事务
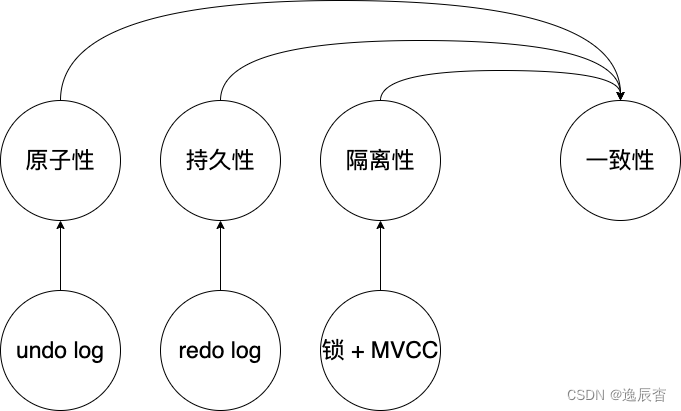
AICD
- Atomicity:原子性
- Isolation:隔离性
- Consistency:一致性
- Durability:持久性
脏读、不可重复读、幻读
- 脏读:一个事务中读到其他未提交事务修改的数据
- 不可重复读:在一个事务中,对同一份数据多次读取到的结果不一致
- 更侧重数据的修改
- 幻读:在一个事务内,相同的select语句前后执行,得到的数据结果不一致
- 更侧重数据的insert和delete
事务隔离级别
- Serializable(顺序读):可避免脏读、不可重复读、幻读
- 所有语句都会上锁;select也会追加共享锁(lock in share mode)
- 加上共享锁,允许其他读操作;保存读取数据一致性;如果发生写操作,尝试对数据加独占锁时,则会失败;必须等共享锁释放才可以。
- Repeatable read(可重复读,默认隔离级别):可避免脏读、不可重复读
- 消除脏读的原因:数据快照ReadView中记录了所有在途的事务集合,可以屏蔽不可见的事务结果
- 消除不可重复读的原因:采用快照读;事务开启的时刻,会创建一份数据快照,事务内的所有读请求都基于该快照
- 会对Select、update、insert、delete加锁
- 为什么无法解决幻读:
- Ready committed(读已提交):可避免脏读
- 消除脏读的原因:数据快照ReadView中记录了所有在途的事务集合,可以屏蔽不可见的事务结果
- 为什么无法解决不可重复读:采用当前读;事务中每次读请求都会创建一份数据快照,会导致不同阶段看到的在途事务不一致
- 只会对update、insert、delete加锁;Select语句不加锁,这是产生重复读的根本原因
- 为什么无法解决幻读:
- 通过MVCC+行间锁可以解决大部分情况的幻读问题,但无法根除;
- Ready uncommitted(读未提交):最低隔离级别,任何情况都无法保障
- 什么锁都不加,没不使用MVCC,所有什么问题都可能发生
RR和RC为什么解决不了幻读、该如何解决:
RR基于临间锁只能解决部分幻读问题;解决不了的幻读场景
-
case1:在事务A的执行期间,事务B执行了insert/delete操作
- 事务A先select(快照读)
- 事务B执行insert(快照读不产生临间锁,写操作不受影响)
- 事务A再执行update(update是当前读,则会刷新快照信息,导致可以看到事务B执行完成后的结果)
- 事务A再执行select就发生幻读

-
case2:事务A中第一次查询采用快照读,第二次采用当前读
- 事务A快照读
- 事务B执行insert(A的快照读不产生临间锁,不阻塞B的写入)
- 事务A当前读

隔离级别的实现原理
MVCC
基于MVCC产生的数据快照 ReadView,其内部结构如下(2个核心集合)
- 创建ReadView时刻,当前DB所有在途事务ID集合(开启但未提交)
- 在途事务集合中最小的事务ID(当事务ID小于这个值,代表事务已提交)
- roll_pointer,回滚指针,指向undo log,记录在途事务的原始数据,串联回滚指针实现全量的快照数据恢复
- 预分配给下一个事物的ID(当事务ID大于等于这个事,代表这个事物是后面创建的,即不可见)
如何判断一个事务是否可见:
- 目标事务ID小于在途事务集合的最小事务ID,代表该事务已提交
- 目标事务ID大于在途事务集合的最大事务ID,代表事务是后来创建的,即不可见
- 目标事务ID介于最小值和最大值之间,则需要判断是否在在途事务集合列表
- 在列表中,说明当前版本创建时,该事务还未提交,所以不可见
- 不在列表中,说明当前版本创建时,该事务已提交,所以可见
MySQL日志
三个日志文件的区别

bin log
记录的是执行的sql语句;主要用于数据同步 & 恢复
redo log
重做日志,用于保障MySQL事务持久化能力。记录的是修改后的最新数据。
如何保障持久化:在事务提交前,先确保修改后的数据成功写入redolog,在执行事务的commit操作。这样当数据库异常,内存数据无法回刷磁盘时,可以通过redo log实现数据恢复,保证事务结果的一致性
sql修改数据的底层流程
- 先通过select将数据检索并加载到内容
- 在内存中更新数据,然后将内存结果回刷到磁盘
因为InnoDB在磁盘的存储单位是页,如果页内的更新数据量较少,或者同时更新多个页,会产生随机IO问题,影响数据回刷的心梗。所以可以再内存数据修改之后,在同步记录一份redo log;作为一份备份保障。当内存数据正常回刷到磁盘,就用不着redo log,如果内存数据回刷不及时或者内存异常,则基于redo log 恢复
所以redo log文件一般是一个固定大小的文件,可以支持覆盖覆写的;并不是无限大。


undo log
回滚日志;记录数据修改前的日志。记录的是一个相反的命令
e.g. 执行一个insert 语句,则undo log里会对应记录一条delete语句;
执行一个update语句,则undo log里会记录一条update语句,只不过更新结果是SQL执行前的原始值。
undo log的写入在内存数据修改之前
使用场景:
- 日志回滚
- MVCC
数据库的索引结构
B树结构的特点
B树的节点包含三个维度的数据
- 索引键
- 对应的Value值
- 子节点的地址索引
优势 - 基于索引的点对点查询比较优化;每个节点都包含数据信息
劣势 - 因为节点包含了索引+数据;当每行数据量过大时,因为节点大小是固定的,会导致整个B树的高度变高,增大了查询是的比较次数,影响查询性能
- 不支持基于索引的范围查询

B+树结构的特点
- 非叶子节点:只存储索引键和子节点的地址信息
- 叶子节点:存储索引键和数据
- 叶子节点有有指向下一个节点的索引;底层是一个双向有序链表
优势 - 树的高度稳定,磁盘IO次数更少
- 支持范围查询
InnoDB引擎的索引结构
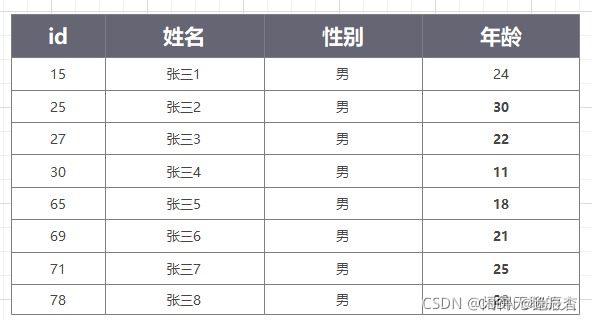
聚簇索引 即主键索引;InnoDB表的数据本身就是基于聚餐索引建立的一个B+树。其中叶子节点记录每一个行完整的数据。非叶子节点只记录了索引信息
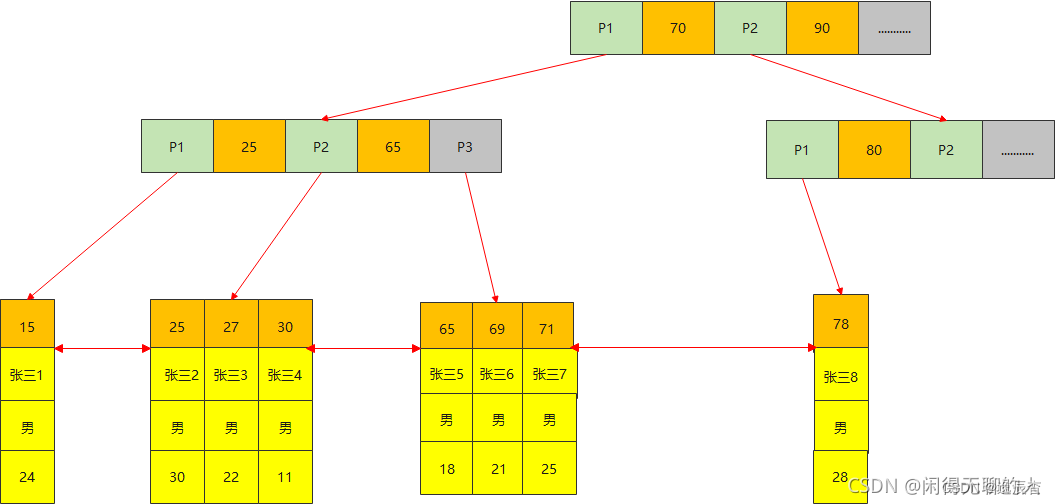
辅助索引,除聚簇索引之外的其他索引。索引结构是基于特定的索引列创建B+树;叶子节点记录对应的主键隐私
所以基于辅助索引的查询,如果只查改列的值,则不需要回表,效果最好。这种方式被称为:覆盖索引