"你我都是流式数据引擎。"
------ Jeff Hawkins
如果你是数据分析师、数据科学家,或身处管理层,你就会明白:在任何时刻持续且及时 地获取数据有多么重要。无论是查询、转换,还是以任何方式访问数据,都希望这些数据代表当下最新的信息,以便用于分析。
一旦数据陈旧 ,你可能得出不准确的结论,或产生偏差的统计结果,从而做出错误的战略决策,进而影响公司未来。无论角色如何,持续数据可达对每个人都有好处。
如今我们都知道,数据的产生速度远超以往。过去,企业数据往往按天、按周,甚至按月更新后再写入数据仓库。数据会不断积累,处理起来也就越来越困难。
现在,我们有应用数据、移动端数据、以及各类传感器数据 ,源源不断地产生对分析有价值的流式信息。但由于生成速度极快,要把它们高效 写入数据仓库并不容易。大量微小文件被持续产出,这确实会引发各种问题。
本章将首先概览 Snowflake 的数据加载策略 ,说明其优劣与取舍;随后介绍 Snowpipe ------一种无服务器(serverless)摄取服务 ,可在新文件抵达云存储时自动加载 数据。你将学习如何设置 Snowpipe 自动摄取(auto-ingest)以进行事件驱动 加载,并使用 Snowpipe REST API 进行自定义集成。最后,我们将探讨动态表(Dynamic Tables) ,它能在 Snowflake 内对流式与批处理 数据进行持续转换 。本章配有实践练习,带你用 Snowpipe 与动态表共同构建数据管道。
本章建立在前文对 Snowflake 架构与摄取方式的讨论之上,面向希望实现近实时数据管道 的读者。无论你是在设计流式分析 、实时看板 ,还是仅仅想降低数据时延,掌握这些工具都是优化基于 Snowflake 的数据生态的关键。
Snowflake 的数据加载策略简介(Introduction to Data Loading Strategies for Snowflake)
先来看把数据加载进数据仓库的传统方式 。图 3-1 所示:数据被持续生成 ,先加载到诸如 S3 之类的暂存环境(staging) ,然后按天或按小时成批(batch)写入数据库。
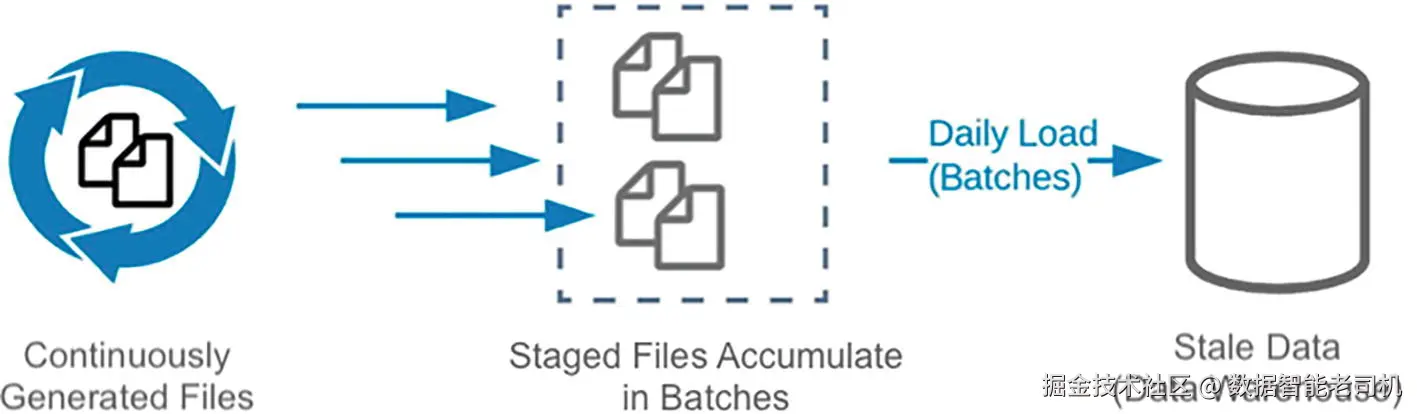
不幸的是,这种方法(按天/按小时/半小时批处理)只能按固定间隔加载数据,无法快速访问刚生成的数据。 用户常常希望随着数据到达就能尽快分析,据此做出关键决策。
