编写测试及控制执行
在 Rust 中,测试是通过函数的方式实现的,它可以用于验证被测试代码的正确性。测试函数往往依次执行以下三种行为:
- 设置所需的数据或状态
- 运行想要测试的代码
- 判断( assert )返回的结果是否符合预期
让我们来看看该如何使用 Rust 提供的特性来按照上述步骤编写测试用例。
测试函数
当使用 Cargo 创建一个 lib 类型的包时,它会为我们自动生成一个测试模块。先来创建一个 lib 类型的 adder 包:
shell
$ cargo new adder --lib
Created library `adder` project
$ cd adder创建成功后,在 src/lib.rs 文件中可以发现如下代码:
rust
#[cfg(test)]
mod tests {
#[test]
fn it_works() {
assert_eq!(2 + 2, 4);
}
}其中,tests 就是一个测试模块,it_works 则是我们的主角:测试函数。
可以看出,测试函数需要使用 test 属性进行标注。关于属性( attribute ),我们在之前的章节已经见过类似的 derive,使用它可以派生自动实现的 Debug 、Copy 等特征,同样的,使用 test 属性,我们也可以获取 Rust 提供的测试特性。
经过 test 标记的函数就可以被测试执行器发现,并进行运行。当然,在测试模块 tests 中,还可以定义非测试函数,这些函数可以用于设置环境或执行一些通用操作:例如为部分测试函数提供某个通用的功能,这种功能就可以抽象为一个非测试函数。
换而言之,正是因为测试模块既可以定义测试函数又可以定义非测试函数,导致了我们必须提供一个特殊的标记 test,用于告知哪个函数才是测试函数。
assert_eq
在测试函数中,还使用到了一个内置的断言:assert_eq,该宏用于对结果进行断言:2 + 2 是否等于 4。与之类似,Rust 还内置了其它一些实用的断言,具体参见后续章节。
cargo test
下面使用 cargo test 命令来运行项目中的所有测试:
shell
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.57s
Running unittests (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s上面测试输出中,有几点值得注意:
- 测试用例是分批执行的,
running 1 test表示下面的输出test result来自一个测试用例的运行结果。 test tests::it_works中包含了测试用例的名称test result: ok中的ok表示测试成功通过1 passed代表成功通过一个测试用例(因为只有一个),0 failed: 没有测试用例失败,0 ignored说明我们没有将任何测试函数标记为运行时可忽略,0 filtered意味着没有对测试结果做任何过滤,0 mesasured代表基准测试(benchmark)的结果
关于 filtered 和 ignored 的使用,在本章节的后续内容我们会讲到,这里暂且略过。
还有一个很重要的点,输出中的 Doc-tests adder 代表了文档测试,由于我们的代码中没有任何文档测试的内容,因此这里的测试用例数为 0,关于文档测试的详细介绍请参见这里。
大家还可以尝试修改下测试函数的名称,例如修改为 exploration,看看运行结果将如何变化。
失败的测试用例
是时候开始写自己的测试函数了,为了演示,这次我们来写一个会运行失败的:
rust
#[cfg(test)]
mod tests {
#[test]
fn exploration() {
assert_eq!(2 + 2, 4);
}
#[test]
fn another() {
panic!("Make this test fail");
}
}新的测试函数 another 相当简单粗暴,直接使用 panic 来报错,使用 cargo test 运行看看结果:
shell
running 2 tests
test tests::another ... FAILED
test tests::exploration ... ok
failures:
---- tests::another stdout ----
thread 'main' panicked at 'Make this test fail', src/lib.rs:10:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::another
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass '--lib'从结果看,两个测试函数,一个成功,一个失败,同时在输出中准确的告知了失败的函数名: failures: tests::another,同时还给出了具体的失败原因: tests::another stdout。这两者虽然看起来存在重复,但是前者用于说明每个失败的具体原因,后者用于给出一眼可得结论的汇总信息。
有同学可能会好奇,这两个测试函数以什么方式运行? 它们会运行在同一个线程中吗?答案是否定的,Rust 在默认情况下会为每一个测试函数启动单独的线程去处理,当主线程 main 发现有一个测试线程死掉时,main 会将相应的测试标记为失败。
事实上,多线程运行测试虽然性能高,但是存在数据竞争的风险,在后文我们会对其进行详细介绍并给出解决方案。
自定义失败信息
默认的失败信息在有时候并不是我们想要的,来看一个例子:
rust
pub fn greeting(name: &str) -> String {
format!("Hello {}!", name)
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Sunface");
assert!(result.contains("孙飞"));
}
}使用 cargo test 运行后,错误如下:
shell
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at 'assertion failed: result.contains(\"孙飞\")', src/lib.rs:12:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name可以看出,这段报错除了告诉我们错误发生的地方,并没有更多的信息,那再来看看该如何提供一些更有用的信息:
rust
fn greeting_contains_name() {
let result = greeting("Sunface");
let target = "孙飞";
assert!(
result.contains(target),
"你的问候中并没有包含目标姓名 {} ,你的问候是 `{}`",
target,
result
);
}这段代码跟之前并无不同,只是为 assert! 新增了几个格式化参数,这种使用方式与 format! 并无区别。再次运行后,输出如下:
shell
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at '你的问候中并没有包含目标姓名 孙飞 ,你的问候是 `Hello Sunface!`', src/lib.rs:14:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace这次的报错就清晰太多了,真棒!在测试用例少的时候,也许这种信息还无法体现最大的价值,但是一旦测试多了后,详尽的报错信息将帮助我们更好的进行 Debug。
测试 panic
在之前的例子中,我们通过 panic 来触发报错,但是如果一个函数本来就会 panic ,而我们想要检查这种结果呢?
