GPGPU架构特点
由于典型的GPGPU只有小的流缓存,因此一个存储器和纹理读取请求通常需要经历全局存储器的访问延迟加上互连和缓冲延迟,可能高达数百个时钟周期。与CPU通过巨大的工作集缓存而降低延迟不同,GPU硬件多线程提供了数以千计的并行独立线程,这些线程可以在一个多处理器内部充分利用数据局部性共享数据,同时利用其他线程的计算掩盖存储访问延时。在一个线程等待数据和纹理加载时,硬件可以执行其他线程。尽管对于单个线程来说存储器访问延迟还是很长,但整体访存延时被掩盖,计算吞吐率得以提升。
例如:当一个warp的一条指令需要等待先前启动的长延迟操作的结果时,这个warp将不会被选中执行。系统将调度另一个不必等待的常驻warp。如果有多个warp能被调度,这就需要一个优先级机制来完成调度。这种利用其他线程的执行来覆盖延迟时间的机制被称为"容许时延"或者"延迟隐藏"。
容许时延
容许时延在日常生活中也很常见。例如,在邮局里,每个人在寄包裹时,在去服务台之前应该填好所有的表格和标签。然而,正如我们所经历的一样,很多人会在填表时询问服务台工作人员要填写哪些表格以及如何填写。
当有很多人在服务台前等待时,就需要最大限度地提高工作人员的工作效率。当一个顾客在填写表格时,让其他顾客继续等待的做法是不可取的。工作人员应该在这个顾客填写表格时去帮助其他的顾客。这些其他的顾客是准备好的并且不会被其他需要更长时间的顾客阻塞。
所以,一个好的工作人员都会礼貌地让第一个顾客去旁边填写表格,以便能让后面的顾客及时得到帮助。在大多数情况下,第一个顾客填完表格后,只要工作人员服务完当前顾客后便能马上得到服务,而不是重新排到队尾。
我们可以将这些顾客想象成 warp,工作人员就是硬件执行单元。需要填写表格的顾客相当于一个需要等待长延迟操作的 warp。
GPGPU流水线技术
流水线技术是利用指令级并行,提高处理器IPC的重要技术之一。它在标量处理器中已经得到了广泛应用。不同功能的电路单元组成一条指令处理流水线,利用各个单元同时处理不同指令的不同阶段,可使得多条指令同时在处理器内核中运行,从而提高各单元的利用率和指令的平均执行速度。
在大多数GPGPU架构中,虽然指令的执行粒度变为包含多个线程的线程束,但为了提高指令级并行,仍然会采用流水线的方式提高线程束指令的并行度。与单指令流水线相比,可以想象成水管变得更粗。当线程束中所有的线程具有相同的指令路径时,指令流水的方式与标量流水线类似。
