文章目录
- [VMamba: Visual State Space Model](#VMamba: Visual State Space Model)
VMamba: Visual State Space Model
摘要
- 卷积神经网络(CNN)和视觉Transformer(ViT)是视觉表示学习的两种最流行的基础模型
- CNN表现出卓越的可扩展性和线性复杂度。
- ViT在图像分辨率方面超过了CNN, 但是复杂性确实二次方。Vit通过结合全局感受野和动态权重实现了卓越的视觉建模性能。
- 作者在继承上述组件的情况下引入了状态空间模型,提出了视觉状态空间模型(VMamba)。该模型在不牺牲全局感受野和动态权重的情况下实现了线性复杂度。
- 通过引入交叉扫描模块(CSM)解决方向敏感问题。
- 实验证明,VMamba在各种视觉任务表现良好,并且随着图像分辨率的提高而表现出更明显的优势。
引言
-
视觉表示学习是计算机视觉领域最基本的研究课题之一。深度基础模型主要分为卷积神经网络(CNN)和Vision Transformer(ViTs)两个主要类别。
-
然而,注意力机制在图像大小方面需要二次方的 复杂度,这在处理下游密集预测任务时计算开销昂贵。为了解决这个问题,人们投入大量的经历通过限制计算窗口的大小或步幅来提高注意力的效率。但是这种是以限制感受野的规模为代价的。因此,作者设计了一种具有线性复杂度的心得视觉基础模型,同时仍然保留与全局感受野和动态权重相关的优势。
-
引入了视觉状态空间模型(VMamba), 用于高效的视觉表示学习。它通过继承自选择性扫描性状态序列模型(S6)。但是因为无法估计和未知扫描补丁的关系,直接使用这种策略会导致接受域受限。作者称这种问题为"方向敏感"问题,并引入交叉扫描模块(CSM)来解决。CSM采用四向扫描策略,即从整个特征的四个角开始扫描映射到相反的为止。如下图所示。该策略保持特征图中的每个元素集成自不同方向的所有其他位置的信息,从而在不增加线性计算复杂度的情况下呈现全局感受野。

-
VMamba的Tiny、Small、Base分别包含22M、44M、75M参数量。能够在FLOPs稳步增加的情况下获得与ViT相当的性能。
-
贡献:
- 提出了VMamba, 一种具有全局感受野和动态权重的视觉状态空间模型,用于视觉表示学习。
- 引入交叉扫描模块(CMS)是为了弥补一维阵列扫描和二维平面扫描之间的差距,促进S6在不影响接受范围的情况下扩展到视觉数据
- 证明VMamba在图像分类、目标检测和语义分割等各种视觉任务具有强大的潜力。
相关工作
具体内容略,主要为卷积神经网络(CNN)、Vision Transformer(ViTs)和状态空间模型(SSMs), 状态空间模型详解可参考Mamba
Preliminaries
状态空间模型 与相关工作一样可参考Mamba
连续时间的SSM可以表示为线性常微分方程(ODEs, linear ordinary differential equations):
h ′ ( t ) = A h ( t ) + B μ ( t ) , y ( t ) = C h ( t ) + D μ ( t ) , \begin{aligned} h'(t)&=\mathbf{A}h(t)+\mathbf{B}\mu(t),\\ y(t)&=\mathbf{C}h(t)+D\mu(t), \end{aligned} h′(t)y(t)=Ah(t)+Bμ(t),=Ch(t)+Dμ(t),
其中, A ∈ R N × N , B ∈ R N × 1 , C ∈ R 1 \mathbf{A}\in\mathbb{R}^{N\times N}, \mathbf{B}\in\mathbb{R}^{N\times1}, \mathbf{C}\in\mathbb{R}^1 A∈RN×N,B∈RN×1,C∈R1是权重参数
SSM的离散化: 状态空间模型(SSMs)作为连续时间模型,需要进行离散化才能更好的集成到深度学习算法中。可以参照Mamba中S4的部分。
选择扫描机制: 为了解决LTI SSMs(SSMs原始公式)获取上下文信息的局限性,Gu等人提出了一种新的SSMs参数化方法, 该方法集成了一个输入依赖的选择机制(S6)。然而,在选择性SSMs的情况下,卷积不适应动态权重导致时变加权参数对隐藏状态难以进行有效计算。而离散化可以使用线性复杂度的关联扫描算法有效地计算出 y b y_b yb。
方法
网络结构