如果你决定实现持续加载 系统,你可能已经了解过为批量加载 场景设计的 COPY 命令。通常是数据累积数小时或数天后,再启动一次 COPY 把数据加载到 Snowflake 的目标表中。
注 :
COPY主要是一条用于把文件加载到 Snowflake 表 中的 SQL 命令,支持多种选项和文件格式。文档参考:docs.snowflake.com/en/user-gui...。
作为近实时 的权宜之计,可以用 COPY 做微批(micro-batching) :按计划任务每隔几分钟执行一次 COPY。但这仍非真正的持续加载 ------新到达且可加载的数据不会被自动触发;通常依赖人工或调度器来驱动。
如果你的数据在持续产生 ,你可能会想:能否有一种易用、低成本 的方式,让 Snowflake 中的数据始终保持最新 ?幸运的是,Snowflake 给出的答案是 Snowpipe 。Snowpipe 是一个自动伸缩 的云端服务,可从内部与外部 stage 将数据持续加载进 Snowflake 数据仓库。
借助像 Snowpipe 这样的持续加载方式,你就拥有一种数据驱动 的机制:新文件一到,就把数据送入目标表。
表 3-1 数据仓库加载方式(Data Warehouse Loading Approaches)
| 方式 | 定义 | Snowpipe 选项 |
|---|---|---|
| 批处理(Batch) | 数据按时间累积(每天/每小时),再周期性加载。 | 指定一个 S3 bucket 和仓库中的目标表,新数据到达后自动上传并加载。 |
| 微批(Microbatch) | 数据按数分钟的小时间窗累积,然后加载。 | 通过 REST API (配合 Java/Python SDK )直接对接,实现高度自定义的加载用例。 |
| 持续(近实时) | 每条 数据一到就被单独加载(近实时)。 | 也可使用 Apache Kafka Connector 进行集成。 |
使用 Snowpipe 有两种主要方式:
- Auto-ingest(S3 事件驱动) :把 S3 的事件通知 配置为在新文件落地 时发送到 Snowflake;Snowpipe 会自动拾取这些文件并加载到目标表。
- REST API 集成 :通过 Snowpipe REST API 构建你自己的集成/应用,按你的触发条件调用 Snowpipe loader。
表 3-2 概述了使用 Snowpipe 的关键收益。
表 3-2 Snowpipe 的关键收益(Key Snowpipe Benefits)
| 收益 | 说明 |
|---|---|
