深度学习基准模型Mamba
Mamba(英文直译:眼镜蛇)具有选择性状态空间的线性时间序列建模,是一种先进的状态空间模型 (SSM),专为高效处理复杂的数据密集型序列而设计。
Mamba是一种深度学习基准模型,专为处理长序列数据而设计,尤其是在自然语言处理(NLP)和其他涉及序列建模的任务中。
以下是关于MAMBA模型的一些关键特性与优势:
- 选择性结构状态空间模型(Selective Structural State-Space Model):MAMBA的核心在于它引入了一种选择机制,这一机制能够高效地决定序列中每个标记的相关性信息是否值得传播或丢弃。这种策略通过优化信息流,显著加快了推理速度,提高了模型的吞吐量,据称相比标准的Transformer模型,其吞吐率提高了五倍。
- 全局感受野与动态加权:MAMBA通过其独特的设计,能够全局地感知序列信息,并依据序列上下文动态地调整权重。这不仅缓解了传统卷积神经网络(CNN)在长序列建模中可能遇到的限制,还提供了与Transformer模型相媲美的高级序列建模能力,但同时在资源消耗和计算效率方面表现更优。
- 基于上下文的推理能力增强:MAMBA通过将模型参数设计为输入上下文的函数,增强了SSM(Structured State Space Models,如S4模型中所用)的上下文推理能力。这样的设计允许模型更加灵活地根据输入调整其行为,从而提高了模型的适应性和表达能力。
- 简化特征工程:与深度学习的一般原则相符,MAMBA也强调了自动特征学习的重要性,即模型能够直接从原始数据中学习到有用的特征表示,减少了手动特征工程的需求。这使得MAMBA不仅在理论上具有吸引力,而且在实践中易于应用到多种序列数据相关的任务中。
- 应用案例:虽然具体的应用案例细节未在摘要信息中明确列出,但提及了"U-Mamba"作为相关模型应用的一个实例,这暗示了MAMBA框架在实际任务中的潜力和灵活性,可能涵盖了诸如文本生成、机器翻译、语音识别、时间序列预测等多个领域。
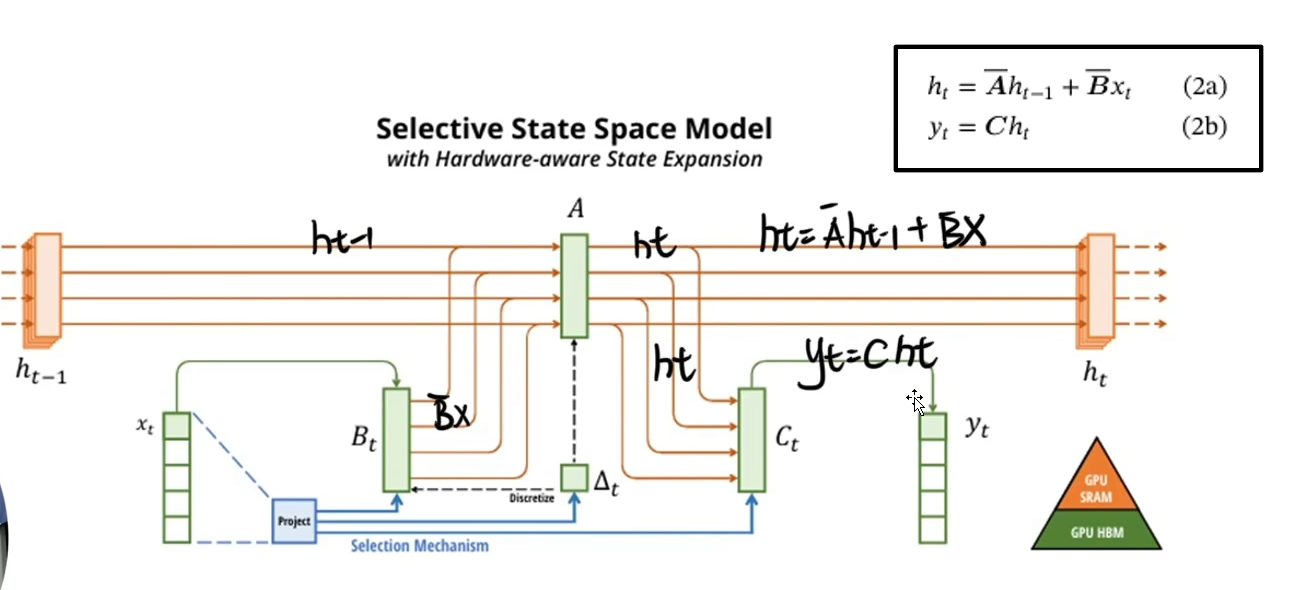
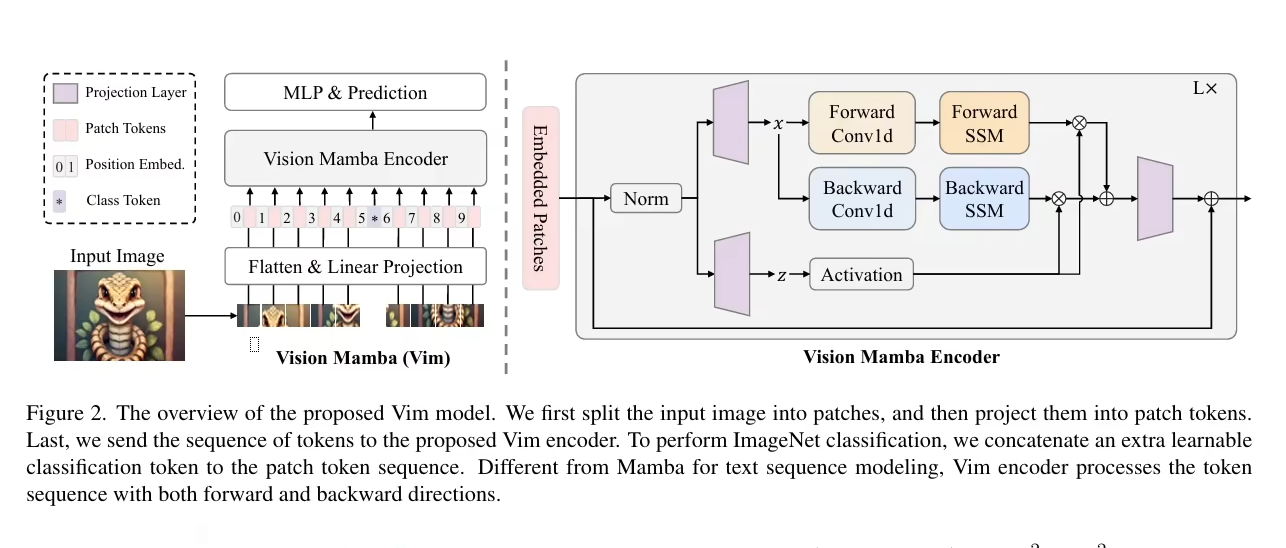
综上所述,MAMBA模型以其创新的选择性结构和高效的信息处理机制,为序列建模任务提供了一个有竞争力的解决方案,旨在克服现有模型在处理长序列数据时面临的挑战,同时推动深度学习技术在序列分析领域的进步。
了解更多知识请戳下: