目录
xmind:

研究背景
本文研究基于 Linux kernel 2.6.32 的32位平台进程地址空间的区别与实现。通过具体的代码示例和实验,揭示虚拟地址空间的概念,并探讨其重要性和操作系统对其管理的机制。
程序地址空间的回顾
在学习 C 语言时,常见的程序地址空间布局如下图所示:
#include <stdio.h>
#include <stdlib.h>
int main()
{
printf("%s\n", getenv("PATH"));
return 0;
}
上述代码展示了典型的程序地址空间结构,但我们对其理解并不深入。通过进一步的代码实验,可以更好地理解程序地址空间的概念。
验证地址空间
实验一:父子进程变量地址一致性
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if(id < 0){
perror("fork");
return 0;
}
else if(id == 0){ //child
printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);
}else{ //parent
printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}输出结果(可能因环境而异):

实验二:变量值修改后父子进程的差异
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if(id < 0){
perror("fork");
return 0;
}
else if(id == 0){ //child
g_val=100;
printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);
}else{ //parent
sleep(3);
printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}输出结果(可能因环境而异):

分析与结论
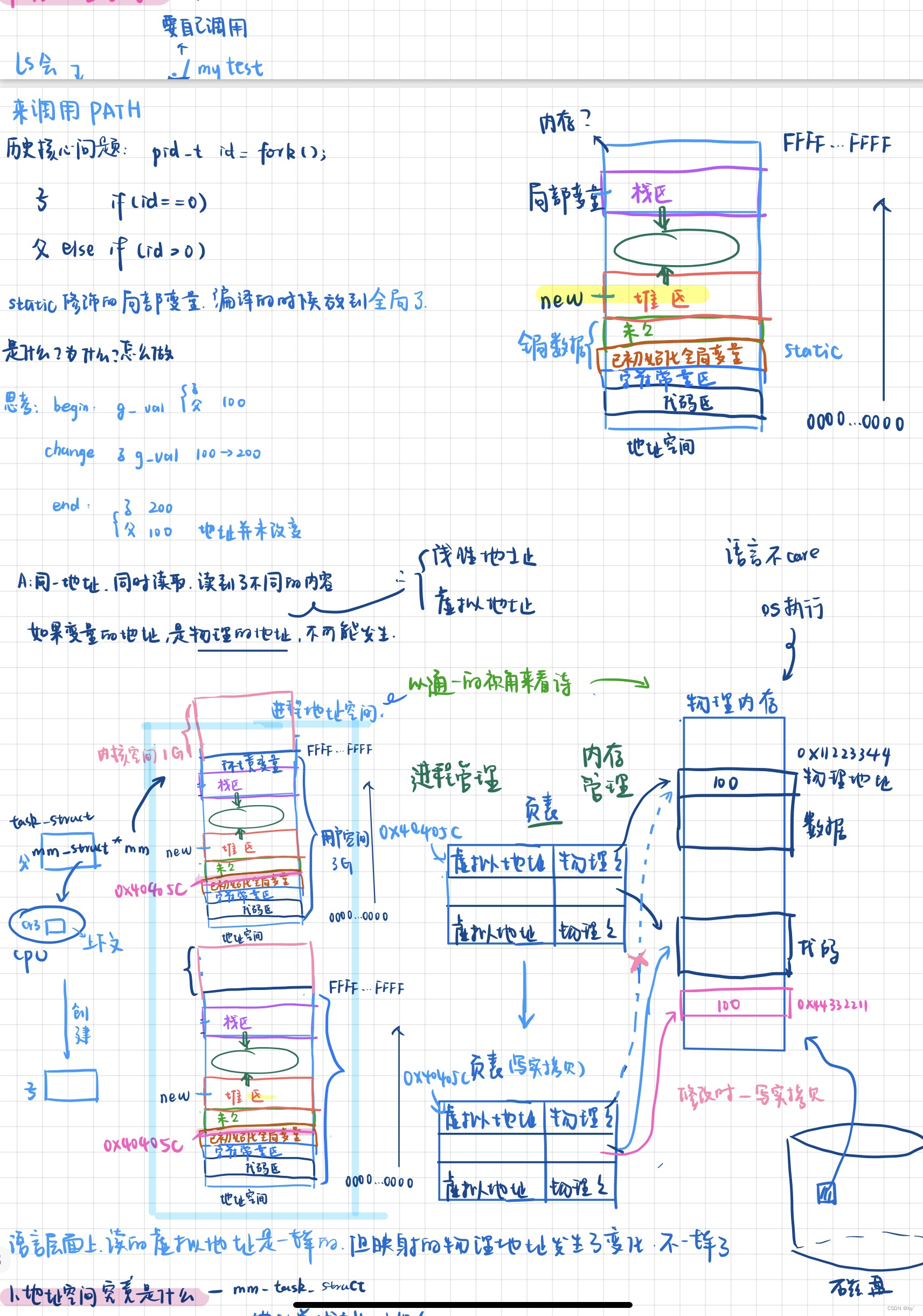
上述实验表明,父子进程的变量地址相同但内容不同,说明地址为虚拟地址,且父子进程有各自独立的物理地址映射。这验证了虚拟地址的概念,即我们在C/C++中看到的地址是虚拟地址,由操作系统负责将其转化为物理地址。
进程地址空间
程序地址空间实际上是进程地址空间的子集,是系统级的概念。进程地址空间通过虚拟地址映射实现内存独立性,确保进程间互不干扰。
实验三:进程地址空间验证
