前言
限流,熔断降级概念
限流:顾名思义,就是对一个资源(服务或者接口都可以算资源)的访问进行限制。简单来说就是限制单位时间内允许资源被访问的次数。常见的算法就是令牌桶算法。
降级:降级其实是一种资源优化策略,当服务器压力剧增时候,关闭某些服务接口或者页面,将服务器资源给到核心业务上,从而确保核心业务正常。常见的作法就是服务接口拒绝(调用接口直接返回某种错误码,然后前端显示忙碌稍后再试),延迟持久化(接口正常访问,但是接口的一些io操作异步进行或者直接丢队列里不进行,等有空闲资源再消费队列里的数据)
熔断:熔断其实是一种**预防微服务链路整体崩溃的措施,**比如,某个服务调用链是A->B->C,假设此调用链是同步阻塞的,并且C是一个极耗时的操作,那么,当并发高时,就会出现很多请求卡在->C这一步。如此一来,轻则A的链接池被打满,导致后续服务进不来,重则服务器崩溃。对这类场景的预防措施,就叫熔断。常见做法和降级相同。
sentinel的熔断保护方式:
客户端请求到达资源后,进行熔断条件判断,如果达到熔断条件,则进入熔断,当进入熔断一定时间后(通常是配置的),进入半开状态,允许部分请求通过以检测资源的健康状态。如果这些请求成功,则关闭熔断器;如果失败,则再次打开熔断器。

sentinel概念
sentinel就是用来帮助我们实现熔断降级限流的组件。使用上来讲,它分为两部分一部分是控制台,一部分是核心库
控制台就是一个web界面,我们通过启动sentinel控制台,能得到一个可视化的界面,在使用章节会详细说。
核心库简单说就是我们服务引的jar包。
使用
1.sentinal 的 dashboard部署
step 1: 下载sentinel的jar包:
https://github.com/alibaba/Sentinel/releases
** sentinel已经很久没有更新了,下载最新的1.8.8就行 **
step2:启动jar包 (其实sentinel也是个springboot项目)
