-
引言
-
简介
-
MLCEngine的聊天功能
-
OpenAI风格API
-
云端REST API
-
Python API
-
iOS SDK
-
Android SDK
-
WebLLM SDK
-
小结
-
-
结构化生成
-
支持各种平台
-
优化引擎性能
-
总结
引言
流星透疏水,走月逆行云。

小伙伴们好,我是《小窗幽记机器学习》的小编:划龙舟的小男孩,紧接前文LLM系列:
LLM端侧部署系列 | 如何将阿里千问大模型Qwen部署到手机上?实战演示(下篇)
LLM端侧部署系列 | 如何将阿里千问大模型Qwen部署到手机上?环境安装及其配置(上篇)
今天这篇小作文延续端侧部署系列 ,主要介绍MLC-LLM最新更新的推理部署引擎MLCEngine及其使用说明。后续会陆续补充介绍更多MLC的详情及其实践,感兴趣的小伙伴可以留意。如需与小编进一步交流,可以在公众号上添加小编微信好友。

简介
当下正是大型语言模型和生成式AI时代,蓬勃发展的大型语言模型带来了定制和特定领域模型部署的重大机(风)遇(口)。一方面,云服务器部署发展迅速,提供能够利用多个GPU为更大模型、更多并发服务请求的解决方案。与此同时,本地化的端侧部署开始崭露头角,量化后的模型已能部署到笔记本电脑、浏览器和手机等端侧设备上。相信未来是端云混合的部署方式,因此让任何人都能在云端和本地环境中运行大型语言模型至关重要。
包括MLC-LLM项目在内的许多LLM推理项目,为服务器和本地模型部署提供了不同的解决方案,具有不同的实现和优化。例如,服务器解决方案通常支持连续批处理和更好的多GPU支持,而本地部署的解决方案则具有更好的跨平台移植性。然而,如何将所有技术集合在一起非常有必要。出现在一种用例中的许多技术如何直接适用于另一种用例。虽然类似连续批处理这样的技术目前在某些本地用例中可能不太实用,但一旦LLM成为操作系统的关键组件并支持多个请求以实现Agent任务,它们就会变得非常有价值。最近,MLC-LLM的研究人提出基于MLCEngine构建一个统一的LLM引擎,使其更加方便支持跨服务器和本地部署。
以下介绍MLC LLM引擎(简称MLCEngine)和细节及其使用详情。MLCEngine是一款通用的LLM部署引擎,引入了一种单一引擎,用于在服务器上实现高吞吐量、低延迟服务,同时无缝集成小型且功能强大的模型,部署到各种本地环境中。
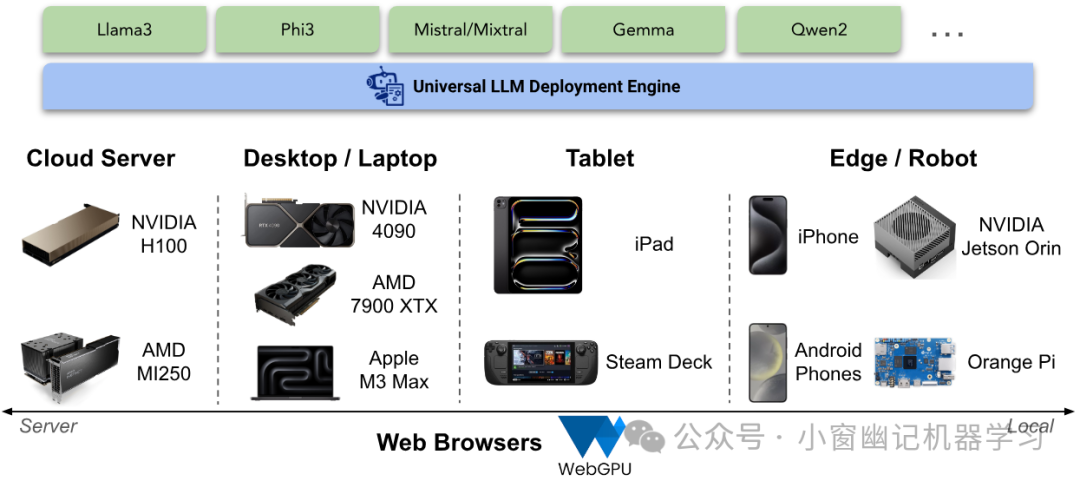
MLCEngine: Universal LLM Deployment Engine
实现通用部署之路存在多种挑战。首先,它需要支持广泛的GPU编程模型和运行时,以实现对每个支持平台的加速。这种过程通常需要大量重复的工程工作。需要尽可能利用有效的供应商库,但也必须支持缺乏标准库支持的新兴平台,如Vulkan或WebGPU。此外,每个应用平台都有不同的编程语言环境,这增加了将引擎引入Swift、Kotlin、Javascript等环境的复杂性。
