目录
处理不平衡数据集
1.分类需求描述
如果你在处理一个机器学习应用,其中正例和负例的比例(用于解决分类问题)非常不平衡,远远不是50-50,常规的错误指标如准确率不适用。通过一个检测罕见疾病的例子,指出即使算法有99%的准确率,可能仍然没有实际意义,因为简单的总是预测为0的算法也能达到类似的准确率。因此,在这种情况下,应该使用其他错误指标来评估算法的表现。
2.计算精确率和召回率
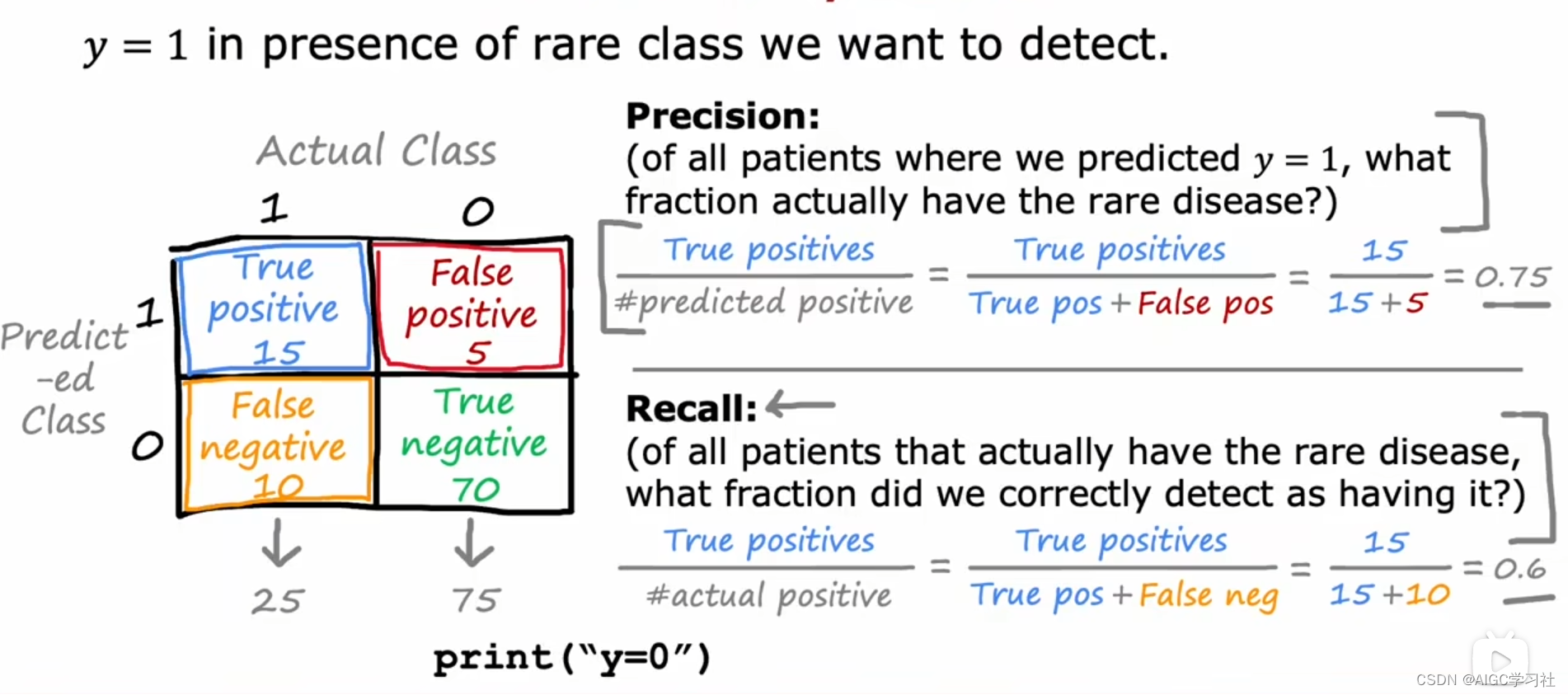
通过构建混淆矩阵,可以计算出真阳性(实际预测都为1)、假阳性(实际为0预测为1)、真阴性(实际预测都为0)和假阴性(实际为1预测为0),从而求得准确率和召回率。
准确率:有多少人真正患有罕见病?真阳性数量/被预测分类为真阳性的数量。
召回率:所有患有罕见病的人中,我们正确检测到多少人有这种病?真阳性数量/实际真阳性的数量。
在罕见类别中,这两个指标可以帮助更好地评估算法的有效性。
权衡精确率和召唤率
1.手动调整阈值
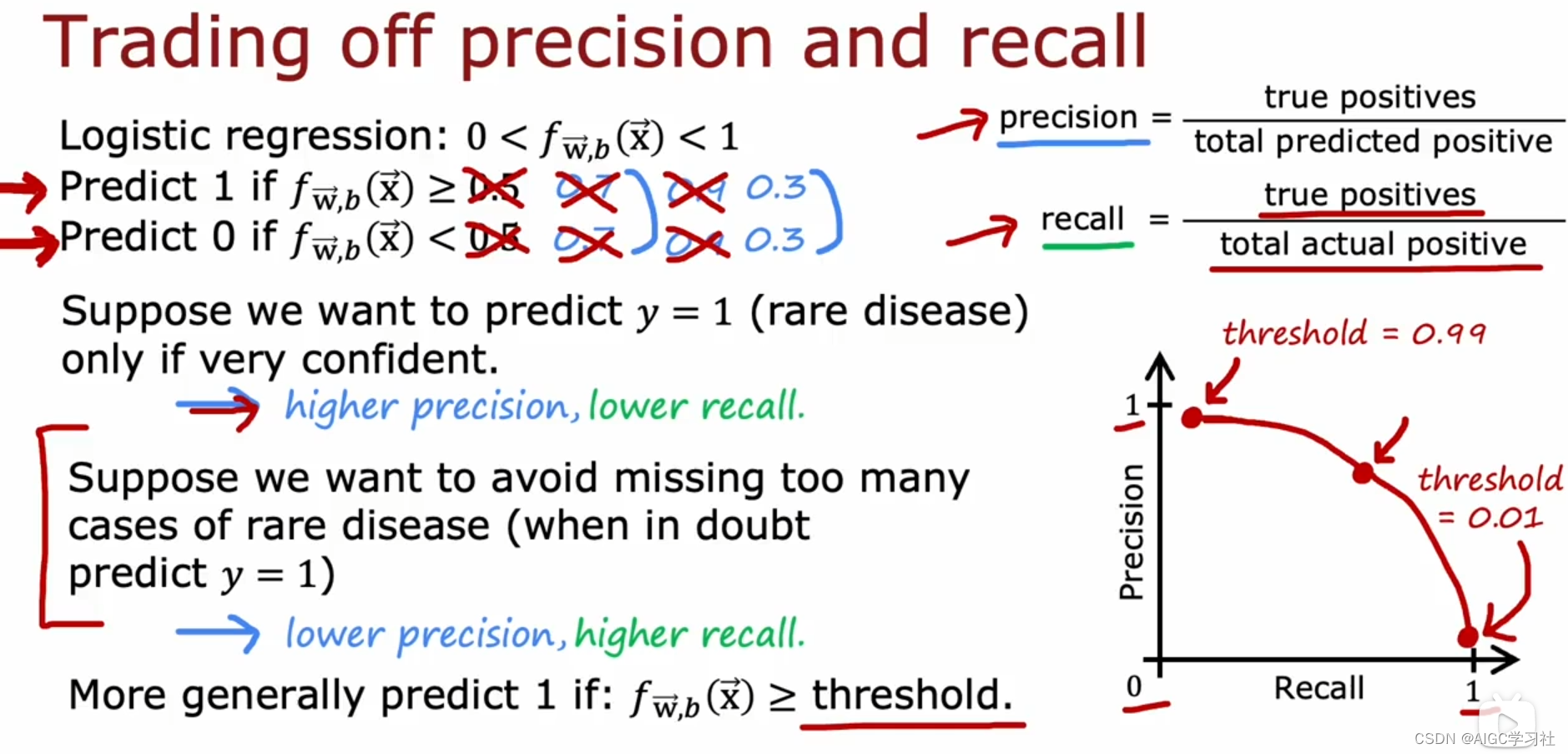
在理想状况下,我们追求高精确度和高召回率的机器学习算法,但现实中这两者往往不可兼得。通过调整预测模型(如逻辑回归)的阈值,可以在精确度和召回率之间进行权衡
-
提高阈值(如从0.5提高到0.7或0.9)会增加模型的精确度,因为它仅在高度确信时预测为正例,减少了假阳性,但这也降低了召回率,因为一些实际的正例可能因标准过高而被遗漏。
-