也就是说,我们需要一个办法来测试一个函数是否会 panic,对此, Rust 提供了 should_panic 属性注解,和 test 注解一样,对目标测试函数进行标注即可:
rust
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {}.", value);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}上面是一个简单的猜数字游戏,Guess 结构体的 new 方法在传入的值不在 1,100 之间时,会直接 panic,而在测试函数 greater_than_100 中,我们传入的值 200 显然没有落入该区间,因此 new 方法会直接 panic,为了测试这个预期的 panic 行为,我们使用 #[should_panic] 对其进行了标注。
shell
running 1 test
test tests::greater_than_100 - should panic ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s从输出可以看出, panic 的结果被准确的进行了测试,那如果测试函数中的代码不再 panic 呢?例如:
rust
fn greater_than_100() {
Guess::new(50);
}此时显然会测试失败,因为我们预期一个 panic,但是 new 函数顺利的返回了一个 Guess 实例:
shell
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
note: test did not panic as expected // 测试并没有按照预期发生 panicexpected
虽然 panic 被成功测试到,但是如果代码发生的 panic 和我们预期的 panic 不符合呢?因为一段糟糕的代码可能会在不同的代码行生成不同的 panic。
鉴于此,我们可以使用可选的参数 expected 来说明预期的 panic 长啥样:
rust
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be greater than or equal to 1, got {}.",
value
);
} else if value > 100 {
panic!(
"Guess value must be less than or equal to 100, got {}.",
value
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "Guess value must be less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}这段代码会通过测试,因为通过增加了 expected ,我们成功指定了期望的 panic 信息,大家可以顺着代码推测下:把 200 带入到 new 函数中看看会触发哪个 panic。
如果注意看,你会发现 expected 的字符串和实际 panic 的字符串可以不同,前者只需要是后者的字符串前缀即可,如果改成 #[should_panic(expected = "Guess value must be less than")],一样可以通过测试。
这里由于篇幅有限,我们就不再展示测试失败的报错,大家可以自己修改下 expected 的信息,然后看看报错后的输出长啥样。
使用 Result<T, E>
在之前的例子中,panic 扫清一切障碍,但是它也不是万能的,例如你想在测试中使用 ? 操作符进行链式调用该怎么办?那就得请出 Result<T, E> 了:
rust
#[cfg(test)]
mod tests {
#[test]
fn it_works() -> Result<(), String> {
if 2 + 2 == 4 {
Ok(())
} else {
Err(String::from("two plus two does not equal four"))
}
}
}如上所示,测试函数不会再使用 assert_eq! 导致 panic,而是手动进行了逻辑判断,并返回一个 Result。当然,当这么实现时,#[should_panic] 将无法再被使用。
至此,关于如何写测试的基本知识,大家已经了解的差不多了,下面来看看该如何控制测试的执行。
使用 -- 分割命令行参数
大家应该都知道 cargo build 可以将代码编译成一个可执行文件,那你知道 cargo run 和 cargo test 是如何运行的吗?其实道理都一样,这两个也是将代码编译成可执行文件,然后进行运行,唯一的区别就在于这个可执行文件随后会被删除。
正因为如此,cargo test 也可以通过命令行参数来控制测试的执行,例如你可以通过参数来让默认的多线程测试变成单线程下的测试。需要注意的是命令行参数有两种,这两种通过 -- 进行分割:
- 第一种是提供给
cargo test命令本身的,这些参数在--之前指定 - 第二种是提供给编译后的可执行文件的,在
--之后指定
例如我们可以使用 cargo test --help 来查看第一种参数的帮助列表,还可以通过 cargo test -- --help 来查看第二种的帮助列表。
先来看看第二种参数中的其中一个,它可以控制测试是并行运行还是顺序运行。
测试用例的并行或顺序执行
当运行多个测试函数时,默认情况下是为每个测试都生成一个线程,然后通过主线程来等待它们的完成和结果。这种模式的优点很明显,那就是并行运行会让整体测试时间变短很多,运行过大量测试用例的同学都明白并行测试的重要性:生命苦短,我用并行。
但是有利就有弊,并行测试最大的问题就在于共享状态的修改,因为你难以控制测试的运行顺序,因此如果多个测试共享一个数据,那么对该数据的使用也将变得不可控制。
例如,我们有多个测试,它们每个都会往该文件中写入一些自己的数据 ,最后再从文件中读取这些数据进行对比。由于所有测试都是同时运行的,当测试 A 写入数据准备读取并对比时,很有可能会被测试 B 写入新的数据,导致 A 写入的数据被覆盖,然后 A 再读取到的就是 B 写入的数据。结果 A 测试就会失败,而且这种失败还不是因为测试代码不正确导致的!