| 持续加载,迅速洞察 | 持续产生的数据可在数秒内用于分析。 |
| 免手工 COPY,高可用自定义集成 | 无需手动执行 COPY;加载自动化 。借助 REST API/SDK 可构建自有数据管道。 |
| 对半结构化数据的完整支持 | 支持 XML、JSON、Parquet、ORC、Avro 等行业标准格式;无需为多样数据类型做预转换,灵活性与性能兼得。 |
| 按用量付费 | 只为用于加载数据的计算时间 付费;空闲不计费。云原生设计使存储与计算独立伸缩 、自动透明。需要了解账单中"加载数据"的单独费用项 ;计费为无服务器(serverless)的基于使用量模式。 |
| 零运维(Zero management) | 加载过程中不需建索引、调参、分区或清理(vacuum)。 |
| 无服务器(Serverless) | 无服务器 加载、无限并发 避免与其他工作负载争用;无需管理服务器,对其他作业零影响。 |
持续加载数据(Loading Data Continuously)
可选方案包括:
- Snowpipe auto-ingest
- 通过 AWS Lambda 使用 Snowpipe REST API
Snowpipe Auto-Ingest
Snowpipe auto-ingest 是一种全自动 模式:把对象存储中的新文件 自动加载到目标表。借助 DDL 带来的简洁配置 体验,任何数据工程师或分析师都能在几分钟 内完成自动化持续加载 流程的设置。图 3-2 展示了该集成的主要组件与工作方式。
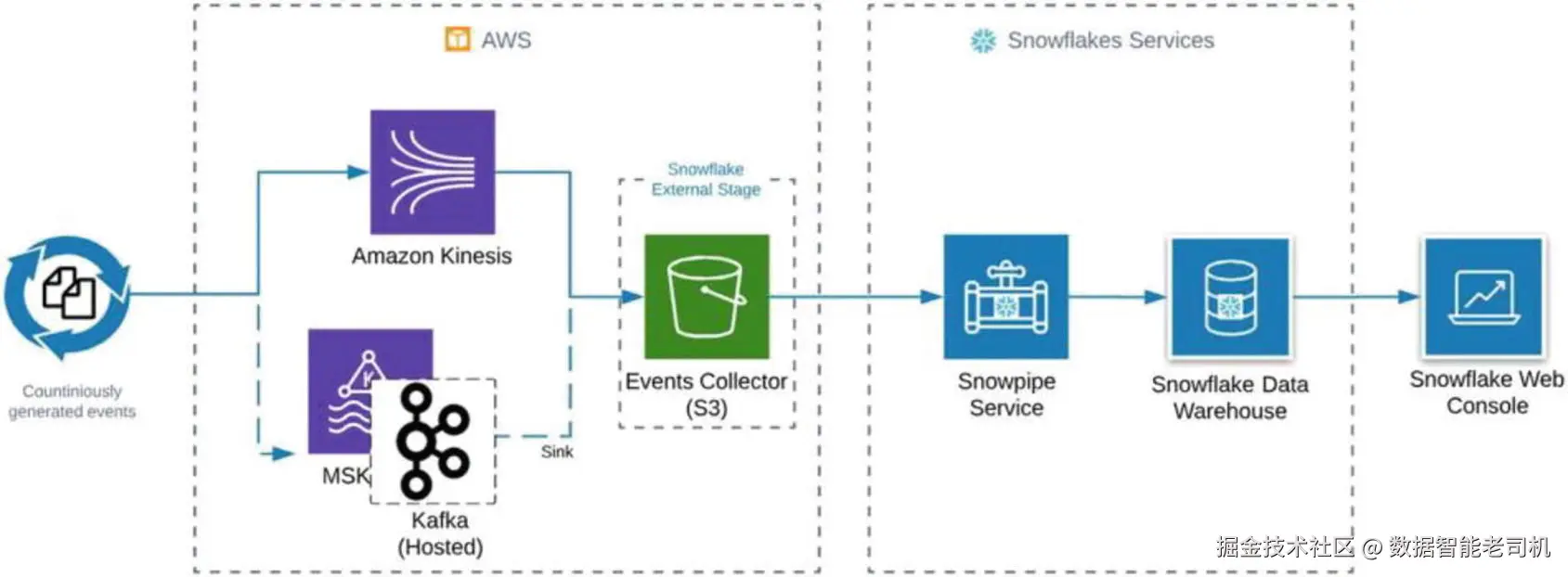
数据源会将持续的数据流 发送到 AWS Kinesis 、AWS Managed Streaming for Kafka (MSK) 、以及托管版 Apache Kafka(Hosted Apache Kafka) 等服务。你可以利用这些服务在文件一到达 外部存储(如 S3 bucket )时,立刻将其暂存(stage)到 Snowflake 的外部 stage 。S3 会通过 SQS 队列向 Snowpipe 发送通知;一旦收到队列中的新文件通知 ,Snowpipe 就会启动无服务器(serverless)加载器应用,在后台把 S3 中的文件加载到目标表中。
使用 Snowpipe Auto-Ingest 构建数据管道(Building a Data Pipeline Using the Snowpipe Auto-Ingest Option)