为了克服支持各平台的挑战,利用了Apache TVM的机器学习编译技术, 自动为各种硬件和平台生成可移植的GPU库。此外,构建了一个可移植的运行时架构,结合了行业一流的LLM服务优化(如连续批处理、投机解码、前缀缓存等),同时最大限度地实现了对云和本地平台的可移植性。
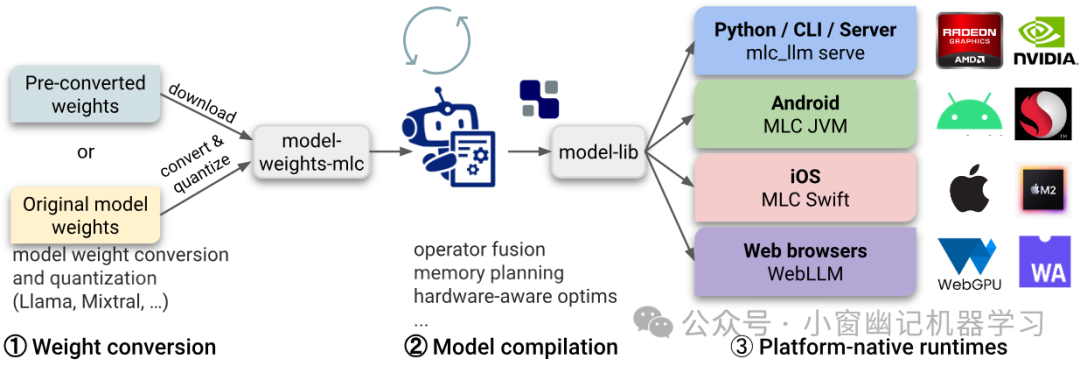
MLC LLM Workflow
编译的模型库与通用运行时协同工作,在不同的主机应用语言中提供直接的语言绑定,共享相同的OpenAI风格的chat completion API。所有本地应用环境都与云服务器环境共享相同的核心引擎,并为每个单独的设置提供专门的配置。
MLCEngine的聊天功能
使用MLCEngine的最简单方式是通过CLI聊天界面。MLC-LLM提供了一个命令行聊天界面。下面是一个示例命令,它在终端中启动聊天CLI,运行一个4位量化的Llama3 8B模型。
mlc_llm chat /share_model_zoo/LLM/mlc-ai/Qwen1.5-1.8B-Chat-q4f32_1-MLC/输出结果:
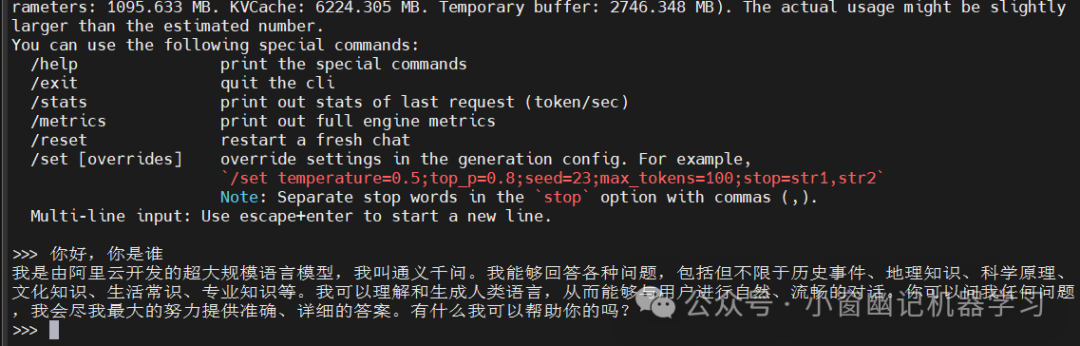
PS:这里的/share_model_zoo/LLM/mlc-ai/Qwen1.5-1.8B-Chat-q4f32_1-MLC/是提前通过以下命令下载到本地的模型:
export HF_HUB_ENABLE_HF_TRANSFER=1
huggingface-cli download --resume-download --local-dir-use-symlinks False mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC --local-dir /share_model_zoo/LLM/mlc-ai/Qwen1.5-1.8B-Chat-q4f32_1-MLC/在幕后,MLC-LLM针对每个平台运行实时进行模型编译,生成GPU代码。因此它可以跨GPU类型和操作系统工作。MLC-LLM现已支持Llama3、Mistral/Mixtral、Phi3、Qwen2、Gemma等各种模型。
OpenAI风格API
MLC-LLM引入了一款通用的LLM引擎,为此设计一套开发人员熟悉并且易于使用的API就变得很重要了。MLC-LLM选择在所有环境中采用与OpenAI API相同的风格。以下将介绍这些API。
云端REST API
LLM服务器通过运行内部LLM引擎来处理从网络收到的请求。MLC-LLM提供了支持完整OpenAI API的REST服务,用于处理LLM生成请求。下面是一个示例命令,用于启动在本地主机上运行的REST服务,来服务4位量化的Qwen2-1.5B-Instruct模型。
mlc_llm serve /share_model_zoo/LLM/mlc-ai/Qwen1.5-1.8B-Chat-q4f32_1-MLC/构建测试请求:
curl -X POST -H "Content-Type: application/json" -d '{"messages":[{"role": "user","content":"你好,我叫爱坤,我会在龙舟上打篮球"},{"role": "assistant","content":"wow,爱坤,你好棒棒啊"},{"role": "user", "content": "你还记得我刚才说我叫什么?"}]}' http://127.0.0.1:8000/v1/chat/completions输出结果如下:
{"id":"chatcmpl-8a35d4c7c1ff4f128d02af40f686ddb2","choices":[{"finish_reason":"stop","index":0,"message":{"content":"是的,我记得你刚才告诉我你叫爱坤。你是我们人工智能助手,我可以帮助你解答各种问题,提供信息,甚至与你进行对话。在今天的对话中,我会尽力为你提供关于打篮球的信息,包括如何在龙舟上进行这项运动,以及一些可能有用的技巧和策略。\n\n首先,让我们来谈谈如何在龙舟上打篮球。打篮球是一项全身运动,需要一定的灵活性、力量和协调性。以下是一些在龙舟上进行篮球运动的建议:\n\n1. **穿着合适的运动装备**:篮球鞋需要提供足够的支撑和抓地力,以适应龙舟跳跃和滑行的需要。此外,一件轻便、透气的运动服装也非常重要,因为龙舟上经常会有剧烈的出汗和湿气。\n\n2. **选择合适的场地和工具**:选择一个平坦、无风且水流畅通的地方进行训练,避免在岩石、树枝或其他障碍物上进行篮球。此外,你需要准备一个篮球,确保它大小合适且质量良好,以在水中自由移动。\n\n3. **保持良好的身体姿势和呼吸方式**:在龙舟上打篮球时,你需要保持良好的身体姿势,例如保持背部挺直、膝关节弯曲并保持膝盖微屈。此外,你需要正确呼吸,利用深呼吸和慢呼气来帮助你在水中保持平衡和控制球。\n\n4. **掌握基本的篮球技巧和战术**:在龙舟上打篮球需要一些基本的篮球技巧,例如运球、传球、防守和投篮。熟悉这些基本技能,并通过训练和比赛来提高它们,可以帮助你在比赛中更好地适应和发挥。\n\n5. **团队协作和沟通**:在龙舟上打篮球是一项团队运动,你需要与队友协作,配合默契,以便在比赛中实现战术目标。在训练和比赛中,你需要学会如何与队友沟通,理解他们的意图和需求,以及如何有效地协调和配合。\n\n6. **练习和毅力**:打篮球需要持续的练习和毅力,尤其是在水中进行,需要适应和调整身体和情绪状态。你需要有足够的耐心和决心,不怕失败和挫折,不断尝试和改进,以提高你的篮球技能和表现。\n\n总的来说,要在龙舟上打篮球,你需要做好充分的准备和训练,保持良好的身体状况,掌握基本的篮球技巧和战术,并且在团队中与队友紧密合作。这样,你就能在龙舟上享受这项运动,同时也能够在比赛中展现出你的篮球实力和才能。如果你有任何问题或需要进一步的帮助,随时告诉我,我将很乐意提供支持和指导。","role":"assistant","name":null,"tool_calls":null,"tool_call_id":null},"logprobs":null}],"created":1717995182,"model":null,"system_fingerprint":"","object":"chat.completion","usage":{"completion_tokens":534,"prompt_tokens":75,"total_tokens":609,"extra":null}}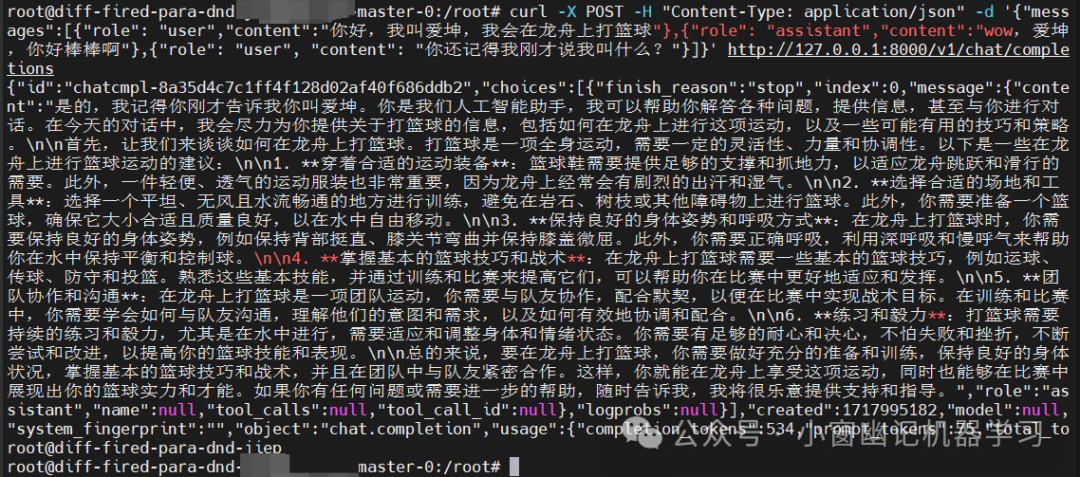
Launching LLM Server and Sending Chat Completion Requests
为了适应不同的服务场景,MLC-LLM提供了三种模式:"server"、"local"和"interactive"。"server"模式可最大化GPU内存使用并支持更高的并发性,而"local"和"interactive"模式则限制并发请求数量并使用更少的GPU内存。建议在专用服务器GPU(如A100/H100)上使用"server"模式,利用全精度FP16模型和FP8变体。对于本地环境,建议使用"local"模式和4位量化模型设置。
Python API
MLC LLM在Python中提供了MLCEngine和AsyncMLCEngine,用于同步和异步LLM生成。两个引擎都支持与OpenAI Python包相同的API。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/6/10 13:27
# @Author : 划龙舟的小男孩
# @File : test_AsyncMLCEngine.py
import asyncio
from mlc_llm import AsyncMLCEngine
model = "/share_model_zoo/LLM/mlc-ai/Qwen1.5-1.8B-Chat-q4f32_1-MLC/"
prompt = (
"赞美一下蔡坤这一RAP篮球明星,他擅长边唱RAP边跳舞边打篮球")
async def chat_completions():
async_engine = AsyncMLCEngine(
model=model,
device="cuda",
)
output_text = " "
async def generate_task():
async for response in await async_engine.chat.completions.create(
messages=[{"role": "user", "content": prompt}],
stream=True, ):
nonlocal output_text
output_text += response.choices[0].delta.content
task = asyncio.create_task(generate_task())
await asyncio.gather(task)
print(f"Output:{output_text}")
asyncio.run(chat_completions())输出结果如下:
Output: 蔡坤,这个名字在中国嘻哈界和篮球界都享有很高的声望,尤其是在篮球和嘻哈音乐领域,他以其独特的魅力和才华成为了业界的一颗璀璨明星。
首先,蔡坤在篮球方面的才华和成就,让人不得不赞叹他的天赋和实力。作为一名自由球员,他在职业生涯中多次代表北京首钢男篮参加CBA联赛,展现出极高的篮球技能和比赛经验。他的身高臂展和全面的个人技术,使他在球场上无论是攻守两端都具有极强的竞争力,无论是在中距离的精准投篮,还是在篮下强硬的强攻,都能给对手带来极大的威胁。
在篮球之外,蔡坤的音乐才华也让人印象深刻。他在2008年加入东方卫视的《热血街舞团》节目,凭借他的扎实舞蹈功底和出色的音乐演绎,展现了他深厚的音乐才华和独特的嘻哈风格。在他的音乐作品中,既有富有动感的嘻哈旋律,又有深情的抒情歌词,展现了他独特的音乐创作才华,深受广大音乐爱好者的喜爱和推崇。
此外,蔡坤还是一位出色的舞者。他在2010年参加上海世界博览会的音乐舞蹈节,展现了他出众的舞蹈技巧和舞台表现力,让全世界观众看到了他不仅是一名出色的篮球运动员,更是集音乐、舞蹈和篮球于一体的全能艺人。
总的来说,蔡坤以其精湛的篮球技术和卓越的音乐才华,成为中国嘻哈界和篮球界的一颗璀璨明星。他的魅力和才华不仅体现在篮球场上,更体现在音乐、舞蹈和舞台表演等多个领域,使他成为了一位深受大众喜爱和尊重的偶像和音乐人。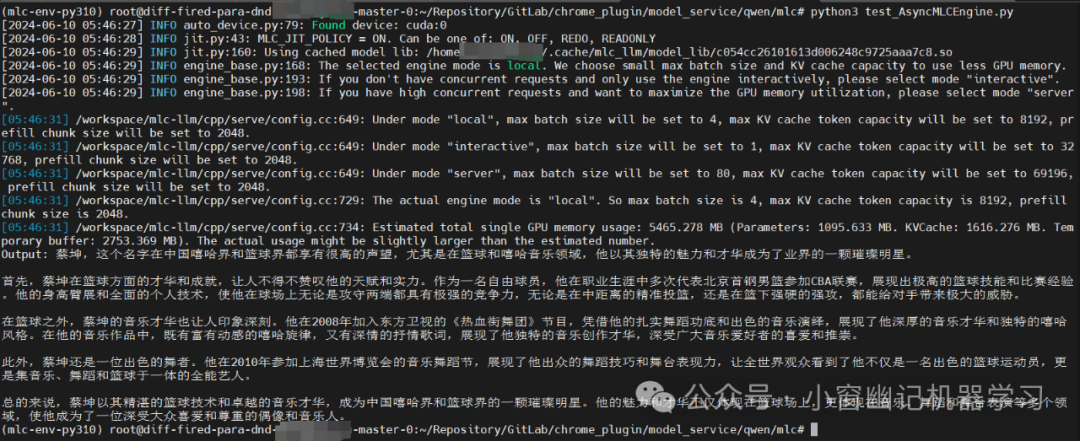
Python API of AsyncMLCEngine
iOS SDK
为了在iPhone和iPad上启用LLM,MLC-LLM在Swift SDK中公开了MLCEngine。虽然OpenAI没有官方的Swift API,这里将其仿照Python API进行设计, 因此设计与Python代码镜像的代码,具有结构化的输入和输出。Swift API还有效地利用了AsyncStream来实现生成内容的异步流式传输。
Android SDK
除了iOS,MLC-LLM也为Android提供相同的体验。我们选择采用仿OpenAI API的Kotlin API。下面是一个示例,展示如何在三星S23上使用聊天完成Kotlin API和MLC Chat应用运行4位量化的Phi-3模型。
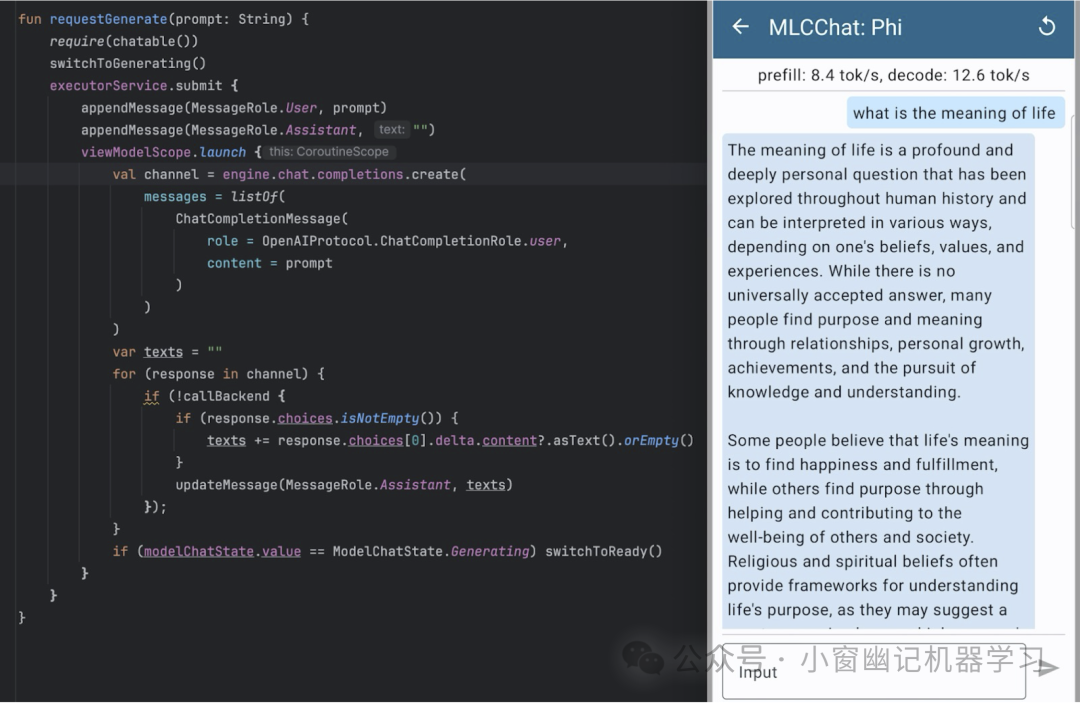
Android/Kotlin API of MLCEngine
WebLLM SDK
