一、实例图片
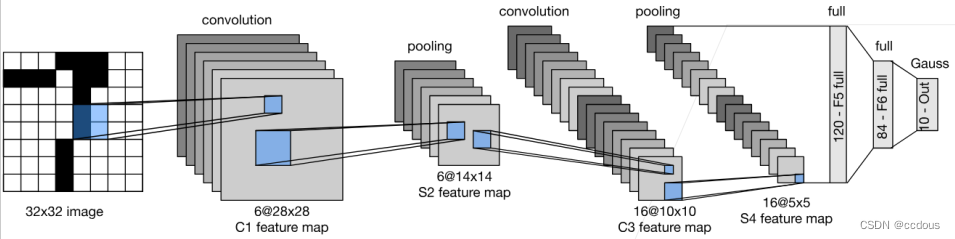
#我们传入的是28*28,所以加了padding
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))二、总结
1、LeNet是早期成功的神经网络
2、先使用卷积层来学习图片空间信息
3、然后使用全连接层来转换到类别空间
三、代码
1、评估模型,将参数放到GPU中
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
#eval是将模型设置为评估模式,评估模式就不会改变模型参数了可以用来预测结果;eval就是关闭模型中的dropout功能,调到评价模式;与之相对的是train()
net.eval()
if not device:
#如果未提供设备参数,则使用模型第一个参数的设备作为默认设备。这确保了数据和模型在 同一设备上运行
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
#确保在计算精度时不会计算梯度,从而节省显存和提高计算效率
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# BERT微调所需的(之后将介绍)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]2、训练模型
#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)"""
#对于net里面的所有parameter,都去run一下那个初始化权重的函数。就是说在整个net中的所有层
上面都使用init__weights函数来初始化所有现行层和卷积层的权重
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
#xavier能够根据输入输出的大小,使得初始化随机权重能使,输入和输出的方差差别不会
很大,保证在模型最开始的时候,结果不会指数爆炸或者消失
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
#SGD是随机梯度下降算法
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
#l是当前批次的平均损失。X.shape[0]是当前批次的样本数。l * X.shape[0]
计算的是当前批次的总损失。
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
#这里是可视化
#(i + 1) % (num_batches // 5)每训练到一个阶段时(5次中的每一次)会更新可视化数据
#i == num_batches - 1:当训练到最后一个批次时,条件也会满足
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')