要搭建一个持续加载的数据管道示例,需要以下组件:
- Stream Producer(流数据生产者) :用于 Kinesis Data Firehose 的示例生产者。
为简化起见,本例可不使用基于 Lambda 的生产者,而是在创建 Firehose 流时使用可用的 Firehose Test Generator。 - Kinesis Data Firehose :作为流式投递服务。
- S3 bucket :作为 Snowflake 的外部 stage。
以及以下 Snowflake 服务:
- Snowpipe
- Snowflake 数据仓库(data warehouse)
- Snowflake 控制台(console)
图 3-3 展示了这些组件之间交互的概览。
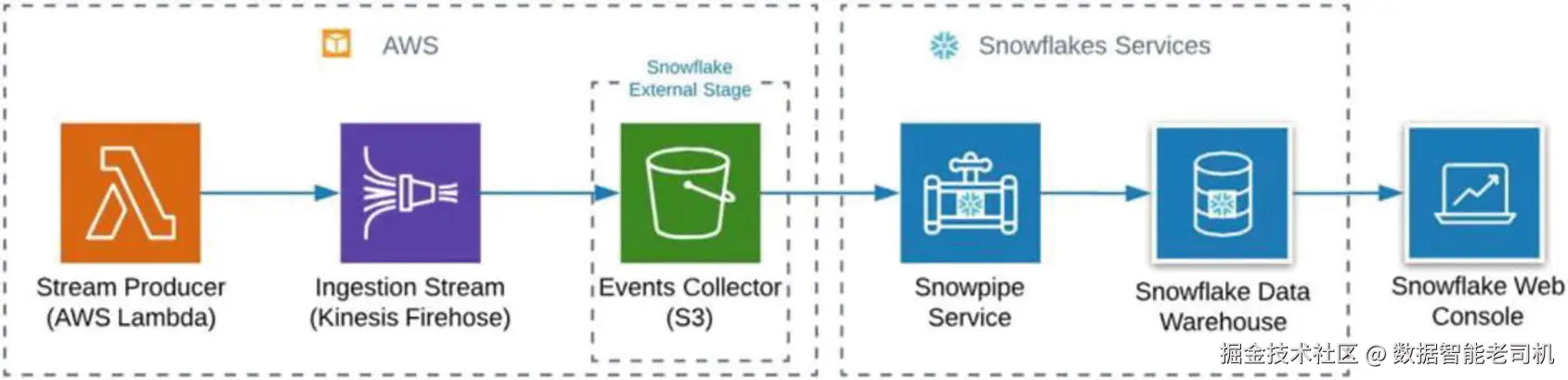
要理解内部集成究竟如何进行,我们需要稍微深入了解 Snowpipe 的内部结构。图 3-4 展示了集成的主要步骤。
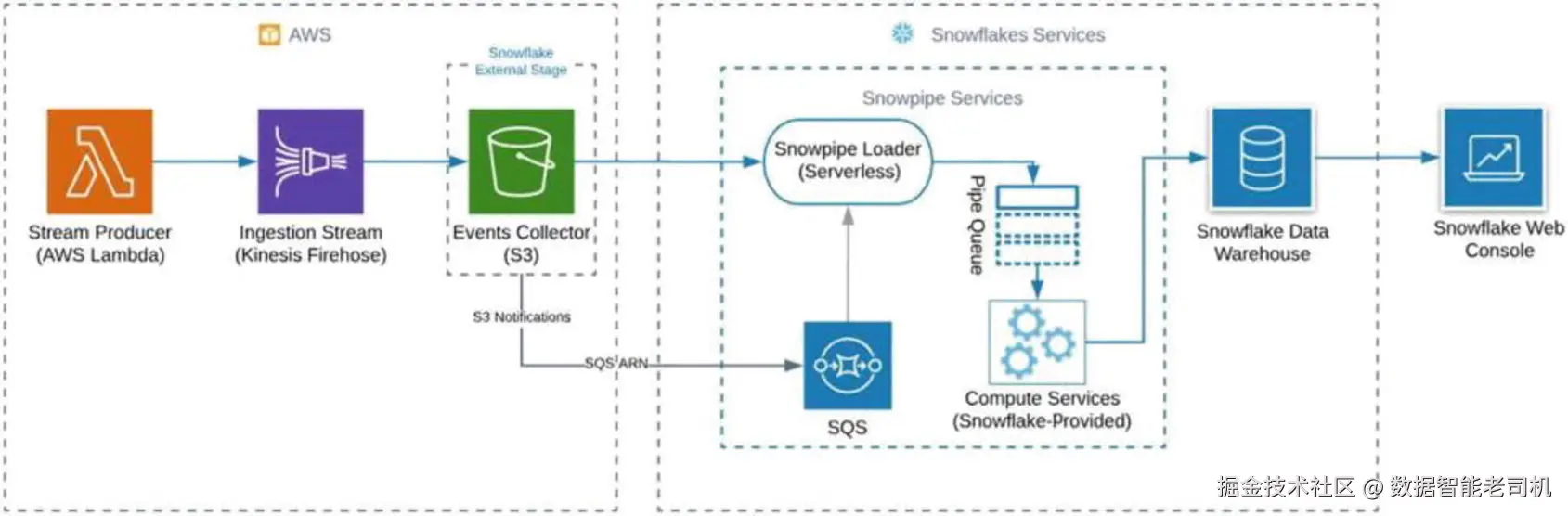
首先,我们需要创建一个外部 stage ,以及一个带有 auto_ingest 选项的 pipe 。当我们执行 DDL 时,需要获取一个内部队列服务 的唯一标识符 (在 AWS 上基于 SQS ),该队列已与 Snowpipe 的无服务器加载器关联。
其次,我们必须创建一个新的 S3 存储桶,并配置S3 存储桶事件通知 ,将通知事件发送到 Snowpipe SNS 。Snowpipe 加载器会接收关于新文件进入 S3 存储桶 的事件,并把包含特定 COPY 命令的 pipe 语句 排入队列。Snowflake 的计算服务在从 pipe 队列执行 DDL 语句时能够完全自动伸缩 。最后一步是创建并配置一个流 ,以高强度地产生大量事件。
注意(Caution) :使用 Snowpipe 进行加载时,无法控制事务边界。
使用 Snowpipe Auto-Ingest 构建数据管道
(BUILDING A DATA PIPELINE USING THE SNOWPIPE AUTO-INGEST OPTION)
本练习将搭建图 3-5 所示的数据管道。具体来说,下面的步骤演示如何使用 Snowpipe 为 Snowflake 创建一个持续数据加载的管道。
-
登录你的 Snowflake 账户,进入 Worksheet。
-
基于 S3 存储桶创建 Snowflake 外部 stage 。
将
<your_AWS_KEY_ID>替换为你的 AWS 凭证,将<your_s3_bucket>替换为你的 S3 存储桶 URL。在 Worksheet 中运行如下 DDL 语句:
sql---- create a new database for testing snowpipe create database snowpipe data_retention_time_in_days = 1; show databases like 'snow%'; ---- create a new external stage create or replace stage snowpipe.public.snowstage url='S3://<your_s3_bucket>' credentials=( AWS_KEY_ID='<your_AWS_KEY_ID>', AWS_SECRET_KEY='<your_AWS_SEKRET_KEY>'); ---- create target table for Snowpipe create or replace table snowpipe.public.snowtable( jsontext variant ); ---- create a new pipe create or replace pipe snowpipe.public.snowpipe auto_ingest=true as copy into snowpipe.public.snowtable from @snowpipe.public.snowstage file_format = (type = 'JSON');注(Note) :
VARIANT是 Snowflake 的通用半结构化数据类型 ,可用于加载 JSON、Avro、ORC、Parquet、XML 等格式。可参阅相关参考资料了解更多信息。上述代码的第一部分基于一个 S3 存储桶创建名为
snowpipe.public.snowstage的外部 stage ;我们提供了 S3 存储桶的 URL 和凭证(也可以设置加密选项)。下一步定义目标表
snowpipe.public.snowtable,用于持续加载 的数据;该表包含一个用于接收 JSON 的VARIANT列。脚本最后定义了一个名为
snowpipe.public.snowpipe的新 pipe 。可以看到将auto_ingest=true打开------表示我们使用 S3 → SQS 的通知来告知 Snowflake 有新数据可加载 。同时,pipe 内部封装了熟悉的COPY语句,用于定义当数据就绪时要执行的转换与加载操作。 -
