分解+降维+预测!多重创新!直接写核心!EMD-KPCA-Transformer多变量时间序列光伏功率预测
目录
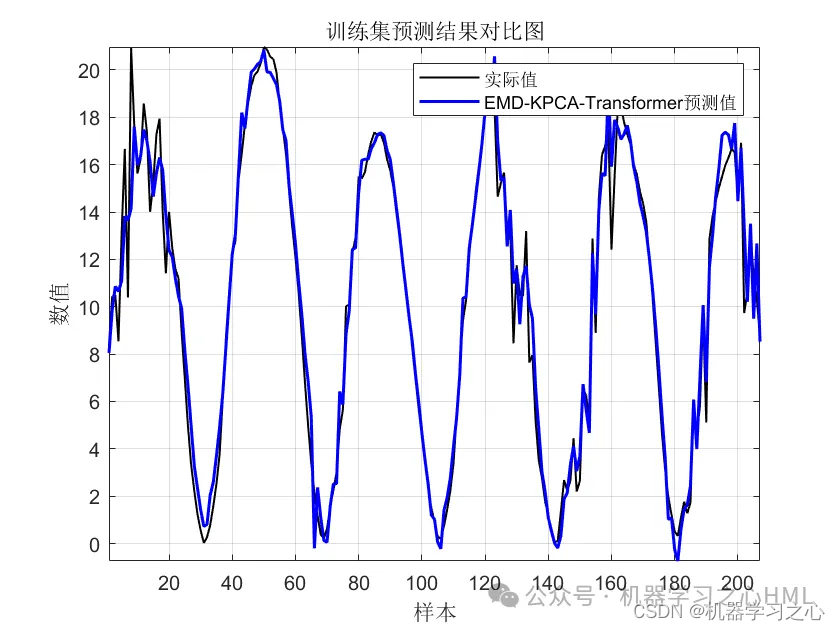
效果一览
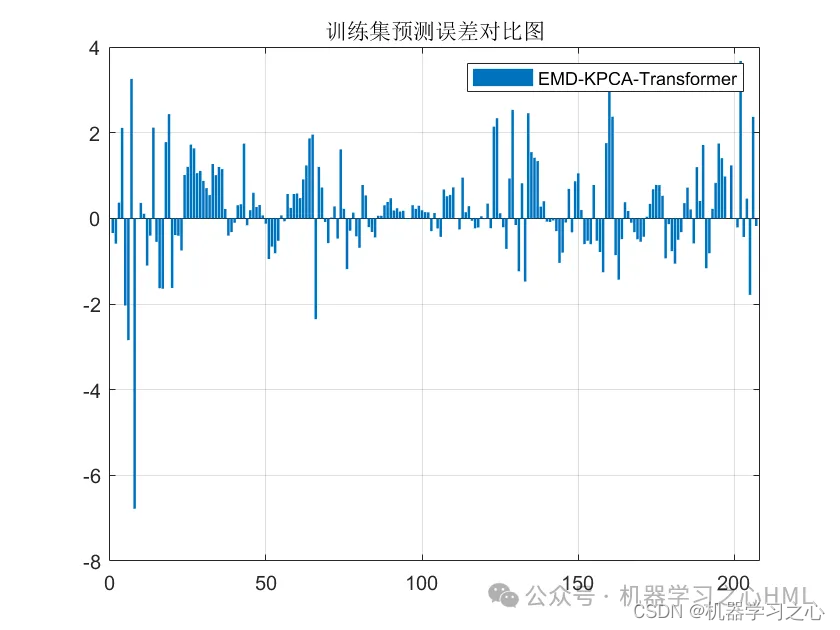
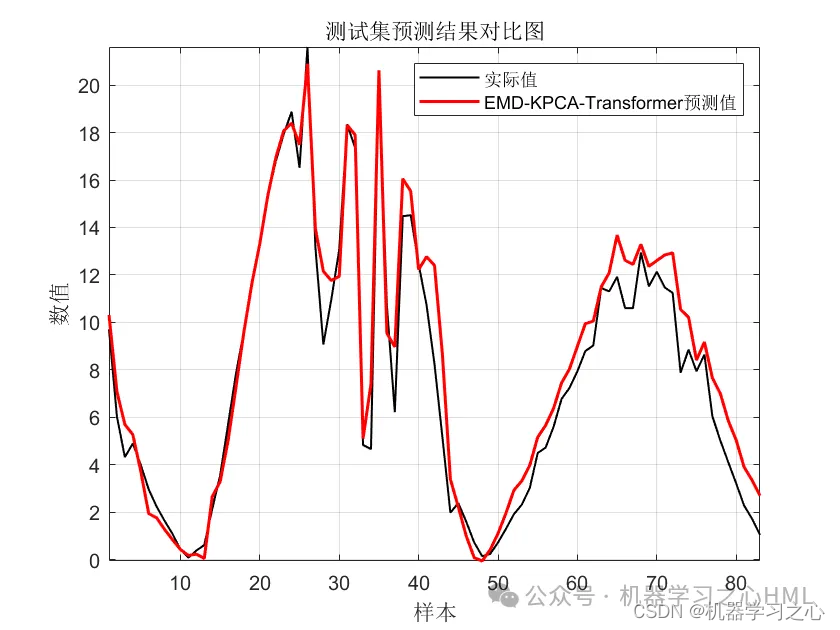
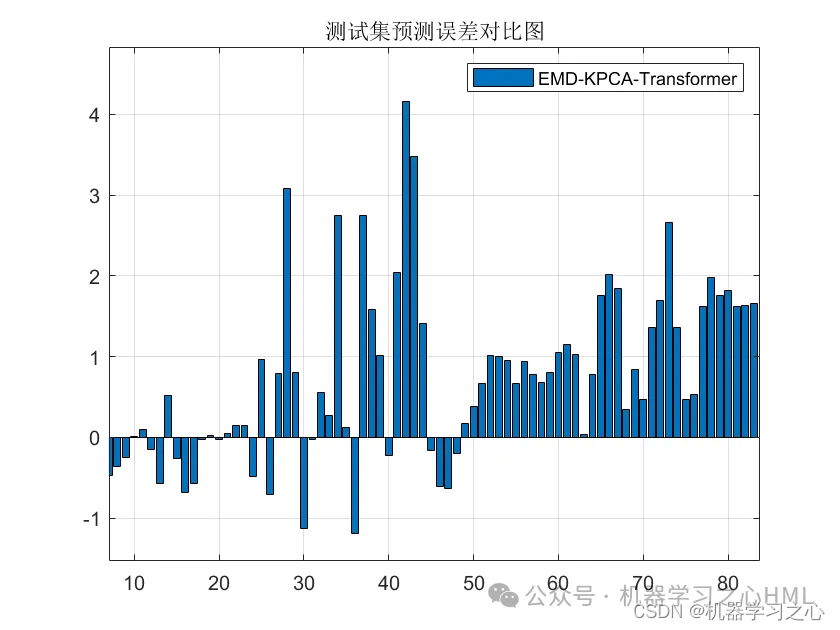
基本介绍
1.MATLAB实现EMD-KPCA-Transformer多变量时间序列光伏功率预测;
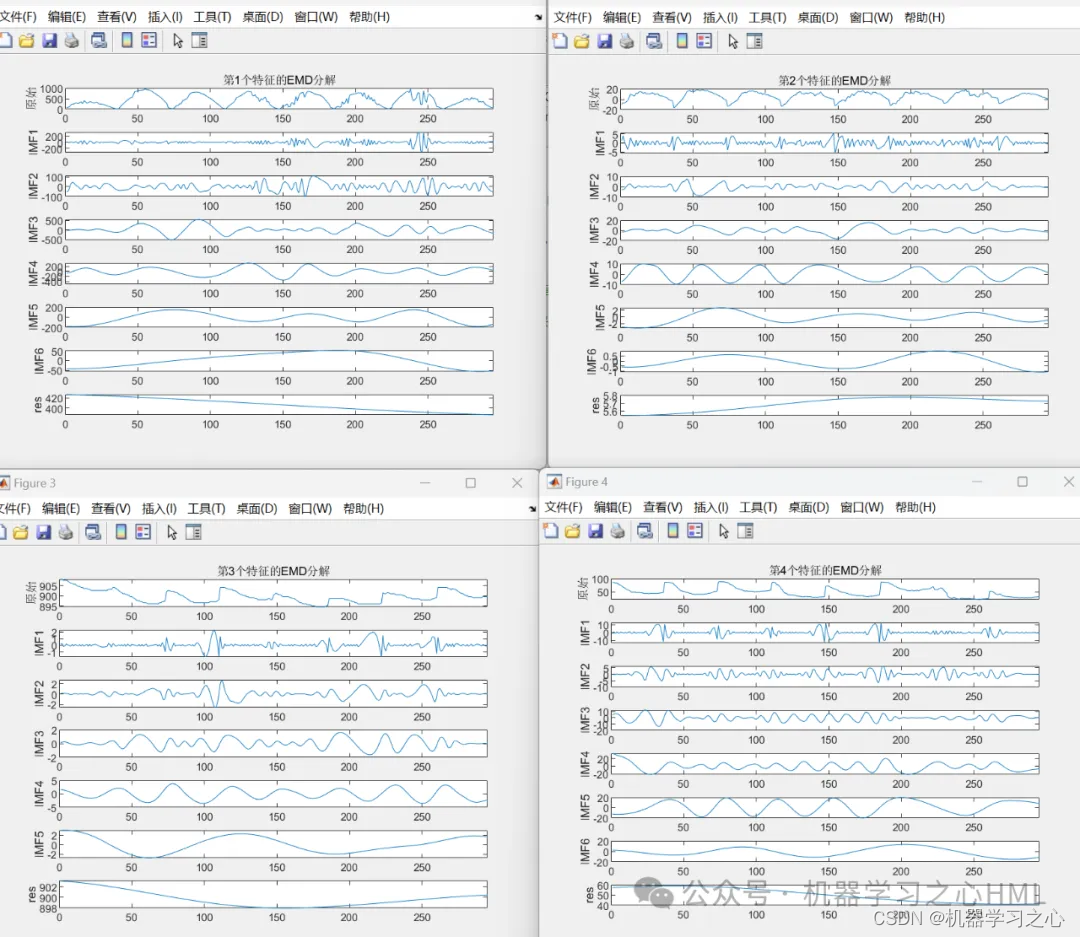
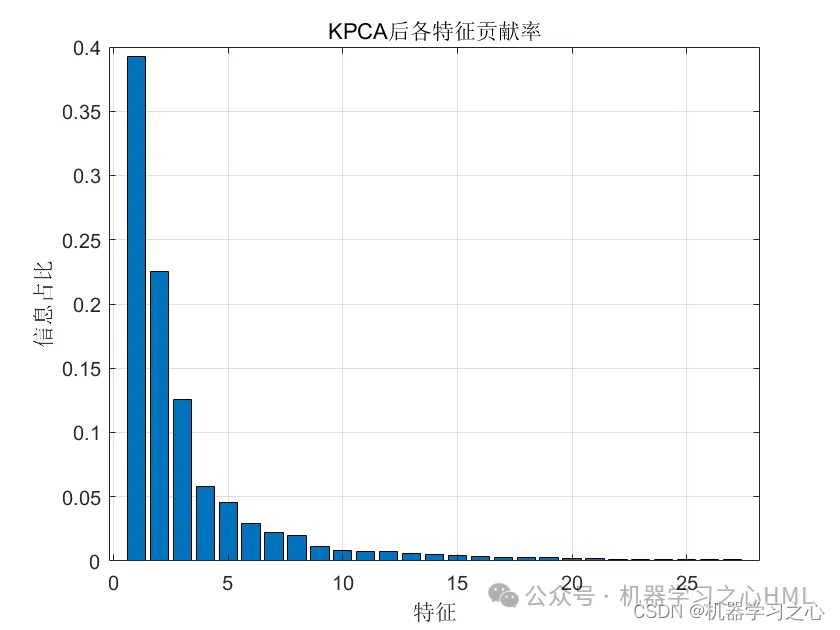
2.多变量时间序列预测 就是先emd把原输入全分解变成很多维作为输入KPCA降维 再输入Transformer预测 ;
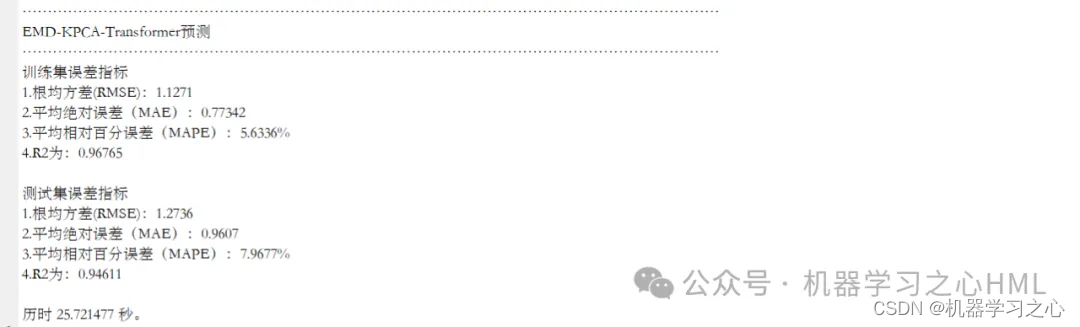
3.运行环境Matlab2023b及以上,输出RMSE、R2、MAPE、MAE等多指标对比,
先运行main1_EMD,进行emd分解;再运行main2_KPCA降维;再运行main3_EMD_KPCA_Transformer建模预测。
注意:一种算法不是万能的,不同的数据集效果会有差别,后面的工作就是需要调整参数;
4.运行环境为Matlab2023b及以上;
5.数据集为excel,光伏数据集,输入多个特征,输出单个变量,考虑历史特征的影响,多变量时间序列预测,所有文件放在一个文件夹;
6.命令窗口输出R2、RMSE、MAE、MAPE等多指标评价。
购&买后可加点击文章底部卡片博主咨询交流。注意:其他非官方渠道购&买的盗版代码不含模型咨询交流服务,大家注意甄别,谢谢。

程序设计
- 完整程序和数据下载私信博主回复分解+降维+预测!多重创新!直接写核心!EMD-KPCA-Transformer多变量时间序列光伏功率预测。
clike
clc;
clear
close all
%% Transformer预测
tic
load origin_data.mat
load emd_data.mat
load KPCA_data.mat
%% EMD-KPCA-Transformer预测
tic
disp('..........................................................................................................................................')
disp('EMD-KPCA-Transformer预测')
disp('..........................................................................................................................................')
data=[KPCA_data X(:,end)];
num_samples = length(data); % 样本个数
kim = 5; % 延时步长(kim个历史数据作为自变量)
zim = 1; % 跨zim个时间点进行预测
or_dim = size(data,2);
res=[];
% 重构数据集
for i = 1: num_samples - kim - zim + 1
res(i, :) = [reshape(data(i: i + kim - 1,:), 1, kim*or_dim), data(i + kim + zim - 1,:)];
end
% 训练集和测试集划分
outdim = 1; % 最后一列为输出
num_size = 0.7; % 训练集占数据集比例
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[P_train, ps_input] = mapminmax(P_train, 0, 1);
P_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);参考资料
1 https://blog.csdn.net/kjm13182345320/article/details/128163536?spm=1001.2014.3001.5502
2 https://blog.csdn.net/kjm13182345320/article/details/128151206?spm=1001.2014.3001.5502