解决办法也有,我们可以让每个测试写入自己独立的文件中,当然,也可以让所有测试一个接着一个顺序运行:
rust
$ cargo test -- --test-threads=1首先能注意到的是该命令行参数是第二种类型:提供给编译后的可执行文件的,因为它在 -- 之后进行传递。其次,细心的同学可能会想到,线程数不仅仅可以指定为 1,还可以指定为 4、8,当然,想要顺序运行,就必须是 1。
测试函数中的 println!
默认情况下,如果测试通过,那写入标准输出的内容是不会显示在测试结果中的:
rust
fn prints_and_returns_10(a: i32) -> i32 {
println!("I got the value {}", a);
10
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn this_test_will_pass() {
let value = prints_and_returns_10(4);
assert_eq!(10, value);
}
#[test]
fn this_test_will_fail() {
let value = prints_and_returns_10(8);
assert_eq!(5, value);
}
}上面代码使用 println! 输出收到的参数值,来看看测试结果:
shell
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'main' panicked at 'assertion failed: `(left == right)`
left: `5`,
right: `10`', src/lib.rs:19:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s大家注意看,I got the value 4 并没有被输出,因为该测试顺利通过了,如果就是想要看所有的输出,该怎么办呢?
rust
$ cargo test -- --show-output如上所示,只需要增加一个参数,具体的输出就不再展示,总之这次大家一定可以顺利看到 I got the value 4 的身影。
指定运行一部分测试
在 Mysql 中有上百万的单元测试,如果使用类似 cargo test 的命令来运行全部的测试,那开发真的工作十分钟,吹牛八小时了。对于 Rust 的中大型项目也一样,每次都运行全部测试是不可接受的,特别是你的工作仅仅是项目中的一部分时。
rust
pub fn add_two(a: i32) -> i32 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn add_two_and_two() {
assert_eq!(4, add_two(2));
}
#[test]
fn add_three_and_two() {
assert_eq!(5, add_two(3));
}
#[test]
fn one_hundred() {
assert_eq!(102, add_two(100));
}
}如果直接使用 cargo test 运行,那三个测试函数会同时并行的运行:
shell
running 3 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test tests::one_hundred ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s就不说上百万测试,就说几百个,想象一下结果会是怎么样,下面我们来看看该如何解决这个问题。
运行单个测试
这个很简单,只需要将指定的测试函数名作为参数即可:
shell
$ cargo test one_hundred
running 1 test
test tests::one_hundred ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 2 filtered out; finished in 0.00s此时,只有测试函数 one_hundred 会被运行,其它两个由于名称不匹配,会被直接忽略。同时,在上面的输出中,Rust 也通过 2 filtered out 提示我们:有两个测试函数被过滤了。
但是,如果你试图同时指定多个名称,那抱歉:
shell
$ cargo test one_hundred,add_two_and_two
$ cargo test one_hundred add_two_and_two这两种方式统统不行,此时就需要使用名称过滤的方式来实现了。
通过名称来过滤测试
我们可以通过指定部分名称的方式来过滤运行相应的测试:
shell
$ cargo test add
running 2 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s事实上,你不仅可以使用前缀,还能使用名称中间的一部分:
shell
$ cargo test and
running 2 tests
test tests::add_two_and_two ... ok
test tests::add_three_and_two ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s其中还有一点值得注意,那就是测试模块 tests 的名称也出现在了最终结果中:tests::add_two_and_two,这是非常贴心的细节,也意味着我们可以通过模块名称来过滤测试:
shell
$ cargo test tests
running 3 tests
test tests::add_two_and_two ... ok
test tests::add_three_and_two ... ok
test tests::one_hundred ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s忽略部分测试