使用以下命令检查配置是否正确。通过
show语句可以查看任何 pipe 与 stage 的状态。sql---- check exists pipes and stages show pipes; show stages; -
在
show pipes结果中,从 NotificationChannel 字段复制 SQS ARN 链接。 -
用一个简单的
select语句检查已加载数据的条数:sql---- check count of rows in target table select count(*) from snowpipe.public.snowtable -
登录你的 AWS 账户。
-
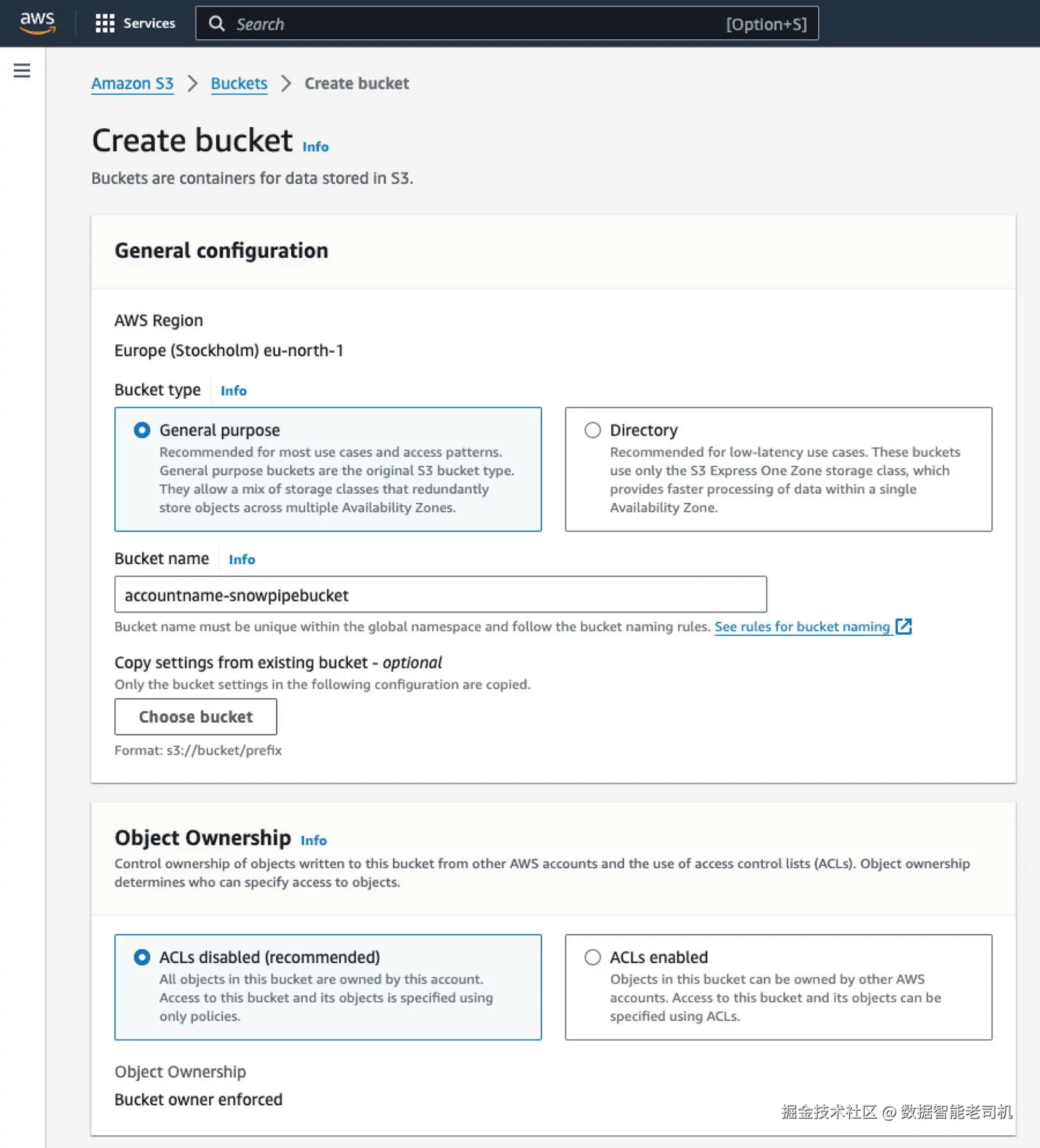
创建名为
<accountname>-snowpipebucket的 AWS S3 存储桶(如图 3-5 所示)。
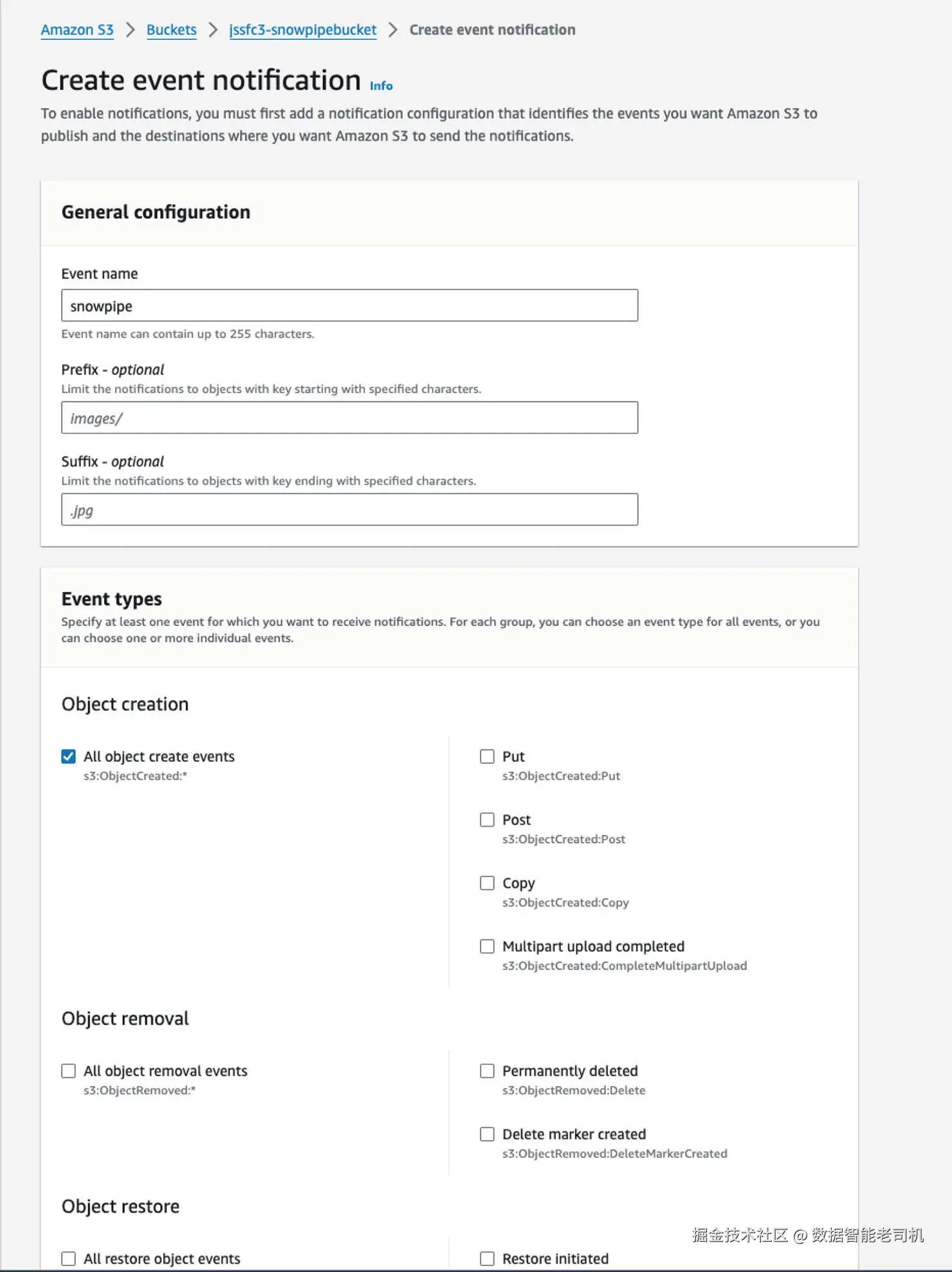
8. 按图 3-6 所示,在 S3 中为 Snowpipe 设置通知事件。路径:
S3 ➤ <accountname>-snowpipebucket ➤ Properties(属性) ➤ Advanced settings(高级设置) ➤ Events(事件) 。
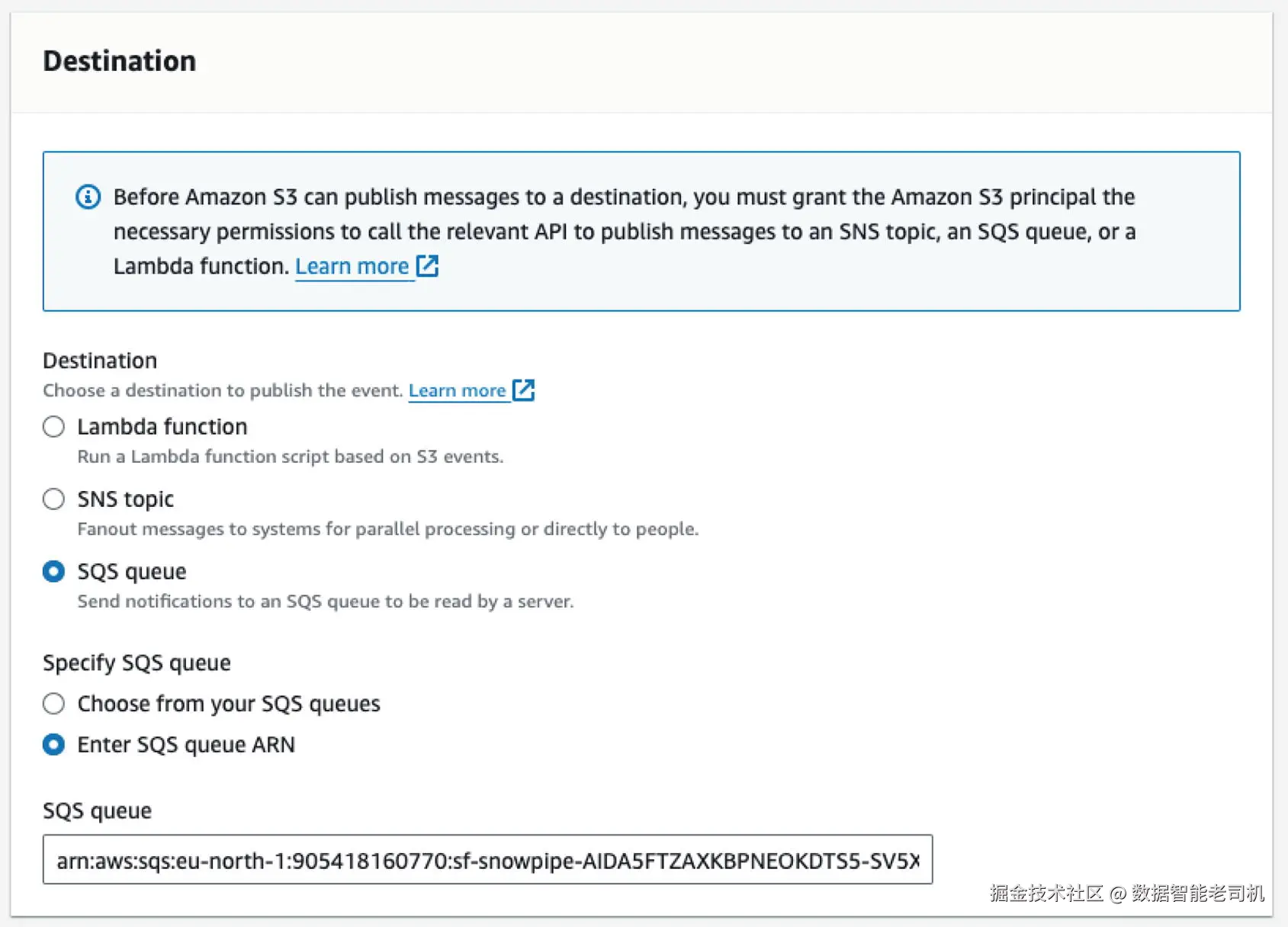
9. 指定 SQS 队列,如图 3-7 所示。
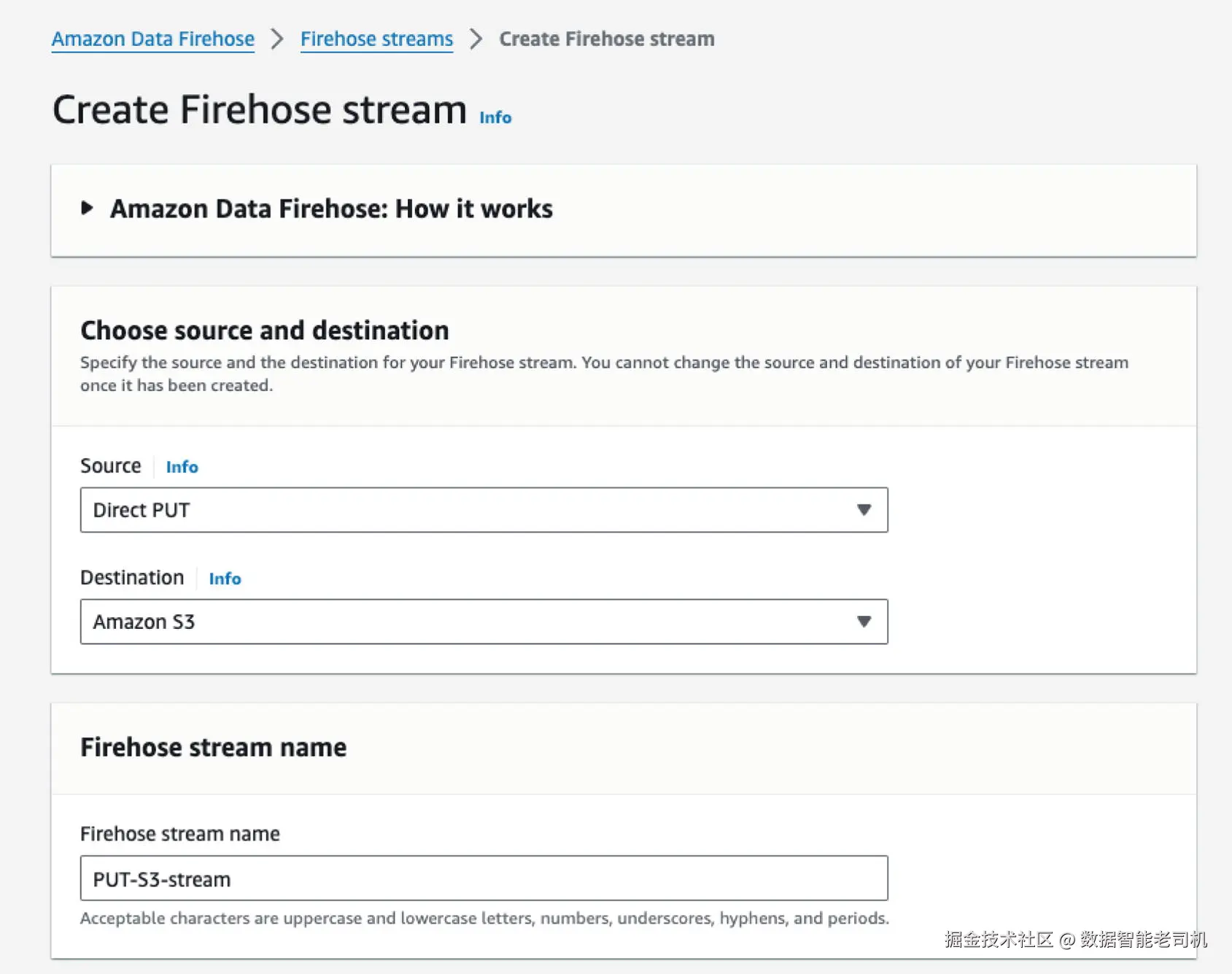
10. 通过以下路径创建新的 Kinesis Data Firehose 流:
Amazon Kinesis ➤ Data Firehose ➤ Create Delivery Stream。
11. 将数据源(Source)设置为 Direct PUT(直接 PUT) ,如图 3-8 所示。
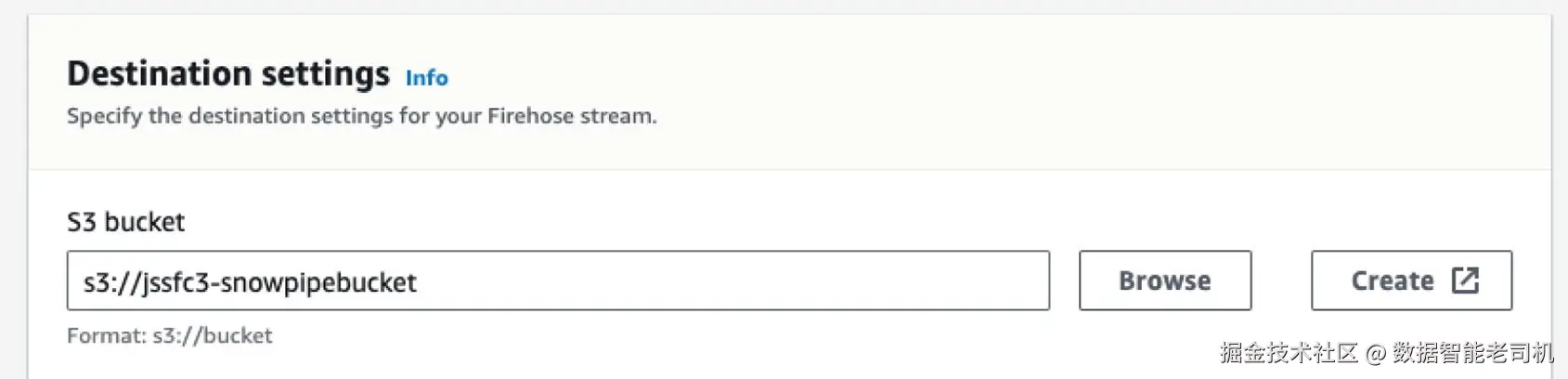
12. 选择 S3 存储桶作为目标(Destination),如图 3-9 所示。
13. 使用 CloudWatch 服务启用日志记录,如图 3-10 所示。
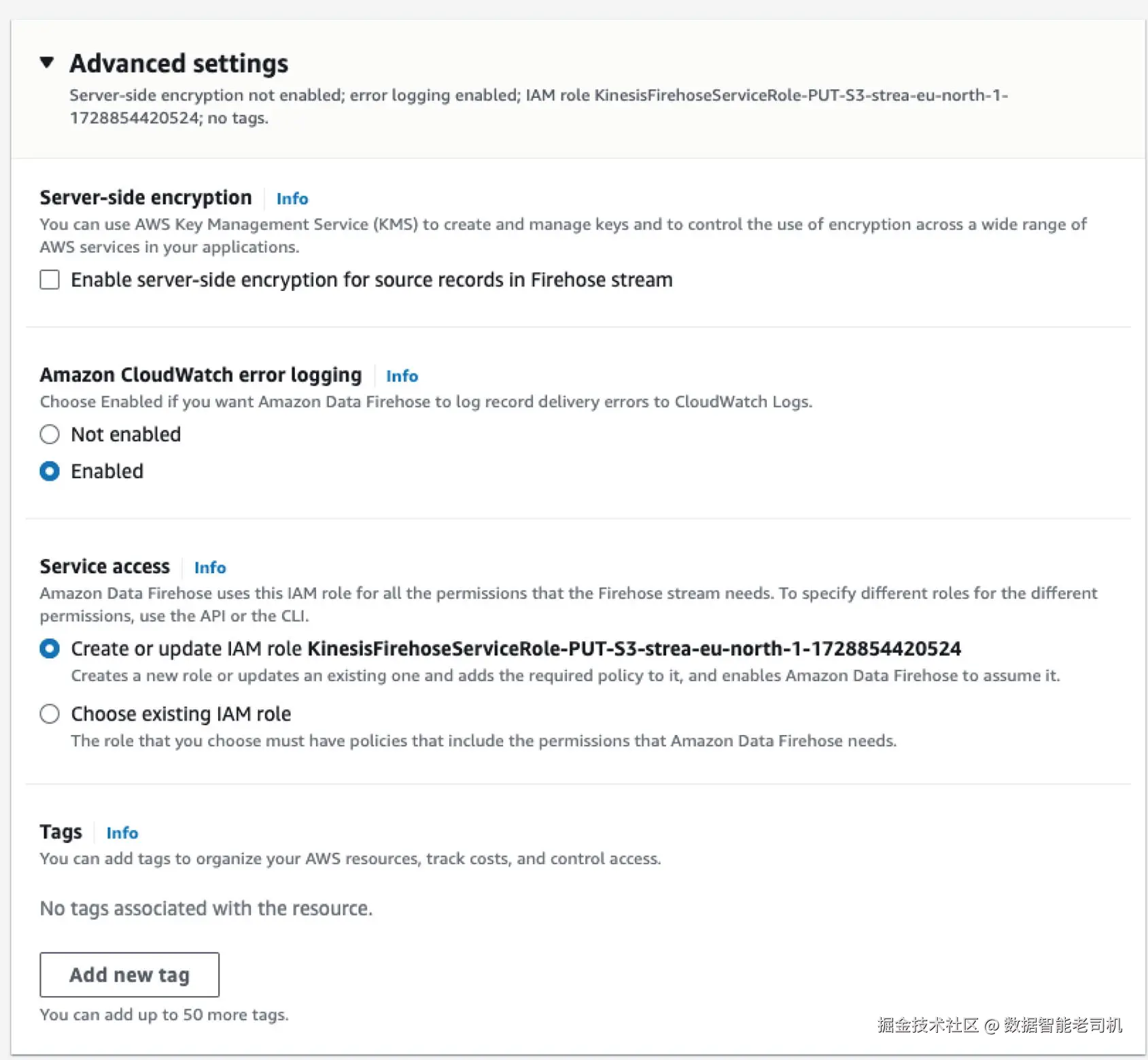
14. 创建一个 IAM 角色,并按如下策略进行配置:
erlang
...
