本文的思维导图如下:
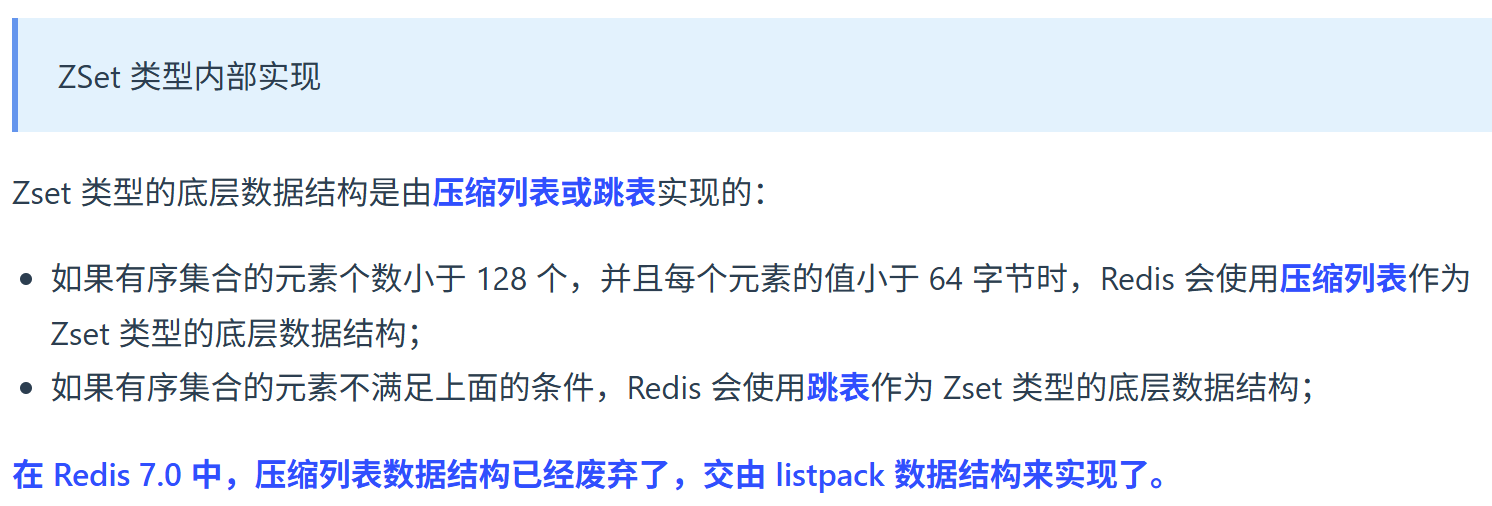
一、数据类型
注意:数据结构 ≈ 数据类型
Redis 提供了丰富的数据类型,常见的有 五种基本类型:
- String(字符串)
- Hash(哈希)
- List(列表)
- Set(集合)
- Zset(有序集合)
随着 Redis 版本的更新,后面又支持了四种高级类型:
- BitMap(2.2 版新增)
- HyperLogLog(2.8版新增)
- GEO(3.2 版新增)
- Stream(5.0 版新增)
(一)String
1. 是什么?