有时候,一些测试会非常耗时间,因此我们希望在 cargo test 中对它进行忽略,如果使用之前的方式,我们需要将所有需要运行的名称指定一遍,这非常麻烦,好在 Rust 允许通过 ignore 关键字来忽略特定的测试用例:
rust
#[test]
fn it_works() {
assert_eq!(2 + 2, 4);
}
#[test]
#[ignore]
fn expensive_test() {
// 这里的代码需要几十秒甚至几分钟才能完成
}在这里,我们使用 #[ignore] 对 expensive_test 函数进行了标注,看看结果:
shell
$ cargo test
running 2 tests
test expensive_test ... ignored
test it_works ... ok
test result: ok. 1 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s输出中的 test expensive_test ... ignored 意味着该测试函数被忽略了,因此并没有被执行。
当然,也可以通过以下方式运行被忽略的测试函数:
shell
$ cargo test -- --ignored
running 1 test
test expensive_test ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s组合过滤
上面的方式虽然很强大,但是单独使用依然存在局限性。好在它们还能组合使用,例如还是之前的代码:
rust
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
assert_eq!(2 + 2, 4);
}
#[test]
#[ignore]
fn expensive_test() {
// 这里的代码需要几十秒甚至几分钟才能完成
}
#[test]
#[ignore]
fn expensive_run() {
// 这里的代码需要几十秒甚至几分钟才能完成
}
}然后运行 tests 模块中的被忽略的测试函数
shell
$ cargo test tests -- --ignored
running 2 tests
test tests::expensive_test ... ok
test tests::expensive_run ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s运行名称中带 run 且被忽略的测试函数:
shell
$ cargo test run -- --ignored
running 1 test
test tests::expensive_run ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 2 filtered out; finished in 0.00s类似的还有很多,大家可以自己摸索研究下,总之,熟练掌握测试的使用是非常重要的,虽然包括我在内的很多开发并不喜欢写测试 😃
[dev-dependencies]
与 package.json( Nodejs )文件中的 devDependencies 一样, Rust 也能引入只在开发测试场景使用的外部依赖。
其中一个例子就是 pretty_assertions,它可以用来扩展标准库中的 assert_eq! 和 assert_ne!,例如提供彩色字体的结果对比。
在 Cargo.toml 文件中添加以下内容来引入 pretty_assertions:
toml
# standard crate data is left out
[dev-dependencies]
pretty_assertions = "1"然后在 src/lib.rs 中添加:
rust
pub fn add(a: i32, b: i32) -> i32 {
a + b
}
#[cfg(test)]
mod tests {
use super::*;
use pretty_assertions::assert_eq; // 该包仅能用于测试
#[test]
fn test_add() {
assert_eq!(add(2, 3), 5);
}
}在 tests 模块中,我们通过 use pretty_assertions::assert_eq; 成功的引入之前添加的包,由于 tests 模块明确的用于测试目的,这种引入并不会报错。 大家可以试试在正常代码(非测试代码)中引入该包,看看会发生什么。
生成测试二进制文件
在有些时候,我们可能希望将测试与别人分享,这种情况下生成一个类似 cargo build 的可执行二进制文件是很好的选择。
事实上,在 cargo test 运行的时候,系统会自动为我们生成一个可运行测试的二进制可执行文件:
shell
$ cargo test
Finished test [unoptimized + debuginfo] target(s) in 0.00s
Running unittests (target/debug/deps/study_cargo-0d693f72a0f49166)这里的 target/debug/deps/study_cargo-0d693f72a0f49166 就是可执行文件的路径和名称,我们直接运行该文件来执行编译好的测试:
shell
$ target/debug/deps/study_cargo-0d693f72a0f49166
running 3 tests
test tests::add_two_and_two ... ok
test tests::add_three_and_two ... ok
test tests::one_hundred ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s如果你只想生成编译生成文件,不想看 cargo test 的输出结果,还可以使用 cargo test --no-run.