降低阈值(如降至0.3)会提升召回率,因为模型在较低的确信度下也会预测为正例,减少了假阴性,但同时引入了更多的假阳性,降低了精确度。
选择合适的阈值需依据具体应用场景:
- 如果错误预测的代价很高(如误诊导致不必要的治疗),可能倾向于提高阈值保证精确度。
- 若漏诊的后果更严重(如错过治疗时机),则可能降低阈值以提高召回率。
通过绘制精确度-召回率曲线并选择曲线上的特定点,可以帮助平衡精确度和召回率,以适应不同的成本效益分析或应用需求。手动调整阈值是一种策略,它依赖于对应用场景特性的深入理解,无法简单地通过自动化过程如交叉验证来完成。
2.F1分数
为了自动平衡精度和召回率,可以使用 F1 分数。精度和召回率作为两个不同的指标,可能会使选择最佳算法变得困难。F1 分数结合了精度和召回率,更强调较低的一个值,提供了一个综合指标来选择最佳算法。
计算 F1 分数的方法是平均 1/精度 和 1/召回率 的值,然后取其倒数。这种方法比简单平均更有效,因为它避免了精度或召回率特别低的情况。

总结
在处理正负样本比例严重不平衡的问题时,传统的错误指标如准确率并不适用。一个算法可能在测试集上达到1%的错误率,看起来效果很好,但如果疾病非常罕见,简单地预测所有患者没有疾病的非学习算法也能达到99.5%的准确率。这表明准确率不足以评估算法的有效性。在这种情况下,使用精度和召回率更为合适。精度衡量预测为阳性的样本中有多少是正确的,而召回率衡量实际为阳性的样本中有多少被正确识别。通过混淆矩阵,可以计算出这些指标,并更好地评估算法的性能。这对于检测罕见类别特别有用。