引言
Hadoop分布式文件系统(HDFS,Hadoop Distributed File System)是Hadoop框架的核心组件之一,它提供了高可靠性、高可用性和高吞吐量的大规模数据存储和管理能力。本文将从HDFS的定义、架构、工作原理、应用场景以及常用命令等多个方面进行详细探讨,帮助读者全面深入地了解HDFS。
1. HDFS 的定义
1.1 什么是HDFS
HDFS是Hadoop生态系统中的一个分布式文件系统,旨在在集群的廉价硬件上可靠地存储大数据集。HDFS设计为高容错,并为高吞吐量数据访问而优化,适用于在商用硬件上运行的大数据应用。
1.2 HDFS 的历史背景
HDFS的灵感来自于Google文件系统(GFS),由Apache软件基金会的Hadoop项目团队开发。2006年,Doug Cutting和Mike Cafarella基于Google的GFS论文,开始开发HDFS,成为Hadoop框架的基础组件之一。
1.3 HDFS 的优点
- 高容错性:数据通过副本机制存储在多个节点上,确保在硬件故障时数据的高可用性。
- 高吞吐量:通过批量处理大数据,HDFS优化了数据的读写速度。
- 可扩展性:通过添加节点,可以轻松扩展HDFS的存储容量和计算能力。
- 可靠性:通过分布式架构和数据冗余,确保数据在系统故障情况下的完整性和可用性。
2. HDFS 的架构
HDFS采用主从架构,主要由NameNode和DataNode两类节点组成。
2.1 NameNode
NameNode是HDFS的主节点,负责管理文件系统的命名空间和文件块的映射关系。它存储所有文件和目录的元数据(如文件名、权限、块位置等),并协调客户端对数据的访问请求。
2.1.1 NameNode 的职责
- 文件系统命名空间管理:管理文件和目录的结构,维护元数据。
- 块管理:管理文件与块的映射关系,以及块在DataNode上的存储位置。
- 集群管理:监控DataNode的健康状态,处理节点故障。
2.2 DataNode
DataNode是HDFS的工作节点,负责存储实际的数据块。每个DataNode定期向NameNode发送心跳信号,报告其健康状态和存储情况。
2.2.1 DataNode 的职责
- 数据存储:存储HDFS文件的数据块。
- 数据块报告:定期向NameNode发送数据块列表,报告其存储情况。
- 数据块操作:执行客户端请求的读写操作,负责数据块的创建、删除和复制。
2.3 Secondary NameNode
Secondary NameNode并不是NameNode的热备份,而是辅助NameNode进行元数据管理的节点。它定期获取NameNode的元数据快照并合并编辑日志,以减轻NameNode的负载。
2.3.1 Secondary NameNode 的职责
- 元数据快照:定期从NameNode获取元数据快照。
- 合并编辑日志:将元数据快照与编辑日志合并,生成新的元数据文件,减轻NameNode的内存压力。
2.4 HDFS 的基本架构图
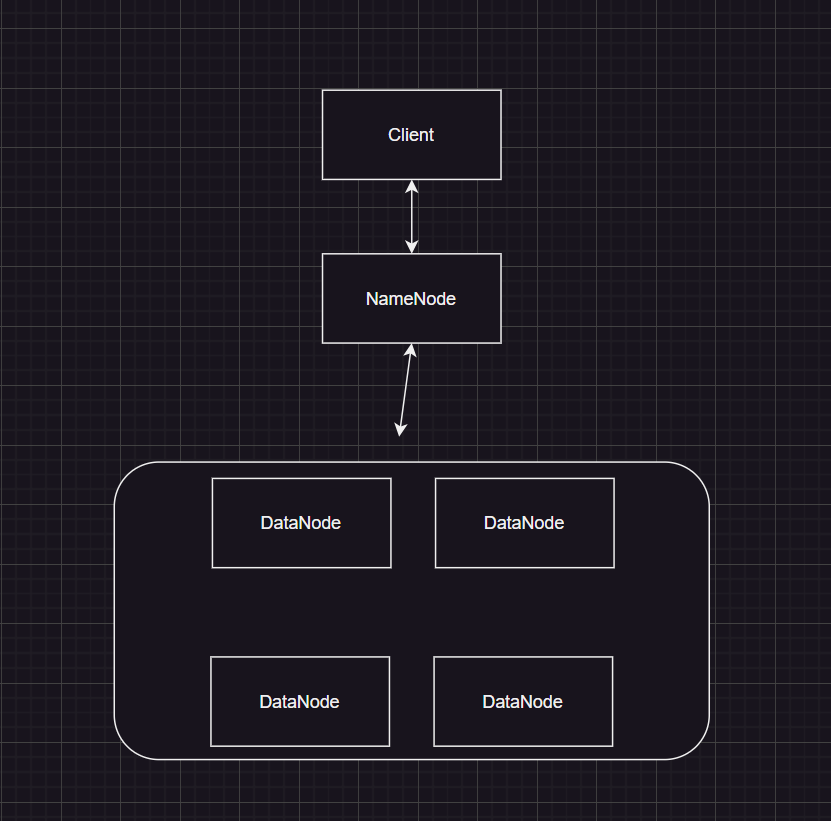
3. HDFS 的工作原理
HDFS通过分布式存储和冗余机制,实现高可靠性和高可用性。以下是HDFS的几个关键工作原理。
3.1 文件存储
HDFS将文件分割成固定大小的块(默认64MB或128MB),并将这些块存储在不同的DataNode上。每个块会被复制到多个DataNode(默认3个副本),以确保数据的可靠性。
3.2 数据写入
当客户端向HDFS写入数据时,数据首先被分割成块,并通过Pipeline机制写入到多个DataNode。具体步骤如下:
- 客户端请求NameNode:客户端向NameNode请求写入文件。
- NameNode 分配块和DataNode:NameNode为文件分配数据块并选择存储这些块的DataNode。
- 客户端写入数据块:客户端将数据块写入第一个DataNode,第一个DataNode再将数据块复制到第二个DataNode,依此类推。
- 数据块确认:当所有副本写入成功后,客户端接收到确认消息,表示数据写入完成。
3.3 数据读取
当客户端从HDFS读取数据时,NameNode提供数据块的位置信息,客户端直接从相应的DataNode读取数据。具体步骤如下:
- 客户端请求NameNode:客户端向NameNode请求读取文件。
- NameNode 返回块位置:NameNode返回文件块所在的DataNode列表。
- 客户端读取数据块:客户端直接从DataNode读取数据块,并在本地合并这些数据块,恢复成完整的文件。
3.4 容错机制
HDFS通过数据块副本机制实现容错。当DataNode发生故障时,NameNode会检测到该DataNode的心跳信号丢失,并在其他健康的DataNode上重新复制丢失的数据块。
3.5 元数据管理
NameNode负责管理文件系统的元数据,包括文件名、目录结构、权限和数据块位置等。为了保证元数据的一致性和持久性,NameNode将元数据存储在内存中,并定期写入到本地磁盘。
4. HDFS 的应用场景
HDFS广泛应用于需要大规模数据存储和高吞吐量数据处理的场景。以下是一些典型的应用场景:
4.1 数据仓库
HDFS可以用作数据仓库,存储和管理大规模的结构化和非结构化数据。企业可以利用HDFS构建数据湖,统一存储各种来源的数据,方便后续的数据分析和挖掘。
4.2 大数据分析
HDFS为大数据分析提供了高效的数据存储和访问机制。结合MapReduce、Spark等分布式计算框架,HDFS能够快速处理和分析海量数据,帮助企业从数据中获取有价值的洞察。
4.3 日志存储与处理
HDFS适用于存储和处理大规模的日志数据,如Web服务器日志、应用日志和系统日志等。企业可以利用HDFS集中存储日志数据,并结合数据分析工具,进行实时监控和异常检测。
4.4 机器学习
HDFS为机器学习提供了可靠的数据存储和高效的数据访问能力。数据科学家可以将训练数据集存储在HDFS上,并利用分布式计算框架训练和优化机器学习模型。
4.5 多媒体存储
HDFS可以用于存储和管理大规模的多媒体数据,如图像、音频和视频文件等。通过分布式存储和并行处理,HDFS能够高效地存储和传输多媒体数据。
5. 常见的HDFS命令
掌握HDFS的常见命令,可以帮助用户更加高效地管理和操作HDFS。以下是一些常用的HDFS命令:
5.1 文件操作命令
ls:列出指定目录下的文件和目录。
hdfs dfs -ls /路径
mkdir:创建一个新的目录。
hdfs dfs -mkdir /路径
put:将本地文件上传到HDFS。
hdfs dfs -put 本地文件 /路径
get:从HDFS下载文件到本地。
hdfs dfs -get /路径 本地文件
rm:删除指定路径下的文件或目录。
hdfs dfs -rm /路径
mv:移动或重命名HDFS文件或目录。
hdfs dfs -mv /源路径 /目标路径
cat:显示HDFS文件的内容5.2 数据块操作命令
fsck:检查HDFS的文件系统状态,报告文件的健康状况。
hdfs fsck /路径
du:显示指定目录或文件的磁盘使用情况。
hdfs dfs -du /路径
df:显示HDFS文件系统的总空间和可用空间。
hdfs dfs -df
checksum:获取HDFS文件的校验和。
hdfs dfs -checksum /路径5.3 数据备份和恢复命令
distcp:用于在HDFS集群之间或在HDFS和其他文件系统之间复制大量数据。
hadoop distcp hdfs://源路径 hdfs://目标路径
snapot:创建HDFS目录的快照。
hdfs dfs -createSnapot /路径 快照名称
deleteSnapot:删除HDFS目录的快照。
hdfs dfs -deleteSnapot /路径 快照名称5.4 权限管理命令
chown:更改文件或目录的所有者。
hdfs dfs -chown 用户:组 /路径
chmod:更改文件或目录的权限。
hdfs dfs -chmod 权限 /路径
chgrp:更改文件或目录的组。
hdfs dfs -chgrp 组 /路径5.5 HDFS 管理员命令
balancer:启动HDFS数据块平衡器,重新分布数据块以优化存储利用。
hdfs balancer
dfsadmin:执行HDFS的管理任务,如查看集群状态、刷新节点等。
hdfs dfsadmin -report
namenode:启动或停止NameNode。
hdfs namenode -format
datanode:启动或停止DataNode。
hdfs datanode6. HDFS 的性能优化
为了充分利用HDFS的优势,可以从以下几个方面进行性能优化:
6.1 数据分块优化
合理设置数据块大小,可以提高HDFS的性能。默认情况下,HDFS的数据块大小为128MB,根据实际情况调整块大小,可以优化数据的读写性能。
6.2 副本数量优化
根据数据的重要性和系统的容错要求,适当调整数据块的副本数量。默认情况下,HDFS的副本数量为3个,可以根据具体情况进行调整,以达到最佳的性能和可靠性平衡。
6.3 网络带宽优化
优化HDFS集群的网络带宽,可以提高数据的传输速度。采用高带宽网络和优化网络拓扑结构,可以显著提升HDFS的性能。
6.4 硬件配置优化
合理配置HDFS集群的硬件资源,包括CPU、内存和磁盘等,可以提高系统的整体性能。采用高性能的磁盘和增加内存容量,可以显著提升HDFS的读写速度。
6.5 数据压缩优化
对大规模数据进行压缩存储,可以减少磁盘空间的使用,提升数据传输效率。HDFS支持多种数据压缩格式,如Gzip、Snappy和LZO等,可以根据实际需求选择合适的压缩算法。
6.6 元数据管理优化
定期对NameNode的元数据进行快照和编辑日志合并,可以减轻NameNode的内存压力,提高系统的响应速度。采用Secondary NameNode或Backup Node,可以进一步增强元数据的管理和容错能力。
7. HDFS 的安全性
HDFS提供了多种安全机制,保护数据的完整性和机密性。
7.1 认证机制
HDFS支持Kerberos认证,确保只有合法用户才能访问文件系统。通过配置Kerberos票据,可以实现安全的用户认证和访问控制。
7.2 授权机制
HDFS提供了基于POSIX的权限模型,可以对文件和目录进行细粒度的访问控制。通过设置文件和目录的所有者、组和权限,可以控制用户对数据的读写和执行权限。
7.3 数据加密
HDFS支持数据在传输和存储过程中的加密,确保数据的机密性。通过配置传输层安全(TLS)和加密文件系统(EFS),可以实现数据的端到端加密。
7.4 审计日志
HDFS提供了审计日志功能,可以记录用户的访问和操作日志。通过分析审计日志,可以监控系统的使用情况,检测和防范潜在的安全威胁。
8. HDFS 的未来发展
HDFS作为一个关键的大数据存储系统,未来将继续发展和演进,以应对不断变化的数据处理需求。
8.1 更高的可扩展性
HDFS将进一步提高其可扩展性,支持更大规模的数据存储和计算。通过优化数据块管理和副本机制,HDFS将能够处理更多的节点和数据。
8.2 更强的兼容性
HDFS将与更多的大数据处理工具和平台集成,提供更加灵活和强大的数据处理能力。通过兼容更多的数据格式和存储协议,HDFS将能够满足不同数据处理需求。
8.3 更好的用户体验
HDFS将继续改进其易用性,包括更加直观的管理界面、更简便的配置流程和更强大的开发工具。通过提供更多的自动化和智能化功能,HDFS将能够简化用户的操作,提高系统的易用性。
8.4 更加智能的资源调度
随着机器学习和人工智能技术的发展,HDFS的资源调度将更加智能化,能够根据任务的特点和资源的使用情况自动调整和优化。通过引入智能化的资源管理算法,HDFS将能够提高系统的整体效率和性能。
8.5 增强的安全性
HDFS将进一步加强其安全机制,提供更加全面和灵活的认证、授权和加密功能。通过引入更多的安全技术和工具,HDFS将能够更好地保护数据的安全和隐私,确保数据在传输和存储过程中的机密性和完整性。
9. HDFS 的社区和支持
HDFS作为一个开源项目,有着庞大的社区支持和丰富的资源。用户可以通过以下渠道获取帮助和支持:
9.1 官方文档
Apache Hadoop的官方网站提供了详细的官方文档,包括安装指南、配置说明和API参考。用户可以通过阅读官方文档快速上手和解决常见问题。
9.2 社区论坛
HDFS社区论坛是用户交流和讨论的主要平台,用户可以在论坛上提出问题、分享经验和获取帮助。Apache Hadoop的官方邮件列表也是一个重要的交流渠道。
9.3 开源贡献
作为一个开源项目,HDFS欢迎用户参与代码贡献和项目维护。用户可以通过GitHub提交代码、报告Bug和参与讨论,帮助改进和发展HDFS。
9.4 商业支持
许多公司提供HDFS的商业支持和服务,包括安装、配置、优化和培训等。用户可以选择合适的商业支持服务,确保HDFS在生产环境中的稳定运行。
10. 总结
HDFS作为Hadoop生态系统的核心组件,提供了高效的大规模数据存储和管理能力。本文从HDFS的定义、架构、工作原理、应用场景、常见命令、性能优化、安全性、未来发展和社区支持等多个方面进行了详细的介绍。
HDFS凭借其高容错性、高吞吐量和可扩展性的特点,已经在数据仓库、大数据分析、日志存储与处理、机器学习和多媒体存储等领域得到了广泛应用。通过掌握HDFS的基础知识和操作技能,用户可以在实际工作中充分利用这一强大的工具,解决大规模数据处理和分析的挑战。
未来,随着大数据技术的不断发展,HDFS将继续演进和优化,提供更加灵活、高效和安全的数据存储和管理解决方案。无论是作为数据工程师、数据科学家还是大数据架构师,深入掌握和应用HDFS都将成为你职业发展的重要技能。