推荐几款学习编程的免费平台
免费在线开发平台(https://docs.ltpp.vip/LTPP/)
探索编程世界的新天地,为学生和开发者精心打造的编程平台,现已盛大开启!这个平台汇集了近4000道精心设计的编程题目,覆盖了C、C++、JavaScript、TypeScript、Go、Rust、PHP、Java、Ruby、Python3以及C#等众多编程语言,为您的编程学习之旅提供了一个全面而丰富的实践环境。
在这里,您不仅可以查看自己的代码记录,还能轻松地在云端保存和运行代码,让编程变得更加便捷。平台还提供了私聊和群聊功能,让您可以与同行们无障碍交流,分享文件,共同进步。不仅如此,您还可以通过阅读文章、参与问答板块和在线商店,进一步拓展您的知识边界。
为了提升您的编程技能,平台还设有每日一题、精选题单以及激动人心的编程竞赛,这些都是备考编程考试的绝佳资源。更令人兴奋的是,您还可以自定义系统UI,选择视频或图片作为背景,打造一个完全个性化的编码环境,让您的编程之旅既有趣又充满挑战。
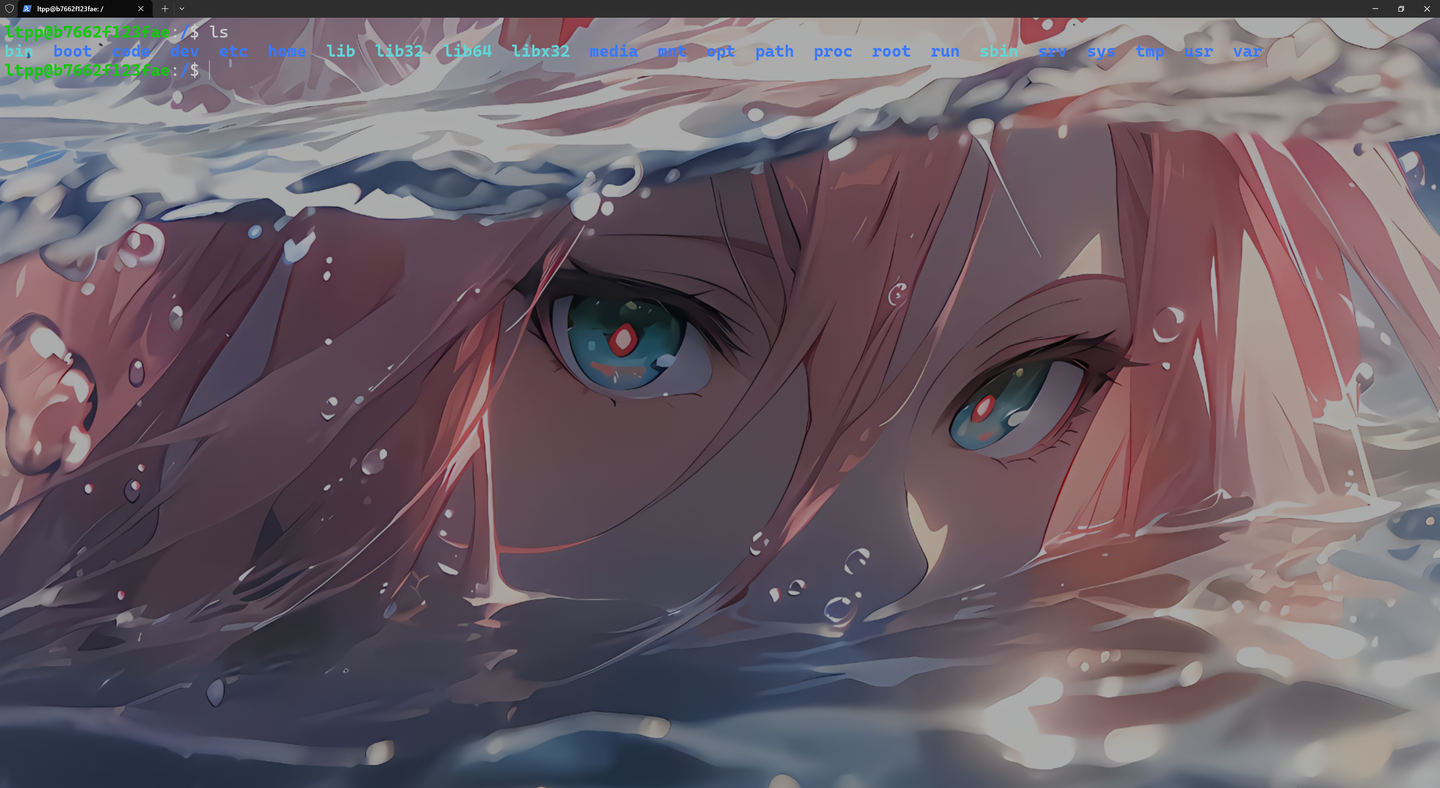
免费公益服务器(https://docs.ltpp.vip/LTPP-SHARE/linux.html)
