目录
- [1527. 患某种疾病的患者](#1527. 患某种疾病的患者)
- [54. 螺旋矩阵](#54. 螺旋矩阵)
- [114. 二叉树展开为链表](#114. 二叉树展开为链表)
1527. 患某种疾病的患者
题目链接
表
- 表
Patients的字段为patient_id、patient_name和conditions。
要求
查询患有 I 类糖尿病的患者 ID (patient_id)、患者姓名(patient_name)以及其患有的所有疾病代码(conditions)。I 类糖尿病的代码总是包含前缀 DIAB1 。
按 任意顺序 返回结果表。
知识点
like:对字符串做限制,通常与%搭配使用,%表示不限字符,并且不限字符的个数。例如select * from Users where name like '张%',假设Users表中有name为张三丰、张四、老张、李四的数据,那么这条语句返回的是name为张三丰、张四的数据。
思路
由于 I 类糖尿病的代码总是包含前缀 DIAB1,并且 'conditions' (疾病)包含 0 个或以上的疾病代码,以 空格 分隔,所以在查询时要将conditions限制到DIAB1%(conditions第一个单词的前缀为DIAB1)或% DIAB1%(DIAB1不是conditions的第一个单词,但有一个其他单词的前缀为DIAB1)中。
代码
sql
select
patient_id,
patient_name,
conditions
from
Patients
where
conditions like 'DIAB1%'
or
conditions like '% DIAB1%'54. 螺旋矩阵
题目链接
标签
数组 矩阵 模拟
思路
按照顺时针螺旋顺序 遍历矩阵很像深度优先搜索 ,都是以一个方向走到头,然后再探测别的方向 。所以本题可以采用深度优先搜索的思想来解决。
先做好预备工作:使用一个boolean[][] vis来存储各个元素是否被遍历过,并且使用一个int[][] dir = {``{0, 1}, {1, 0}, {0, -1}, {-1, 0}}来作方向数组,这个方向数组的方向依次为向右、向下、向左、向上 ,也就是题目中的顺时针螺旋顺序,如果不是这个顺序,则会出问题。
然后再进行遍历:本题的搜索需要在传入 矩阵 和 当前元素的坐标 外,传入当前遍历的方向 ,然后 标记遍历过当前元素 并 将其放入结果链表,接着依次按照向右、向下、向左、向上 的方向进行深搜,搜索的前提是下一个元素在矩阵中(对下一个元素的索引做检查),并且下一个元素没有遍历过(对下一个元素的vis做检查)。当搜索到最后一个元素时,它无论向哪个方向都无法再进行搜索(因为此时vis中所有元素都是true,也就是说所有元素已经被遍历过了),所有的递归就此终结。
最后返回结果链表即可。
代码
java
class Solution {
public List<Integer> spiralOrder(int[][] matrix) {
if (matrix == null || matrix.length == 0 || matrix[0].length == 0) { // 如果矩阵为空
return new ArrayList<>(); // 则返回空集合
}
int row = matrix.length, col = matrix[0].length;
res = new ArrayList<>(row * col); // 初始化结果链表大小为row * col,避免链表扩容影响性能
vis = new boolean[row][col]; // 初始化判断数组
dfs(matrix, 0, 0, 0); // 从0行0列开始向右遍历
return res;
}
// 从r行c列开始 沿d方向 遍历
private void dfs(int[][] matrix, int r, int c, int d) {
vis[r][c] = true; // 记录遍历过本元素
res.add(matrix[r][c]); // 将当前元素加入结果链表
for (int k = 0; k < 4; k++) { // 分别向4个方向探测
int kd = (d + k) % 4; // 获取方向数组的索引
int kr = r + dir[kd][0], kc = c + dir[kd][1]; // 获取 沿kd方向前进的 下一个元素的 索引
if (!(kr >= 0 && kr < matrix.length
&& kc >= 0 && kc < matrix[0].length) // 如果这个元素不在矩阵中
|| vis[kr][kc]) { // 或者这个元素被遍历过了
continue; // 则跳过这个元素
}
dfs(matrix, kr, kc, kd); // 从这个元素开始 沿kd方向 遍历
}
}
private List<Integer> res; // 结果链表
private boolean[][] vis; // 判断某个元素是否已经被遍历过了
private int[][] dir = {{0, 1}, {1, 0}, {0, -1}, {-1, 0}}; // 方向数组,分别为向右、向下、向左、向上
}114. 二叉树展开为链表
题目链接
标签
栈 树 深度优先搜索 链表 二叉树
前序遍历
思路
本题的简单思路十分简单,使用前序遍历 将二叉树中所有的节点存入链表,然后再将链表中的所有节点按顺序 调整指向:让前一个节点的左指针指向null,右指针指向当前节点,从而形成链表的结构。
代码
java
class Solution {
public void flatten(TreeNode root) {
if (root == null) {
return;
}
List<TreeNode> list = new ArrayList<>();
preOrder(root, list);
for (int i = 1; i < list.size(); i++) {
TreeNode prev = list.get(i - 1); // 获取前一个节点
TreeNode curr = list.get(i); // 获取当前节点
prev.left = null; // 让前一个节点的左子节点指向null
prev.right = curr; // 将当前节点 放到 前一个节点的右子节点处
}
}
// 前序遍历二叉树,将节点按照前序保存到list中
private void preOrder(TreeNode curr, List<TreeNode> list) {
if (curr == null) {
return;
}
list.add(curr);
preOrder(curr.left, list);
preOrder(curr.right, list);
}
}前驱
思路
什么叫做前驱节点?前驱节点指的是以中序遍历 遍历二叉树时,某一个节点的前一个节点(前驱节点是当前节点左子树 中的一路往右子节点遍历 的最终 节点)。在二叉搜索树,前驱节点是小于当前节点值的最大节点。
为什么要讲前驱节点?因为对于一个节点来说,前序遍历总是先处理当前值,然后再遍历左子节点,最后是右子节点。从而在前序遍历中,前驱节点的下一个节点就是当前节点的右子节点。
所以只需要在当前节点有左子节点时,将左子节点 到前驱节点 这段二叉树插入到当前节点 与右子节点之间,然后更新当前节点为插入之后的右子节点即可。对于没有左子节点的节点,无需理会,直接更新当前节点为下一个右子节点。
例如对于以下二叉树:

先寻找节点1的前驱节点,发现其前驱节点为节点4,将节点4与节点5建立连接,并将节点2放到节点5原本的位置上,然后当前节点更新到节点2,如下图所示:
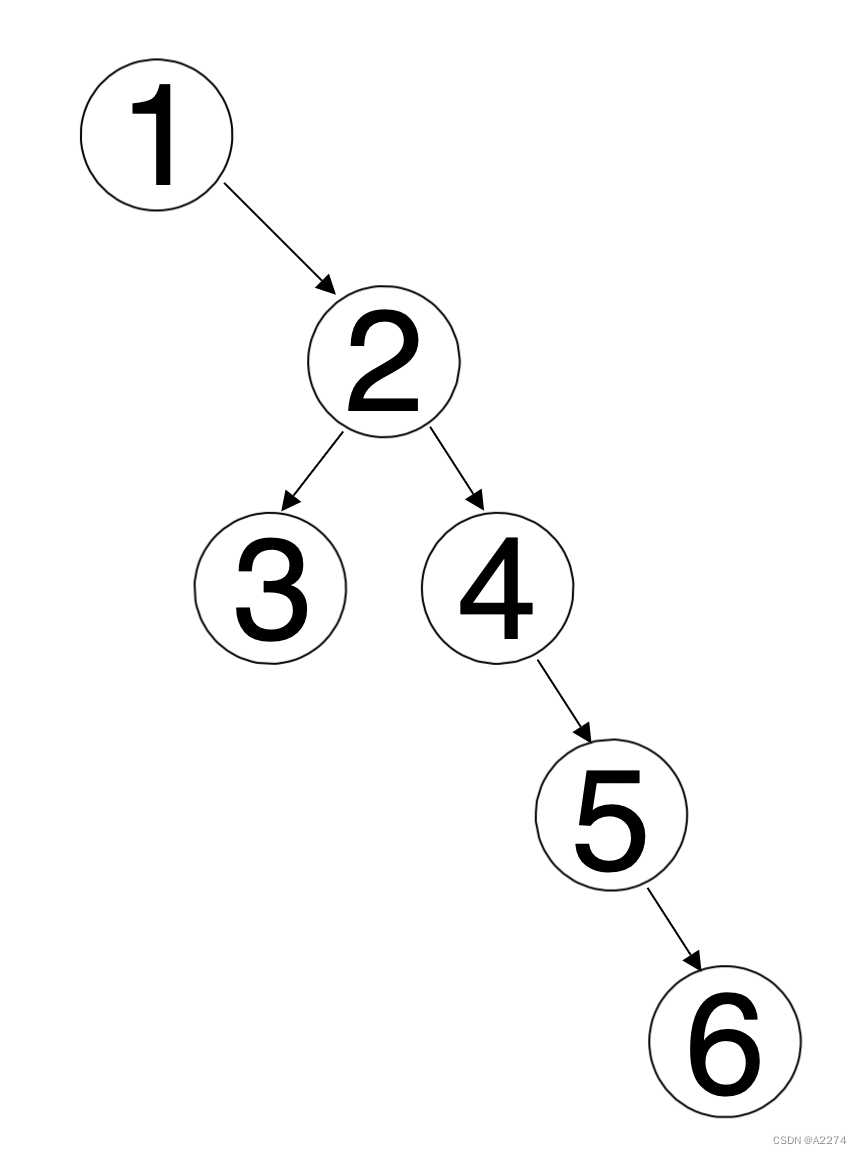
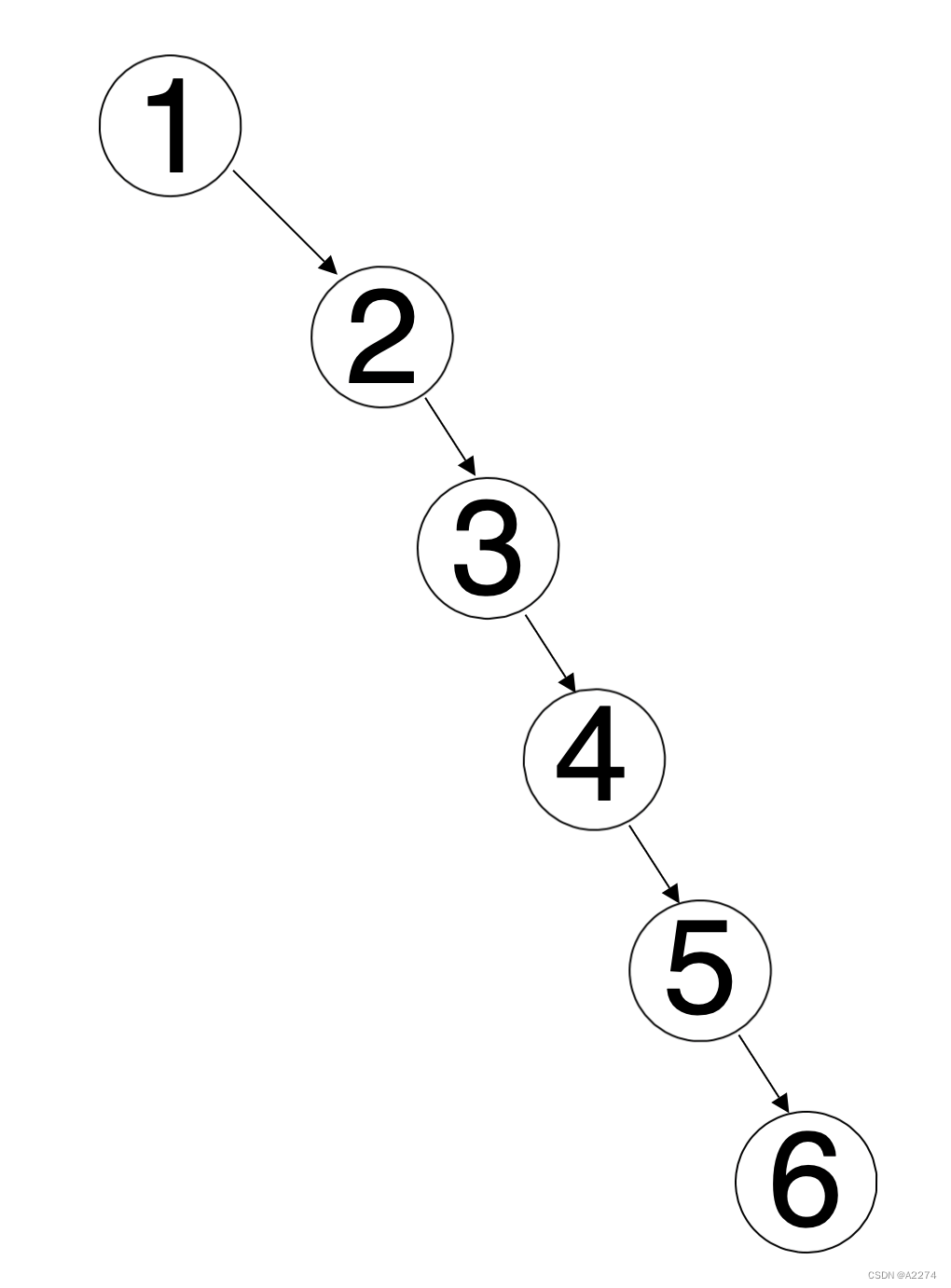
接着寻找节点2的前驱节点,发现其前驱节点为节点3,将节点3与节点4建立联系,并将节点3放到节点4原本的位置上,接着就不存在有左子节点的节点了,如下图所示:
代码
java
class Solution {
public void flatten(TreeNode root) {
TreeNode curr = root;
while (curr != null) {
if (curr.left != null) { // 如果左子节点不为空,则进行操作
TreeNode next = curr.left; // 先保存左子节点
TreeNode predecessor = predecessor(curr); // 获取当前节点的前驱节点
predecessor.right = curr.right; // 让前驱节点的右指针 指向 当前节点的右子节点
curr.left = null; // 让当前节点的左指针 指向 null
curr.right = next; // 让当前节点的右指针 指向 左子节点
}
curr = curr.right; // 更新当前节点
}
}
// 寻找curr的前驱节点
private TreeNode predecessor(TreeNode curr) {
TreeNode pre = curr.left; // 先获取当前节点的左子节点
while (pre.right != null) {
pre = pre.right; // 一路往右子节点方向遍历
}
return pre; // 找到最终节点
}
}