图1显示了一种典型的GPGPU架构流水线设计。可以看到,每个线程束按照流水方式执行指令的读取(fetch)、解码(decode)、发射(issue)、执行(execute)及写回(writeback)过程。
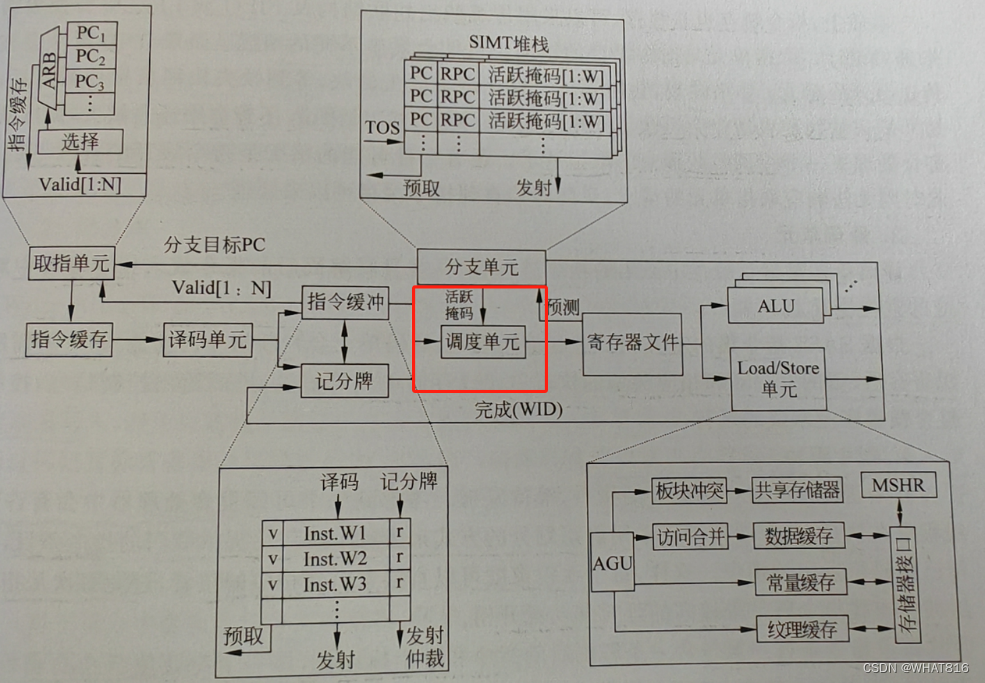
图1
与本文介绍内容相关的部分为调度单元,图1以及用红框标出。
调度单元
调度单元通过线程束调度器(warp scheduler)选择指令缓冲中某个线程束的就绪指令发射执行。发射会从寄存器文件中读取源寄存器传送给执行单元。调度器则很大程度上定了流水线的执行效率。
线程束并行、调度与发射
在编程人员看来,线程是按照线程块指定的配置规模来组织和执行的。从硬件角度看,当一个线程块被分配给一个可编程多处理器后,GPGPU会根据线程的编号(TID),将 若干相邻编号的线程组织成线程束。线程束中所有线程按照锁步方式执行,所有线程的技行进度是一致的,因此一个线程束可以共享一个PC。线程束中每个线程按照自己线程TID和标量寄存器的内容来处理不同的数据。多个线程聚集在一起就等价于向量操作,多个线程的标量寄存器聚集在一起就等价于向量寄存器,向量宽度即为线程束大小。
大量的线程束提供了高度的并行性,使得GPGPU可以借助零开销的线程束切换来藏如缓存缺失等长延时操作。原则上线程束越多,并行度越高,延时掩藏的效果可能会越好。但实际上这个并行度是由一个可编程多处理器中可用的硬件资源及每个线程的资源需求决定的,如最大线程数、最大线程块数及寄存器和共享存储器的容量。例如,在NVIDA V100 GPGPU中,一个可编程多处理器最多同时执行 2048个线程,即64个线程束或 32个线程块,并为这些线程提供了65536个寄存器和最多96KB的共享存储器。如果一个kernel函数使用了2048个线程且每个线程使用超过32个寄存器,那么就会超过一个可编程多处理器内部寄存器数量;如果每个线程束占用的共享存储器超过1536B,那么共享存储器的资源无法支撑足够多的线程束在可编程多处理器中执行。最终执行时可达到的线程并行度是由线程块、线程、寄存器和共享存储器中允许的最小并行度决定的。由于并不是所有资源都能够同时达到满载,因此对于非瓶颈的资源来说存在一定的浪费。
例如:假定每个SM包含16384个寄存器,kernel代码中的每个线程需要使用10个寄存器。线程块大小为16×16,那么每个SM上能运行多少个线程?我们要想回答这个问题,首先要计算每个块要用到多少个寄存器,一共是10×16×16=2560个。6个块则需要用到15360个寄存器,没有超过16384的上限。增加一个线程块将需要17920个寄存器,这个数量超出了限制。因此,寄存器的限制只允许线程块总共有1536个线程在每个SM上运行,也满足了线程槽1536个线程的限制。
现在假设程序员在kernel中又声明了另外2个自动变量,这样每个线程要使用的寄存器的数量将会上升到12个。假设线程块大小还是16×16,那么现在每个块需要12×16×16=3072个寄存器。6个块现在需要18432个寄存器,这已经超过了寄存器数量的限制范围。SM通过减少一个块来处理这种情况,因此所需要的寄存器的数目减少到15360个。然而,这也使得在 SM 上运行的线程数从1536个减少到1280个,也就是说,多使用2个自动变量,程序中warp的并行性减少了1/6。这有可能导致所谓的性能悬崖,即资源的使用稍微有些增加就可能会导致并行性和性能急剧减少。
Note:kernel资源线程块与线程束分配并非越多越好,而是应该根据SM资源合理分配。
当可编程多处理器中有众多线程束且处于就绪态(或活跃)时,需要调度器从其中挑造出一个。这个被选中的线程束会在接下来的执行周期中根据它的PC发射出一条新的指令来执行。从整个可编程多处理器角度看,由于调度器每个周期都可以切换它所选择的线程束,不同线程束的不同指令可能会细粒度地交织在一起,而同一个线程束的指令则是顺序行的,如图2所示。调度器需要根据 GPGPU的架构特点设计合适的策略来做出这个选择,尽可能保证SIMT执行单元不会空闲。
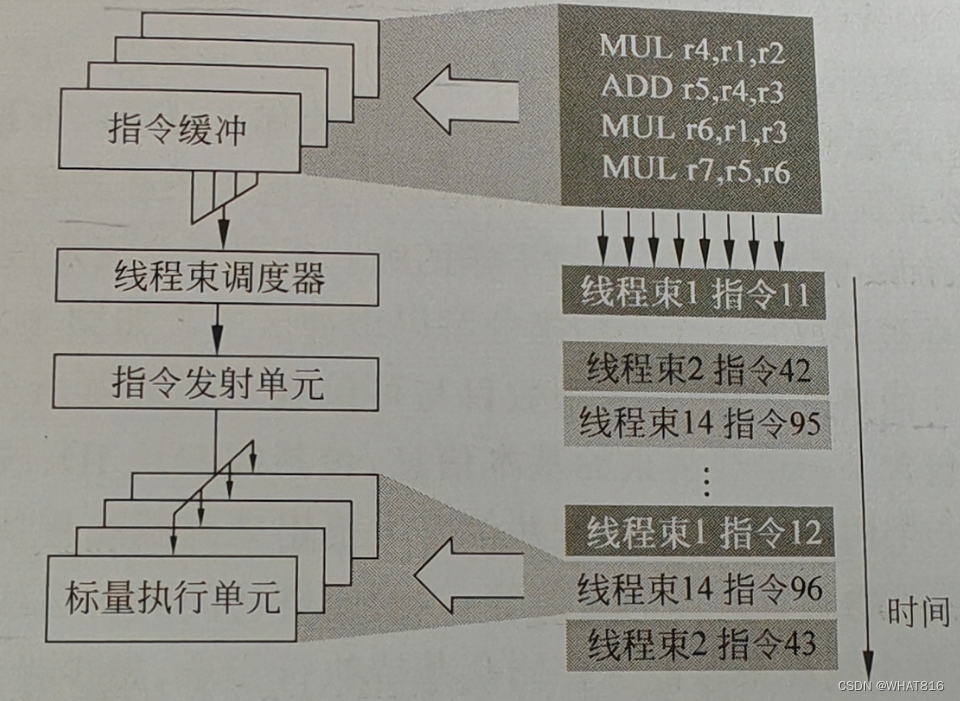
图2
线程束调度器往往采用基本的轮询(Round-Robin,RR)调度策略。如图3所示,它在调度过程中,对处于就绪状态的线程束0、1、3、4、5都赋予相同的优先级,并按照轮询的策略依次选择处于就绪状态的线程束指令进行调度,完成后再切换到下一个就绪线程束,如线程束0、1、3、4、5都执行完成第1条指令(指令 0)后再重复上述过程直到执行结束。与之相对应的另一种策略称关GTO(Greedy-Then-Oldest)。该策略允许一个线程束按照贪心策略一直执行到不能执行为止。例如,当线程遭遇了缓存缺失,此时调度器再选择一个最久未调度的线程束来执行如果再次停顿再调度其他线程束,直到执行结束。
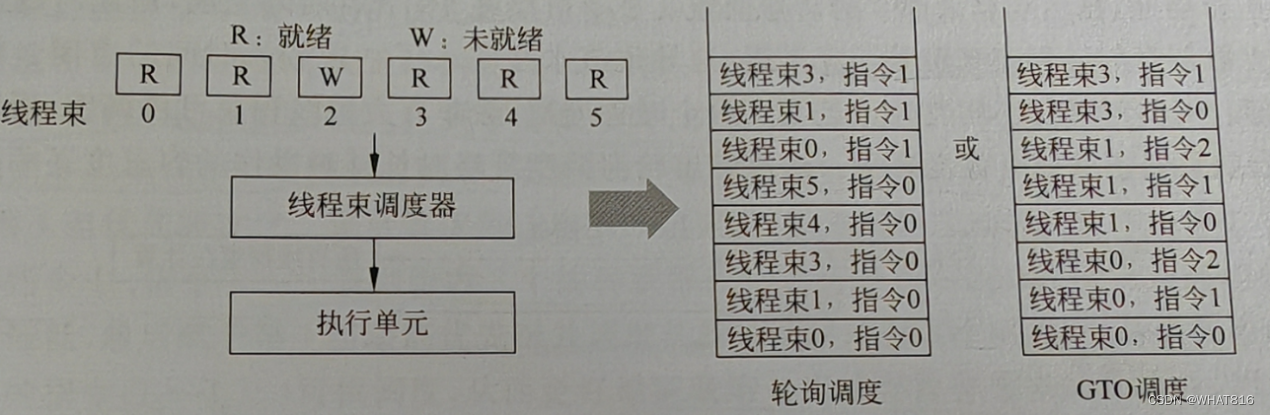
图3
线程块分配与调度
线程块的分配和调度是GPGPU硬件多线程执行的前提。线程块的分配决定了哪些线程块会被安排到哪些可编程多处理器上执行,而线程块的调度决定了已分配的线程块按照什么顺序执行。两者关系密切,对于GPGPU的性能有着直接的影响。
