pandas使用Numpy的np.nan代表缺失数据,显示为NaN。NaN是浮点数标准中地Not-a-Number。对于时间戳,则使用pd.NaT,而文本使用的是None。
首先构造一组数据:
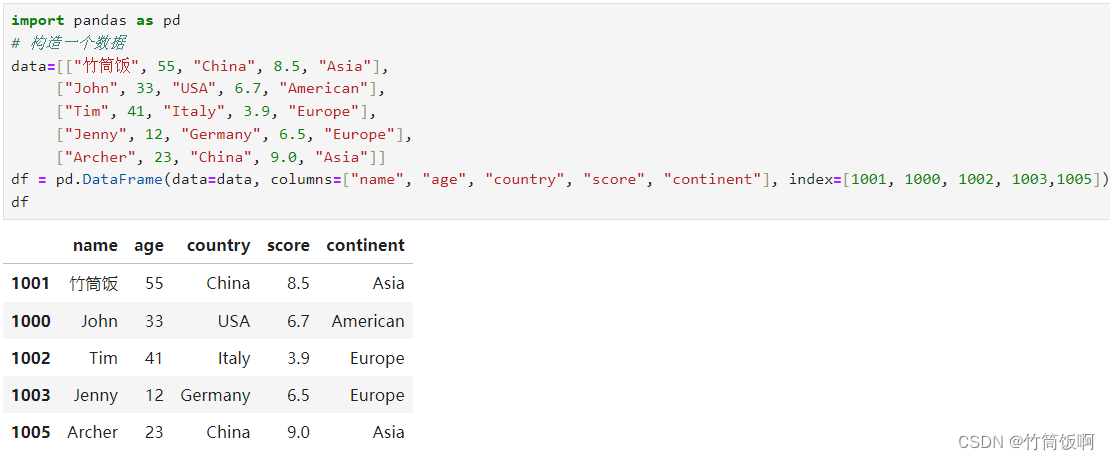
使用None或者np.nan来表示缺失的值:

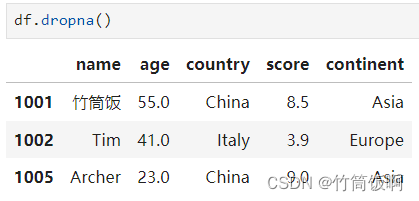
清理DataFrame时,如果要移除所有包含缺失数据的行:
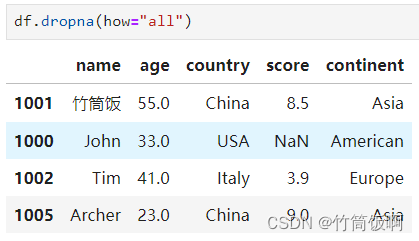
如果只想移除所有的值都缺失的行,可以使用how参数:
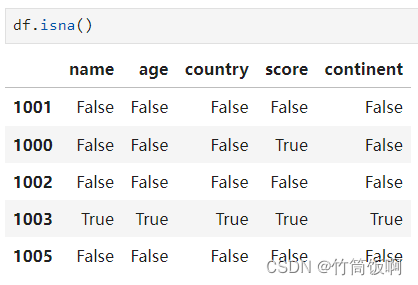
要想获得一个反映对应位置上是否是NaN的布尔DataFrame或Series,可以使用isna方法:
还可以使用fillna来填补缺失的值,例如将score列中的NaN替换为平均值:
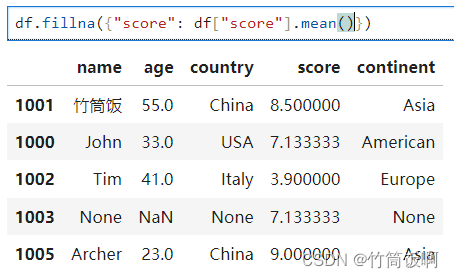
和缺失数据一样,重复数据也会对数据分析的可靠性造成负面影响。可以使用drop_duplicates方法清理重复的行。也可以提供列的子集作为参数:
执行drop_duplicates("country", "continent"),如果某些行的country和continent都一样,则保留第一行,删除后续和它一样的行。
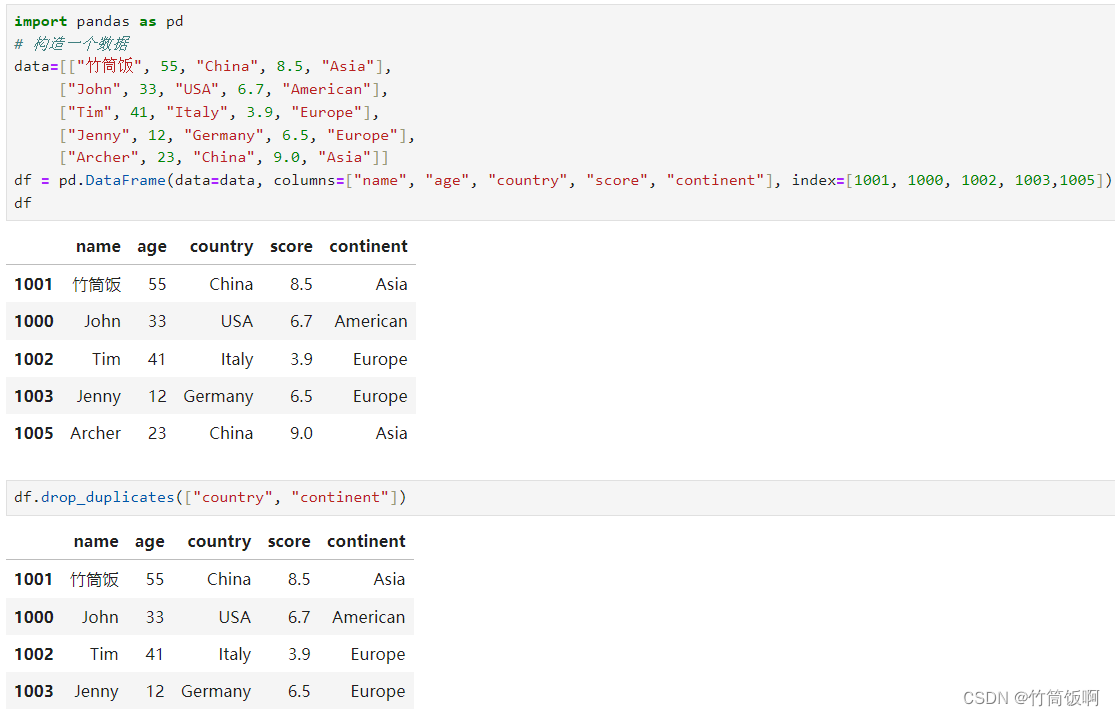
is_unique用于确认某一列是否包含重复的数据,unique则可以获得去重后的值。
duplicated方法可以知道哪些行是重复的,它的返回值是一个布尔Series。keep参数默认值是first,意思是会保留第一次出现的数据,只将重复数据标记为True。将keep参数设置为False时,所有重复数据(包含第一次出现的数据)都会被标记为True。