作者在三个尺度上开发了VMamba: VMamba-Tiny(VMamba-T)、VMamba-Small(VMamba-S)和VMamba-Base(VMamba-B)。VMamba-T架构的概述如下图中的a所示。首先将输入图像 I ∈ R H × W × 3 I\in\mathbb{R}^{H\times W\times 3} I∈RH×W×3分割成多个patch, 得到一个维度为 H / 4 × W / 4 H/4\times W/4 H/4×W/4的2d的特征图空间。随后,使用多个网络阶段创建分辨率为 H / 8 × W / 8 , H / 16 × W / 16 , H / 32 × W / 32 H/8\times W/8, H/16\times W/16, H/32\times W/32 H/8×W/8,H/16×W/16,H/32×W/32的分层表示。每个阶段都包括一个下采样层(第一阶段除外),然后是一个堆叠的视觉状态空间(VSS)块。
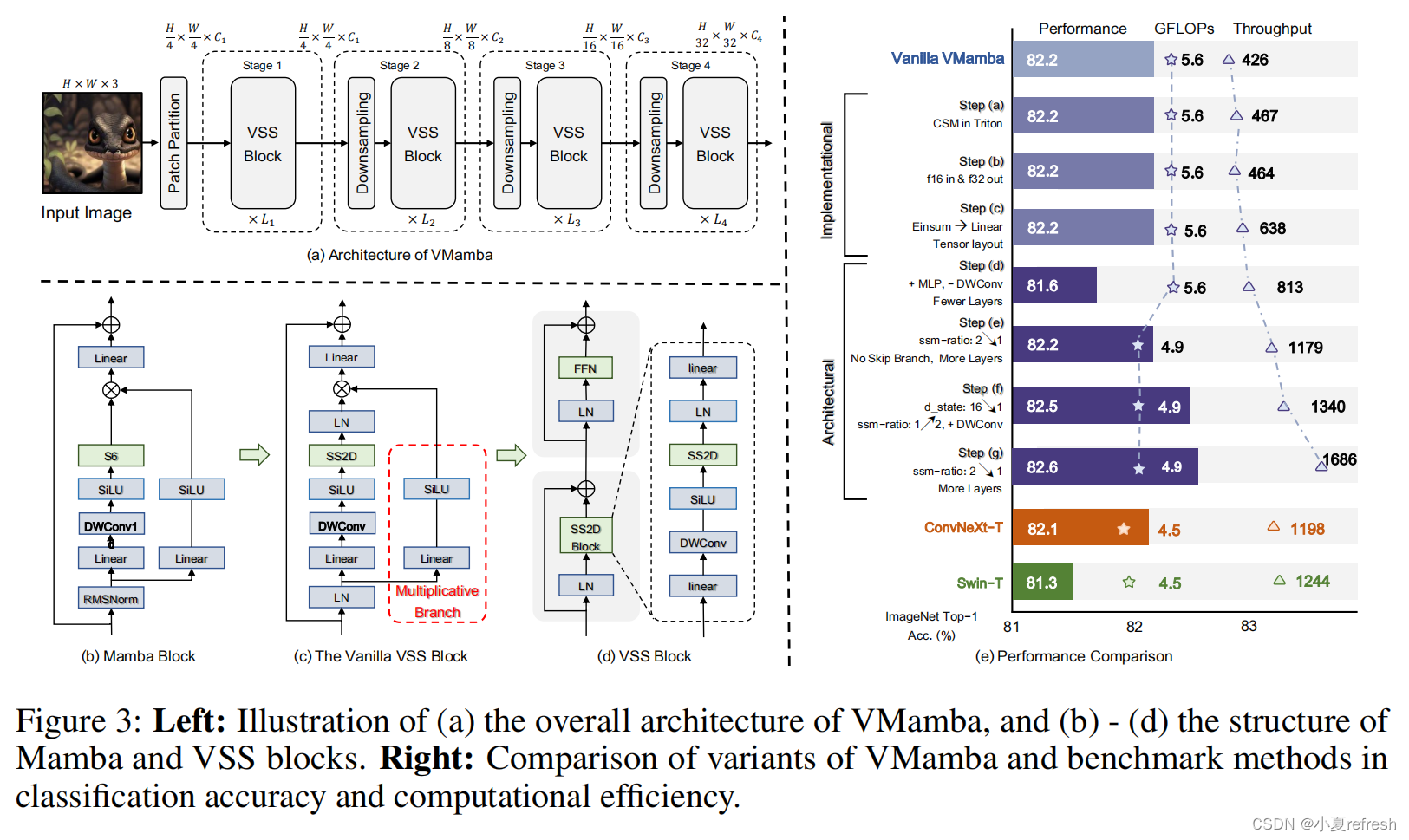
VSS块是Mamba块(上图的b)的视觉对应部分。新提出的2d选择扫描模块(SS2D)替换VSS块的初始架构(上图的c)作为Mamba的核心的同时实现全局接受域,动态权重(即选择性)和线性复杂度。
为了进一步提高计算效率,消除了整个乘法分支(上图c中的红框部分),因为门控机制的影响是通过SS2D的选择性来说实现的。因此,生成的VSS块(上图的d)由一个包含两个残差模块的单一网络分支组成,模仿了一个普通transformer的架构。
2D-Selective-Scan for Vision Data(SS2D)
S6中的扫描操作的顺序性质难以用于视觉数据。因为视觉数据本质上是非顺序的,包含空间信息(如局部纹理和全局结构)。为了解决该问题, S4ND用卷积运算重新指定了SSM, 通过外积将内核从一维扩展到二维,然而这种修改使得权重无法独立于输入,从而限制了捕获上下文信息的能力。因此,作者基于选择性扫描方法提出了了2D选择性扫描模块(SS2D),在不影响其优势的情况下使S6适应视觉数据。
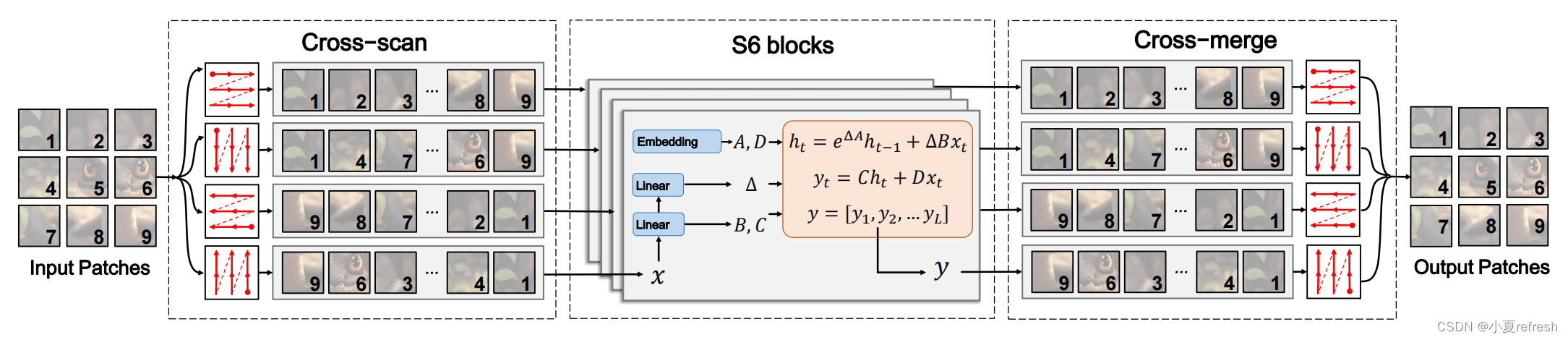
如上图所示,SS2D中的数据前向包含三个步骤: 交叉扫描、S6的选择性扫描和交叉合并。给定输入数据,SS2D首先沿着输入patch沿着四个不同的遍历路径展开成序列(即交叉扫描),使用单独的S6块并行的处理每个patch序列,然后对合成序列进行重构和合并, 以形成输出映射(即交叉合并)。通过采用互补的以为遍历路径,SS2D使图像中的每个像素能够有效地整合其他所有像素的信息,从而促进在二维空间中建立全局接受域的过程。