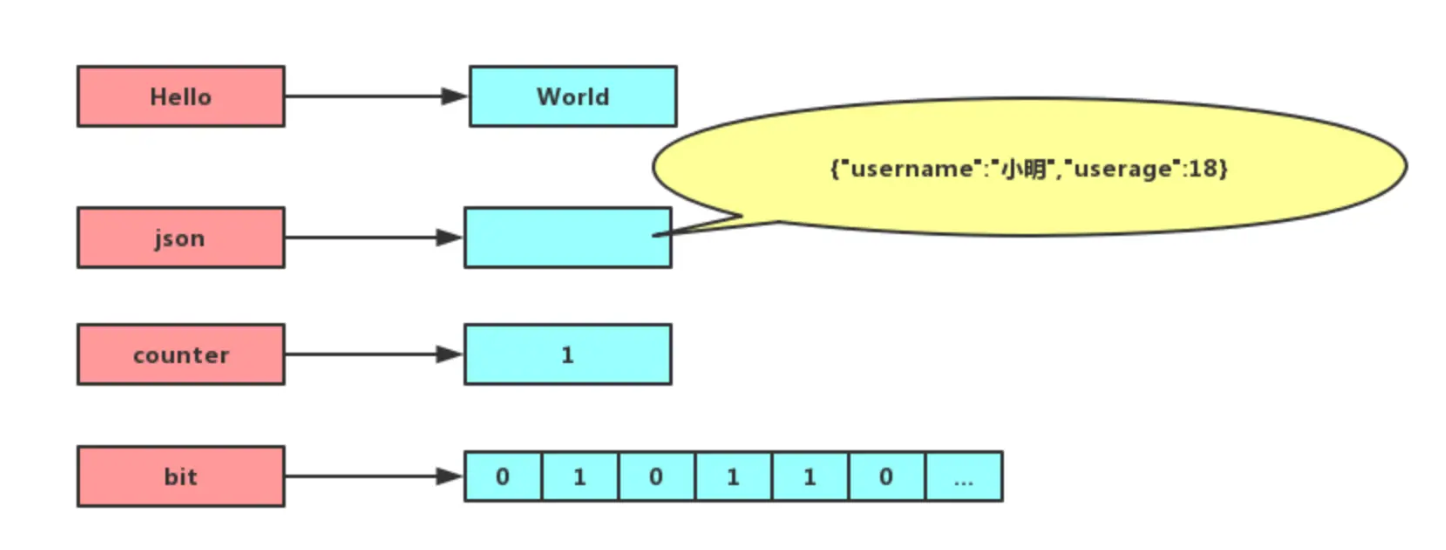
String(字符串)是 Redis 中最基本的数据类型、key-value 结构。
key 是唯一标识,value 是具体的值,value 可以存储任意类型的数据,比如文本、数字和二进制数据,value 的最大长度为512MB。
2. 底层结构
Redis 的 String 的底层数据结构:动态字符串 SDS(Simple Dynamic String)。
SDS 结构包含:
plsql
len 当前字符串长度
alloc 已分配的空间
flags 类型标识
buf[] 真正的字符串内容📌 特点:
- 二进制安全(可以存任意数据)
- 自动扩容 / 不会溢出
- 支持 O(1) 获取长度(因为有 len 字段)
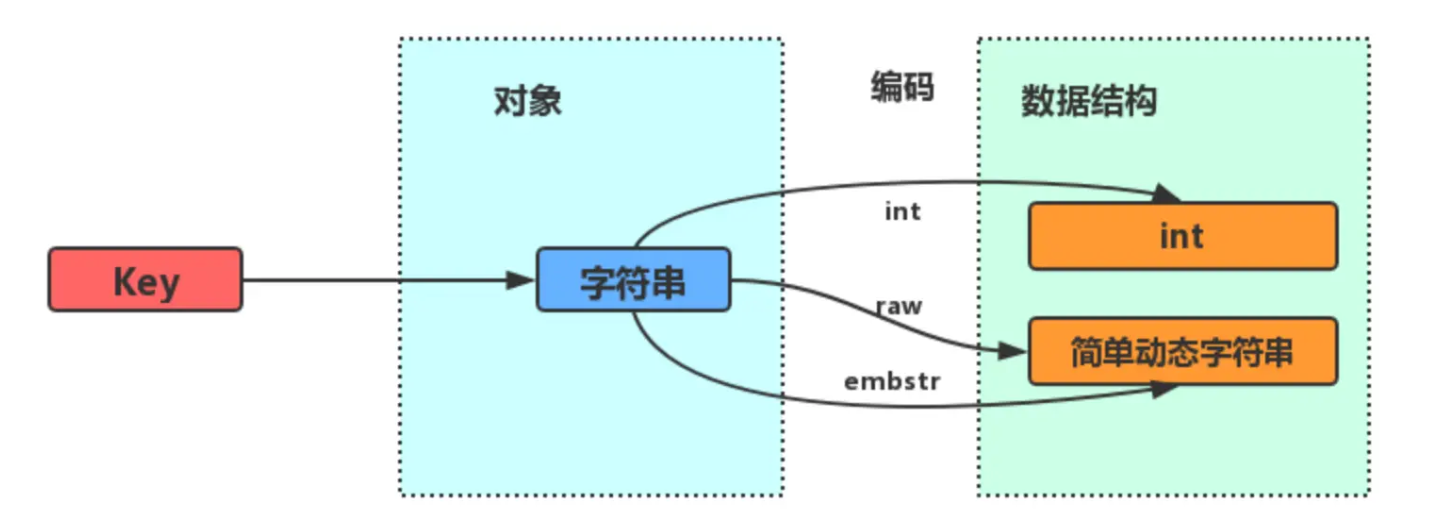
字符串对象的内部编码(encoding)有3种:int、raw和 embstr。
3. 使用场景
String 类型主要适用于简短的字符场景 ,其应用场景包括 缓存对象、常规计数、分布式锁、共享 session 信息等。
- 缓存: 存储临时数据,如用户会话、页面缓存。
- 计数器: 用于统计访问量、点赞数等,通过原子操作增加或减少。
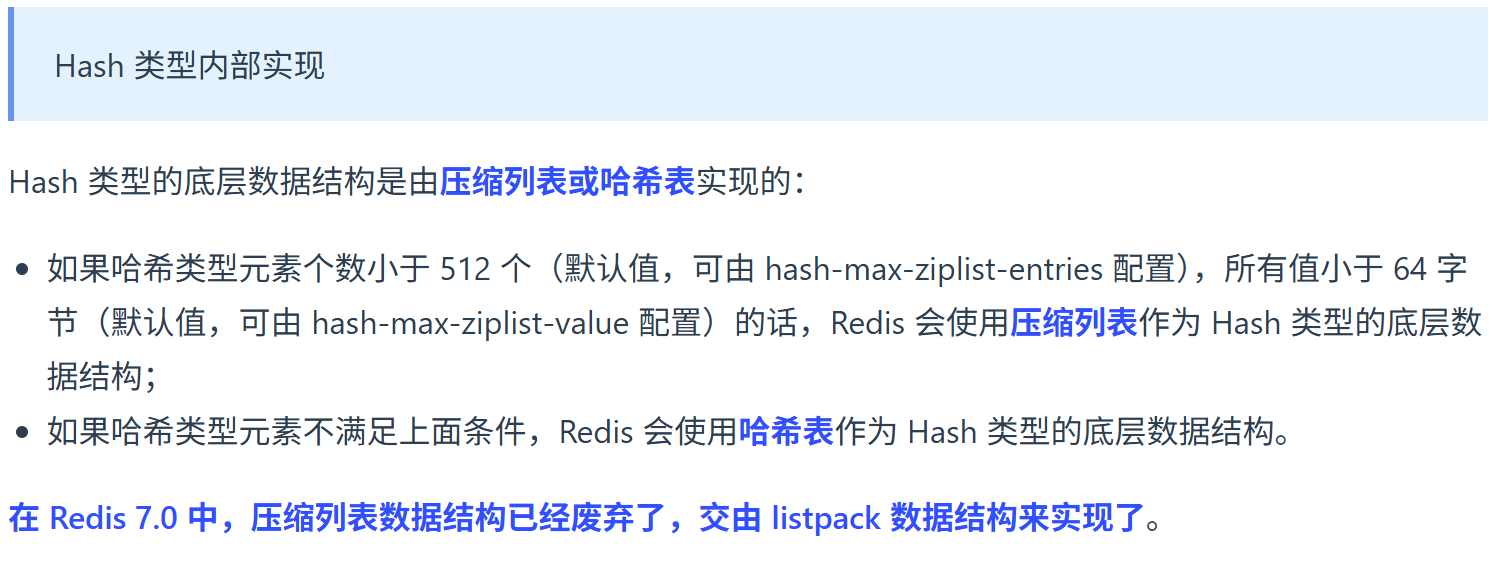
(二)Hash
1. 是什么?