java -Dserver.port=9725 -Dcsp.sentinel.dashboard.server=localhost:9725 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard-1.8.8.jar
启动成功可看到日志为:
step3:访问sentinel的控制台 http://localhost:9725/ 端口为刚才启动参数中的端口
进入登录界面,默认用户名和密码都是sentinel
登录成功后看到如下界面:
2.服务集成sentinal
** 本章节继续前面几章节内容,如何创建boot服务不再赘述 **
step1:引入依赖包 以admin服务(一个是spring cloud项目下的spring boot服务)为例
<!-- sentinel依赖 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>step2:在配置文件中的 spring.cloud节点下新增配置
sentinel:
transport:
eager: true # 是否提前触发 Sentinel 初始化
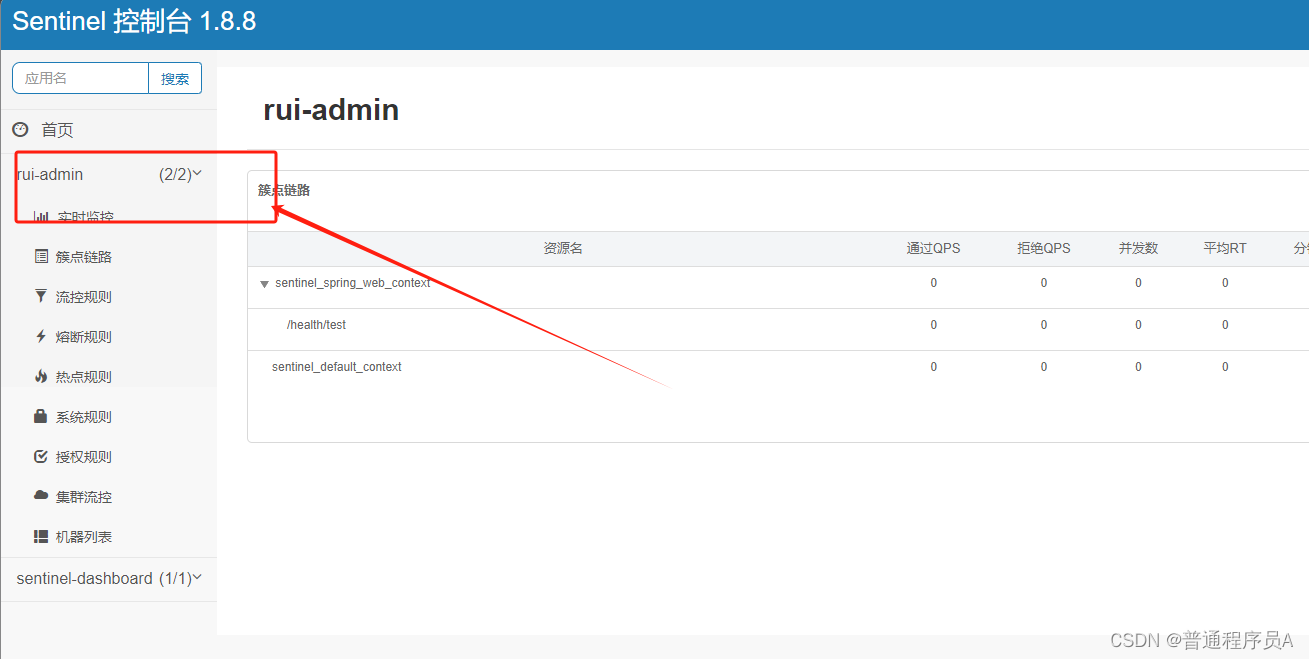
dashboard: localhost:9725启动服务,就可以看到,服务已经注册到了控制台(我使用不同端口启动了两个rui-admin,模拟一个集群,所以看到,服务后面的数字是2)
3.dashboard中各种规则讲解
3.1. 限流
流控的设置通过点击下图箭头2处进入
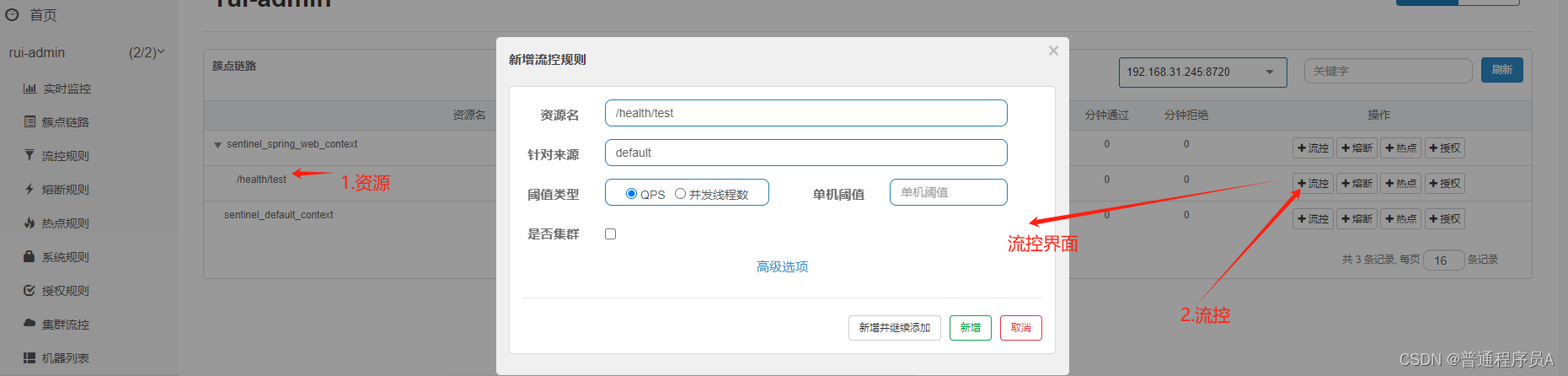
分几张图来介绍限流配置中的能力
1)基础设置

QPS: 每秒访问量
并发线程数: 并发线程数量。理想情况下,一个用户的访问就是一个线程,所以这个模式的很多时候用于控制访问用户数量。
集群:
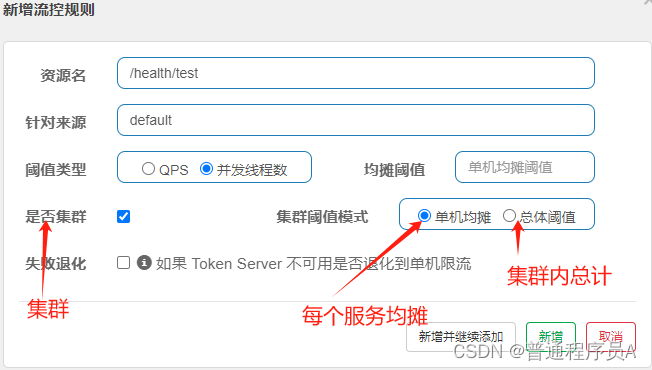
2)点击高级选项:
直接:
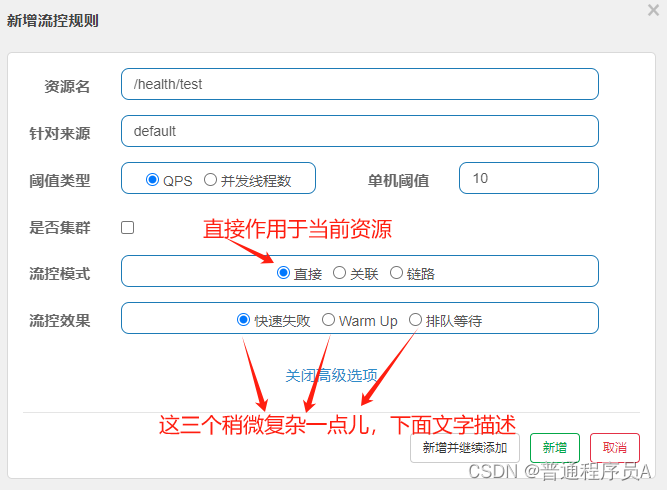
快速失败: 直接进行限流,再访问时候会报错我,无法访问资源
warm up :热身,选择后会出来一个框,让选多少秒,意思就是,在一定秒数内,缓慢放开访问数量,在最终允许访问数量达到阈值。这种模式的意义在于,服务刚启动的时候,一些接口设置有缓存,由于服务刚启动,缓存中还没有值,需要缓慢的放开请求让缓存数据产生,然后再接纳大并发量,避免刚启动服务,瞬时来巨大的并发量导致异常。

排队等待:排队等待的意思就是匀速的让请求进入资源,选择这个选项后,会选择一个超时时长,意思是超时等待多久的请求需要被拒绝。

关联:
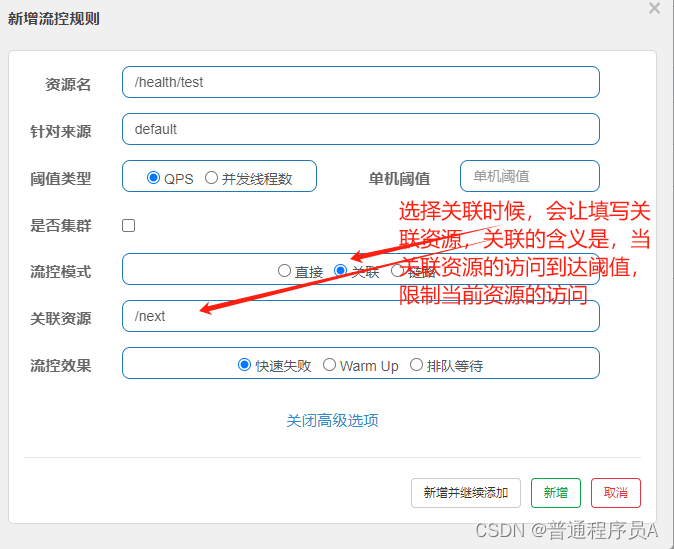
如图,关联资源的含义是,当关联的资源的访问达到阈值,对当前资源进行限流。最常见的场景就是,关联资源对数据库进行操作,比较消耗性能,当前资源也要获取数据库,这种情况下会使用关联。
链路:
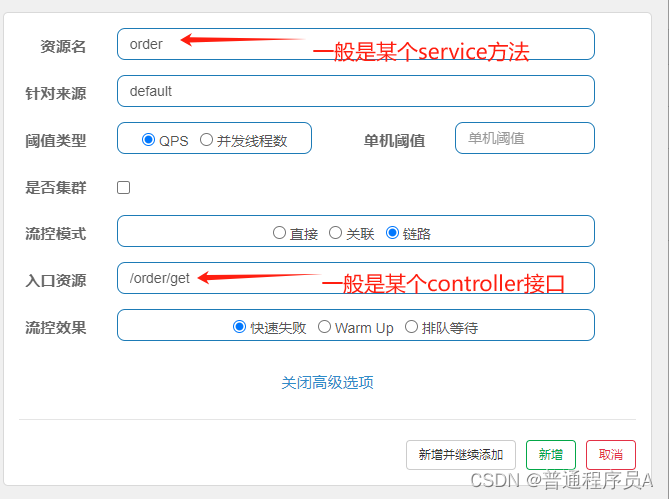
该规则的含义就是,当入口资源的访问道道阈值,限制资源的访问。入口资源一般就是某个controller的mvc接口,资源一般是某个service的实现类方法。
3.2. 熔断
1.慢调用比例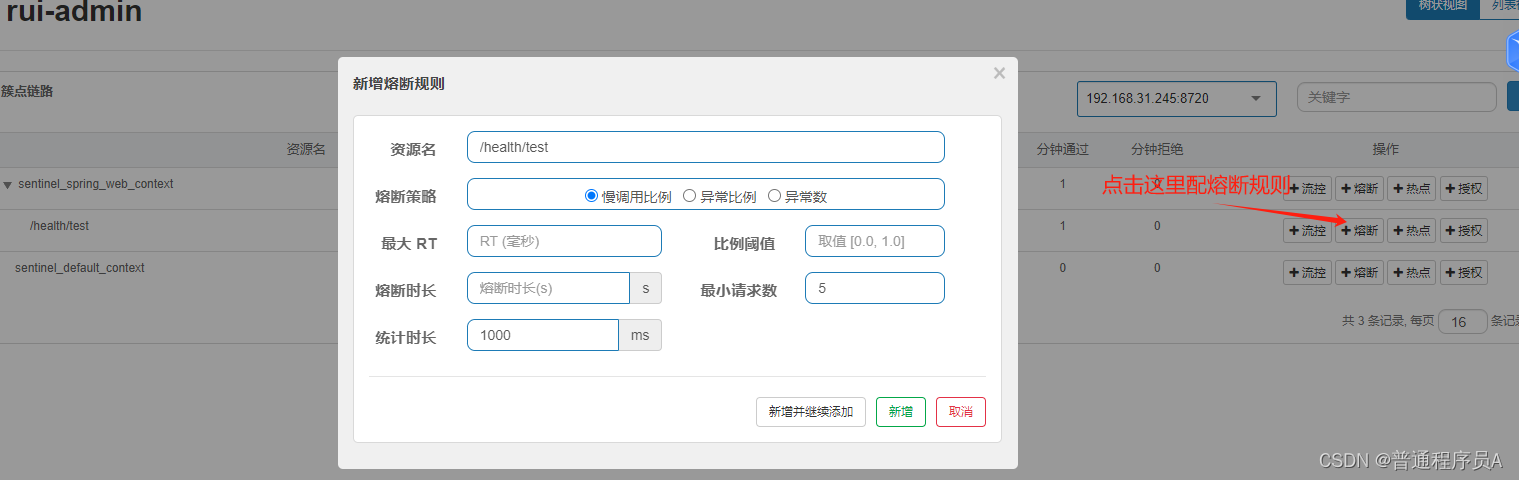
最大RT:该资源最慢响应速度,单位是毫秒。
比例阀值:达到最大最大RT的请求和总请求的比例。
熔断时长:对该资源进行熔断的时间。
最小请求数:请求数量到达最小请求数量才会开始计算熔断
统计时长:一个时间范围,可以是每1分钟、每3小时。根据这个时间内的请求,来统计总请求和数
2.异常比例
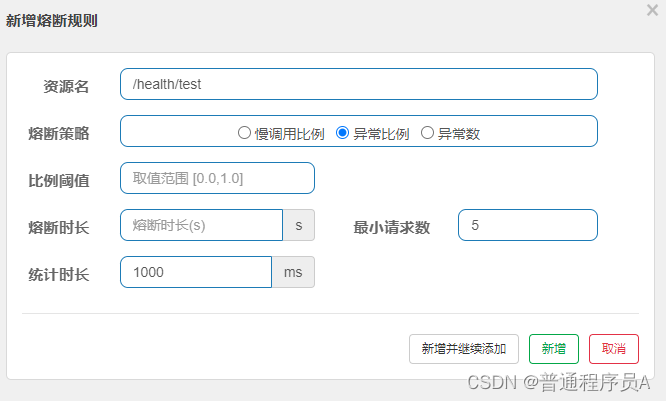
比例阀值:达到最大最大RT的请求和总请求的比例。
熔断时长:对该资源进行熔断的时间。
最小请求数:请求数量到达最小请求数量才会开始计算熔断
统计时长:一个时间范围,可以是每1分钟、每3小时。根据这个时间内的请求,来统计总请求和数
3.异常数量:
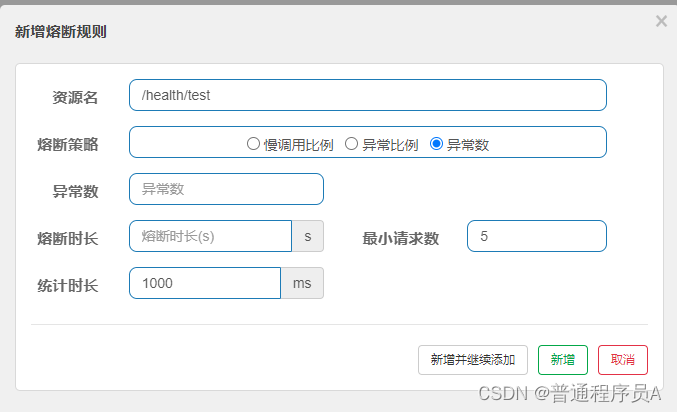
跟上面一样,没啥说的
生产中的如何配置sentinel
1. 利用nacos做配置持久化
1.1. 为何使用nacos做持久化
