互联网应用中,为了提高数据获取的即时性,产生了各种分布式缓存组件,比如Redis、Memcached等等。
大模型时代,除非是免费模型,否则每次对话都会花费金钱来进行对话,对话是不是也可以参照缓存的做法来提高命中率,即时响应提高需求呢。
近日,月之暗面提出了上下文缓存的概念。
Context Caching (上下文缓存)是一种高效的数据管理技术,它允许系统预先存储那些可能会被频繁请求的大量数据或信息。这样,当您再次请求相同信息时,系统可以直接从缓存中快速提供,而无需重新计算或从原始数据源中检索,从而节省时间和资源。
不过定价还是比较贵的,按时长计算。特别是对于智能客户场景,用户提问的问题总归是趋于收敛的,所以可以节省不少资金花费。
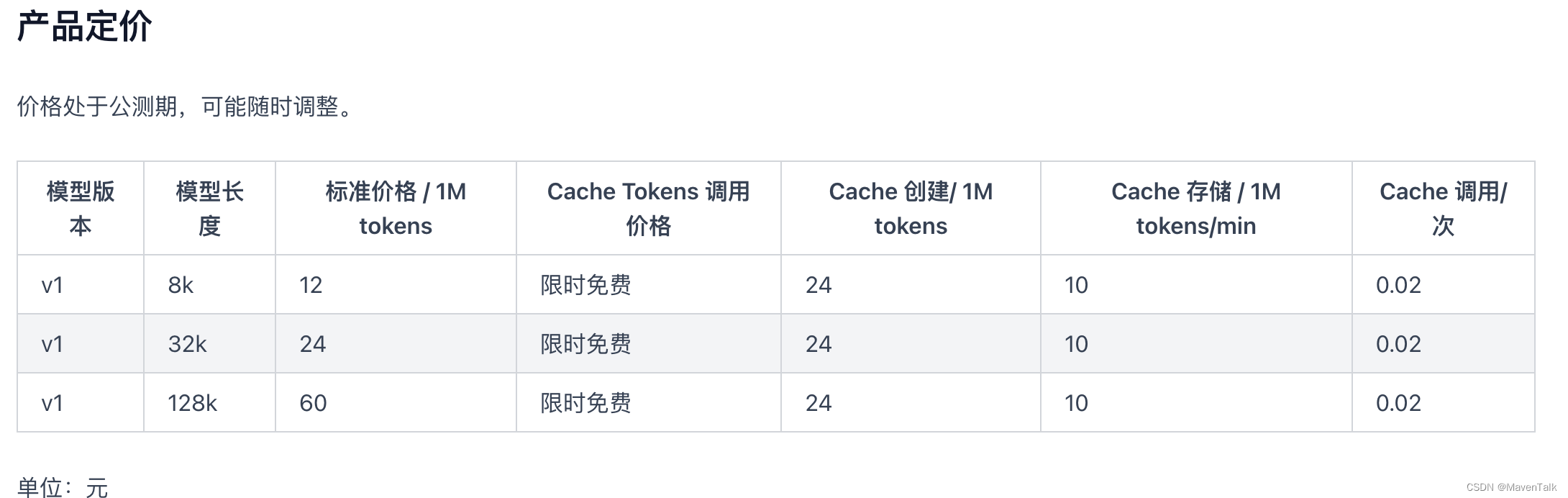
同样,使用分布式缓存的做法,一样可以完成对话缓存,每次提问先经过模型比对,因为有语义理解能力,即便不是同一句话,但意思相同,一样可以认为是命中,命中后就可以直接从缓存中取出数据来响应用户。
Context Caching 特别适合于用频繁请求,重复引用大量初始上下文的情况,通过重用已缓存的内容,可以显著提高效率并降低费用。因为这个功能具有强烈的业务属性,我们下面简单列举一些合适的业务场景:
- 提供大量预设内容的 QA Bot,例如 Kimi API 小助手。
- 针对固定的文档集合的频繁查询,例如上市公司信息披露问答工具。
- 对静态代码库或知识库的周期性分析,例如各类 Copilot Agent。
- 瞬时流量巨大的爆款 AI 应用,例如哄哄模拟器,LLM Riddles。
- 交互规则复杂的 Agent 类应用,例如什么值得买 Kimi+ 等。