哈希是一个键值对集合,适合存储对象的属性。Redis内部使用哈希表 实现,适合小规模数据。
Hash = 键值对集合(field → value)
2. 底层结构
Redis 会根据规模选择两种结构:
1)小数据量 → listpack(Redis 7.0 前是 ziplist)
触发条件(默认):
- field 和 value 都较小(长度 < 64 字节)
- 键值对数量 < 512
底层结构:listpack(以前是 ziplist)
📌 特点:
- 连续内存
- 节省空间
- 小 hash 性能很好
2)大数据量 → 哈希表(dict)
键值对数量变大后 Hash 会自动转为:
dict(hash table)哈希表
字典在 Redis 中使用:
- 数组 buckets
- 链地址法(链表)解决冲突
并且使用:
- 渐进式 rehash(分批迁移) ------ 避免一次性扩容导致卡顿
Hash 总结
| 数据量 | 底层结构 |
|---|---|
| 小 | listpack(旧 ziplist) |
| 大 | 哈希表 dict |
3. 使用场景
Hash 主要适用于存储、读取、修改用户、商品等属性。
其业务场景比如存储商品详情,即存储商品的各个属性,方便快速检索。
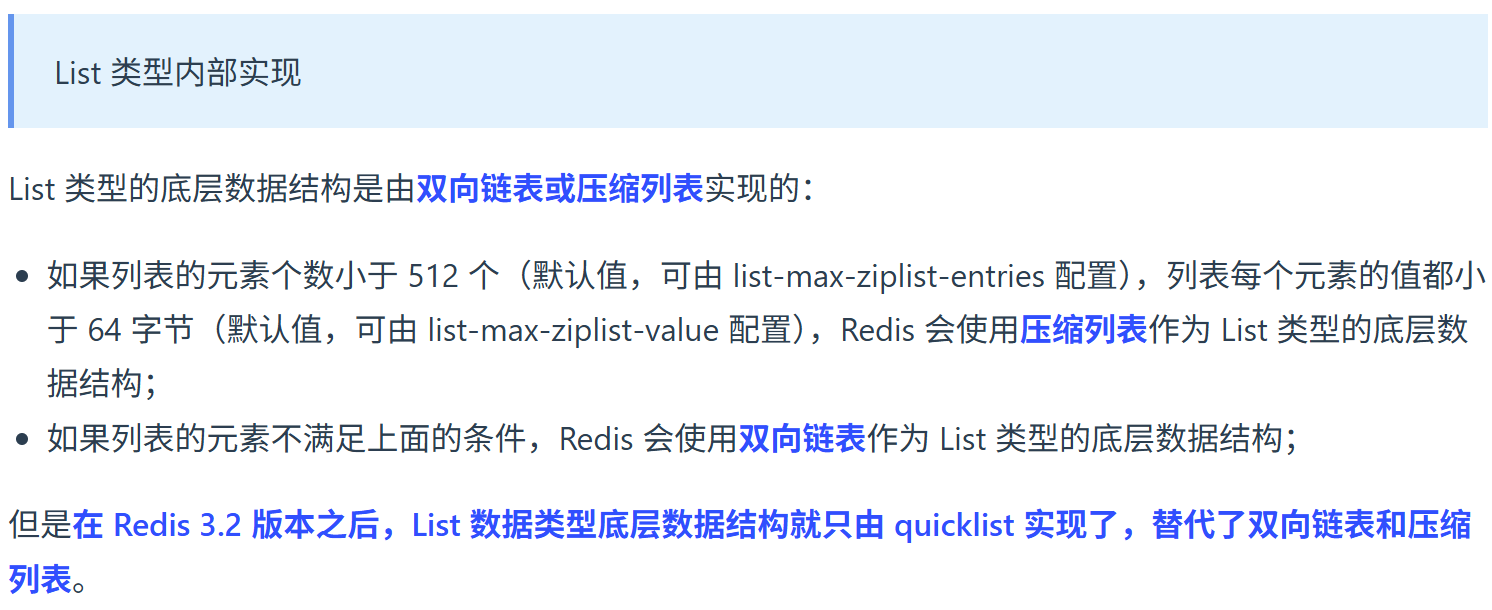
(三)List
1. 是什么
列表是有序的字符串集合,支持从两端推入和弹出元素。
2. 底层结构
一句话总结:
早期 List 用 ziplist + linkedlist 两种,但Redis 3.2 后,List 底层彻底统一为 quicklist
List 的底层实现跟 Redis 的版本有关,我们可以分为两阶段来讲:
1)Redis 3.2 之前(早期版本)
List 的底层可能是两种结构之一:
- 双向链表(linkedlist)
- 压缩列表(ziplist)
Redis 会根据++列表的"大小"++ 和++"元素长度"++自动选择:
- 当List 的 元素个数较少 ,并且 每个元素的字节长度较短 时,
➜ 使用 ziplist(压缩列表) ,优点是内存连续、比较省空间。 - 当 元素个数很多 或者 元素偏大 时,
➜ 使用 双向链表 ,优点是插入删除方便,但指针多、内存开销相对更大。
List 的元素个数 由
list-max-ziplist-entries配置,默认值是** 512** 个。List 的元素字节长度 由
list-max-ziplist-value配置,默认值是 64 字节。
2)Redis 3.2 之后(后期版本)
从 Redis 3.2 开始,List 的底层实现就不再用「双向链表 + 压缩列表」二选一了,而是**统一改成 quicklist **。
我们可以把 quicklist 理解为:"双向链表 + 压缩列表"的组合体。
也就是说:
- 外面是一条 双向链表
- 链表的每个节点里,不是存一个元素,而是存 一个压缩列表(ziplist)
这样就兼顾了两类优点:
- ✔ 节省内存 :
- 每个节点里用 ziplist 连着放很多元素,减少指针开销。
- ✔ 插入删除仍然高效 :
- 在链表层面插入/删除节点是 O(1),
- 在小的 ziplist 里移动元素成本也不高。
- ✔ 访问性能也不错 :
- 比纯链表更 cache-friendly(因为 ziplist 是连续内存)。
List 总结
| Redis 版本 | 底层结构 |
|---|---|
| 3.2 前 | ziplist 或 linkedlist |