{
"Sid": "",
"Effect": "Allow",
"Action": [
"s3:AbortMultipartUpload",
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::snowpipebucket",
"arn:aws:s3:::snowpipebucket/*",
]
},
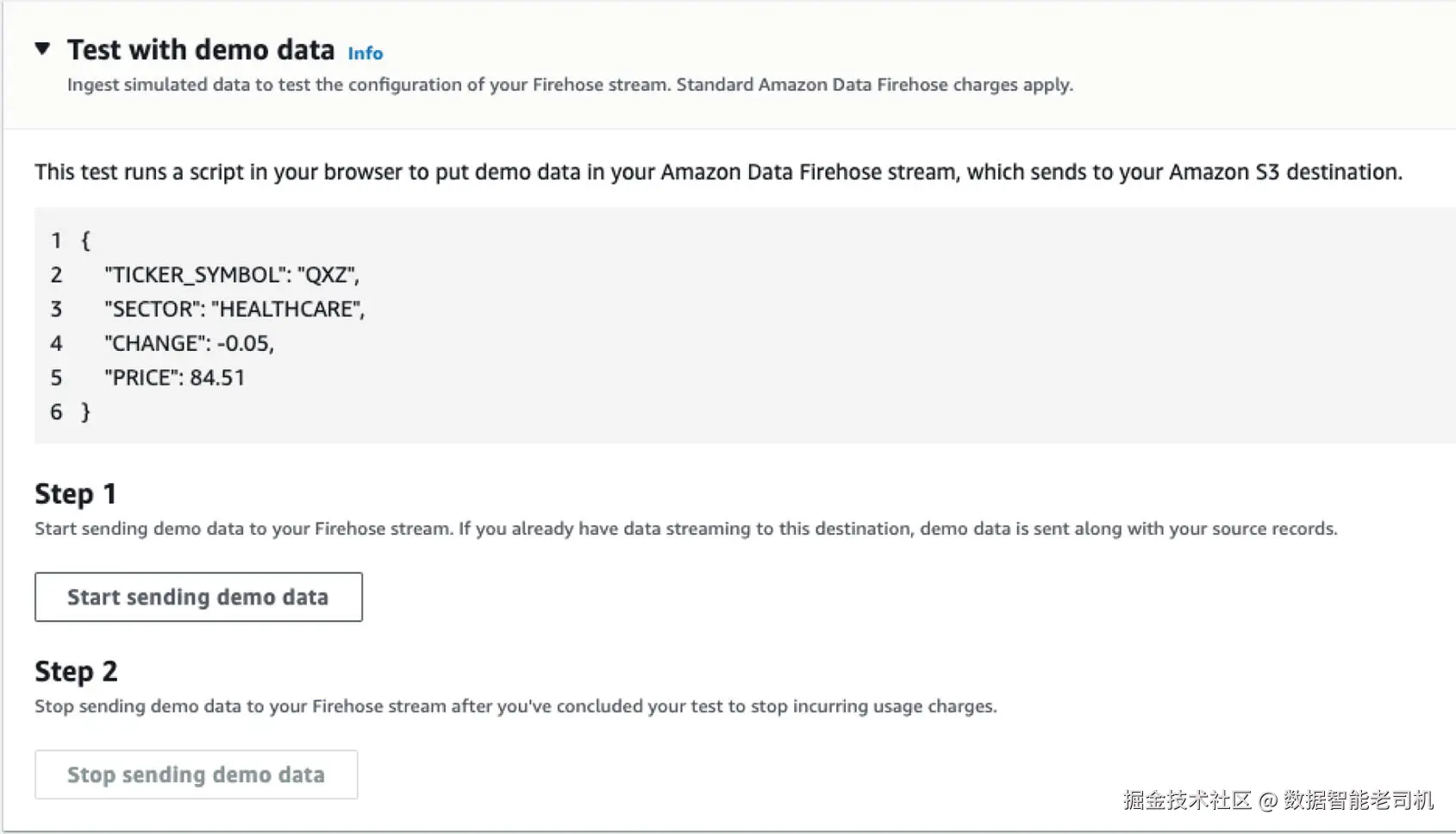
...15. 运行测试流(testing stream),如图 3-11 所示。
16. 在 S3 存储桶中检查文件。
17. 检查已加载数据的条数。
sql
---- check count of rows in target table
select count(*) from snowpipe.public.snowtable借助 AWS Lambda 使用 Snowpipe REST API(Snowpipe REST API Using AWS Lambda)
如果由于某些原因你的账户无法使用 auto-ingest 选项,你需要一种更灵活 的方式与其他服务集成,从而仍可通过 Snowpipe REST API 来实现你的方案。图 3-12 展示了如何使用该 REST API 配合自定义应用来构建数据管道。
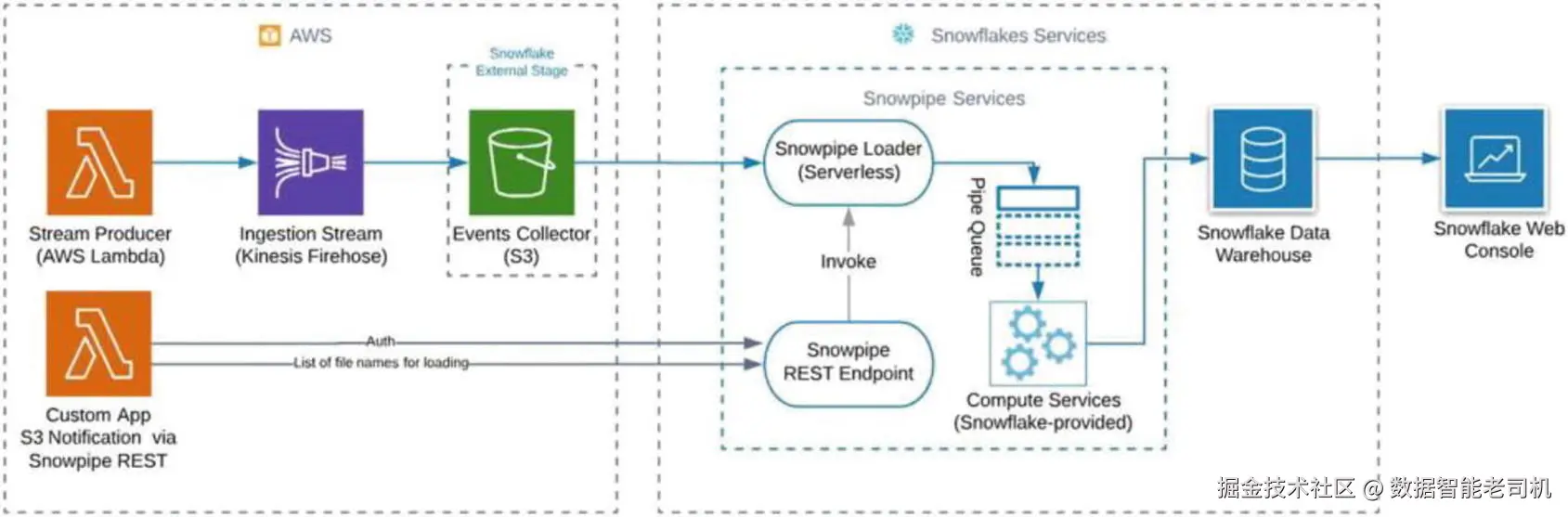
图 3-12 展示了第二种方案 。左侧是你的应用程序 :它既可以是运行在虚拟机 或 Docker 容器 中的真实应用,也可以是你在 AWS Lambda 上运行的代码。你的 Lambda 函数 或应用在文件落盘 后,负责将待加载文件放入 S3 存储桶。
随后,Snowpipe 会把这些文件加入位于 REST API 端点之后的队列 。你调用 REST API ,从而触发 Snowpipe 加载服务(loader) ;该服务从队列取任务 ,把数据加载到你所定义的目标表 中。若需逐步的操作指南,可参考官方文档。
在 Snowflake 中使用动态表(Working with Dynamic Tables in Snowflake)
动态表(Dynamic Tables)是 Snowflake 中功能强大且独特的能力,允许对流式数据 进行持续且增量 的转换(transformation)。这既能实现近实时 的数据管道、加快数据处理,又能减少对批处理 ETL 的依赖。下面将说明动态表的工作原理、如何设置,以及如何把它们集成到你的 Snowflake 数据架构中。
什么是动态表?(What Are Dynamic Tables?)