近年来,WebGPU生态系统日益成熟。WebGPU通过将WGSL(WebGPU Shading Language)着色器转换为本机GPU着色器来工作。这使得在浏览器中执行GPU计算成为可能,快速(原生GPU加速)、方便(无需任何环境设置)且私密(100%客户端计算)。通过WebLLM项目,MLCEngine也可在JavaScript中使用。
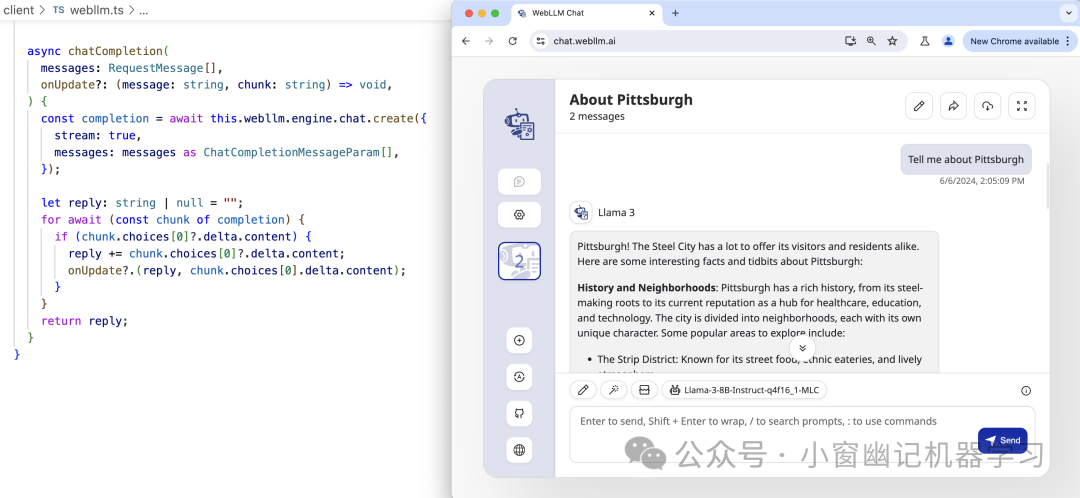
JavaScript/TypeScript API of MLCEngine
小结
以上这些API都遵循相同的engine.chat.completions.create风格,因此在这些平台上的开发体验一致。另外,MLC-LLM官方也尽可能利用语言的本地特性来创建结构化的输入输出,并启用异步流式传输,从而不会阻塞UI。
结构化生成
除了构建聊天应用程序外,MLC-LLM还将支持超出聊天的应用。LLM的结构化生成极大地提高了LLM的能力,不仅限于基本的聊天或纯文本生成。通过可控的结构化生成,LLM能够成为标准工具,并可以更好地集成到其他生产应用程序中。在各种场景中,JSON是最广泛使用的标准格式,因此对LLM引擎支持JSON字符串的结构化生成至关重要。
MLCEngine提供了最先进的JSON模式结构化生成。对于每个请求,MLCEngine都会运行并维护高性能的GrammarBNF状态机,在自回归生成过程中约束响应格式。
MLCEngine支持两个级别的JSON模式:通用JSON响应和JSON模式自定义。通用JSON模式约束响应符合JSON语法。要使用通用JSON模式,请传递参数response_format={"type": "json_object"}到聊天完成请求中。以下是使用JSON模式的请求示例。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/6/10 14:06
# @Author : 划龙舟的小男孩
# @File : test_mlc_json_format.py
from mlc_llm import MLCEngine
# Create engine
model = "/share_model_zoo/LLM/mlc-ai/Qwen1.5-1.8B-Chat-q4f32_1-MLC/"
engine = MLCEngine(model)
prompt = "用Json格式列出3个广州必游景点"
response = engine.chat.completions.create(
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"}, )
print(response.choices[0].message.content)
engine.terminate()输出结果如下:
[{
"name": "白云山",
"description": "广州市最大的山,海拔338米,位于广州市中心,是广州市内最高的山脉,以其壮观的山体、清澈的溪流、美丽的自然风光和深厚的历史文化底蕴而闻名。白云山景区内有广州塔、流花溪、天字广场、白云山动物园、白云山植物园等景点,游客可以登高远眺,领略广州市的全景风光。"
},
{
"name": "陈家祠",
"description": "陈家祠位于广州市老城区的中山大学南校门内,是广东省最大的民间建筑群之一,以陈家祠的祠堂建筑和极具特色的砖雕艺术而闻名。陈家祠内部设有大量的祠堂,包括黄遵宪祠堂、林伯渠祠堂、陈名中祠堂、陈世光祠堂等,每个祠堂都有其独特的历史故事和民间传说。陈家祠的建筑风格独特,典雅庄重,是中国传统文化的重要载体,也是广州市人民生活和历史记忆的重要见证。"
},
{
"name": "珠江夜游",
"description": "珠江夜游是广州市的一项特色旅游活动,游客可以在珠江上欣赏到广州市的夜景,领略广州的夜生活。珠江夜游的行程通常会安排在夜晚,乘客可以选择乘坐游船,沿途欣赏广州的夜景,如珠江两岸的灯光秀、珠江上的倒影等,同时还可以在船上品尝各种广州美食,体验广州市的夜生活。珠江夜游的船票通常会根据乘客的乘坐时间、船只类型等因素进行定价,价格通常在几十元到几百元之间。"
}]此外,MLCEngine允许为每个单独的请求自定义JSON模式。当提供了JSON模式时,MLCEngine将严格按照该模式生成响应。以下是使用自定义JSON模式的请求示例。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/6/10 14:23
# @Author : 划龙舟的小男孩
# @File : test_customization_json.py
import json
import pydantic
from typing import List
from mlc_llm import MLCEngine
# Create engine
model = "/share_model_zoo/LLM/mlc-ai/Qwen1.5-1.8B-Chat-q4f32_1-MLC/"
engine = MLCEngine(model)
class Country(pydantic.BaseModel):
name: str
capital: str
class Countries(pydantic.BaseModel):
country: List[Country]
prompt = "用Json格式列出三个国家及其首都"
schema = json.dumps(Countries.model_json_schema())
response = engine.chat.completions.create(
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object", "schema": schema},
)
print(response.choices[0].message.content)
engine.terminate()输出结果如下:
{"country": [{"name": "中国", "capital": "北京"}, {"name": "美国", "capital": "华盛顿"}, {"name": "英国", "capital": "伦敦"}]}PS:此时schema值如下:
{"$defs": {"Country": {"properties": {"name": {"title": "Name", "type": "string"}, "capital": {"title": "Capital", "type": "string"}}, "required": ["name", "capital"], "title": "Country", "type": "object"}}, "properties": {"country": {"items": {"$ref": "#/$defs/Country"}, "title": "Country", "type": "array"}}, "required": ["country"], "title": "Countries", "type": "object"}在引擎中内置结构化生成,这意味着它可以在MLCEngine支持的所有API平台上使用。
支持各种平台
MLC-LLM的一个使命是使LLM在不同平台上可以访问。前面已经讨论了服务器GPU、Android和iOS上的用例。MLCEngine可以在各种平台上运行,包括但不限于:
-
NVIDIA RTX 4090、
-
NVIDIA Jetson Orin、
-
NVIDIA T4(在Google Colab上)、
-
AMD 7900 XTX、
-
Steam Deck、
-
Orange Pi
机器学习编译帮助我们减少了构建MLCEngine所需的工程工作量,并帮助我们为更广泛的硬件带来高性能解决方案,让更多人可以访问这些模型。
优化引擎性能
虽然这是MLCEngine的第一个发布里程碑,但我们已经为优化其性能付出了很大努力。该引擎结合了多项关键系统改进,如连续批处理、投机解码、分页KV管理、公共前缀缓存和级联推理。我们利用FlashInfer库在CUDA平台上计算快速注意力,并通过编译器代码生成扩展到更广阔的平台支持。
MLCEngine开箱即支持多GPU。下面的命令在两个GPU上启动REST服务器:
mlc_llm serve /share_model_zoo/LLM/mlc-ai/Qwen1.5-1.8B-Chat-q4f32_1-MLC/ --overrides "tensor_parallel_shards=2"在高吞吐量低延迟设置下,MLCEngine可实现高度竞争力的性能,特别是在服务器用例中,并且能够很好地扩展到多个GPU。MLC-LLM还在苹果GPU等平台上保持了最先进的性能水平,同时支持WebGPU等新兴平台。
总结
本文介绍了MLCEngine,这是一款统一高效的LLM引擎,可以在不同的硬件和平台上运行LLM,包括云服务器到边缘设备。