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int un_g_val;
int g_val = 100;
int main(int argc, char* argv[], char* env[])
{
printf("code addr : %p\n", main);
printf("init global addr : %p\n", &g_val);
printf("uninit global addr : %p\n", &un_g_val);
char* m1 = (char*)malloc(100);
printf("heap addr : %p\n", m1);
printf("stack addr : %p\n", &m1);
int i = 0;
for (i = 0; i < argc; i++) {
printf("argv addr : %p\n", argv[i]);
}
for (i = 0; env[i]; i++) {
printf("env addr : %p\n", env[i]);
}
}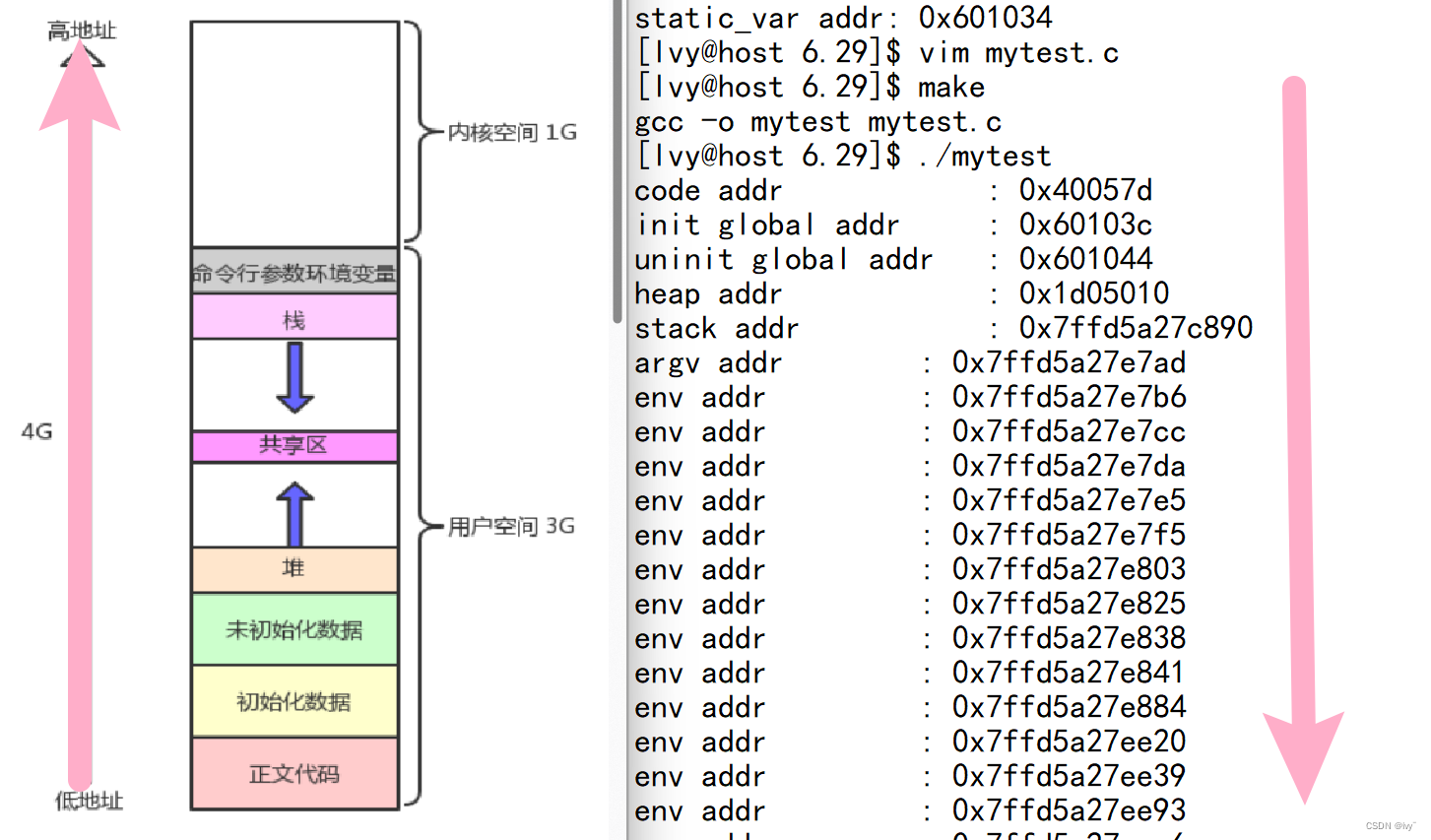
运行结果:
地址整体依次增大,堆区向地址增大方向增长,栈区向地址减少方向增长,验证了堆和栈的挤压式增长方向。