作为开发者或学生,您是否经常因为搭建和维护编程环境而感到头疼?现在,您不必再为此烦恼,因为一款全新的免费公共服务器已经为您解决了所有问题。这款服务器内置了多种编程语言的编程环境,并且配备了功能强大的在线版VS Code,让您可以随时随地在线编写代码,无需进行任何复杂的配置。
随时随地,云端编码无论您身在何处,只要有网络连接,就可以通过浏览器访问这款公共服务器,开始您的编程之旅。这种云端编码的便利性,让您的学习或开发工作不再受限于特定的设备或环境。
丰富的编程语言支持服务器支持包括C、C++、JavaScript、TypeScript、Go、Rust、PHP、Java、Ruby、Python3以及C#等在内的多种主流编程语言,满足不同开发者和学生的需求。无论您是初学者还是资深开发者,都能找到适合自己的编程环境。
在线版VS Code,高效开发内置的在线版VS Code提供了与本地VS Code相似的编辑体验,包括代码高亮、智能提示、代码调试等功能,让您即使在云端也能享受到高效的开发体验。
数据隐私和安全提醒虽然服务器是免费的,但为了保护您的数据隐私和安全,我们建议您不要上传任何敏感或重要的数据。这款服务器更适合用于学习和实验,而非存储重要信息。
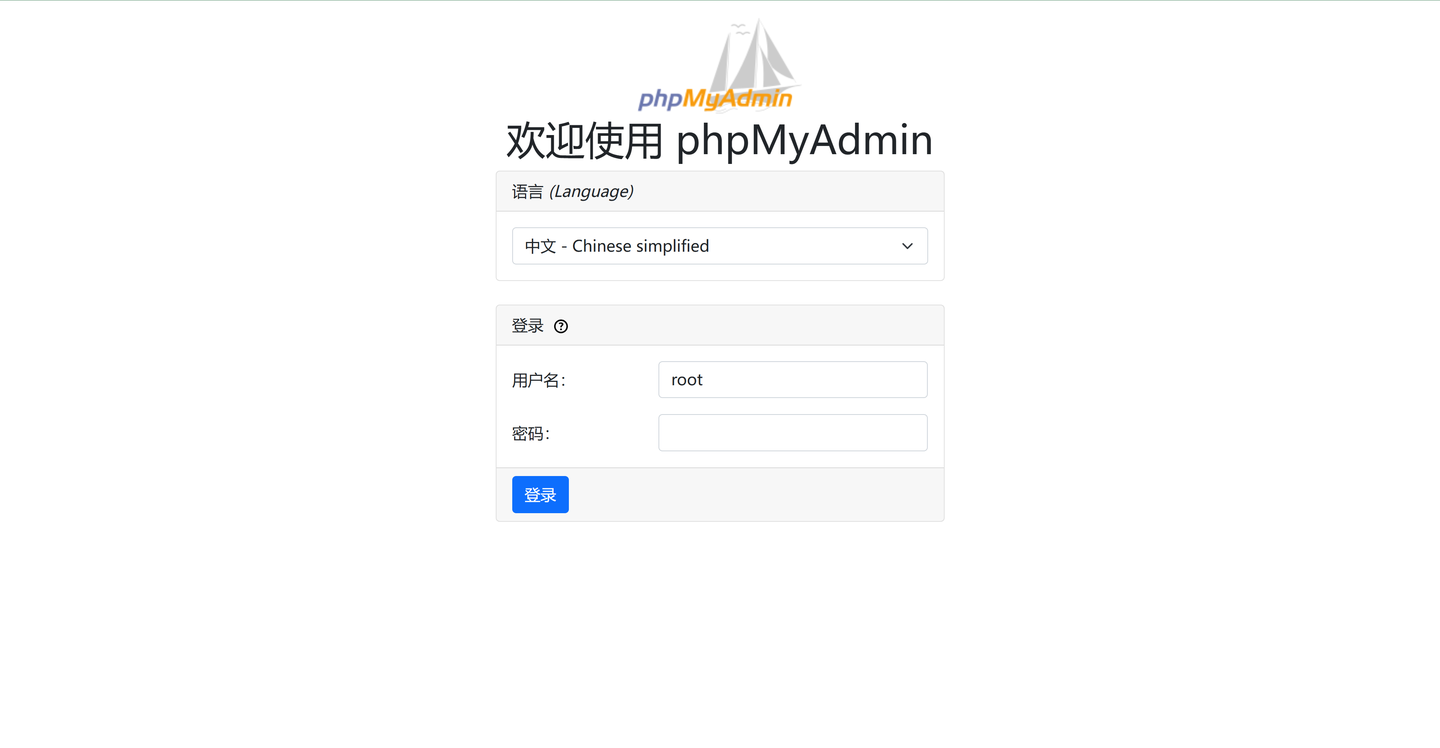
免费公益MYSQL(https://docs.ltpp.vip/LTPP-SHARE/mysql.html)
作为一名开发者或学生,数据库环境的搭建和维护往往是一个复杂且耗时的过程。但不用担心,现在有一款免费的MySQL服务器,专为解决您的烦恼而设计,让数据库的使用变得简单而高效。
性能卓越,满足需求虽然它是免费的,但性能绝不打折。服务器提供了稳定且高效的数据库服务,能够满足大多数开发和学习场景的需求。
在线phpMyAdmin,管理更便捷内置的在线phpMyAdmin管理面板,提供了一个直观且功能强大的用户界面,让您可以轻松地查看、编辑和管理数据库。
数据隐私提醒,安全第一正如您所知,这是一项公共资源,因此我们强烈建议不要上传任何敏感或重要的数据。请将此服务器仅用于学习和实验目的,以确保您的数据安全。

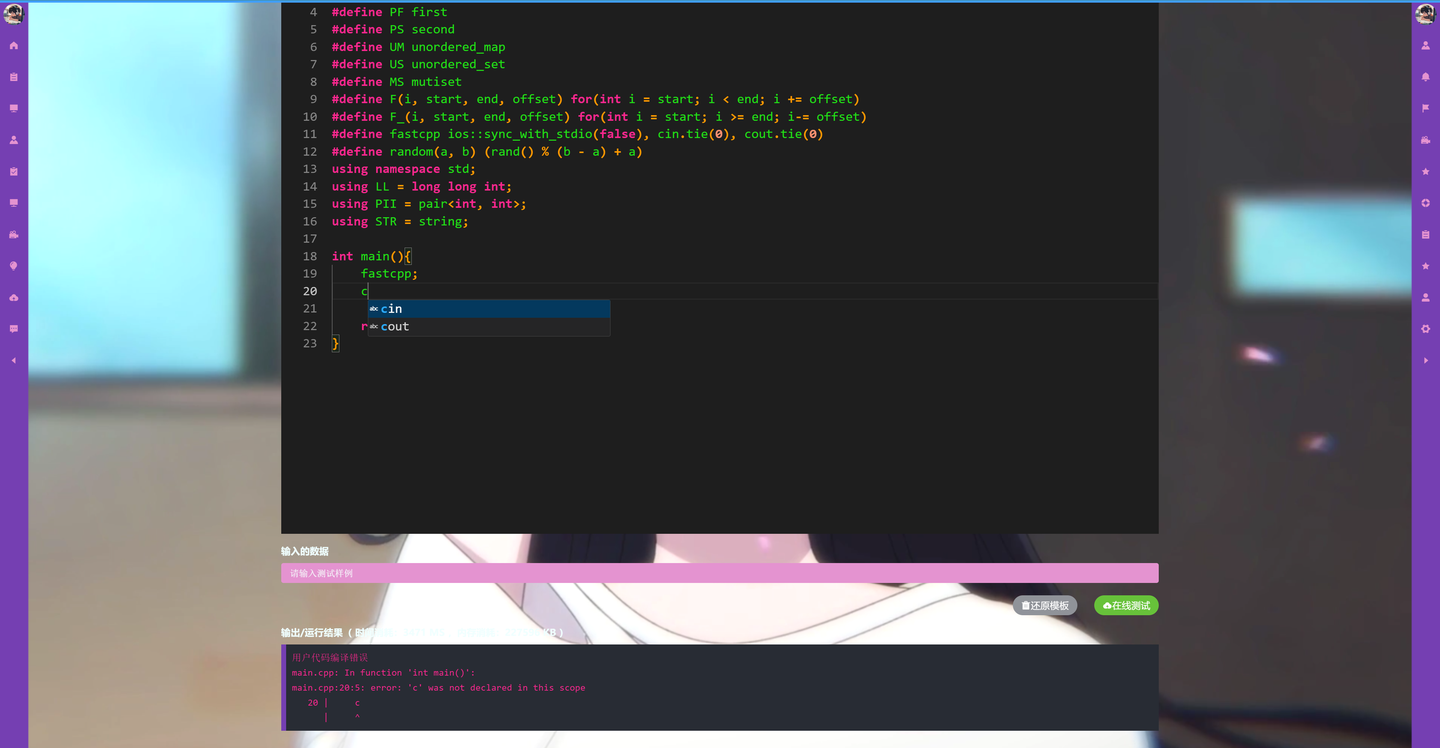
免费在线WEB代码编辑器(https://docs.ltpp.vip/LTPP-WEB-IDE/)
无论你是开发者还是学生,编程环境的搭建和管理可能会占用你宝贵的时间和精力。现在,有一款强大的免费在线代码编辑器,支持多种编程语言,让您可以随时随地编写和运行代码,提升编程效率,专注于创意和开发。
多语言支持,无缝切换这款在线代码编辑器支持包括C、C++、JavaScript、TypeScript、Go、Rust、PHP、Java、Ruby、Python3以及C#在内的多种编程语言,无论您的项目需要哪种语言,都能在这里找到支持。
在线运行,快速定位问题您可以在编写代码的同时,即时运行并查看结果,快速定位并解决问题,提高开发效率。
代码高亮与智能提示编辑器提供代码高亮和智能提示功能,帮助您更快地编写代码,减少错误,提升编码质量。
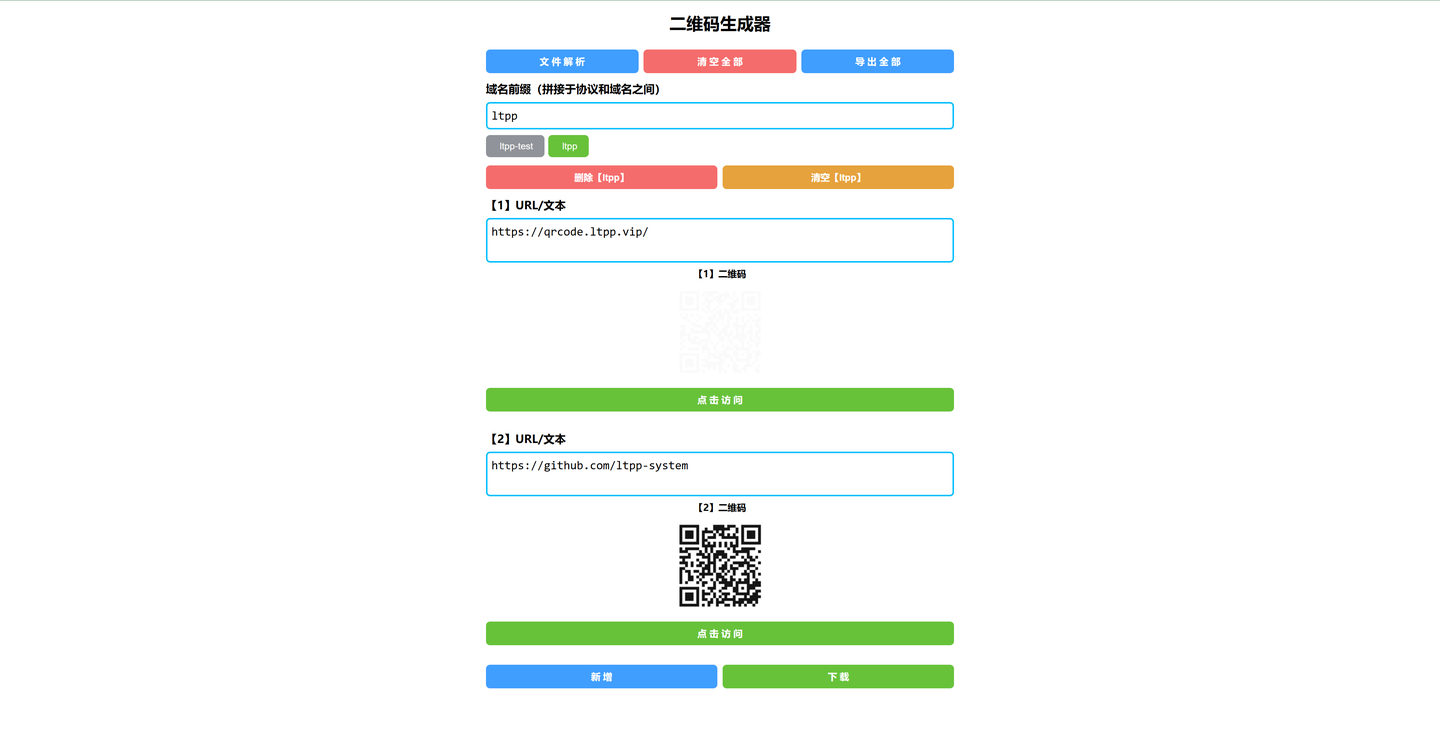
免费二维码生成器(https://docs.ltpp.vip/LTPP-QRCODE/)
二维码(QR Code)是一种二维条码,能够存储更多信息,并且可以通过智能手机等设备快速扫描识别。它广泛应用于各种场景,如:
企业宣传企业可以通过二维码分享公司网站、产品信息、服务介绍等。
活动推广活动组织者可以创建二维码,参与者扫描后可以直接访问活动详情、报名链接或获取电子门票。
个人信息分享个人可以生成包含联系方式、社交媒体链接、个人简历等信息的二维码。
电子商务商家使用二维码进行商品追踪、促销活动、在线支付等。
教育教师可以创建二维码,学生扫描后可以直接访问学习资料或在线课程。
交通出行二维码用于公共交通的票务系统,乘客扫描二维码即可进出站或支付车费。 功能强大的二维码生成器通常具备用户界面友好,操作简单,即使是初学者也能快速上手和生成的二维码可以在各种设备和操作系统上扫描识别的特点。