| 3.2 以后 | quicklist(唯一实现) |
3. 使用场景
List 类型的应用场景有 消息队列、历史记录 等。
但是存在两个问题:
- 生产者需要自行实现全局唯一 ID;
- 不能以消费组形式消费数据。
- 消息队列:
- 用于简单任务调度、消息传递等场景
- 通过LPUSH 和 RPOP 操作实现生产者消费者模式
- 具体的有** 最新消息排行功能:**比如朋友圈的时间线
- 历史记录: 存储用户操作的历史记录,便于快速访问。
(四)Set
1. 是什么
集合(Set)是无序且不重复 的字符串集合**,使用哈希表**实现,支持快速查找和去重操作。
Set(集合)存储 member,保证唯一性。
2. 底层结构
集合的底层分为:intset(整数集合) 和 dict(哈希表)两种底层数据结构。
1)小整数集合 → intset
当:
- 所有成员都是整数
- 成员数量 <
set-max-intset-entries(默认 512)
则使用 ------ intset
intset 是一个连续内存数组,内部自动升级:
- 元素小 → 用 int16
- 更大 → 自动升级为 int32、int64
2)大数据量或非整数 → dict
只要出现:
- 非整数元素
- 元素过多
立即使用------ dict
📌 特点:
- 查找 O(1)
- 保证唯一性
Set 总结
| 情况 | 底层结构 |
|---|---|
| 全是整数且数量少 | intset |
| 有非整数 或 数据量大 | dict(哈希表) |
3. 使用场景
Set 类型的使用场景有 聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动。
- 标签系统: 存储用户的兴趣标签,避免重复。
- 唯一用户集合: 记录访问过某个页面的唯一用户,方便进行分析。
- 共同好友, 根据 tag 求交集。
- 好友推荐时,根据 tag 求交集,大于某给阈值就可以推荐。
(五)ZSet
1. 是什么
ZSet = Sorted Set(有序集合),每个元素由:
sql
member(成员) + score(分值)ZSet 是一组++按关联分数++有序排列的字符串集合,这里的分数(Score)是个抽象概念,任何指标都可以抽象为分数,以满足不同的场景。
ZSet 里面的字符串是如何排序的?

2. 底层结构
Redis 会根据数据量自动选择底层结构:
1)小数据量 → listpack(Redis 7.0 之前叫 ziplist)
触发条件(默认):
- 元素数量 < 128
- 成员字符串长度 < 64 bytes
满足以上 → 使用 listpack。
Redis 7.0 中,压缩列表 ziplist 已经废弃,改为 listpack。
其结构如下:

📌 特点:
- 紧凑结构(连续内存),节省空间
- 插入、遍历比较快
- 适合小 ZSet
2)大数据量 → Skiplist + HashTable
不满足条件 → 使用 skiplist + hashtable 双结构
📌 为什么要两个结构?
| 结构 | 作用 |
|---|---|
| Skiplist(跳表) | 按 score 排序,支持范围查询 O(logN) |
| Hashtable(字典) | 根据 member 快速查 score,时间复杂度 O(1) |
▶ 跳表负责 "按 score 排序"
▶ Hash 表负责 "按 member 查找"
两者互补。
为什么要双结构:skiplist + hash?
ZSet 的操作有两类:
1)按 member 查找
如:
plsql
ZSCORE key member
ZREM key member→ 需要 O(1) 哈希表查找。
2)按 score 排序或范围查询
如:
plsql
ZRANGE key 0 -1
ZRANGEBYSCORE key 1 100
ZREVRANGE key ...→ 跳表对范围查询、排序非常友好,能做到 O(logN)。
⭐ 只有其中一种结构无法同时做到高性能
❌ 单用 hashtable
- 无序
- 不支持按 score 排序和范围查询
❌ 单用 skiplist
- 查找 member 必须从头到尾扫描,O(N)
→ 因此必须:跳表负责排序,哈希表负责快速查找
总结表
| Redis 版本 | 小数据结构 | 大数据结构 |
|---|---|---|
| Redis 3.2 以前 | ziplist | skiplist + hashtable |
| Redis 3.2~6.x | ziplist(更优化) | skiplist + hashtable |
| Redis 7.0+ | listpack(ziplist 替代者) | skiplist + hashtable |
3. 使用场景
Zset 类型的使用场景有 排序场景,比如排行榜、电话和姓名排序等。
- 排行榜: 存储用户分数,实现实时排行榜,比如游戏排行榜。
- 任务调度: 根据任务的优先级进行排序,方便调度执行。
| 结构类型 | 结构存储的值 | 结构的读写能力 |
|---|---|---|
| String 字符串 | 可以是字符串、整数或浮点数 | 对整个字符串或字符串的一部分进行操作; 对整数或浮点数进行自增或自减操作; |
| Hash 哈希表 | 包含键值对的无序散列表 | 包含方法有添加、获取、删除单个元素 |
| List 列表 | 一个链表,链表上的每个节点都包含一个字符串 | 对链表的两端进行 push 和 pop 操作,读取单个或多个元素;根据值查找或删除元素; |
| Set 集合 | 包含字符串的无序集合 | 字符串的集合,包含基础的方法有查看是否存在添加、获取、删除;还包含计算交集、并集、差集等 |
| Zset 有序集合 | 和散列一样,用于存储键值对 | 字符串成员与浮点数分数之间的有序映射; 元素的排列顺序由分数的大小决定; 包含方法有添加、获取、删除单个元素以及根据分值范围或成员来获取元素 |
(六)BitMap
- BitMap(2.2 版新增)
- 常用于二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等。
(七)HyperLogLog
- HyperLogLog(2.8 版新增)
- 常用于海量数据基数统计的场景,比如百万级网页 UV 计数等。
(八)GEO
- GEO(3.2 版新增)
- 常用于存储地理位置信息的场景,比如滴滴叫车。
(九)Stream
- Stream(5.0 版新增)
- 常见的应用场景有:消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据。
相关面试题
Redis 的数据类型有哪些?
提示:Redis 有 5 种基本类型 和 4 种高级类型,面试能回答出五种常见的基本类型就可以,其他新的数据类型则需学习。
Redis 常见的数据结构有五种:String(字符串)、List(列表)、Hash、Set(集合)、Zset(有序集合)。
Redis 有哪些底层数据结构?