验证静态局部变量
静态修饰的局部变量,编译的时候已经被编译到全局数据区,这一点可以通过以下代码验证:
#include <stdio.h>
#include <stdlib.h>
void func() {
static int static_var = 10;
printf("static_var addr: %p\n", &static_var);
}
int main() {
func();
return 0;
}结论:

这也说明了这些变量的地址在全局数据区,而不是局部栈区。
理解进程地址空间
区域与页表
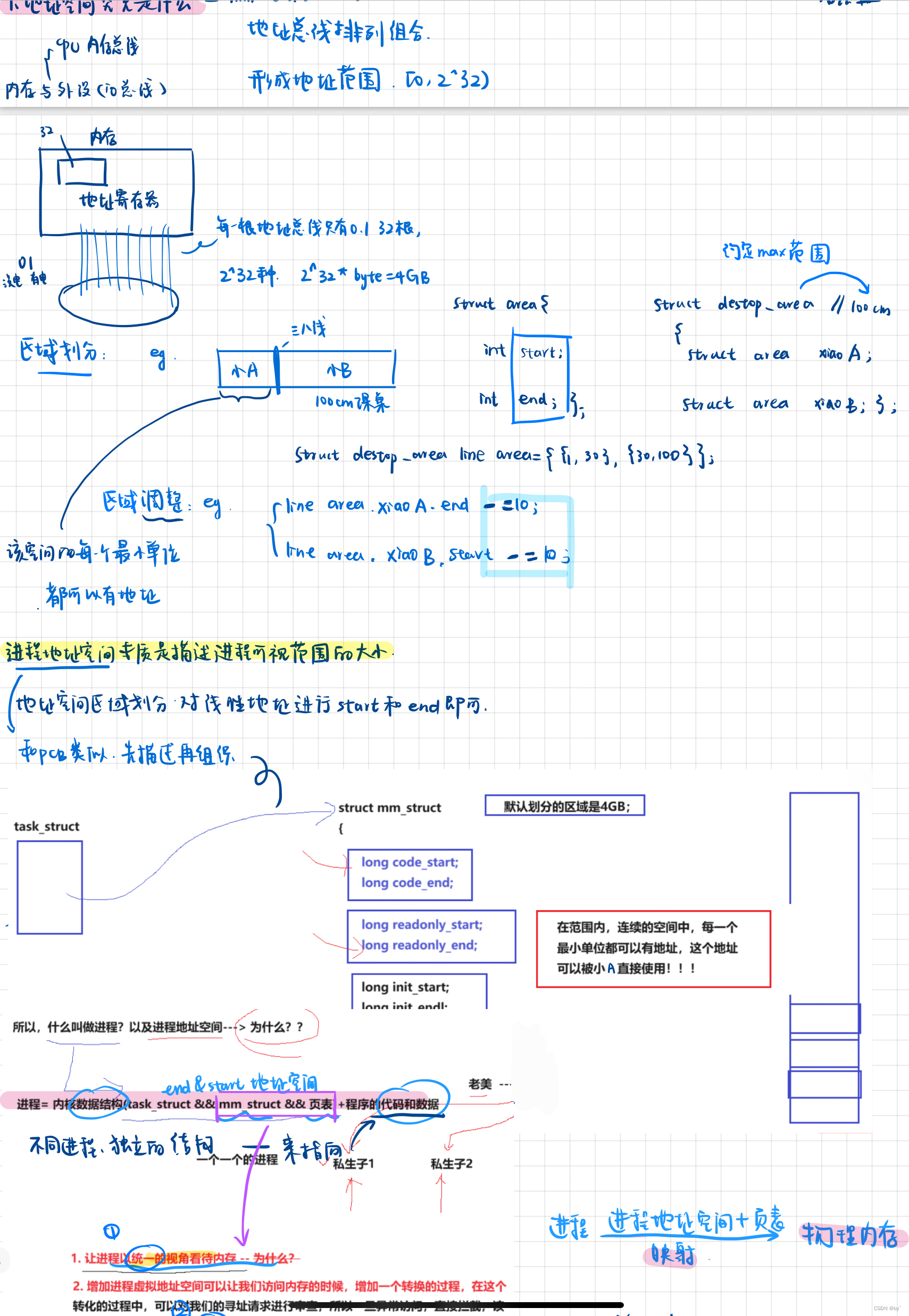
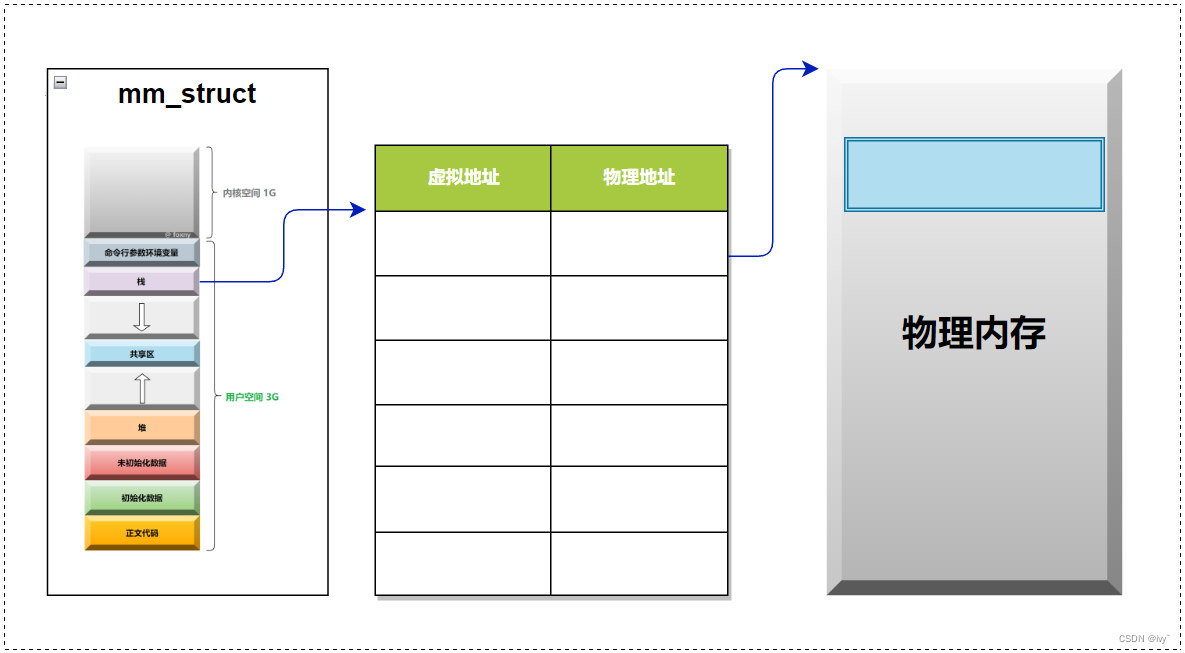
进程地址空间通过 mm_struct 结构体来管理各个区域。每个区域的定义如下:
struct mm_struct {
long code_start;
long code_end;
long init_start;
long init_end;
long uninit_start;
long uninit_end;
long heap_start;
long heap_end;
long stack_start;
long stack_end;
...