在 Snowflake 中,动态表提供一种机制:根据源表的变化 ,自动、持续 地刷新目标表数据。其关键特性在于:无需人工干预或复杂编排 ,即可持续管理增量转换 。当你处理需要经常转换或聚合的高速数据时,动态表尤其有用。
本质上,动态表让你自动将 SQL 查询实体化为表 ;系统会跟踪数据变化 ,并在新数据流入 时更新这些表。可以把动态表看作数据架构中的**"响应式层"**:对上游变化做出反应,而无需手动刷新或定时批处理任务。
这种响应式架构 与 Snowflake 事件驱动 的数据加载方式(特别是与 Snowpipe 搭配)非常契合,可确保你的数据始终是最新的。
为什么使用动态表?(Why Use Dynamic Tables?)
- 持续转换 :不同于周期性运行的批处理,动态表会在源数据一更新 时就运行转换,适合近实时分析。
- 自动刷新 :无需调度作业或手动刷新,Snowflake 会根据底层数据变化自动保持最新。
- 简化管道:不必编写复杂的增量处理逻辑,动态表替你处理这些复杂性。
- 可伸缩性:依托 Snowflake 的弹性基础设施,随着数据量增长仍能高效运行。
使用动态表实现持续数据加载
(USING DYNAMIC TABLES FOR CONTINUOUS DATA LOADING)
下面通过步骤演示如何在 Snowflake 中创建并使用动态表 。假设已有一条通过 Snowpipe 摄取 到 Snowflake 的数据流 。本示例将创建一个动态表,持续 从第一节练习中创建的表 SNOWTABLE 的 JSON 列提取关键字段,并写入一个新的结构化 表中。借助动态表,随着数据变化或加载 ,持续转换会自动发生。
1. 登录你的 Snowflake 账户,进入 Worksheet。
2. 创建仓库(动态表执行查询需要计算资源)。可使用以下 SQL:
ini
-- Creating a Warehouse in Snowflake
CREATE WAREHOUSE IF NOT EXISTS my_warehouse
WITH
WAREHOUSE_SIZE = 'XSMALL'
AUTO_SUSPEND = 300
AUTO_RESUME = TRUE;注:
WAREHOUSE_SIZE = 'XSMALL'指定仓库大小(可按需调整为SMALL、MEDIUM等)。AUTO_SUSPEND = 300表示空闲 5 分钟自动挂起,有助于节省成本。AUTO_RESUME = TRUE允许在有查询需要时自动恢复,免去手动干预。
3. 运行 CREATE WAREHOUSE 后验证是否创建成功:
ini
SHOW WAREHOUSES;4. 定义动态表 ,自动转换 JSON 数据并存入 TRANSFORMED_JSON(示例):
vbnet
CREATE OR REPLACE DYNAMIC TABLE transformed_json_table
WAREHOUSE = 'MY_WAREHOUSE'
TARGET_LAG = '5 minutes'
AS
SELECT
json_key,
json_value
FROM (
WITH transformed_json AS (
SELECT
JSONTEXT,
PARSE_JSON(JSONTEXT) AS json_data
FROM
SNOWTABLE
),
flattened_json AS (
SELECT
t.JSONTEXT,
f.key AS json_key,
f.value AS json_value
FROM
transformed_json t,
LATERAL FLATTEN(input => t.json_data) f
)
SELECT
json_key,
json_value
FROM
flattened_json
);在此,我们定义了会自动 从 SNOWTABLE 查询并转换 数据的动态表。
-
每当有新数据加载到
SNOWTABLE,Snowflake 都会更新transformed_json_table。 -
AS之后的 SQL 完成以下步骤:- 用
PARSE_JSON解析 JSON 字符串; - 使用
LATERAL FLATTEN展开 JSON 结构,提取键值对。
- 用
-
动态表会依据
TARGET_LAG周期性处理数据更新:TARGET_LAG = '5 minutes'表示每 5 分钟刷新一次;- 设为更低值(如 1 分钟 )可获得更近实时 的更新,但计算成本可能上升;
- 可在 Snowsight 中查看刷新历史以了解上次更新时间。
5. 测试 动态表:与前一练习类似,向 S3 存储桶上传一个 JSON 文件以触发流程。
6. 如有需要,可刷新 Snowpipe 以捕获数据:
ini
ALTER PIPE SNOWPIPE REFRESH;7. 验证动态表结果:
sql
-- Query the transformed_json_table
SELECT * FROM transformed_json_table;通过本示例,你已了解如何利用 Snowflake 动态表 ,将存放在 SNOWTABLE 的 JSON 数据自动转换 为结构化 结果。它展示了如何用 Snowpipe 做持续加载 ,并用动态表 做实时转换 ,而无需人工干预。
将 Snowpipe 与 动态表 结合,你可以构建稳健、可扩展 、且运维开销极小 的数据管道;动态表能让转换与摄取保持同步 ,确保下游表 始终最新。
小结(Summary)
本章探讨了 Snowpipe 在持续数据加载 方面的能力,重点讲解了如何在 Snowflake 中高效构建与维护数据管道 。我们介绍了将 Snowpipe 与云存储集成以实现近实时数据摄取 的关键特性,审视了计费 相关考量,并讨论了多种数据摄取管理选项。
此外,本章引入了动态表(Dynamic Tables)这一强大工具,用于对流式数据 进行增量自动转换 。我们示范了如何设置基于底层数据变化持续刷新 的动态表,从而实现无缝、近实时的数据转换。
下一章将深入 Snowflake 管理 ,讨论对仓库(warehouses)、数据库(databases)与角色(roles)等核心对象 的管理,并介绍如何为可扩展性与性能优化你的 Snowflake 环境。