在上一节我们介绍了sentinel的限流和熔断的使用,通过dashboard,我们对资源配置了限流和熔断规则,但是这种配置是没有进行持久化的,当服务重启时,我们的配置会失效。因此,在实际生产中,需要对受保护资源进行可被持久化的配置。
1.2. 使用nacos进行sentinel的持久化配置
step1:引入依赖
在前三篇的基础上,增加如下依赖:
<!--以nacos作为sentinel数据源的依赖-->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>step2:编写配置
流控配置:
[
{
"resource":"/health/test",
"limitApp":"default",
"grade":1,
"count":2,
"strategy":0,
"controlBehavior":0,
"clusterMode":false
}
]resource:表示要进行流量控制的资源,本例中为"/test flow rule",也就是对"/test flow rule"的访问进行流量控制
limitApp: 表示流量控制的针对范围,这里设置为"default",表示针对默认组的应用进行流量控制;
grade: 表示流量控制的维度 0 代表根据并发数量来限流1 代表根据 QPS 来进行流量控制count: 表示允许通过的请求数,这里设置为 2,表示当请求超过 2次时,将触发流量控制;
strategy: 表示流量控制的策略
0-直接 1-关联 2-链路
controlBehavior:表示流量控制的行为
0-快速失败 1-Warm UP 2-排队等待
clusterMode: 表示是否使用集群模式,这里设置为 false,表示不使用集群模式
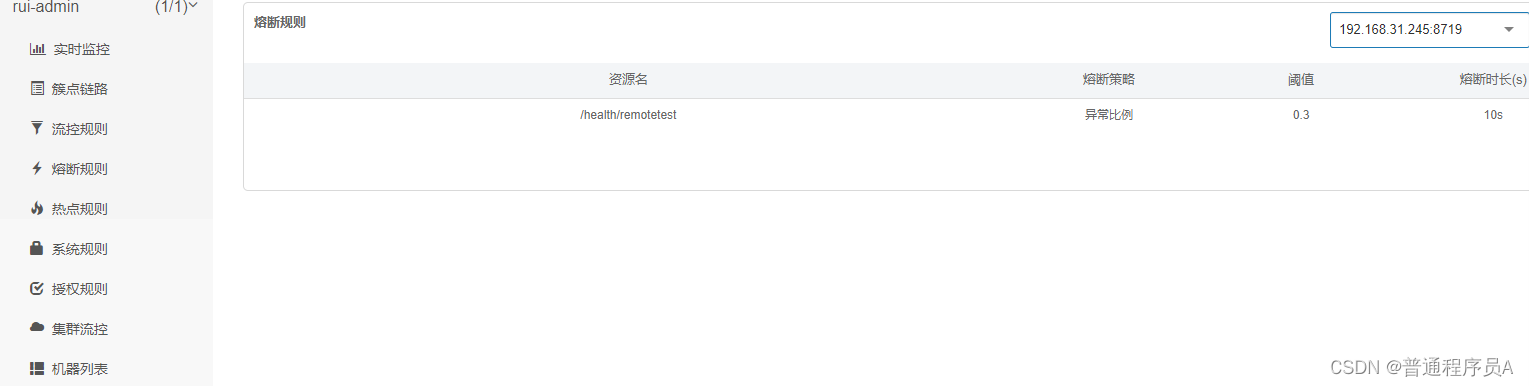
熔断配置:
[
{
"resource":"/health/remotetest",
"limitApp":"default",
"grade": 1,
"count": 0.3,
"timeWindow": 10,
"minRequestAmount":5
}
]resource:表示要进行熔断降级控制的资源,本例中为"/health/remotetest",也就是对"/health/remotetest"的访问进行熔断降级控制;
limitApp: 表示熔断降级控制的针对范围,这里设置为"default",表示针对默认组应用进行熔断降级控制;
grade: 表示熔断降级控制的维度
0-慢调用比例 1-异常比例 2-异常数策略
count:代表20%异常比例
timeWindow: 表示熔断时长10秒
minRequestAmount: 表示在熔断前必须在时间窗口内通过的请求次数,本例中设置为5;
step3:yml中增加sentinel配置
spring:
application:
name: rui-admin
profiles:
# 环境配置
active: dev
# cloud
cloud:
# sentinel
sentinel:
transport:
dashboard: localhost:9725
eager: true # 是否提前触发 Sentinel 初始化
datasource: # sentinel 持久化配置
flow: # 流控
nacos:
server-addr: 127.0.0.1:8848
data-id: sentinel-flow-rules
group-id: DEFAULT_GROUP
rule-type: flow
degrade: # 熔断
nacos:
server-addr: 127.0.0.1:8848
data-id: sentinel-degrade-rules
group-id: DEFAULT_GROUP
rule-type: flow完成以上步骤后,启动服务,打开sentinel的dashboard,可以看到:
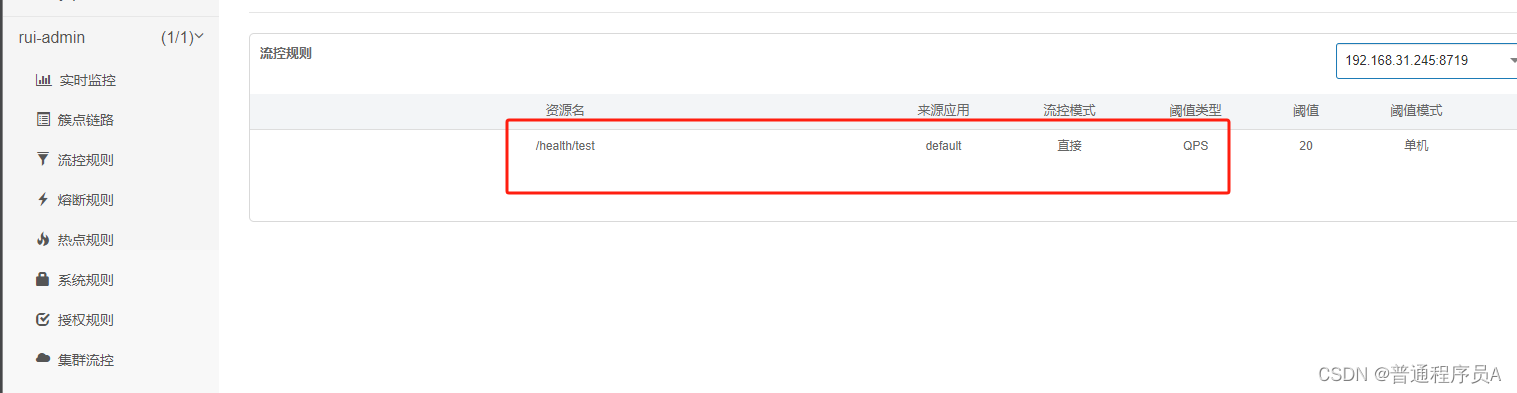
2. 使用注解定义资源
2.1.使用场景: 生产中,我们可能会对一些service级别,而非controller级别的方法做限流或熔断,需要将service定义为资源,并作一些自定义的配置。这种情况,就可以使用@SentinelResource这个注解来完成
