一、背景介绍
最近项目需要识别自定义物品,于是学习利用YOLOv8算法,实现物品识别。由于物体类别不再常规模型中,因此需要自己训练相应的模型,特此记录模型训练的过程。
二、训练模型的步骤
1.拍照获取训练图片(训练图片越多越好)
2.将图片进行处理获得数据集:
给图片打标签,并完成数据集分割。按照验证情况,训练集越多,最终的模型验证结果越好。
深度相机识别物体------实现数据集准备与数据集分割-CSDN博客
3.训练模型:
用以下代码进行模型训练,epochs表示的是迭代次数,imgsz表示的是图像大小。
模型训练前,需要先配置相应的文件,配置文件test_data.yaml如下:
python
# 模型训练时的配置文件,说明了文件训练的地址和
# path: C:\Users\82370\.conda\envs\Ayolo8\Lib\site-packages\ultralytics\dataset
train: C:\Users\82370\.conda\envs\Ayolo8\Lib\site-packages\ultralytics\dataset\train # train 文件夹
val: C:\Users\82370\.conda\envs\Ayolo8\Lib\site-packages\ultralytics\dataset\val # val 文件夹
test: # test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
nc: 2 # 类别数目
# Classes
names: [Sumblock, Barbie]
#0: Sunblock
#1: Barbie模型训练文件train_model,py 如下:
python
# 用于训练自定义模型的代码文件
from ultralytics import YOLO
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE' # 这里是用于解决报错
# load a model 加载模型
model = YOLO('yolov8n.pt')
# train the model 训练模型
results = model.train(data='test_data.yaml', epochs=300, imgsz=640)
# 模型验证
model.val()注意,运行训练模型文件时,需要先在命令行执行cd C:\Users\82370\.conda\envs\Ayolo8\Lib\site-packages\ultralytics\dataset ,进入到test_data.yaml配置文件所在文件夹。
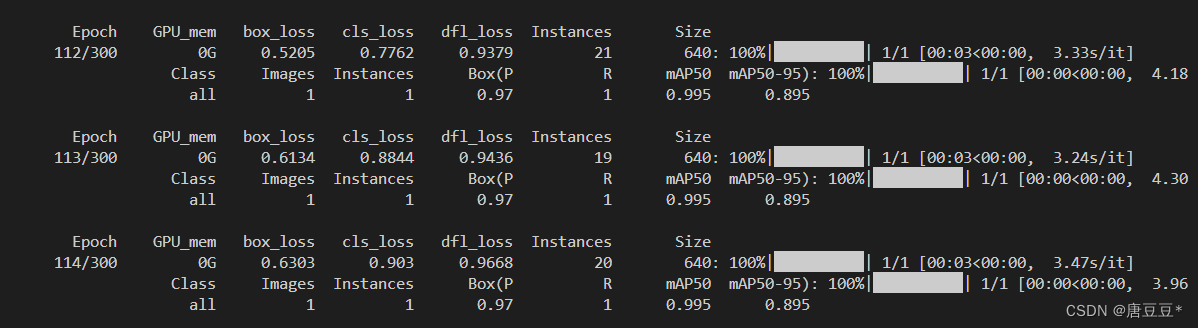
训练过程示意图:
下图为训练结果储存位置,其中best为训练出的模型

4. 利用图片对相应的模型进行验证
相应Yolo_test.py代码如下
python
from ultralytics import YOLO
model =YOLO(r'C:\Users\82370\.conda\envs\Ayolo8\Lib\site-packages\ultralytics\dataset\runs\detect\train\weights\best.pt')
model.predict(r'E:\T\TE1.jpg',save=True)
model.predict(r'E:\T\testa.jpg',save=True)
model.predict(r'E:\T\ts.jpg',save=True)验证结果如下:



