Painless 是一种高性能、安全的脚本语言,专为 Elasticsearch 设计。你可以使用 Painless 在 Elasticsearch 支持脚本的任何地方安全地编写内联和存储脚本。
Painless 提供众多功能,这些功能围绕以下核心原则:
- 安全性 :确保集群的安全性至关重要。为此,Painless 使用细粒度的允许列表,粒度细到类的成员。任何不属于允许列表的内容都会导致编译错误。请参阅 Painless API 参考,了解每个脚本上下文的可用类、方法和字段的完整列表。
- 性能:Painless 直接编译为 JVM 字节码,以利用 JVM 提供的所有可能的优化。此外,Painless 通常会避免在运行时需要额外较慢检查的功能。
- 简单性:Painless 实现的语法对任何具有一些基本编码经验的人来说都很自然熟悉。Painless 使用 Java 语法的子集,并进行了一些额外的改进,以增强可读性并消除样板。

本篇文章的是系列文章中的其中一篇:
开始编写脚本
准备好开始使用 Painless 编写脚本了吗?让我开始编写我们的第一个脚本。
只要 Elasticsearch API 支持脚本,语法就会遵循相同的模式;你可以指定脚本的语言、提供脚本逻辑(或源代码),并添加传递到脚本中的参数:
"script": {
"lang": "...",
"source" | "id": "...",
"params": { ... }
}| 条目 | 描述 |
|---|---|
| lang | 指定脚本所用的语言。默认为 painless。 |
source, id |
脚本本身,你将其指定为内联脚本的源或存储脚本的 id。使用存储脚本 API 创建和管理存储脚本。 |
| params | 指定作为变量传递到脚本中的任何命名参数。使用参数而不是硬编码值来减少编译时间。 |
书写你的第一个脚本
Painless 是 Elasticsearch 的默认脚本语言。它安全、高效,并为任何具有一点编码经验的人提供自然的语法。
Painless 脚本的结构为一个或多个语句,并且可以在开头选择一个或多个用户定义的函数。脚本必须始终至少有一个语句。
Painless 执行 API 提供了使用简单的用户定义参数测试脚本并接收结果的能力。让我们从完整的脚本开始并查看其组成部分。
首先,使用单个字段索引文档,以便我们可以使用一些数据:
PUT my-index-000001/_doc/1
{
"my_field": 5
}然后,我们可以构建一个对该字段进行操作的脚本,并作为查询的一部分运行评估该脚本。以下查询使用搜索 API 的 script_fields 参数来检索脚本评估。这里发生了很多事情,但我们将分解各个组件以分别理解它们。现在,你只需要了解此脚本接受 my_field 并对其进行操作。
GET my-index-000001/_search
{
"script_fields": {
"my_doubled_field": {
"script": { // 1
"source": "doc['my_field'].value * params['multiplier']", // 2
"params": {
"multiplier": 2
}
}
}
}
}- script 对象
- script 代码
script 是一个标准 JSON 对象,用于定义 Elasticsearch 中大多数 API 下的脚本。此对象需要 source 来定义脚本本身。script 未指定语言,因此默认为 Painless。
运行上面的代码,我们可以看到如下的结果:

从上面的输出中,我们可以看到有一个新的字段叫做 my_doubled_field。它的纸是 10。是之前的字段 my_field 的值的两倍。
请注意,从 Elastic Stack 7.11 发布后,我们可以使用 runtime fields 来实现同样的功能:
GET my-index-000001/_search
{
"runtime_mappings": {
"my_doubled_field": {
"type": "long",
"script": {
"source": "emit(doc['my_field'].value * 2)"
}
}
},
"fields": [
"my_doubled_field"
]
}上面运行的结果为: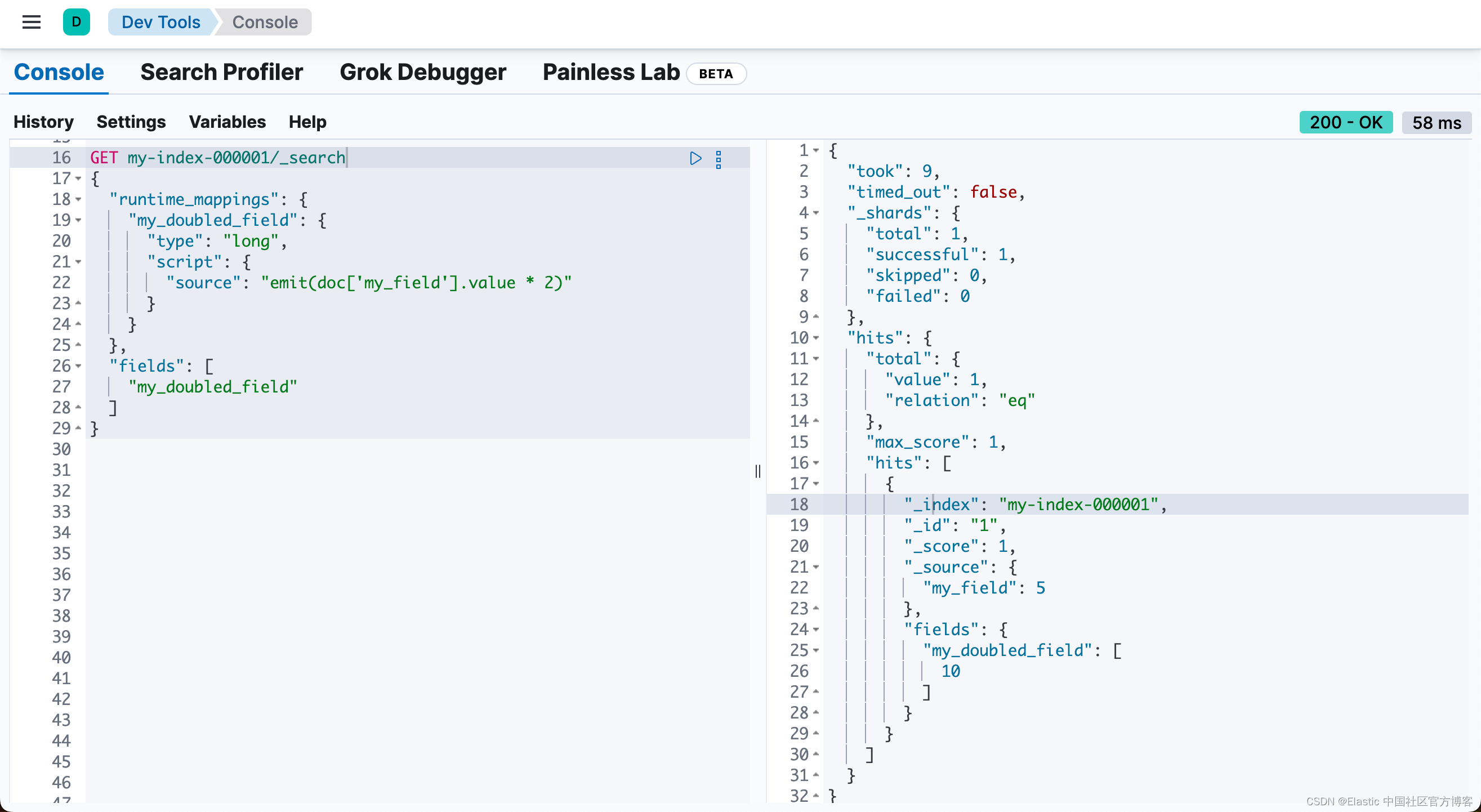
从 Elastic Stack 8.14 后,我们甚至可以使用 ES|QL 来实现同样的功能:
POST _query?format=txt
{
"query": """
FROM my-index-000001
| EVAL my_doubled_field = my_field*2
| LIMIT 1
"""
}上面代码执行的结果为:

在脚本中使用参数
Elasticsearch 第一次看到新脚本时,它会编译该脚本并将编译后的版本存储在缓存中。编译可能是一个繁重的过程。与其在脚本中硬编码值,不如将它们作为命名参数传递。
例如,在上一个脚本中,我们可以只硬编码值并编写一个看似不太复杂的脚本。我们可以只检索 my_field 的第一个值,然后将其乘以 2:
"source": "return doc['my_field'].value * 2"虽然这种方法有效,但灵活性很差。我们必须修改脚本源代码才能更改乘数,而且每次乘数更改时,Elasticsearch 都必须重新编译脚本。
不用对值进行硬编码,而是使用命名参数来提高脚本的灵活性,同时还可以减少脚本运行时的编译时间。现在,你可以更改 multiplier 参数,而无需 Elasticsearch 重新编译脚本。
"source": "doc['my_field'].value * params['multiplier']",
"params": {
"multiplier": 2
}默认情况下,每 5 分钟最多可以编译 150 个脚本。对于采集上下文,默认脚本编译速率不受限制。
script.context.field.max_compilations_rate=100/10m重要:如果你在短时间内编译了太多唯一脚本,Elasticsearch 会拒绝新的动态脚本并出现 circuit_breaking_exception 错误。