在线程块分配方面,GPGPU通常采用轮询作为基本策略。首先,线程块调度器将按照轮询方式为每个可编程多处理器分配至少一个线程块,若第一轮分配结束后可编程多处理器上仍有空闲未分配的资源(包括寄存器、共享存储器、线程块分配槽等),则进行第二轮分配,同理,若第二轮分配后仍有资源剩余,可以开始下一轮资源分配,直到所有可编程多处理器上的资源饱和为止。对于尚未分配的线程块,需要等待已分配的线程块执行完毕并将占有的资源释放后,才可以分配到可编程多处理器上执行。由于GPGPU执行的上下文信息比较丰富,为了方便管理并简化硬件,GPGPU一般不允许任务的抢占和迁移,即当一个线程块分配给一个可编程多处理器之后,在其完成之前不会被其他任务抢占或迁移到其他可编程多处理器上执行。
图4描述了一个基于轮询的线程块分配示例。假设一个GPGPU中有3个可编程多处理器,分别为SM0、SM1和SM2,每个 SM 允许最多同时执行2个线程块。一个内核函数声明了12个线程块 TB0~TB11。根据轮询的原则,TB0~TB2被分配到SM0~SM2。由于每个SM可以同时执行2个线程块TB3~TB5 也被分配到SM0~SM2中。此时,SM的硬件资源已经被完全占用,剩下的线程块暂时无法分配到SM中执行,必须等待有线程块执行完毕释放硬件资源,才能继续分配。一段时间后,SM2中TB5 率先执行完毕释放硬件资源,TB6被分配到SM2中执行。之后 SM0 中 TB3 执行完毕,TB7被分配到 SM0 中执行。最终线程块执行的流程如图4所示。可以看到,初始一轮的线程块分配顺序还比较有规律,但第二轮的维程块分配完全是按照执行进度来安排的。

图4
基于轮询的线程块分配策略简单易行,而且保证了GPGPU中不同可编程多处理器之间的负载均衡,尽可能公平地利用每个可编程多处理器的资源。然而,**轮询的分配策略也存在一定问题,比如可能会破坏线程块之间的空间局部性。**一般情况下,相邻线程块所要访问的数据地址由于与其线程ID等参数线性相关,很大可能会存储在全局存储器中连续的地址空间上,因此相近的线程块所需要的数据在DRAM或缓存中也相近。如果将它们分配在同一个可编程多处理器上,就可以访问DRAM中的同一行或缓存的同一行,利用空间局部性减少访存次数或提高访存效率。轮询的分配策略反而会将它们分配到不同的可编程多处理器上,导致相邻数据的请求会从不同的可编程多处理器中发起。如果随着执行时间的推进,线程块的执行进度有明显的差别,可能会降低访存合并的可能性,对性能造成不利的影响。
线程块的调度与线程束的调度策略有很高的关联性。两者对GPGPU的执行性能都有着重要的影响,所关注的问题也类似,只是调度的粒度有所不同。因此可以看到两者所采用的策略有很多相似之处,比如轮询调度策略,GTO调度策略对于线程块的调度也同样适用很多线程束调度的改进设计思想也可以应用在线程块调度问题上,或将两者联系起来作为一个整体来考虑。例如,通过建立线程束调度器和线程块调度器之间的交互,调度器更好地协调多个可编程多处理器之间的线程执行。
线程块的调度与线程块的分配策略也密切相关,分配方式也会影响到调度的质量。例如,每个可编程多处理器中线程块最大可分配的数量就与调度策略和执行性能相关。轮询的分配策略虽然具有公平性,但按照可编程多处理器允许的最高并行度将尽可能多的线程块分配执行,并不一定会提升应用的性能。很多研究统计表明,随着可编程多处理器中运行的线程块数目的增加,一些应用的性能只会缓慢提升甚至下降。
图5的例子对这个问题给出了直观的解释。假设有4个线程块TB0~TB3 被分配到一个可编程多处理器上。图5(a)中假设线程块和各自的线程束都按照GTO的方式进行调度。那么当一个线程块,如 TB0 执行遭遇停顿,此时会去调度其他线程块如 TB1、TB2 或 TB3 执行。由于线程块的计算执行相对较长,假设在 TB3 被调度之前,TB0的长延人时操作就已经完成,那么遵循GTO 策略的调度器会倾向于重新执行 TB0,使得TB3不会得到调度。此时将TB3分配到这个可编程多处理器上其实对性能是没有帮助的,反而可能会由于分配了过多的线程块而导致资源紧张,因此可能会发生随着线程块数目的增加性能反方而下降的情况。如果改变线程块的调度策略为轮询策略也同样存在问题,如图5(b)就显示了这样一种情况,假设 TB3 和 TB0 读取的数据都存放在同一缓存行中,就会导致TB3和TB0在数据缓存上存在竞争。此时线程块的轮询调度会调度TB3执行,使得 TB0 刚刚访问返回的数据受到影响,因冲突缺失导致缓存抖动问题,增加了缓存缺失率和访问开销也会导致随着线程块数量的增加性能反而下降的情况。
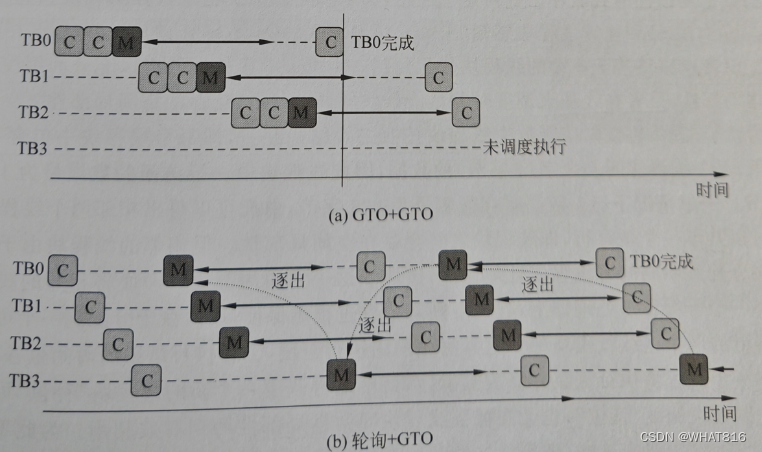
图5
Note:线程块的分配与kernel运行时的调度相关,以分配的线程块数量正好满足调度策略掩盖延迟为宜。所以应该调整线程块大小满足上述要求。
参考文献:
1、通用图形处理器设计
2、大规模并行处理器编程实战(第2版)