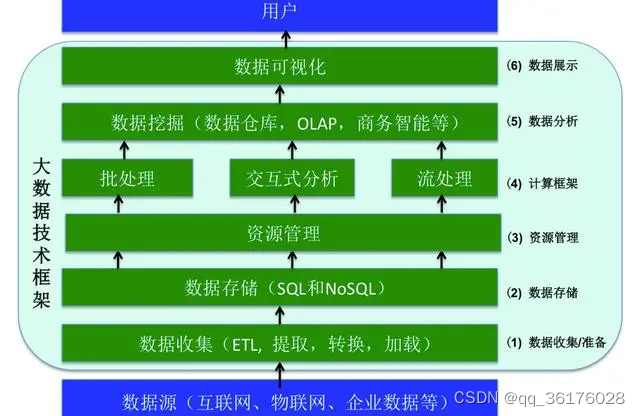
随着大数据时代的到来,处理海量数据成为了各个领域的关键挑战之一。为了应对这一挑战,多个大数据处理框架被开发出来,其中最知名的包括Hadoop、Spark和Flink。本文将对这三个大数据处理框架进行比较,以及在不同场景下的选择考虑。
一、Hadoop
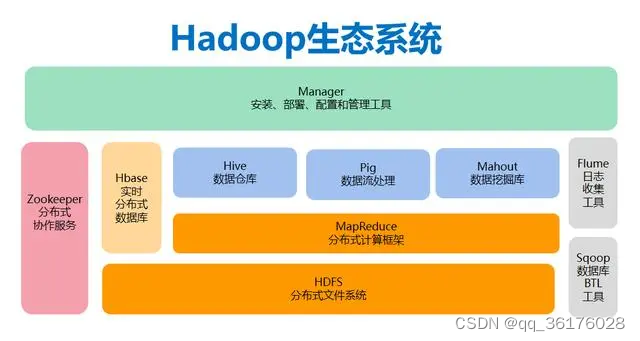
Hadoop是大数据处理领域的先驱,其核心组件包括Hadoop Distributed File System(HDFS)和MapReduce。HDFS负责将大数据分布式存储在多台服务器上,而MapReduce则负责将数据分成小块进行并行处理。Hadoop适用于批处理任务,但在实时数据处理方面表现不佳。


优点:
-
良好的可伸缩性,适用于处理大规模数据。
-
成熟稳定,得到了广泛的应用。
-
适合批处理作业,特别是离线数据分析。
缺点:
-
实时性差,适用性有限。
-
编写MapReduce任务较为繁琐。
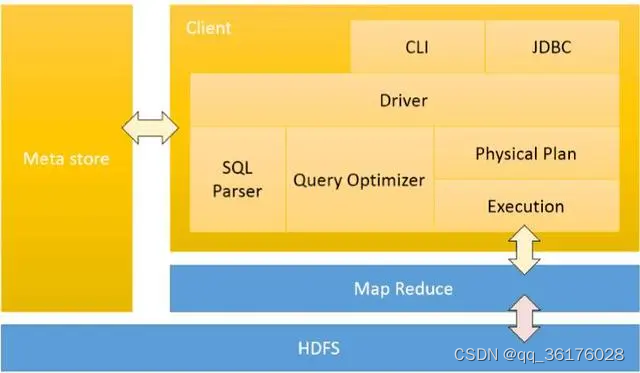
二、Spark
Spark是一个快速、通用的大数据处理框架,拥有比Hadoop更好的性能和更广泛的应用领域。它支持多种编程语言(如Scala、Python、Java)和多种数据处理模式(如批处理、流处理、机器学习等)。Spark内置了弹性分布式数据集(RDD)的概念,可用于内存中高效地存储和处理数据。


