SSD目标检测
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法。使用Nvidia Titan X在VOC 2007测试集上,SSD对于输入尺寸300x300的网络,达到74.3%mAP(mean Average Precision)以及59FPS;对于512x512的网络,达到了76.9%mAP ,超越当时最强的Faster RCNN(73.2%mAP)。具体可参考论文1。 SSD目标检测主流算法分成可以两个类型:
-
two-stage方法:RCNN系列
通过算法产生候选框,然后再对这些候选框进行分类和回归。
-
one-stage方法:YOLO和SSD
直接通过主干网络给出类别位置信息,不需要区域生成。
SSD是单阶段的目标检测算法,通过卷积神经网络进行特征提取,取不同的特征层进行检测输出,所以SSD是一种多尺度的检测方法。在需要检测的特征层,直接使用一个3 ×× 3卷积,进行通道的变换。SSD采用了anchor的策略,预设不同长宽比例的anchor,每一个输出特征层基于anchor预测多个检测框(4或者6)。采用了多尺度检测方法,浅层用于检测小目标,深层用于检测大目标。SSD的框架如下图:

模型结构
SSD采用VGG16作为基础模型,然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测。SSD的网络结构如图所示。上面是SSD模型,下面是YOLO模型,可以明显看到SSD利用了多尺度的特征图做检测。

两种单阶段目标检测算法的比较:
SSD先通过卷积不断进行特征提取,在需要检测物体的网络,直接通过一个3 ×× 3卷积得到输出,卷积的通道数由anchor数量和类别数量决定,具体为(anchor数量*(类别数量+4))。
SSD对比了YOLO系列目标检测方法,不同的是SSD通过卷积得到最后的边界框,而YOLO对最后的输出采用全连接的形式得到一维向量,对向量进行拆解得到最终的检测框。
模型特点
-
多尺度检测
在SSD的网络结构图中我们可以看到,SSD使用了多个特征层,特征层的尺寸分别是38 ×× 38,19 ×× 19,10 ×× 10,5 ×× 5,3 ×× 3,1 ×× 1,一共6种不同的特征图尺寸。大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体。多尺度检测的方式,可以使得检测更加充分(SSD属于密集检测),更能检测出小目标。
-
采用卷积进行检测
与YOLO最后采用全连接层不同,SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为m ×× n ×× p的特征图,只需要采用3 ×× 3 ×× p这样比较小的卷积核得到检测值。
-
预设anchor
在YOLOv1中,直接由网络预测目标的尺寸,这种方式使得预测框的长宽比和尺寸没有限制,难以训练。在SSD中,采用预设边界框,我们习惯称它为anchor(在SSD论文中叫default bounding boxes),预测框的尺寸在anchor的指导下进行微调。
模型构建
SSD的网络结构主要分为以下几个部分:
-
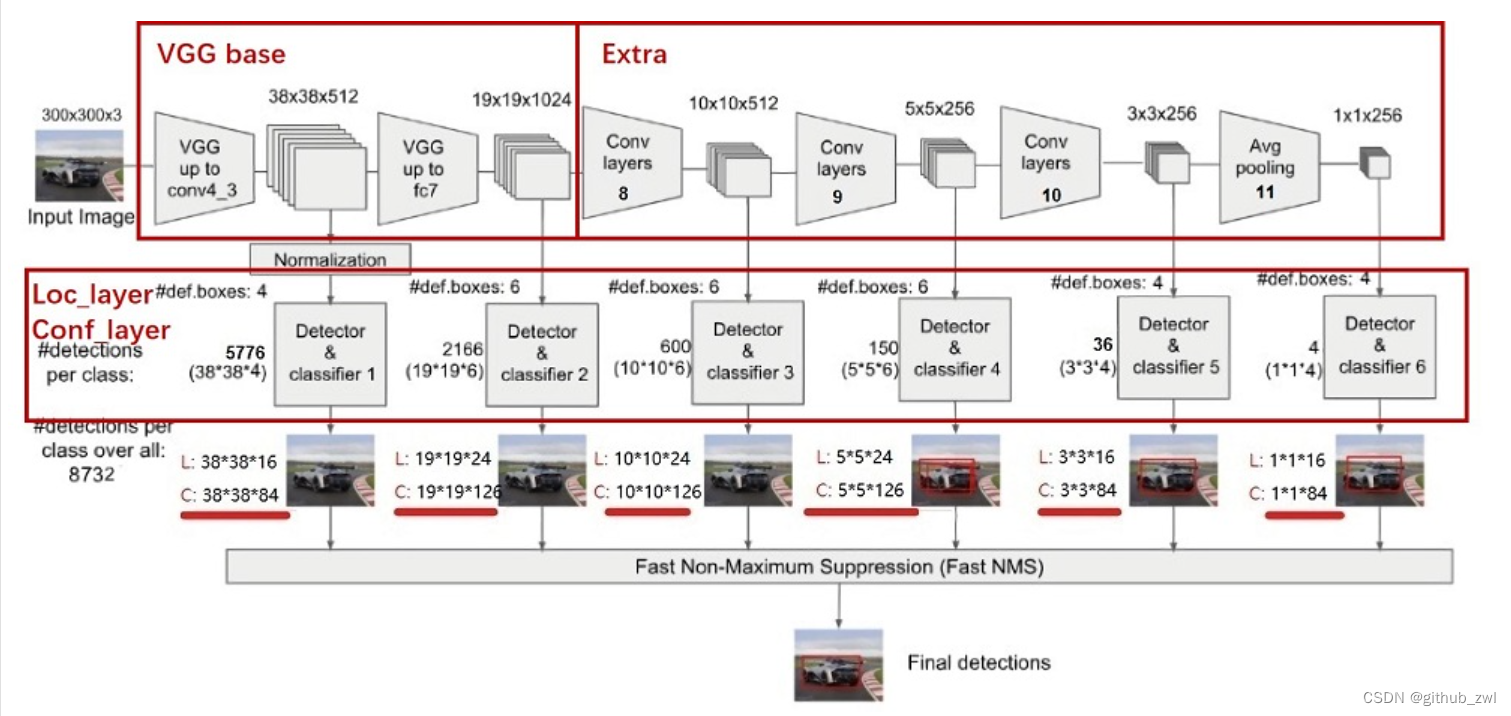
-
VGG16 Base Layer
-
Extra Feature Layer
-
Detection Layer
-
NMS
-
Anchor
损失函数
SSD算法的目标函数分为两部分:计算相应的预选框与目标类别的置信度误差(confidence loss, conf)以及相应的位置误差(locatization loss, loc):
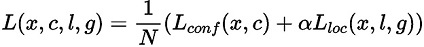
其中:
N 是先验框的正样本数量;
c 为类别置信度预测值;
l 为先验框的所对应边界框的位置预测值;
g 为ground truth的位置参数
α 用以调整confidence loss和location loss之间的比例,默认为1。
对于位置损失函数
针对所有的正样本,采用 Smooth L1 Loss, 位置信息都是 encode 之后的位置信息。
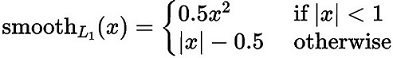
对于置信度损失函数
置信度损失是多类置信度(c)上的softmax损失。