2.2. 使用方法介绍:
直接再方法上加上@SentinelResource注解即可,例如:
@Service
public class TestService implements ITestService {
@Override
@SentinelResource(value = "annotition_resource")
public String doSth() {
return "do sth";
}
}之后,访问对应的调用的controller,然后打开控制台,就能看到该资源了
2.3.SentinelResource 的其他属性
该注解还支持另外两个属性,如下:
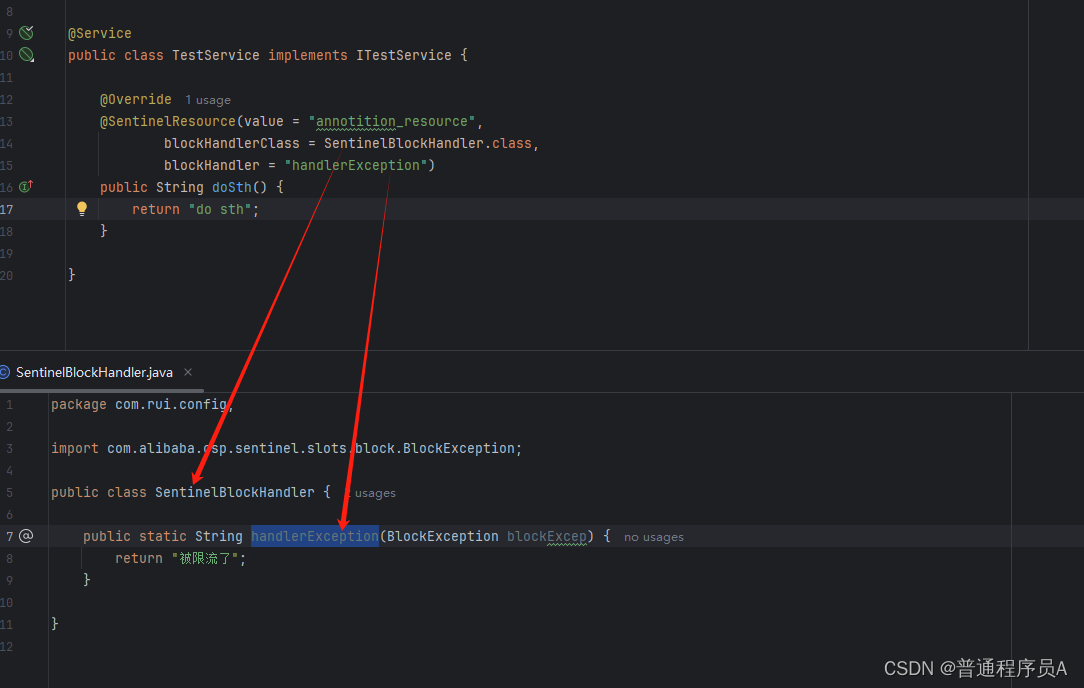
HandlerClass代表一个异常处理类, Handler是具体的处理方法。
实际上这个用的不多,异常的统一处理实际上会放在gateway中。我们用SentinelResource 的时候大多是为了标记一些无法自动识别的资源,对于handler这个功能大家了解一下这个注解还有这个能力就好。
3.gateway整合sentinel
实际开发中,很多时候我们直接将一个服务当作资源,对整个服务进行熔断,所以,很多情况会直接把sentinel集成到gateway服务中,如果要在gateway服务中集成sentinel,需要进行如下操作:(以对oath服务进行流控为例)
step1:引入依赖:
<!-- SpringCloud Alibaba Sentinel -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
<!-- SpringCloud Alibaba Sentinel Gateway -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-sentinel-gateway</artifactId>
</dependency>step2:同本章节刚讲过的持久化到nacos,配置对应的配置文件及编写sentinel的配置json。
以对oauth服务限流为例:
json:
[
{
"resource": "rui-auth",
"count": 500,
"grade": 1,
"limitApp": "default",
"strategy": 0,
"controlBehavior": 0
}
}yml配置:
sentinel:
# 取消控制台懒加载
eager: true
transport:
# 控制台地址
dashboard: 127.0.0.1:8718
# nacos配置持久化
datasource:
ds1:
nacos:
server-addr: 127.0.0.1:8848
dataId: sentinel-ruoyi-gateway
groupId: DEFAULT_GROUP
data-type: json
rule-type: gw-flow基本原理及工作流程
1.基本原理
Sentinel为springboot提供了一个starter依赖,引入这个依赖后,会实例化一个Interceptor拦截所有的http请求并进行埋点(Slot),所以,我们只需要引入了spring-cloud-starter-alibaba-sentinel这个依赖,所有的http接口就都会收到sentinel的保护。
一张图简单说明Sentinel执行过程
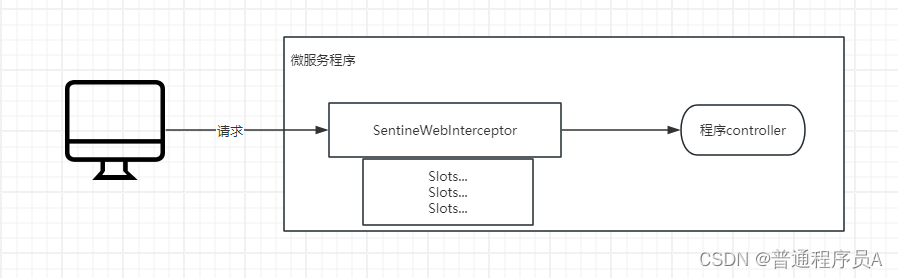
再说一下Sentinel的Slot,sentinel维护了一个SlotChains,请求进入后会一个个slot的向下执行,整个执行链路结束后才能正常进入请求,如果某一步校验不通过则执行对应熔断或者限流。
用一张图说一下各个Slot:
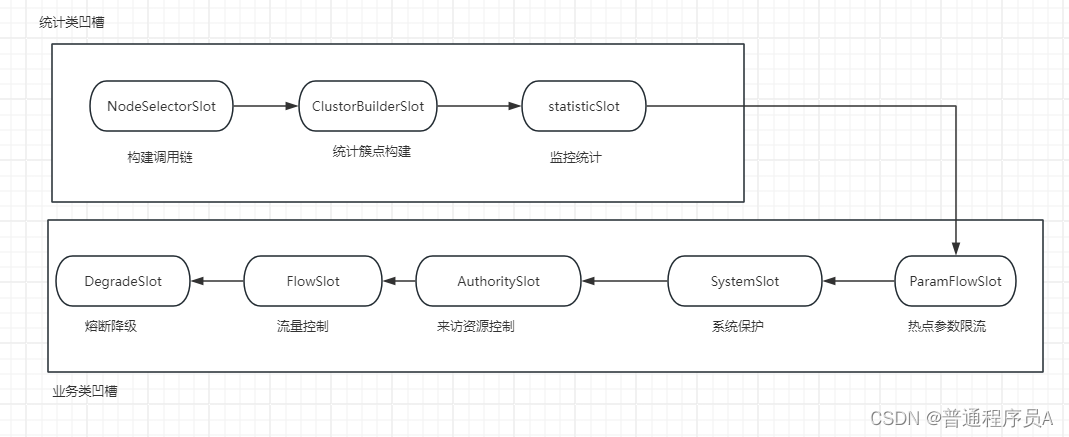
sentinel中,重要的几个插槽如上图所示,大致分为两类,一类是统计类,一类是做各种判定及业务功能。
重点说一下StatisticSlot这个,它是核心sentinel核心之一,用于实现数据的统计。,面试中常问的滑动事件窗口算法就是它实现的。
滑动时间窗口算法:
其功能是为了统计过去一段时间内数据流量有多少。在此算法产生之前,我们统计用的是固定时间窗口算法,所谓固定时间窗口算法,就是按照秒/分这种时间来统计流量,比如固定出一秒的范围,然后看当前一秒内有多少请求。
这种算法有一个缺陷,比如,规定秒流量最高400,在第一秒的第800-900毫秒,来了350个请求,然后在第一秒结束的第100毫秒-200毫秒,又来了350个请求。按照固定窗口算法,这个访问量是ok的,因为第一秒和第二秒流量都在范围内,但是实际上这700个请求是在400毫秒内就发生了,所以它实际上会给系统带来很大的压力。
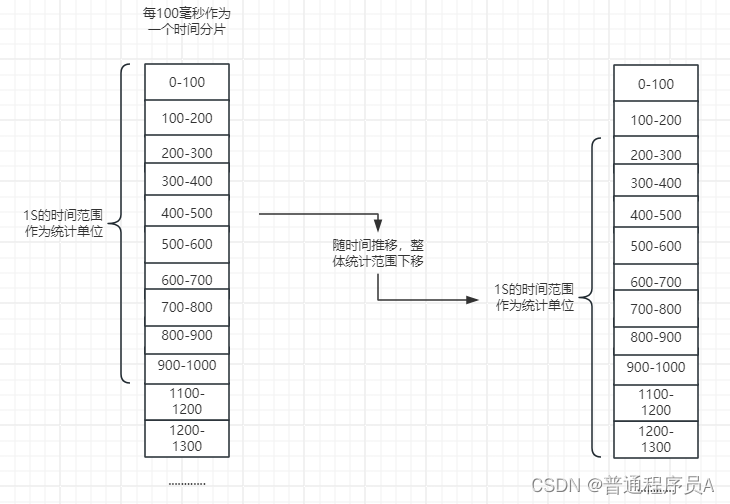
因此,就有了滑动时间窗口算法。滑动时间窗口算法,简单来说就是把一个固定时间切割,然后统计时候,由当前时间片向前推算。比如,仍然是统计1s内的流量,将1秒切割为10个时间窗口,每100毫秒是一个时间片,统计时,求当前时间片及当前时间片前面的9个时间片的流量和。以此方式,避免了固定时间窗口存在的问题。
一张图理解滑动时间窗口:
面试常问
sentinel其实就我的经验来看,问的公司不多,因为实际上很多公司根本用不到....,别看现在微服务,高并发喊得飞起,但是其实真的需要高并发保护的项目并不算多。
-
sentinel的运行原理 (见本文 基本原理及工作流程)
-
滑动时间窗口算法 (见本文)
-
sentinel的dashboard和服务是怎么通讯的?(http,短链接)
-
限流策略有哪些,熔断策略有哪些 (见本文 dashboard 中各种规则讲解)
5.sentinel中如何自定义限流处理逻辑 (见本文 如何使用注解定义资源)
6.sentinel的实时监控怎么实现的 (这个其实就结合sentinel服务和dashboard的通讯及各个统计Slot来说)
- sentinel如何保证自身的高可用 (就是聊sentinel的集群模式搭建)
sentinel目前的问题,个人感想
Sentinel最大的问题就是阿里不维护了,项目在阿里手里,但是阿里已经很久没有更新项目了,到了1.8版本之后基本不动了,所以对于限流,熔断,除了Sentinel之外,需要再掌握个别的用来防身,比如resilience4j,