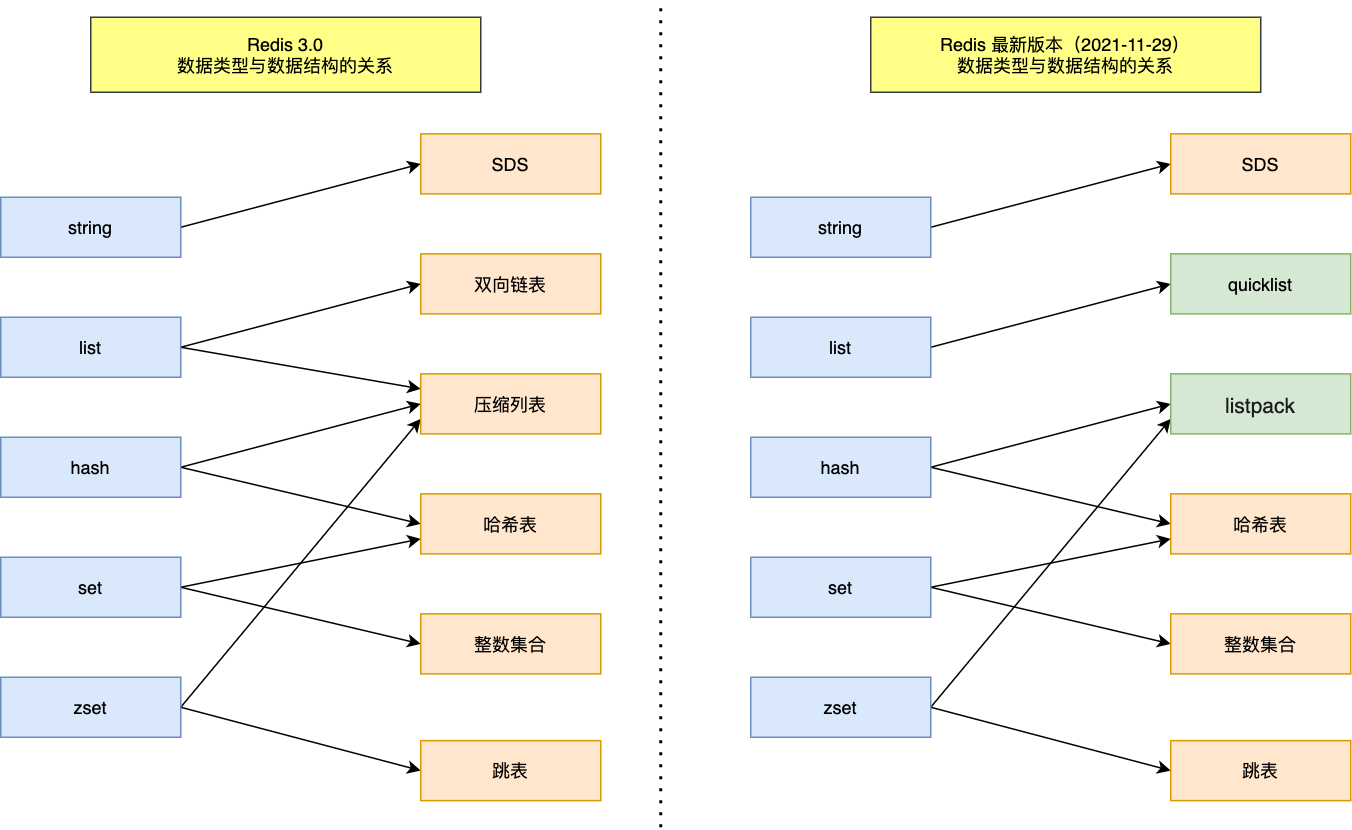
Redis 主要数据结构的底层实现如下:
- String 使用 SDS 实现,是动态可扩展的二进制安全字符串。
- Hash 小数据时使用 listpack(旧版本 ziplist),大时使用哈希表 dict。
- List 在 Redis 3.2 后统一由 quicklist 实现,即用双向链表串联多个 listpack 节点。
- Set 小整数集合用 intset,否则使用 dict。
- ZSet 小集合用 listpack,大集合用 skiplist + dict 双结构组合,以同时支持按 score 排序和按 member 查找。
String 的底层实现是什么?
早期:list = ziplist 或 linkedlist,根据元素个数和大小自动选择;
Redis 3.2 之后:List 底层统一由 quicklist 实现 , quicklist =「双向链表 +
压缩列表」的混合结构,用链表串起多个小的压缩列表,在内存占用与操作性能之间做了折中。
参考:
Hash 的底层实现是什么?
参考:
List 的底层实现是什么?
参考:
Set 的底层实现是什么?
参考:

ZSet 的底层实现是什么?
ZSet 底层结构取决于数据量大小。
- 当成员数量较少(默认小于 128)且成员较短(小于 64 字节)时,ZSet 底层采用 listpack(旧版本是 ziplist),节省内存。
- 当数据量较大时,ZSet 使用 skiplist + hashtable 的双结构 : 哈希表根据 member 做 O(1) 查找;跳表按 score 排序并支持范围查询 O(logN)。 Redis 7.0 后 ziplist 被废弃,统一由 listpack
实现。这样的双结构可以同时支持按 score 排序和按 member 查找。
参考: