目录
[10.1 Spark概述](#10.1 Spark概述)
[10.1.1 Spark简介](#10.1.1 Spark简介)
[10.1.2 Scala简介](#10.1.2 Scala简介)
[10.1.3 Spark与Hadoop的比较](#10.1.3 Spark与Hadoop的比较)
[10.2 Spark生态系统](#10.2 Spark生态系统)
[Spark Core:](#Spark Core:)
[Spark SQL:](#Spark SQL:)
[Spark Streaming:](#Spark Streaming:)
10.1Spark概述
10.1.1 Spark简介
Spark 最初由美国加州伯克利大学( UCBerkeley )的 AMP 实验室于 2009 年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析 应用程序 。
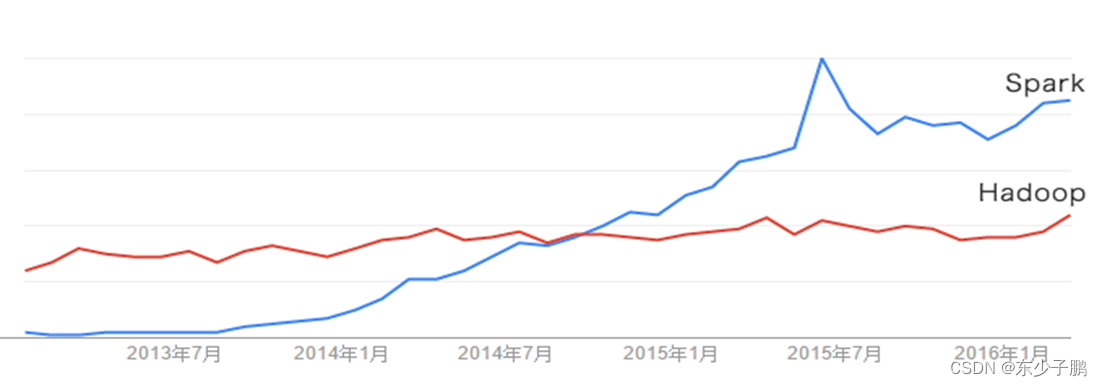
2013 年 Spark 加入 Apache 孵化器项目后发展迅猛,如今已成为 Apache 软件基金会最重要的三大分布式计算系统开源项目之一( Hadoop 、 Spark 、 Storm ) 。
Spark 在 2014 年打破了 Hadoop 保持的基准排序纪录
Spark/206 个节点 /23 分钟 /100TB 数据
Hadoop/2000 个节点 /72 分钟 /100TB 数据
Spark 用十分之一的计算资源,获得了比 Hadoop 快 3 倍的速度
Spark具有如下几个主要特点:
通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件
运行模式多样:可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源
通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件
运行模式多样:可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源
Spark如今已吸引了国内外各大公司的注意,如腾讯、淘宝、百度、亚马逊等公司均不同程度地使用了Spark来构建大数据分析应用,并应用到实际的生产环境中。
10.1.2 Scala简介

Scala是Spark的主要编程语言,但Spark还支持Java、Python、R作为编程语言。Scala的优势是提供了REPL(Read-Eval-Print Loop,交互式解释器),可在Spark Shell中进行交互式编程,提高程序开发效率。
10.1.3 Spark与Hadoop的比较



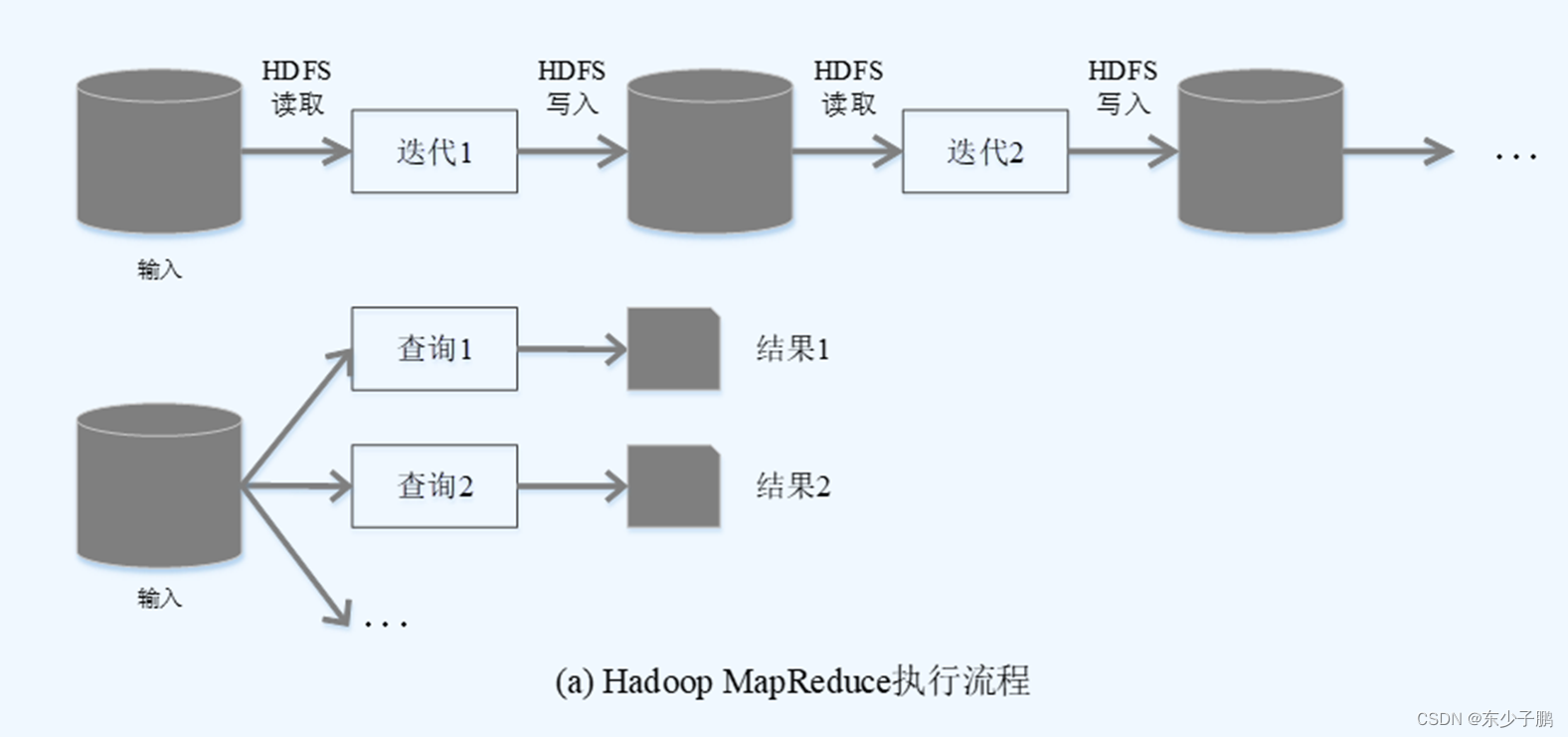
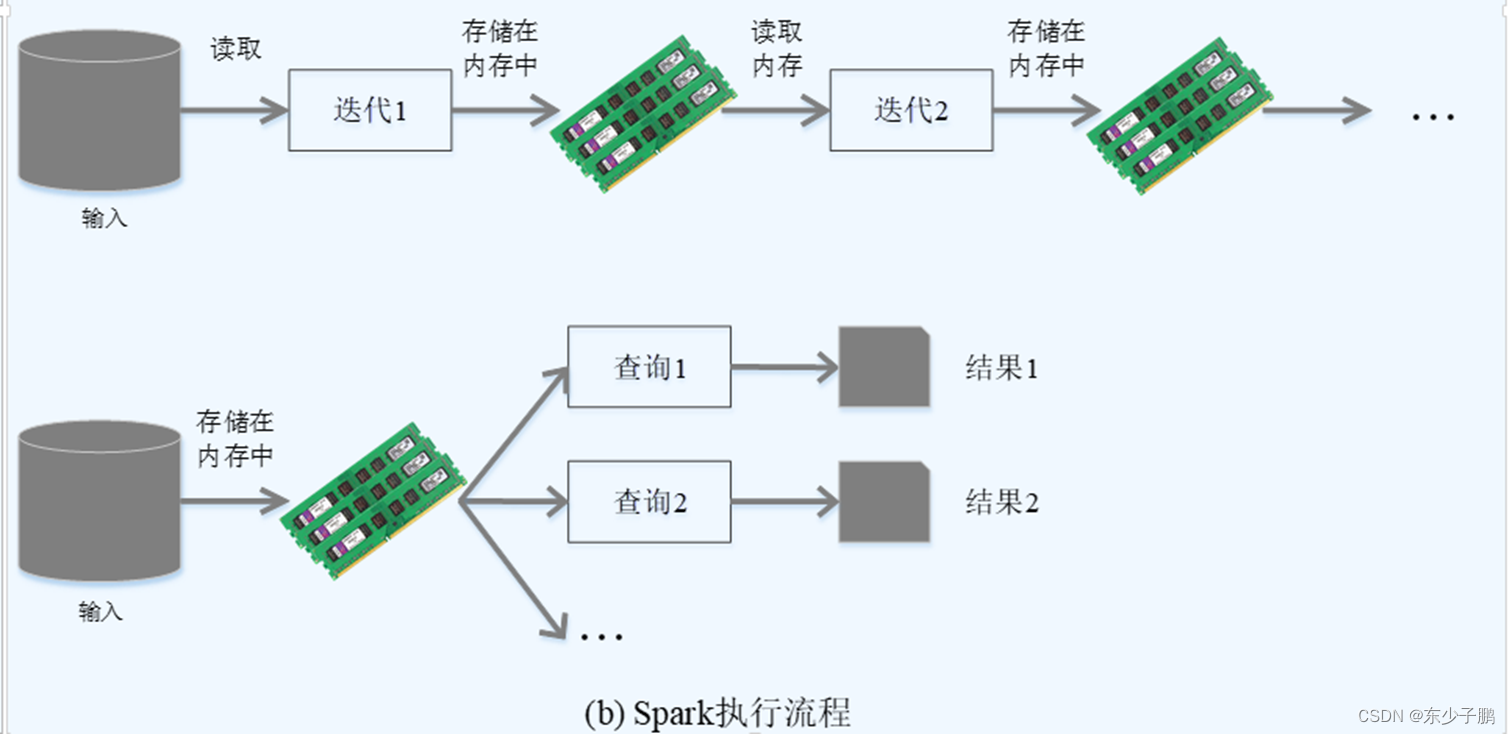
使用 Hadoop 进行迭代计算非常耗资源
Spark 将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结果作运算,避免了从磁盘中频繁读取 数据
Hadoop 需要不少相对编写底层的代码,不够高效。相对而言, Spark 提供了多种高层次、简洁的 API ,通常情况下,相同功能的应用程序, Hadoop 的代码量比 Spark 多 2~5 倍。
Spark提供了实时交互式编程反馈,可以方便地验证、调整算法
尽管 Spark 比 Hadoop 具有巨大优势,但 Spark 不能完全取代 Hadoop , Spark主要替代Hadoop中的MapReduce计算模型。
Hadoop 可以使用廉价的、异构的机器做分布式存储与计算,但是 Spark 对硬件(内存、 CPU 等)的要求高一些。
10.2Spark生态系统
在实际应用中,大数据处理主要包括以下三个类型:
• 复杂 的批量数据处理:通常时间跨度在数十分钟到数小时之间
• 基于历史数据的交互式查询:通常时间跨度在数十秒到数分钟之间
• 基于实时数据流的数据处理:通常时间跨度在数百毫秒到数秒 之间

这样做难免会带来一些问题:
不同场景之间输入输出数据无法做到无缝共享,通常需要进行数据格式的转换
不同的软件 需要 不同开发 和维护团队,带来了较高的使用成本
比较难以对同一个集群中的各个系统进行 统一资源协调 和 分配
Spark 的设计遵循"一个软件栈满足不同应用场景"的理念,逐渐形成了一套完整的 生态系统 , 既 能够提供内存计算框架,也可以支持 SQL 即席查询、实时流式计算、机器学习和图计算 等 。
Spark 可以部署在资源管理器 YARN 之上,提供一站式的大数据解决 方案 , 因此,Spark所提供的生态系统足以应对上述三种场景,即同时支持批处理、交互式查询和流数据处理
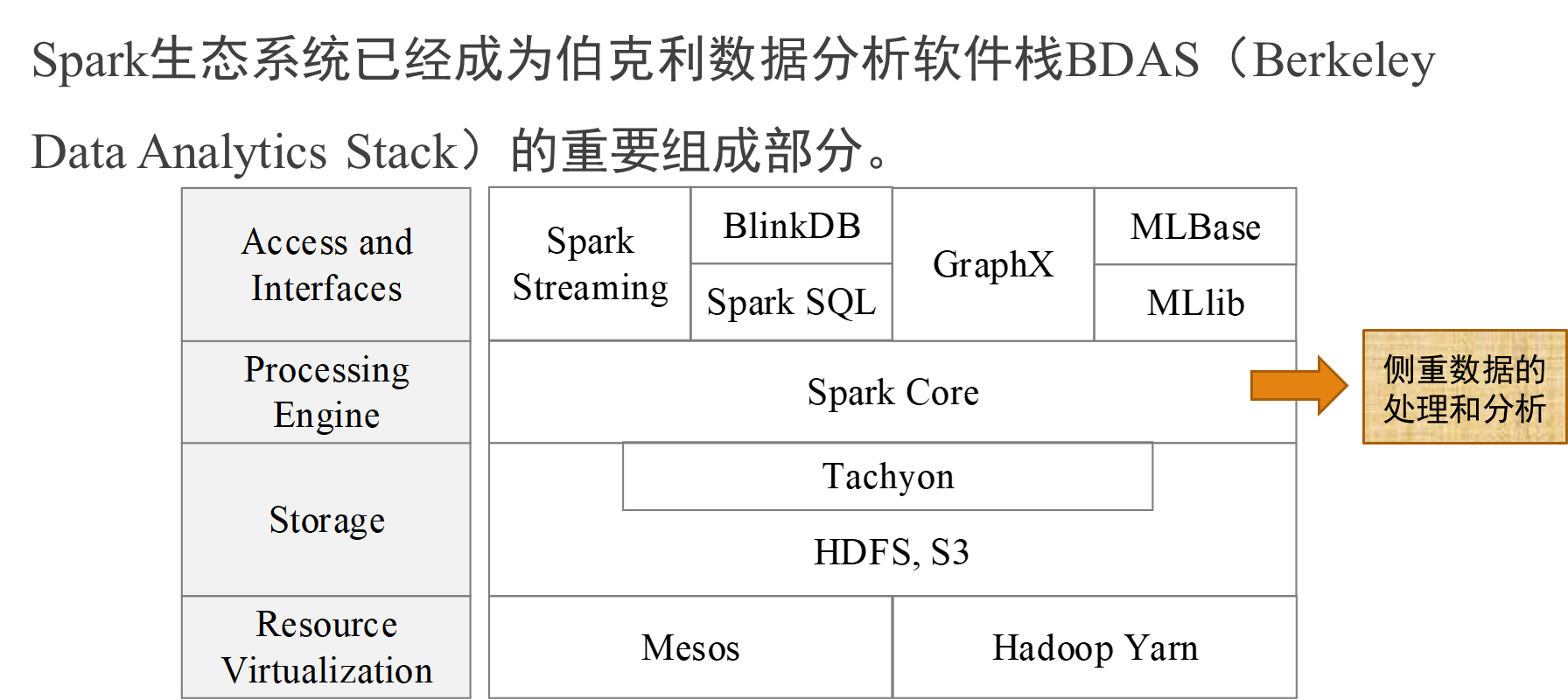

Spark Core:
Spark Core :实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。 Spark Core 中还包含了对弹性分布式数据集 (Resilient Distributed DataSet ,简称 RDD) 的 API 定义。
Spark SQL:
Spark SQL : Spark SQL 允许开发人员直接处理 RDD ,同时也可查询 Hive 、 HBase 等外部数据源。 Spark SQL 的一个重要特点是其能够统一处理关系表和 RDD ,使得开发人员可以轻松地使用 SQL 命令进行查询,并进行更复杂的数据分析。
Spark Streaming:
Spark Streaming : Spark Streaming 支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流式计算分解成一系列短小的批处理作业。 Spark Streaming 支持多种数据输入源,如 Kafka 、 Flume 和 TCP 套接字等;
MLlib(机器学习):
MLlib (机器学习): MLlib 提供了常用机器学习算法的实现,包括聚类、分类、回归、协同过滤等,降低了机器学习的门槛,开发人员只要具备一定的理论知识就能进行机器学习的工作;
GraphX(图计算):
GraphX (图计算): GraphX 是 Spark 中用于图计算的 API ,可认为是 Pregel 在 Spark 上的重写及优化, Graphx 性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。