嗨,小伙伴们。又到喜闻乐见的Python 数据分析王牌库 Pandas 的学习时间。按照数据分析处理过程,这次轮到了新增维度的部分了。
老样子,我们先来回忆一下,一个完整数据分析的过程,包含哪些部分内容。
其中,Pandas 的基础信息导入、数据导入和数据整理、数据探索和清洗已经在前几篇文章里聊过。
感兴趣的小伙伴,可以点击链接跳转观看。
像学Excel 一样学 Pandas系列-数据探索和数据清洗

新增维度 部分,是在完成数据探索,获取数据的现状,并且对脏数据完成清洗工作后的后道工序。而且,这部分非常的关键,很多分析场景下,需要做的挖掘分析,情况归类,都需要在维度新增里完成。

这个时候,Pandas 要开始变形了。为什么增加维度这么重要。
增加数据维度,是最终分析报告能获取到的分析颗粒度的有力支持。新增数据维度可以显著提升分析的深度和广度。

以我所在的汽车行业举例。
通过添加车辆特征维度(如发动机类型、驱动方式、燃油效率),可以更全面地了解具备哪些特性的车型更受消费者欢迎。结合销售数据和客户反馈维度,可以精确分析哪些车型的特定问题(如燃油效率低、维修率高)影响了客户满意度。
合并增加利用车辆使用数据(如行驶里程、维修记录)和客户人口统计信息,可以深入洞察车辆的长期性能和客户的忠诚度。
按例,为了方便后续的演示,同样创建一个虚拟的Pandas DataFrame来演示维度新增的过程。这个DataFrame,包括车型、销售日期、销售数量、客户年龄和客户收入等字段。
import Pandas as pd
data = { '车型': ['轿车', 'SUV', '轿车', 'SUV', 'MPV'], '销售日期': pd.date_range(start='2024-01-01', periods=5, freq='D'), '销售数量': [10, 15, 12, 20, 8], '客户年龄': [34, 29, 45, 31, 41], '客户收入': [5000, 7000, 6000, 8000, 5500]}
df = pd.DataFrame(data)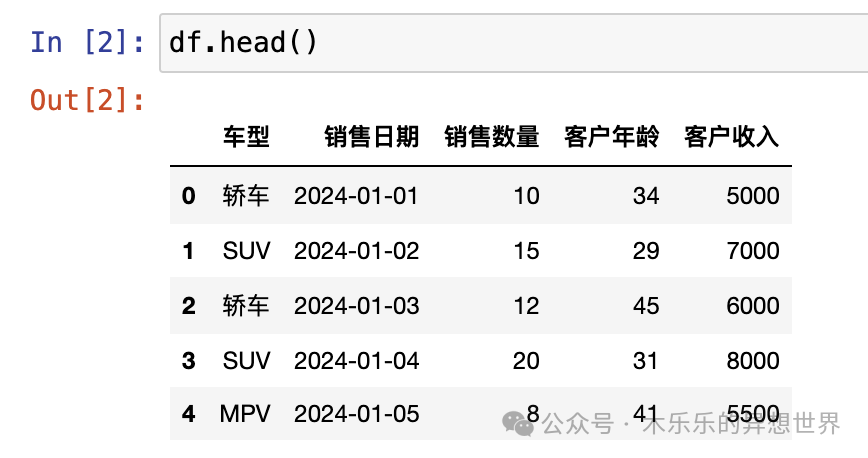
01 数据分箱映射
为啥我这么爱 pandas。每次做车型价格带分析,最烦躁的就是,今天 5 万一个档做价格带切割,明天还得弹性切割。每次做分组映射,分分钟烦死个人。在 Pandas 这里,一个函数就搞定。
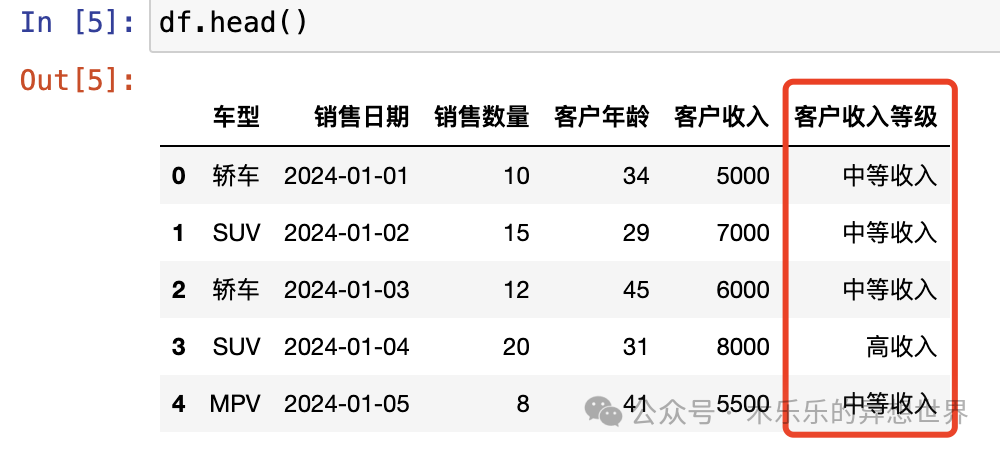
假定,我们要根据客户收入将客户分为不同的等级。你只需要在 imcome_map 里配置一个映射字典,描述清楚"低收入","中等收入","高收入"人群的收入加个分层。
然后,使用 pd.cut 函数,配置分区的边界值 bins 和每一个分组对应的 labels,就可以完成映射了。
下次老板再找你调收入等级,分分钟完成。
#income_map = {# '低收入': [0, 3000],# '中等收入': (3000, 7000],# '高收入': (7000, np.inf)#} #备注给人类看的,区分每一个分层的收入范围。
df['客户收入等级'] = pd.cut(df['客户收入'], bins=[0, 3000, 7000, np.inf], labels=['低收入', '中等收入', '高收入'])看看,是不是超容易,是不是超简单!
02 多字段综合规则研判维度增加
老板拿到分箱结果后,说不行,我们还得综合客户的年龄来判断这个人的收入水平。那么,基于客户年龄和收入,我们创建一个新列来标识是否为潜在的高端客户。这就涉及了多字段综合规则研判维度增加的问题了。
df['潜在高端客户'] = df.apply(lambda row: '是' if row['客户年龄'] > 35 and row['客户收入'] > 5000 else '否', axis=1)这里用一个 df.apply 函数,结合 lambda 函数,快速锁定年龄小于 35 岁,收入大于 5000 的用户,并且判断未潜在高端用户。
年纪轻轻就高收入,确实潜力不小,哈哈哈。

03 维度表映射增加
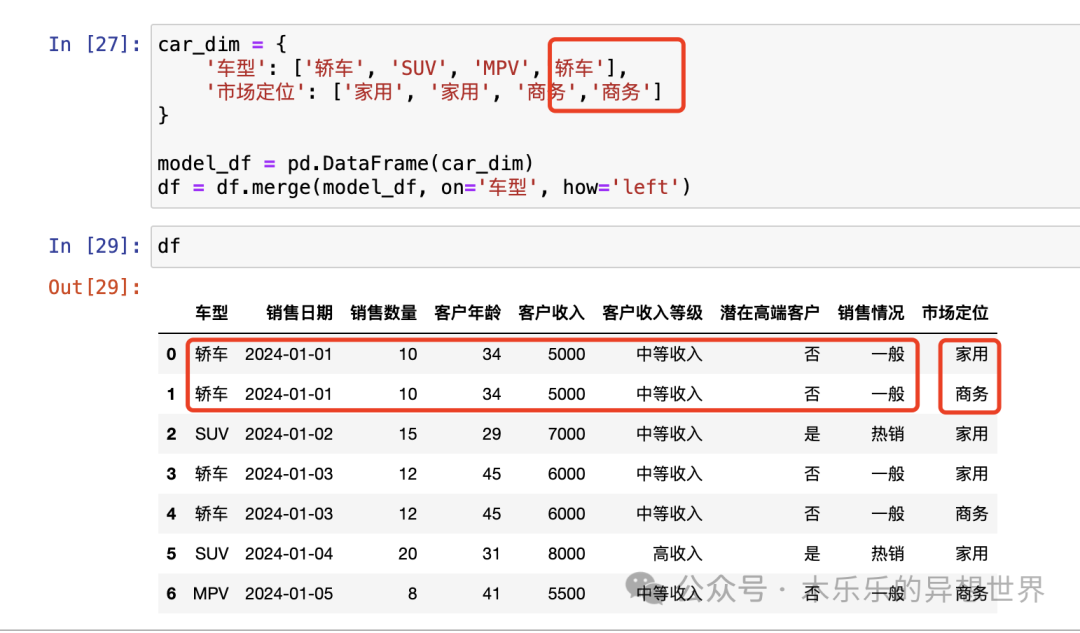
假设我们有一个车型维度表,包含车型对应的市场定位信息。这里可以通过 pd.merge,数据合并映射的方式,将 car_dim 里的维度添加如 df 内,形成一个新的列,这个列名就是"市场定位"。
car_dim = { '车型': ['轿车', 'SUV', 'MPV'], '市场定位': ['家用', '家用', '商务']}
model_df = pd.DataFrame(car_dim)df = df.merge(model_df, on='车型', how='left')
这里有一个地方需要注意一下,你的车型和市场定位必须是一一映射匹配的关系。如果存在一对多的情况,使用 pdf.merge 就会分裂出新的数据行。
我们来看一个错误案例:我在 car_dim 里错误的将轿车的市场定位配置了两个类型,包含"家用"和"商务"。生成的结果数据里,每种情况,都分裂多出来的一条数据。这个,需要认真检查映射表字段的内容,是否严格遵守一一对应关系。
好啦,今天用超级简单的数据进行了数据维度新增的说明和演示。
如果小伙伴有其他想深入了解的内容,欢迎留言、关注、点赞、评论转发。您的每一份互动,都是我肝下去的动力。