kafka\learn\chapter3\KafkaConsumerAnalysis.java
*
* 2024-6-22 创建 消费者 KafkaConsumerAnalysis.java 类,自定义分区器、自定义拦截器 分析,进行消费消息测试
*/
package djh.it.kafka.learn.chapter3;
//注意导包,一定要导成 kafka 的序列化包
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class KafkaConsumerAnalysis {
//private static final String brokerList = "localhost:9092";
private static final String brokerList = "172.18.30.110:9092";
private static final String topic = "heima";
private static final String groupId = "group.heima";
private static final AtomicBoolean isRunning = new AtomicBoolean(true);
public static Properties initConfig(){
Properties props = new Properties();
//1)设置 key 序列化器 -- 优化代码
//properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//2)设置值序列化器 -- 优化代码
//properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//3)设置集群地址 -- 优化代码
//properties.put("bootstrap.servers", brokerList);
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
//4)消费组
//properties.put("group.id", groupId);
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
//指定 KafkaConsumer 对应的客户端ID,默认为空,如果不设置KafkaConsumer会自动生成一个非空字符串
props.put("client.id", "consumer.client.id.demo");
// 指定消费者拦截器
props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, ConsumerInterceptorTTL.class.getName());
//kafka 消费者找不到消费的位移时,从什么位置开始消费,默认:latest :末尾开始消费 earliest : 从头开始
//props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
// //是否启用自动位移提交
// props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
return props;
}
public static void main( String[] args ) throws InterruptedException{
Properties props = initConfig();
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topic));
// 正则订阅主题
//consumer.subscribe(Pattern.compile("heima"));
// 指定订阅的分区
//consumer.assign(Arrays.asList(new TopicPartition("heima", 0)));
try{
while (isRunning.get()){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for(ConsumerRecord<String, String> record : records){
System.out.println("topic = " + record.topic() + ", partition = " + record.partition() + ", offset = " + record.offset() );
System.out.println("key = " + record.key() + ", value = " + record.value());
// do something to process record.
}
}
}catch (Exception e){
e.printStackTrace();
//log.error("occur exception ", e);
} finally {
consumer.close();
}
}
}5、在 kafka_learn 工程中,创建 生产者 ProducerFastStart.java 类中,添加超时发送和不超时发送消息,进行测试。
java
/**
* kafka_learn\src\main\java\djh\it\kafka\learn\chapter1\ProducerFastStart.java
*
* 2024-6-21 创建 生产者 ProducerFastStart.java 类
*/
package djh.it.kafka.learn.chapter1;
import org.apache.kafka.clients.producer.*;
//注意导包,一定要导成 kafka 的序列化包
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.Future;
public class ProducerFastStart {
//private static final String brokerList = "localhost:9092";
private static final String brokerList = "172.18.30.110:9092";
private static final String topic = "heima";
public static void main( String[] args ) {
Properties properties = new Properties();
//1)设置 key 序列化器 -- 优化代码
//properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//2)设置重试次数 -- 优化代码
properties.put(ProducerConfig.RETRIES_CONFIG, 10);
//3)设置值序列化器 -- 优化代码
//properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//4)设置集群地址 -- 优化代码
//properties.put("bootstrap.servers", brokerList);
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
ProducerRecord<String,String> record = new ProducerRecord<>(topic, "kafka-demo-000", "hello,kafka");
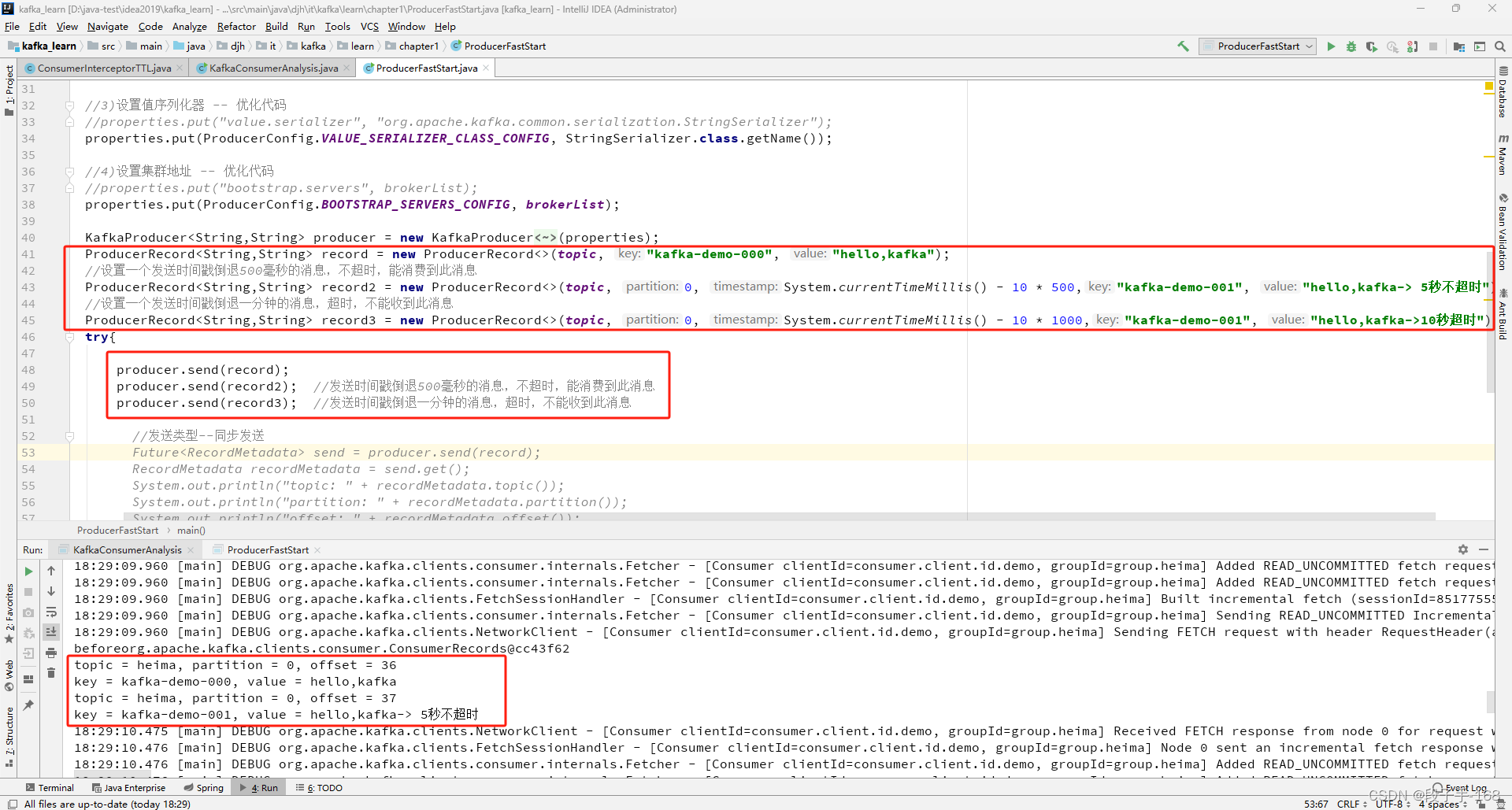
//设置一个发送时间戳倒退500毫秒的消息,不超时,能消费到此消息
ProducerRecord<String,String> record2 = new ProducerRecord<>(topic, 0, System.currentTimeMillis() - 10 * 500,"kafka-demo-001", "hello,kafka-> 5秒不超时");
//设置一个发送时间戳倒退一分钟的消息,超时,不能收到此消息
ProducerRecord<String,String> record3 = new ProducerRecord<>(topic, 0, System.currentTimeMillis() - 10 * 1000,"kafka-demo-001", "hello,kafka->10秒超时");
try{
producer.send(record);
producer.send(record2); //发送时间戳倒退500毫秒的消息,不超时,能消费到此消息
producer.send(record3); //发送时间戳倒退一分钟的消息,超时,不能收到此消息
// //发送类型--同步发送
// Future<RecordMetadata> send = producer.send(record);
// RecordMetadata recordMetadata = send.get();
// System.out.println("topic: " + recordMetadata.topic());
// System.out.println("partition: " + recordMetadata.partition());
// System.out.println("offset: " + recordMetadata.offset());
// //发送类型--异步发送
// producer.send(record, new Callback() {
// public void onCompletion(RecordMetadata metadata, Exception exception) {
// if (exception == null) {
// System.out.println("topic: " + metadata.topic());
// System.out.println("partition: " + metadata.partition());
// System.out.println("offset: " + metadata.offset());
// }
// }
// });
}catch (Exception e){
e.printStackTrace();
}
producer.close();
}
}
九、kafka 消费者 总结
1、kafka 消费者参数补充:
- 1)fetch.min.bytes
这个参数允许消费者指定从 broker 读取消息时最小的数据量。当消费者从 broker 读取消息时,如果数据量小于这个阈值,broker 会等待直到有足够的数据,然后才返回给消费者。对于写入量不高的主题来说,这个参数可以减少 broker 和消费者的压力,因为减少了往返的时间。而对于有大量消费者的主题来说,则可以明显减轻 broker 压力。
上面的 fetch.min.bvtes 参数指定了消费者读取的最小数据量,而这个参数则指定了消费者读取时最长等待时间,从而避免长时间阻塞。这个参数默认为 500ms。
- 3)max.partition.fetch.bytes
这个参数指定了每个分区返回的最多字节数,默认为1M。也就是说,Kafkaconsumer.poll(0) 返回记录列表时,每个分区的记录字节数最多为 1M。如果一个主题有 20 个分区,同时有5个消费者,那么每个消费者需要 4M 的空间来处理消息。实际情况中,我们需要设置更多的空间,这样当存在消费者宕机时,其他消费者可以承担更多的分区。
- 4)max.poll.records
这个参数控制一个 poll(0) 调用返回的记录数,这个可以用来控制应用在拉取循环中的处理数据量。
2、kafka 消费者总结
- kafka 消费者和消费组的概念,
- 使用 KafkaConsumer,
- kafka 消费者参数的配置,
- kafka 订阅、
- kafka 反序列化、
- kafka 位移提交、
- kafka 再均衡、
- kafka 拦截器等。
上一节关联链接请点击
# Kafka_深入探秘者(2):kafka 生产者