优点:
-
比Hadoop处理速度更快,尤其是在内存计算模式下。
-
支持多种数据处理模式,包括批处理和实时流处理。
-
API丰富,适合不同类型的数据处理任务。
缺点:
-
对于数据流处理,性能可能不如专门的流处理框架。
-
在某些情况下,需要更多的内存资源。
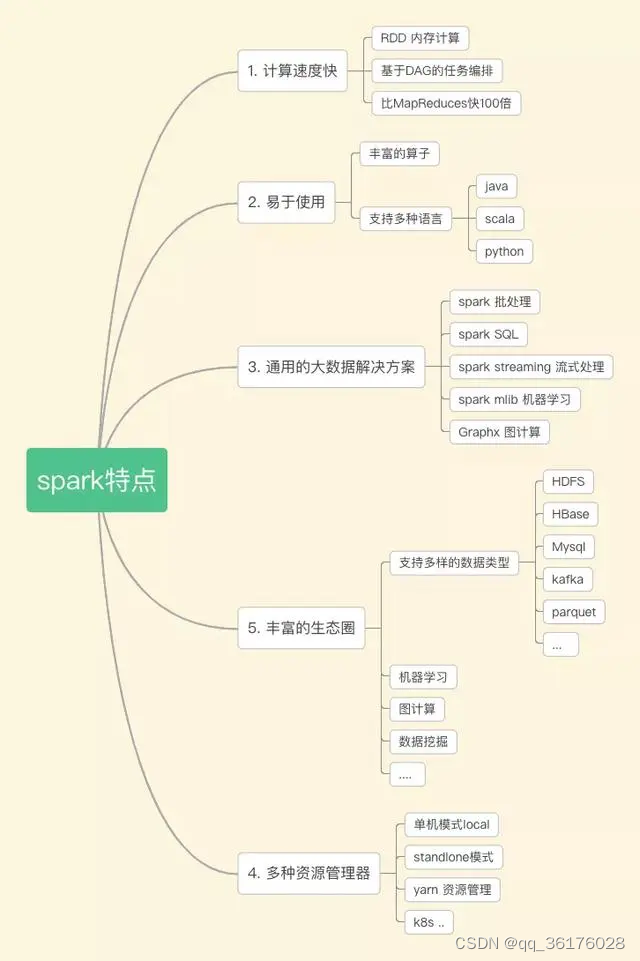
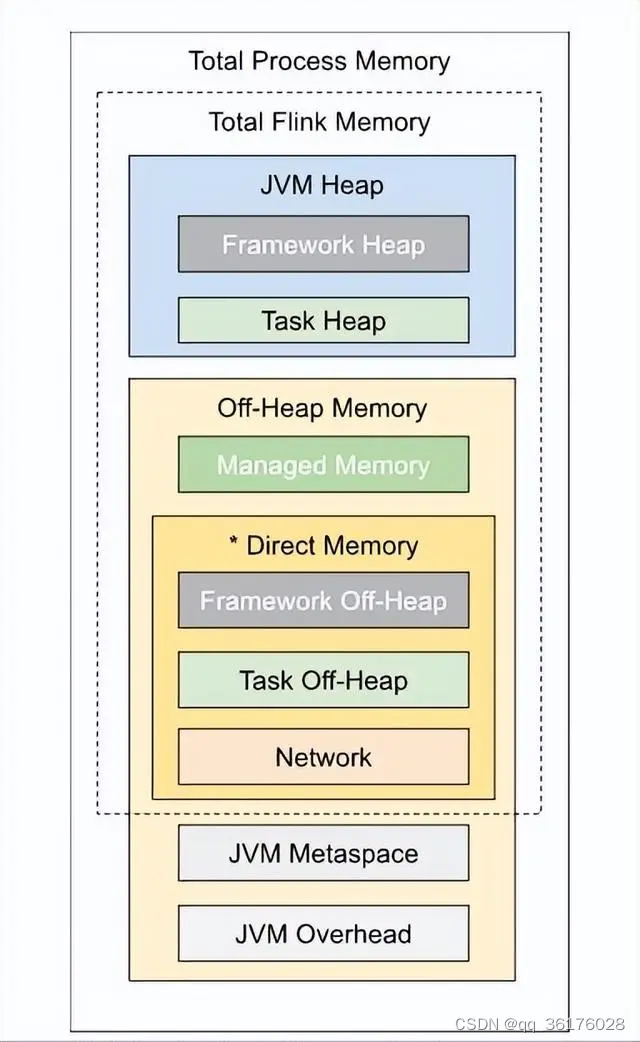
三、Flink
Flink是一个强大的流式处理框架,能够实现低延迟的实时数据处理。与Spark相比,Flink专注于流处理,可以提供更好的事件处理和状态管理。它还支持批处理任务,因此在一些情况下可以替代Hadoop和Spark。

优点:
-
低延迟的实时数据处理,适用于需要实时反馈的应用。
-
支持流处理和批处理,具有更好的事件处理和状态管理能力。
-
适用于复杂的事件处理和数据流分析。
缺点:
-
相对较新,相比Hadoop和Spark社区规模较小。
-
对于某些特定的批处理任务,性能可能不如Spark。
四、如何选择?
选择适合的大数据处理框架取决于项目的需求和目标:

-
Hadoop: 如果你主要需要处理离线的大规模批处理任务,Hadoop可能是一个不错的选择。
-
Spark: 如果你需要在大规模数据上进行快速的数据分析和处理,而且希望有更好的编程灵活性,Spark可能是更好的选择。
-
Flink: 如果你需要低延迟的实时数据处理,尤其是对于事件处理和流分析,Flink是一个优秀的选择。

在选择框架时,还需要考虑团队的技能水平、资源需求和项目目标。最终,根据具体需求权衡各个框架的优缺点,选择最适合的大数据处理框架。