}用一个start 和end 就可以表示区域
每个区域都有一个 start 和 end,它们之间就有了地址,地址我们称之为虚拟地址,
然后这些虚拟地址经过页表,就能映射到内存中了。
父子进程全局变量共享与写时拷贝
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 100;
int main(void)
{
pid_t id = fork();
if (id == 0) {
// child
int flag = 0;
while (1) {
printf("child: %d, ppid: %d, g_val: %d, &g_val: %p\n", getpid(), getppid(), g_val, &g_val);
sleep(1);
flag++;
if (flag == 5) {
g_val = 200;
printf("child modified g_val\n");
}
}
}
else {
// father
while (1) {
printf("parent: %d, ppid: %d, g_val: %d, &g_val: %p\n", getpid(), getppid(), g_val, &g_val);
sleep(2);
}
}
}运行结果:
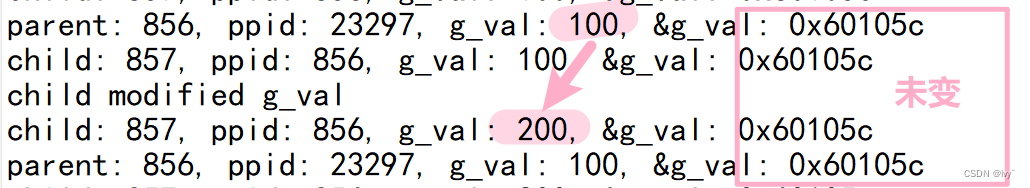
在父子进程中,虚拟地址相同但值不同,验证了写时拷贝机制。
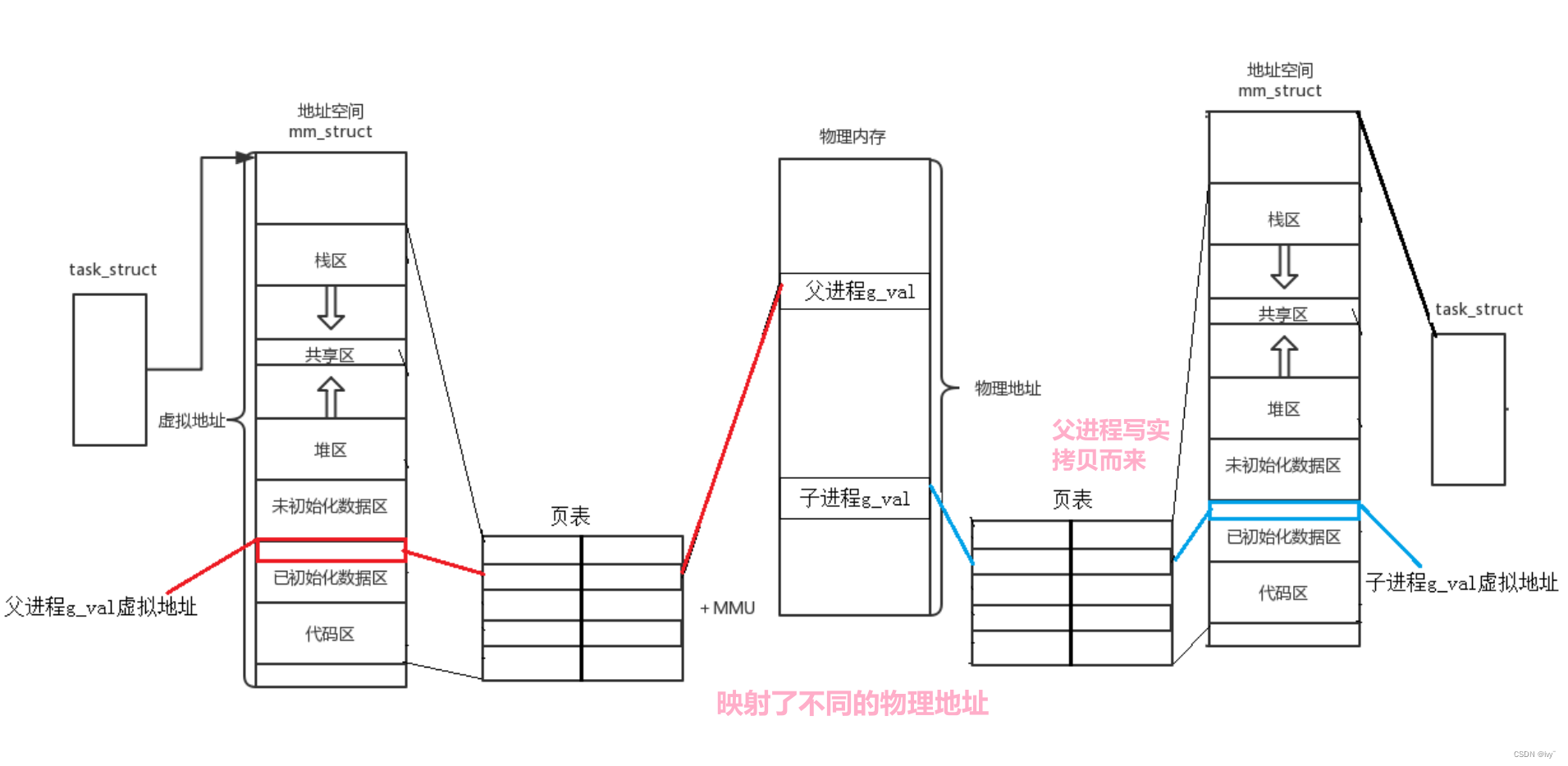
写时拷贝机制
写时拷贝是指当父子进程有一方尝试修改变量时,操作系统会为修改方分配新的物理内存并拷贝数据,以确保独立性。
回顾:fork的两个返回值
pid_t id 是属于父进程的栈空间中定义的。
fork 内部 return 会被执行两次,return 的本质就是通过寄存器将返回值写入到接收返回值的变量中。当我们的 id = fork() 时,谁先返回,谁就要发生 写时拷贝。所以,同一个变量会有不同的返回值,本质是因为大家的虚拟地址是一样的,但大家的物理地址是不一样的。
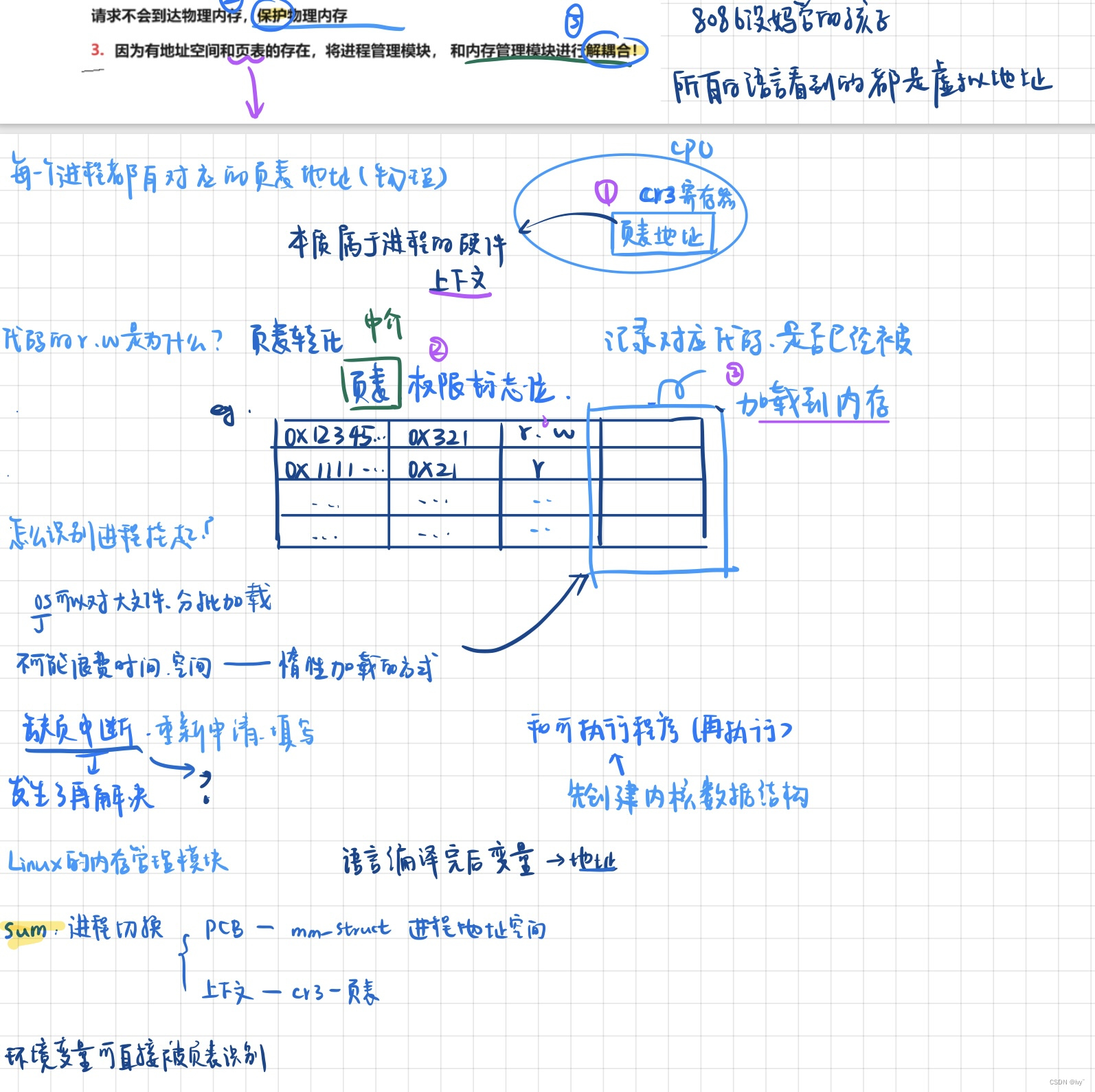
进程地址空间的意义
虚拟地址空间通过软硬结合层,保护内存并简化进程和程序的设计和实现,确保进程的独立性和安全性。
表格:进程地址空间区域划分
| 区域类型 | 起始地址 | 结束地址 |
|---|---|---|
| 代码区 | code_start | code_end |
| 初始化全局变量 | init_start | init_end |
| 未初始化全局变量 | uninit_start | uninit_end |
| 堆区 | heap_start | heap_end |
| 栈区 | stack_start | stack_end |
那么有什么意义呢

拓展:os 对大文件的分批加载是怎么实现的呢
采用惰性加载的方式
存在 缺页中断 ,重新申请 填写页表
缺页中断:
当一个进程访问虚拟内存中的某一页时,操作系统会先检查该页是否当前已经被加载到物理内存中。如果这一页已经在物理内存中,CPU就可以直接访问它。但是,如果这一页并没有在物理内存中,就会发生缺页中断。
当发生缺页中断时,CPU会暂停当前的执行,并将控制权交给操作系统内核。操作系统内核会首先查找页表,寻找到相关的页面对应的磁盘地址。然后,操作系统会将磁盘上的内容读取到空闲的物理内存页中。
一旦内容被加载到物理内存中,操作系统会更新页表,将该页面的映射关系添加到页表中,然后将控制权交还给进程并重新开始执行。这样,进程可以继续访问所需的内存页面。
整个过程用于解决虚拟内存中的页面不在物理内存中的问题,使得系统看起来好像比它实际拥有的更多内存一样,从而使得多个进程能够共享有限的内存资源,提高内存利用率和系统的整体性能。
就达到分批加载的效果啦
所以 进程 应该是先创建内核数据结构,再执行可执行程序的
文章手稿: