GPT-4o简介
在5月14日的OpenAI举行春季发布会上,OpenAI在活动中发布了新旗舰模型"GPT-4o"!据OpenAI首席技术官穆里·穆拉蒂(Muri Murati)介绍,GPT-4o在继承GPT-4强大智能的同时,进一步提升了文本、图像及语音处理能力,为用户带来更加流畅、自然的交互体验。
GPT-4o的"o"代表"omni",源自拉丁语"omnis"。在英语中"omni"常被用作词根,用来表示"全部"或"所有"的概念。GPT-4o是一个多模态大模型,支持文本、音频和图像的任意组合输入,并能生成文本、音频和图像的任意组合输出。与现有模型相比,它在视觉和音频理解方面尤其出色。
GPT-4o的几个核心炸裂能力
 图片来源:OpenAI官网截图题
图片来源:OpenAI官网截图题
能力一:"实时"互动,表达富有情感,视觉功能更强
OpenAI表示,GPT-4o显著提升了AI聊天机器人ChatGPT的使用体验。虽然ChatGPT长期支持语音模式,可将ChatGPT的文本转为语音,但GPT-4o在此基础上进行了优化,使用户能够像与助手互动一样自然地使用ChatGPT。
例如,用户现在可以在ChatGPT回答问题时中断它。而且,新模型能够提供"实时"响应,甚至能够捕捉到用户声音中的情感,并以不同的情感风格生成语音,如同真人一般。此外,GPT-4o还增强了ChatGPT的视觉功能。通过照片或屏幕截图,ChatGPT现在可以迅速回答相关问题,从"这段代码是做什么用的"到"这个人穿的是什么品牌的衬衫"。
OpenAI的演示表明,机器人现在可以与人类进行实时对话,与真人水平几乎没有区别。如果最终版本像OpenAI官方的演示一样,那么OpenAI似乎已经从某种程度上验证AI将在多大程度上改变我们的世界。
能力二:多语言表现出色,响应速度几乎与真人无异
GPT-4o的多语言功能得到了增强,在50种不同的语言中表现更佳。在OpenAI的API中,GPT-4o的处理速度是GPT-4(特别是 GPT-4 Turbo)的两倍,价格则是GPT-4 Turbo的一半,同时拥有更高的速率限制。
OpenAI官网介绍称,GPT-4o最快可以在232毫秒的时间内响应音频输入,平均响应时间为320毫秒,这与人类在对话中的响应时间相似。它在英语文本和代码方面的性能与GPT-4 Turbo的性能一致,并且在非英语文本方面的性能有了显著提高。
用户只需发出简单的"嘿,ChatGPT"语音提示,即可获得代理的口语回应。然后,用户可以用口语提交查询,并在必要时附上文字、音频或视觉效果------后者可包括照片、手机摄像头的实时画面或代理能"看到"的任何其他内容。
能力三:在推理及音频翻译方面树立新标杆
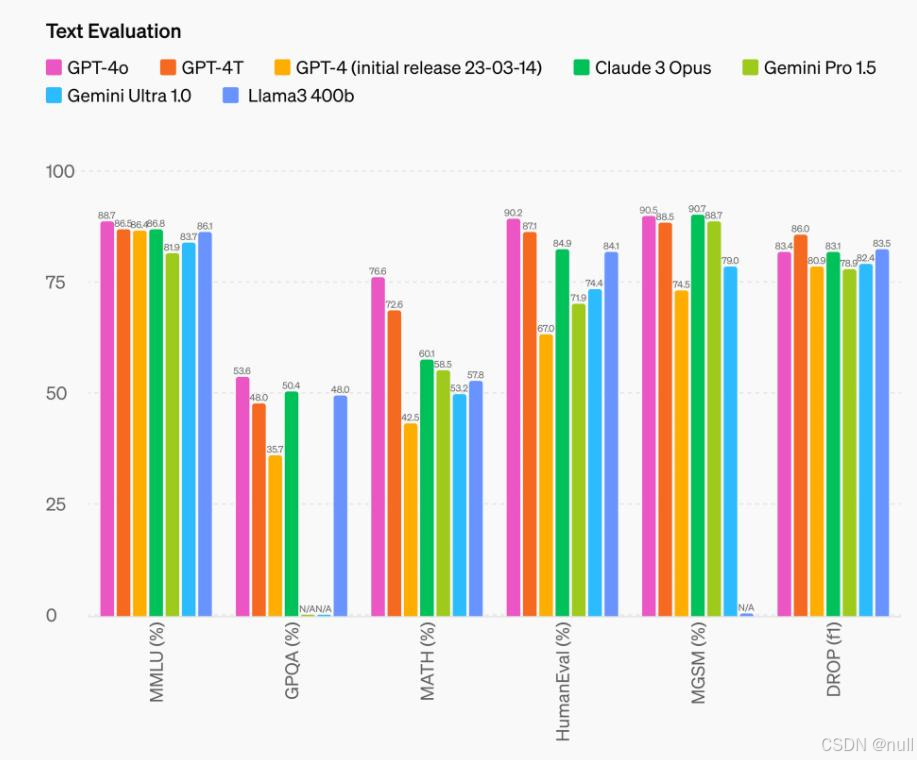
据OpenAI研究人员William Fedus透露,GPT-4o实际上就是上周在LMSYS模型竞技场上引起整个AI圈疯狂试用的GPT-2模型的另一版本,并附上了GPT-4o的基准测试评分对比图,相比GPT-4 Turbo提升了超过100个单位。
推理能力方面,GPT-4o在MMLU、GPQA、MATH、HumanEval等测试基准上均超越GPT-4 Turbo、Claude 3 Opusn、Gemini Pro 1.5等前沿模型,取得最高分。
 图片来源:OpenAI
图片来源:OpenAI
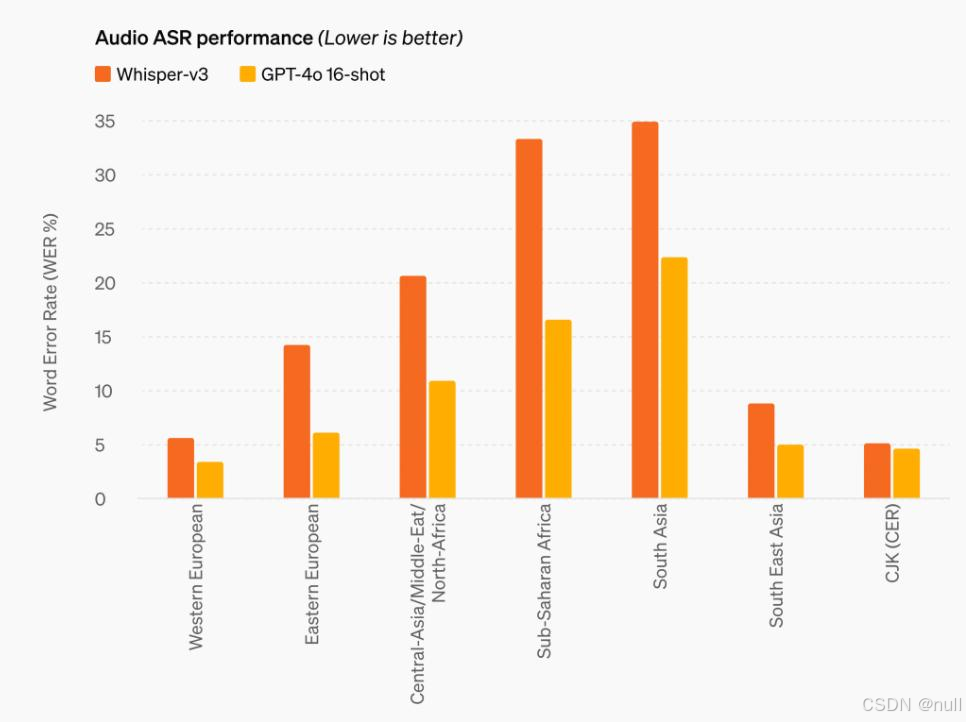
音频ASR(智能语音识别)性能方面,GPT-4o相比Whisper-v3,在所有语言的语音识别性能上均大幅提高,尤其是资源较少的语言。
 图片来源:OpenAI
图片来源:OpenAI
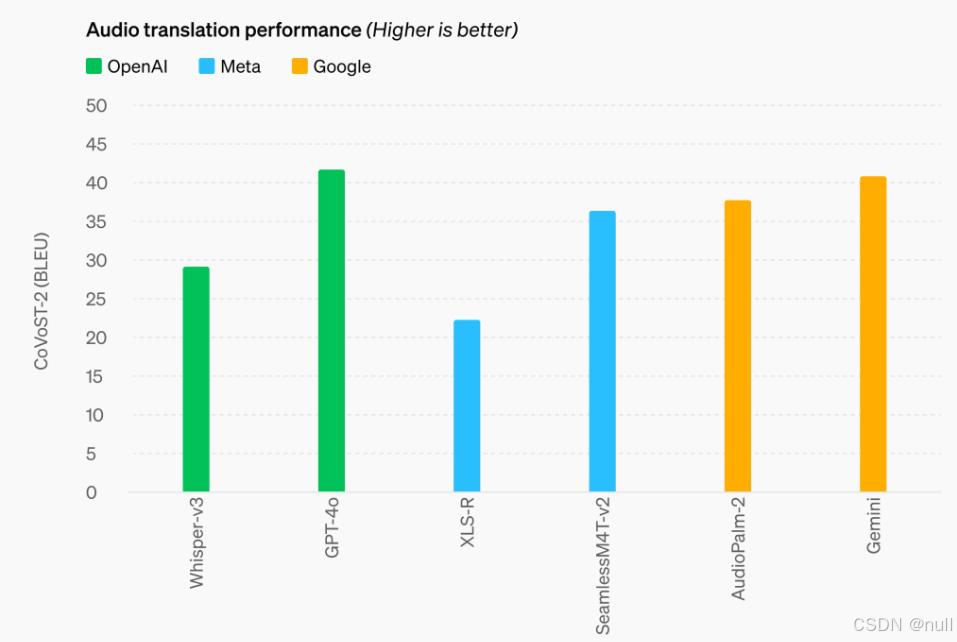
音频翻译方面,GPT-4o也树立了新的标杆,在MLS基准测试中优于Whisper-v3以及Meta、谷歌的语音模型。
 图片来源:OpenAI
图片来源:OpenAI
GPT-4与GPT-4o区别
整体来说,GPT-4和GPT-4o在性能、响应速度、成本效益、多模态处理能力、技术优化、应用场景和计费方式等方面存在明显的区别。GPT-4o作为GPT-4的特别版本,在特定任务上进行了优化,具有更高的效率和更低的成本,同时保持了与GPT-4相当的智能水平。详细对比如下:
性能特点
- GPT-4:作为OpenAI的强大大型语言模型(LLM),它能够处理从编写电子邮件到生成代码等一系列任务,且能适应特定的语气、情感和流派。GPT-4还能生成代码、处理图像并解释26种语言。
- GPT-4o:作为GPT-4的特别版本,它在某些特定的任务上进行了优化,如编程辅助、数据分析等,使其在这些领域的表现更加高效。GPT-4o具有"全能"的特性,能够处理文本、音频和视觉的输入,并生成相应的输出。
响应速度
- GPT-4o的响应速度是GPT-4 Turbo的两倍,具体到音频输入的响应时间,最短可达232毫秒,平均320毫秒,与人类在对话中的响应速度相当。这使得GPT-4o在实时交互方面具有明显优势。
成本效益
- GPT-4o的使用成本比GPT-4低50%,这对于开发者来说是一个重大的吸引力,因为它降低了实施成本,同时提高了使用率限制。
多模态处理能力
- GPT-4o支持文本、音频、图像任意组合的输入,并能以同样的方式输出。它不仅能处理传统的文本数据,还能理解和生成与之相关的音频和视觉内容。GPT-4虽然能够解释图像,但其多模态处理能力相对GPT-4o较弱。
技术优化
- GPT-4o基于Transformer架构进行了优化,采用了更深层次的神经网络和更高效的注意力机制,使得模型在处理长文本时表现更加优异。此外,GPT-4o还引入了混合专家模型(Mixture of Experts),使得在特定任务上能够调用特定的专家子模型,提高了处理效率和输出质量。
应用场景
- GPT-4设计为多功能工具,适用于广泛的任务,从文学创作到商务咨询都能提供支持。GPT-4o则更多地针对需要高效计算和特定技术解决方案的场景进行了优化,如快速编写和检查代码。
计费方式
- GPT-4通常按照生成的文本量(即使用的代币数)来计费,适合需要大量文本处理的用户。GPT-4o可能提供更多的计费选项,例如按执行任务的次数计费,这样可以为频繁执行特定任务的用户节省成本。
GPT-4o与GPT-4:用户该如何选择
选择哪一个模型,主要取决于您的具体需求:
- 如果您的工作涉及广泛的文本生成、创意写作或需要复杂的语言理解,GPT-4是更合适的选择。
- 如果您主要关注程序编写、数据处理或其他需要快速和高效解决方案的技术任务,GPT-4O将提供额外的优势。
如何体验GPT-4o
目前官方给出的免费限制在一定的消息数量上,超过这个消息量后,免费用户的模型将被切换回ChatGPT,也就是GPT3.5,具体见官方说明。