基本结构

字段gcwaiting、stopwait和stopnoted都是串行运行时任务执行前后的辅助协调手段
gcwaiting字段的值用于表示是否需要停止调度
- 在停止调度前,该值会被设置为1
- 在恢复调度之前,该值会被设置为0
- 这样做的作用是,一些调度任务在执行时只要发现gcwaiting的值为1,就会把当前P的状态置为Pgcstop,然后自减stopwait字段的值
- 如果发现自减后的值为0,就说明所有P的状态都已为Pgcstop
- 这样就可以利用stopnote字段,唤醒因等待调度停止而暂停的串行时任务了
字段sysmonwait和sysmonnote与前面那一组字段的用户类似,只不过它们针对的是系统监测任务
- 在串行运行时任务执行之前,系统监测任务也需要暂停
- sysmonwait字段的作用就是表示是否已暂停,0表示未暂停,1表示已暂停
系统监测任务是持续执行的,更准确地说,它处在无尽的循环之中。在每次迭代之初,系统监测程序都会先检查调度情况
一旦发现调度停止(gcwaiting字段的值不为0或所有的P都已闲置),就会把sysmonwait字段的值设置为1,并利用sysmonnote字段暂停自身。另一方面,在恢复调度之前,调度器发现sysmonwait字段的值不为0,就会把它置为0,并利用sysmonnote字段恢复系统监测任务的执行
一轮调度
封装main函数的G总是Go运行时创建的第一个用户G。用户G因Go程序中的代码而生,用于封装用户级的程序片段(即需并发执行的函数)。相对的,用户封装运行时任务的G称为运行时G
M锁定的情况
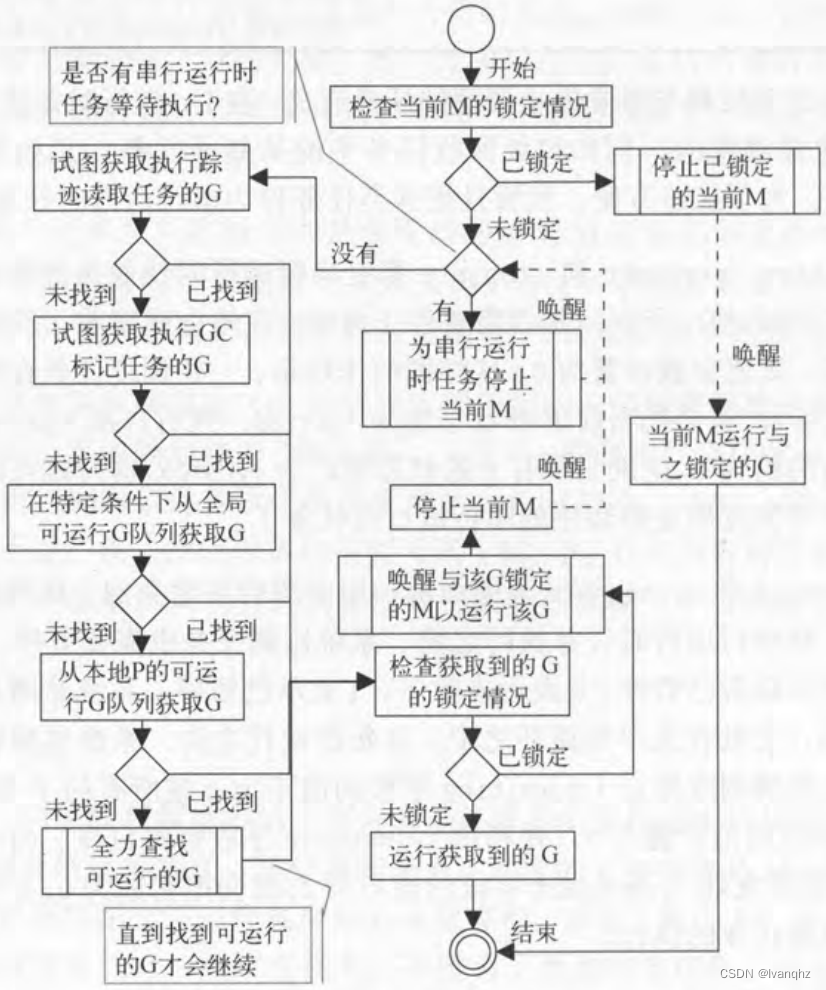
在一轮调度开始处,调度器会先判断当前M是否已被锁定。M和G是可以成对地锁定在一起
锁定M和G的操作可以说是为CGO准备的。CGO代表了Go中的一种机制,是Go程序和C程序之间的一座桥梁。是它们的相互调用成为可能
通过调用runtime.LockOSThread函数,把当前的G与当时运行它的那个M锁定在一起,也可以通过调用runtime.UnlockOSThread函数解除当前G与某个M的锁定
如果调度器在一轮调度之初发现当前M已与某个G锁定,就会立即停止调度并停止当前M(或是说让它暂时阻塞)。一旦与它锁定的G处于可运行状态,它就会被唤醒并继续运行那个G
停止当前M意味着相关的内核线程不能再去做其他事情了。此时,调度器也不会为当前M寻找可运行的G。相应的,当调度器为当前M找到了一个可运行的G,但却发现该G已与某个M锁定,它就会唤醒那个与锁定的M以运行该G,并重新为当前M寻找可运行的G
M未锁定的情况& 串行任务
如果调度器判断当前M未与任何G锁定,那么一轮调度的主流程就会继续进行
调度器会检查是否有运行时串行任务正在等待执行
- 串行任务,这类任务执行时需要停止Go调度器。官方称此种停止操作为"Stop the world",简称STW
如果gcwaiting字段的值不为0,那么一轮调度流程又会走进另一个分支,即:停止并阻塞当前M以等待运行时串行任务执行完成。一旦串行任务执行完成,该M就会被唤醒,一轮调度也会再此开始
寻找可运行G
如果调度器在此关于锁定和运行时串行任务的判断都为假,就会开始真正的可以运行G寻找之旅。一旦找到一个可运行G,调度器就会判断该G未与任何M锁定之后,立即让当前M运行它
全力查找可运行的G
调度器如果没有找到可运行的G,就会进入"全力查找可运行G"的子流程。这个子流程会多次尝试从各处搜索可运行的G,甚至还会从别的P(非本地P)哪里偷取可运行的G
获取执行终结器的G
一个终结器可以与一个对象关联,通过调用runtime.SetFinalizer函数就可以产生这种关联
当一个对象变为不可达(即:未被任何其他对象引用)时,垃圾回收器在回收该对象之前,就会执行与之关联的终结函数
所有终结函数的执行都会由一个专用的G负责。调度器会在判定这个专用G已完成任务之后试图获取它,然后把它置为Grunnable状态并放入本地P的可运行G队列
从本地P的可运行G队列获取G
调度器会尝试从该处获取一个G,并把它作为结果返回
从调度器的可运行G队列获取G
调度器会尝试从该处获取一个G,并把它作为结果返回
从网络I/O轮询器(或称netpoller)处获取G
如果netpoller已被初始化且已有过网络I/O操作,那么调度器会试着从netpoller哪里获取一个G列表,并把作为表头的那个G当作结果返回,同时把其余的G都放入调度器的可运行G队列
如果netpoller还未被初始化或还未有过网络I/O操作,这一步就会跳过
从其他P的运行G队列获取G
在条件允许的情况下,调度器会使用一种伪随机算法在全局P列表中选取P
然后试着从它们的可运行G队列中盗取(转移)一半的G到本地P的可运行G队列。选取P和盗取G的过程会重复多次,成功即停止
如果成功,那么调度器就会盗取的一个G作为结果返回。否则,搜索的第一阶段就结束了
获取执行GC标记任务的G
在搜索的第二阶段,调度器会先判断是否正处于GC标记阶段,以及本地P是否可用于GC标记任务
如果答案都是true,调度器就会把本地P持有的GC标记专用G置为Grunnable状态并作为结果返回
从调度器的可运行G队列获取G
调度器再次尝试从该处获取一个G,并把它作为结果返回
如果依然找不到可运行的G,就会解除本地P与当前M的关联,并把该P放入调度器的空闲P列表
从全局P列表中每个P的可运行G队获取G
遍历全局P列表中的P,并检查它们的可运行G队列
只要发现某个P的可运行G队列不为空的,就从调度器的空闲P列表中取出一个P,并在判定其可用后与当前M关联在一起,然后再返回第一阶段重新搜索可运行的G
如果所有P的可运行G队列都是空的,那就只能继续后面的搜索
获取执行GC标记任务的G
判断是否正处于GC的标记阶段,以及与GC标记任务相关的全局资源是否可用
如果答案都是true,调度器就会从其空闲P列表拿出一个P。如果这个P持有一个GC标记专用G,就关联该P与当前M,然后再次执行第二阶段
从网络I/O轮询器(netpoller)处获取G
如果netpoller已被初始化了,并且有过网络I/O操作,那么调度器会再次试着从netpoller哪里获取一个G列表
此步骤和之前步骤基本相同,但有一个明显区别:这里的获取是阻塞的
只有当netpoller哪里有可用的G时,阻塞才会解除