缩短脚本
使用 Painless 固有的语法功能,你可以减少脚本的冗长程度并使其更短。下面是我们可以缩短的简单脚本:
GET my-index-000001/_search
{
"script_fields": {
"my_doubled_field": {
"script": {
"lang": "painless",
"source": "doc['my_field'].value * params.get('multiplier');",
"params": {
"multiplier": 2
}
}
}
}
}让我们看一下脚本的缩短版本,看看它与上一次版本相比有哪些改进:
GET my-index-000001/_search
{
"script_fields": {
"my_doubled_field": {
"script": {
"source": "field('my_field').get(null) * params['multiplier']",
"params": {
"multiplier": 2
}
}
}
}
}此版本的脚本删除了几个组件并显著简化了语法:
- lang 声明。由于 Painless 是默认语言,因此如果你正在编写 Painless 脚本,则无需指定语言。
- return 关键字。Painless 会自动使用脚本中的最后一个语句(如果可能)在需要返回值的脚本上下文中生成返回值。
- get 方法,用括号 \[\] 替换。Painless 专门为 Map 类型使用了快捷方式,允许我们使用括号而不是较长的 get 方法。
- source 语句末尾的分号。Painless 不需要在块的最后一个语句中使用分号 ;。但是,在其他情况下确实需要它们来消除歧义。
在 Elasticsearch 支持脚本的任何地方使用此缩写语法,例如当你创建 runtime fields。
存储和检索脚本
你可以使用存储脚本 API 从集群状态存储和检索脚本。存储脚本可减少编译时间并加快搜索速度。
注意:与常规脚本不同,存储脚本要求你使用 lang 参数指定脚本语言。
要创建脚本,请使用 create stored script API。例如,以下请求将创建一个名为 calculate-score 的存储脚本。
POST _scripts/calculate-score
{
"script": {
"lang": "painless",
"source": "Math.log(_score * 2) + params['my_modifier']"
}
}你可以使用 get stored script API 检索该脚本。
GET _scripts/calculate-score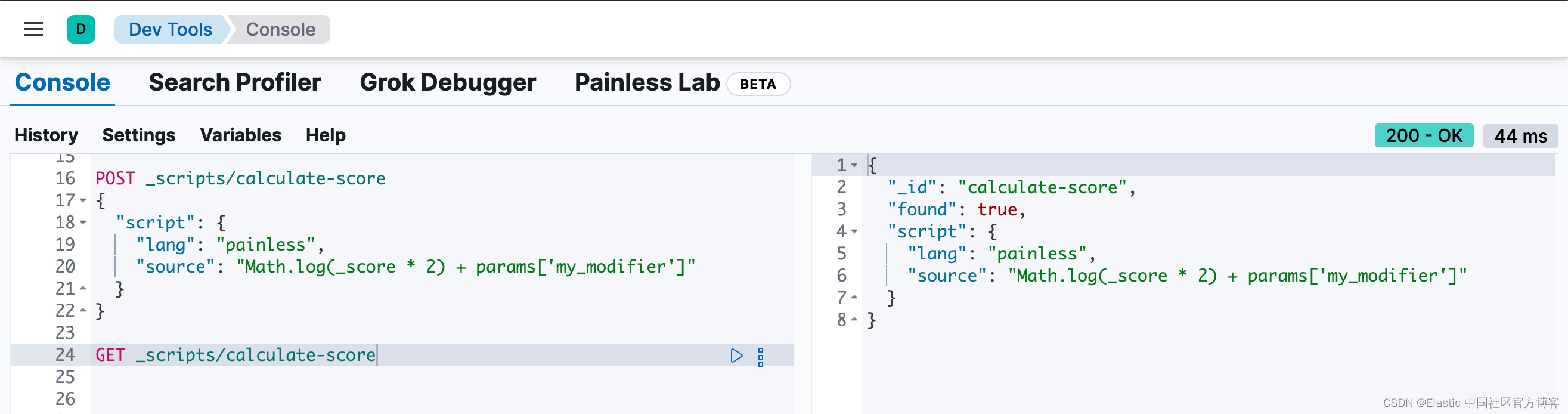
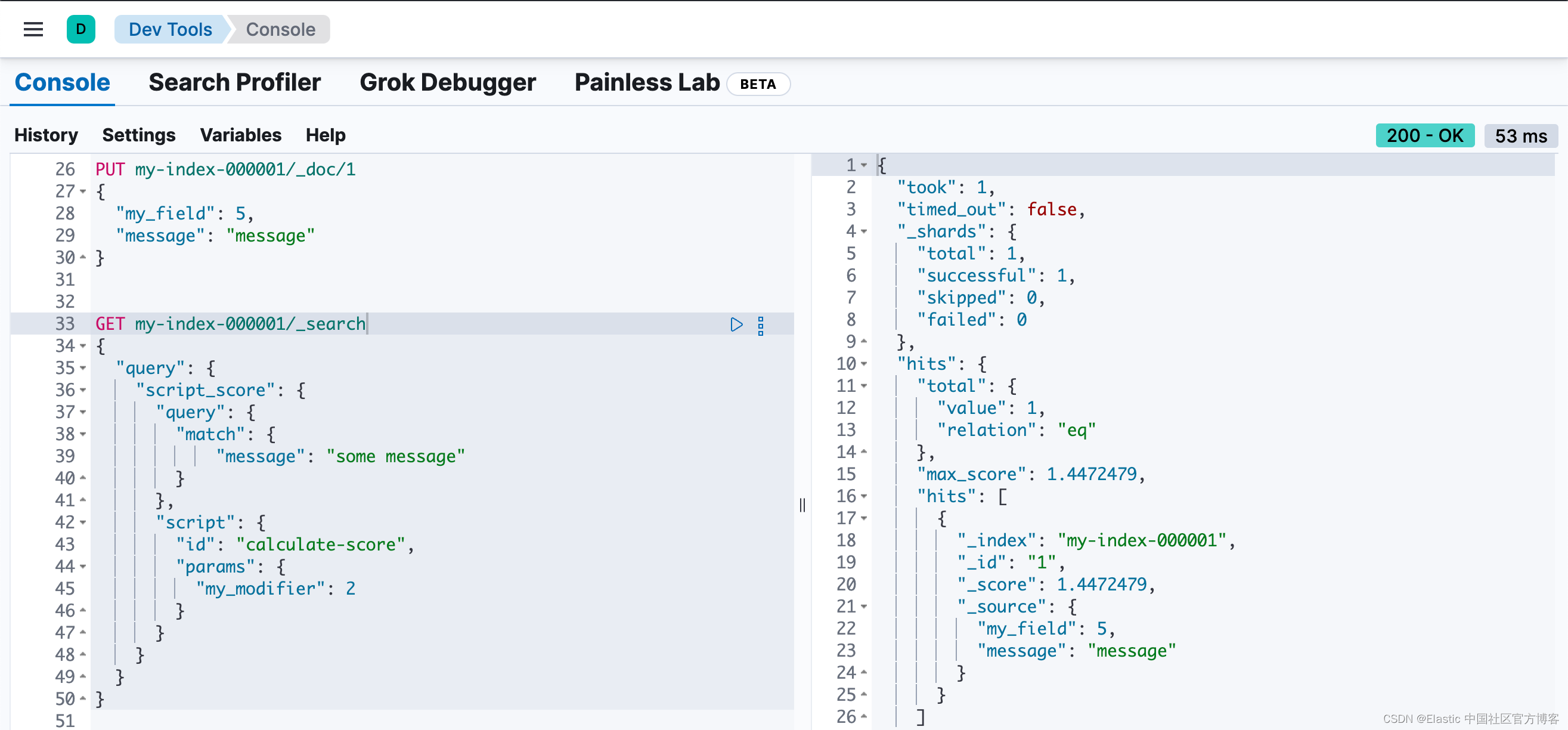
要在查询中使用存储的脚本,请在脚本声明中包含脚本 ID:
GET my-index-000001/_search
{
"query": {
"script_score": {
"query": {
"match": {
"message": "some message"
}
},
"script": {
"id": "calculate-score", // 1
"params": {
"my_modifier": 2
}
}
}
}
}
- id 是存储脚本的 id
要删除存储的脚本,请提交 delete stored script API 请求。
DELETE _scripts/calculate-score使用脚本更新文档
你可以使用 update API 使用指定的脚本更新文档。脚本可以更新、删除或跳过修改文档。更新 API 还支持传递部分文档,该部分文档将合并到现有文档中。
首先,让我们索引一个简单的文档:
DELETE my-index-000001
PUT my-index-000001/_doc/1
{
"counter" : 1,
"tags" : ["red"]
}要增加 counter,你可以使用以下脚本提交更新请求:
POST my-index-000001/_update/1
{
"script" : {
"source": "ctx._source.counter += params.count",
"lang": "painless",
"params" : {
"count" : 4
}
}
}我们可通过如下的命令来进行查看:
GET my-index-000001/_doc/1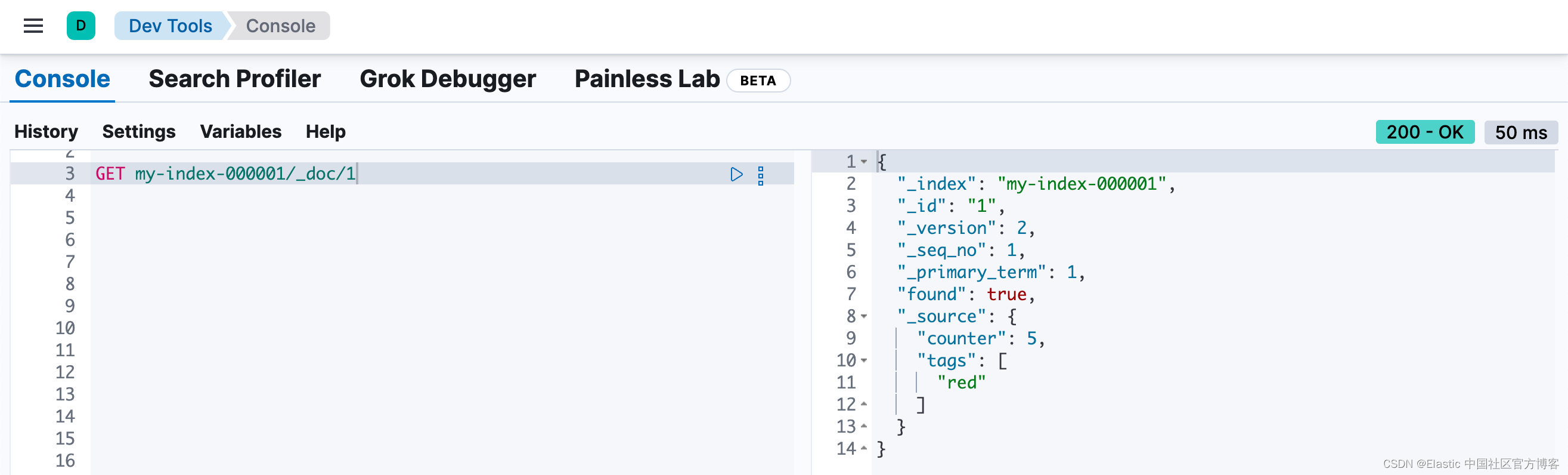
我们可以看见 counter 的值从 1 变为 5。
类似地,你可以使用更新脚本将标签添加到 tag 列表中。因为这只是一个列表,所以即使标签存在,也会被添加:
POST my-index-000001/_update/1
{
"script": {
"source": "ctx._source.tags.add(params['tag'])",
"lang": "painless",
"params": {
"tag": "blue"
}
}
}
GET my-index-000001/_doc/1
我们可以看到 blue 已经被添加。
注意:在修改 source 的时候,我们需要使用正确的上下文,也即使用 ctx._source 来进行修改。
你还可以从标签列表中删除标签。Java List 的 remove 方法在 Painless 中可用。它采用要删除的元素的索引。为避免可能的运行时错误,你首先需要确保标签存在。如果列表包含标签的重复项,则此脚本只会删除一个出现项。
POST my-index-000001/_update/1
{
"script": {
"source": "if (ctx._source.tags.contains(params['tag'])) { ctx._source.tags.remove(ctx._source.tags.indexOf(params['tag'])) }",
"lang": "painless",
"params": {
"tag": "blue"
}
}
}你还可以在文档中添加和删除字段。例如,此脚本添加了字段 new_field:
POST my-index-000001/_update/1
{
"script" : "ctx._source.new_field = 'value_of_new_field'"
}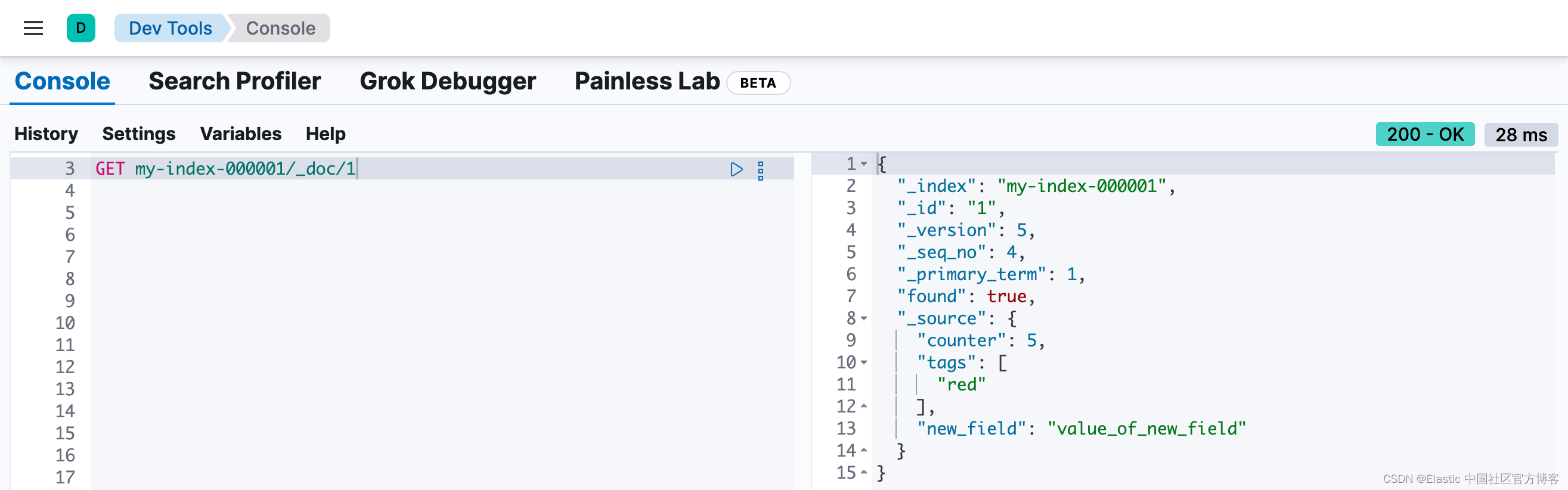
相反,此脚本删除了字段 new_field:
POST my-index-000001/_update/1
{
"script" : "ctx._source.remove('new_field')"
}除了更新文档之外,你还可以更改从脚本内部执行的操作。例如,如果 tags 字段包含 green,则此请求将删除文档。否则它不执行任何操作(noop):
POST my-index-000001/_update/1
{
"script": {
"source": "if (ctx._source.tags.contains(params['tag'])) { ctx.op = 'delete' } else { ctx.op = 'none' }",
"lang": "painless",
"params": {
"tag": "green"
}
}
}脚本、缓存和搜索速度
Elasticsearch 执行了许多优化,以使使用脚本的速度尽可能快。一个重要的优化是脚本缓存。编译后的脚本放置在缓存中,以便引用脚本的请求不会产生编译惩罚。
缓存大小很重要。你的脚本缓存应该足够大,以容纳用户需要同时访问的所有脚本。
如果您看到大量脚本缓存驱逐和节点统计信息(node stats)中的编译数量不断增加,则你的缓存可能太小。
默认情况下,所有脚本都缓存,因此只需在发生更新时重新编译它们。默认情况下,脚本没有基于时间的过期时间。你可以使用 script.cache.expire 设置更改此行为。使用 script.cache.max_size 设置配置缓存的大小。
注意 :脚本的大小限制为 65,535 字节。设置 script.max_size_in_bytes 的值以增加该软限制。如果你的脚本确实很大,那么请考虑使用本机脚本引擎。
提高搜索速度
脚本非常有用,但不能使用 Elasticsearch 的索引结构或相关优化。这种关系有时会导致搜索速度变慢。
如果你经常使用脚本来转换索引数据,则可以通过在摄取期间转换数据来加快搜索速度。但是,这通常意味着索引速度变慢。让我们看一个实际的例子来说明如何提高搜索速度。
运行搜索时,通常按两个值的总和对结果进行排序。例如,考虑一个名为 my_test_scores 的索引,其中包含测试分数数据。此索引包括两个 long 类型的字段:
- math_score
- verbal_score
你可以使用将这些值加在一起的脚本运行查询。这种方法没有错,但是查询会变慢,因为脚本估值是请求的一部分。以下请求返回 grad_year 等于 2099 的文档,并按脚本的估值对结果进行排序。
GET /my_test_scores/_search
{
"query": {
"term": {
"grad_year": "2099"
}
},
"sort": [
{
"_script": {
"type": "number",
"script": {
"source": "doc['math_score'].value + doc['verbal_score'].value"
},
"order": "desc"
}
}
]
}如果你正在搜索一个小型索引,那么将脚本作为搜索查询的一部分可能是一个很好的解决方案。如果你想加快搜索速度,你可以在提取期间执行此计算,并将总和索引到字段。
首先,我们将向名为 total_score 的索引添加一个新的字段,它将包含 math_score 和 verbal_score 字段值的总和。
PUT my_test_scores/_doc/1
{
"math_score": 90,
"verbal_score": 80
}
PUT /my_test_scores/_mapping
{
"properties": {
"total_score": {
"type": "long"
}
}
}接下来,使用包含 script processor 的 ingest pipeline 计算 math_score 和 verbal_score 的总和,并将其索引到 total_score 字段中。
PUT _ingest/pipeline/my_test_scores_pipeline
{
"description": "Calculates the total test score",
"processors": [
{
"script": {
"source": "ctx.total_score = (ctx.math_score + ctx.verbal_score)"
}
}
]
}要更新现有数据,请使用此管道将 my_test_scores 中的所有文档 reindex 到名为 my_test_scores_2 的新索引。
POST /_reindex
{
"source": {
"index": "my_test_scores"
},
"dest": {
"index": "my_test_scores_2",
"pipeline": "my_test_scores_pipeline"
}
}继续使用管道将任何新文档索引到 my_test_scores_2。
POST /my_test_scores_2/_doc/?pipeline=my_test_scores_pipeline
{
"student": "kimchy",
"grad_year": "2099",
"math_score": 1200,
"verbal_score": 800
}我们可以通过如的代码来查询 my_test_scores_2:
GET my_test_scores_2/_search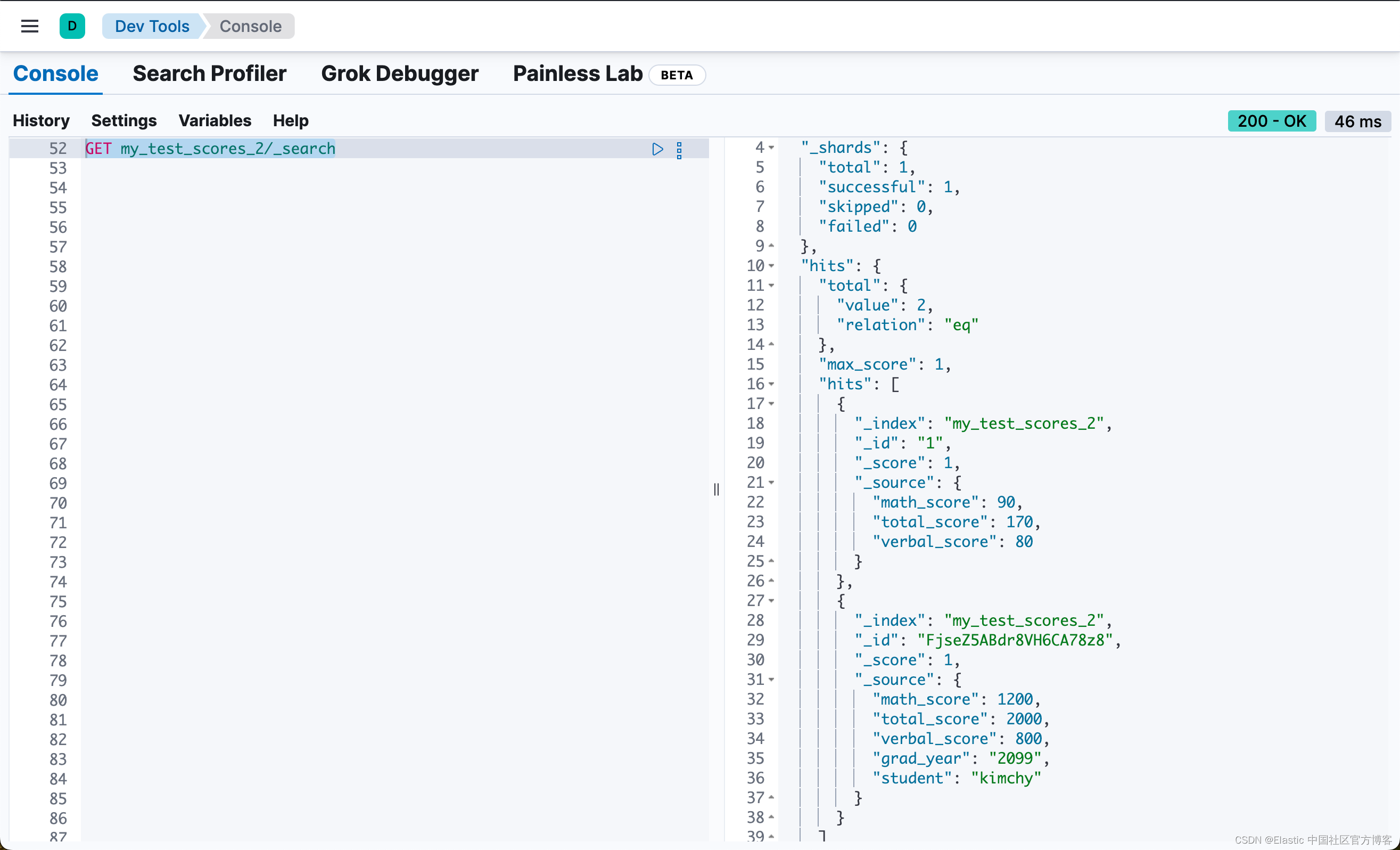
我们可以看到一个新的字段 total_score,并且它的值是 math_score 和 verbal_score 两个字段的总和。
这些更改会减慢索引过程,但可以加快搜索速度。你可以使用 total_score 字段对 my_test_scores_2 上的搜索进行排序,而无需使用脚本。响应几乎是实时的!虽然此过程会减慢采集时间,但它会大大增加搜索时的查询次数。
GET /my_test_scores_2/_search
{
"query": {
"term": {
"grad_year": "2099"
}
},
"sort": [
{
"total_score": {
"order": "desc"
}
}
]
}Dissect 数据
Dissect 将单个文本字段与定义的模式进行匹配。剖析模式由要丢弃的字符串部分定义。特别注意字符串的每个部分有助于构建成功的 dissect 模式。
如果你不需要正则表达式的强大功能,请使用剖析模式而不是 grok。Dissect 使用的语法比 grok 简单得多,而且通常总体上速度更快。dissect 的语法是透明的:告诉 dissect 你想要什么,它就会将这些结果返回给你。
Dissect 模式
Dissect 模式由变量和分隔符组成。任何由百分号和花括号 %{} 定义的内容都被视为变量,例如 %{clientip}。你可以将变量分配给字段中任何部分的数据,然后仅返回所需的部分。分隔符是变量之间的任何值,可以是空格、破折号或其他分隔符。
例如,假设你有一个日志数据,其中的 message 字段如下所示:
"message" : "247.37.0.0 - - [30/Apr/2020:14:31:22 -0500] \"GET /images/hm_nbg.jpg HTTP/1.0\" 304 0"你将变量分配给数据的每个部分以构建成功的 dissect 模式。请记住,告诉剖析你想要匹配的内容。
数据的第一部分看起来像一个 IP 地址,因此你可以分配一个变量,例如 %{clientip}。接下来的两个字符是破折号,两边各有一个空格。你可以为每个破折号分配一个变量,或者分配一个变量来表示破折号和空格。接下来是一组包含时间戳的括号。括号是分隔符,因此你可以将它们包含在剖析模式中。到目前为止,数据和匹配的剖析模式如下所示:
247.37.0.0 - - [30/Apr/2020:14:31:22 -0500] #1
%{clientip} %{ident} %{auth} [%{@timestamp}] #2- message 字段中的第一个数据块
- dissect 模式以匹配所选数据块
使用相同的逻辑,你可以为剩余的数据块创建变量。双引号是分隔符,因此请将其包含在你的 dissect 模式中。该模式用 %{verb} 变量替换 GET,但将 HTTP 保留为模式的一部分。
\"GET /images/hm_nbg.jpg HTTP/1.0\" 304 0
"%{verb} %{request} HTTP/%{httpversion}" %{response} %{size}将这两种模式结合起来会得到如下所示的 dissect 模式:
%{clientip} %{ident} %{auth} [%{@timestamp}] \"%{verb} %{request} HTTP/%{httpversion}\" %{status} %{size}现在您有了 dissect 模式,如何测试和使用它?
使用 Painless 测试 dissect 模式
你可以将 dissect 模式合并到 Painless 脚本中以提取数据。要测试你的脚本,请使用 Painless execute API 的 field contexts 或创建包含脚本的运行时字段。运行时字段提供了更大的灵活性并接受多个文档,但如果你在测试脚本的集群上没有写入权限,则 Painless execute API 是一个不错的选择。
例如,通过包含 Painless 脚本和与你的数据匹配的单个文档,使用 Painless execute API 测试你的剖析模式。首先将消息字段索引为 wildcard 数据类型:
PUT my-index
{
"mappings": {
"properties": {
"message": {
"type": "wildcard"
}
}
}
}如果要检索 HTTP 响应代码,请将你的解析模式添加到提取响应值的 Painless 脚本中。要从字段中提取值,请使用此函数:
`.extract(doc["<field_name>"].value)?.<field_value>`在此示例中,message 是 <field_name>,response 是 <field_value>:
POST /_scripts/painless/_execute
{
"script": {
"source": """
String response=dissect('%{clientip} %{ident} %{auth} [%{@timestamp}] "%{verb} %{request} HTTP/%{httpversion}" %{response} %{size}').extract(doc["message"].value)?.response;
if (response != null) emit(Integer.parseInt(response)); //1
"""
},
"context": "long_field", //2
"context_setup": {
"index": "my-index",
"document": { //3
"message": """247.37.0.0 - - [30/Apr/2020:14:31:22 -0500] "GET /images/hm_nbg.jpg HTTP/1.0" 304 0"""
}
}
}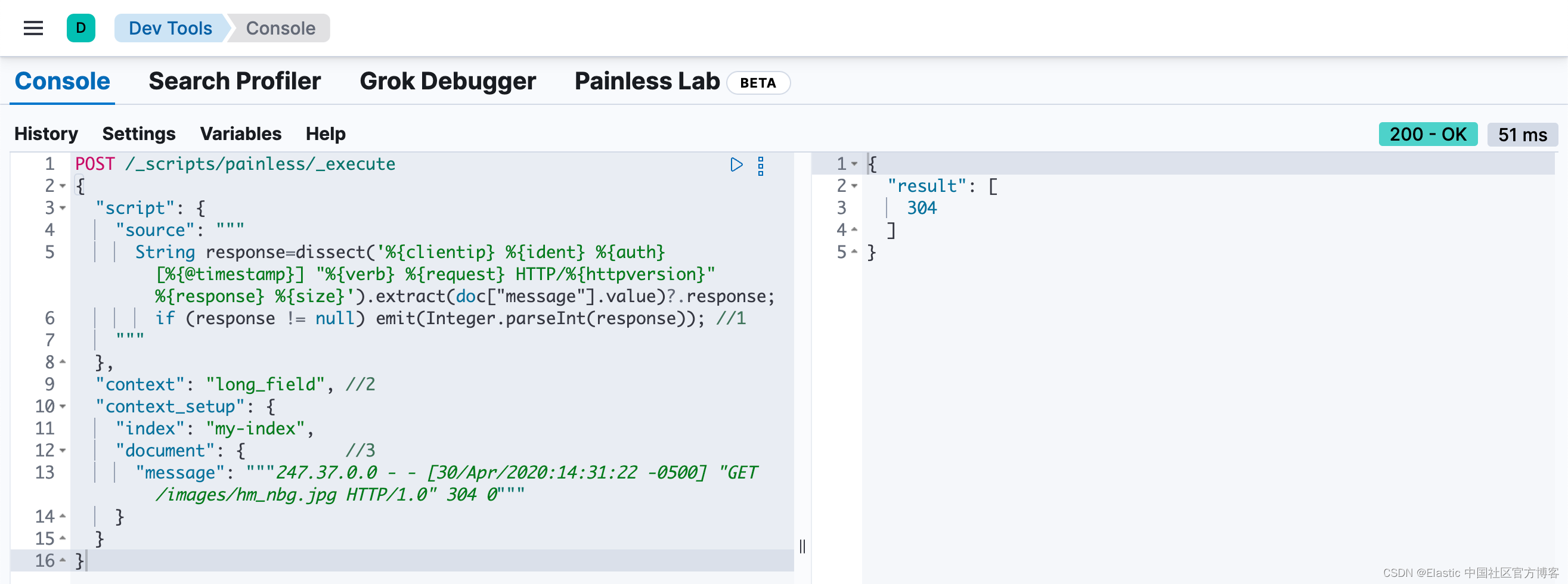
- 运行时字段需要 emit 方法才能返回值。
- 由于响应代码是整数,因此请使用 long_field 上下文。
- 包含与你的数据匹配的示例文档。
在运行时字段中使用 dissect 模式和脚本
如果你有一个功能性 dissect 模式,则可以将其添加到运行时字段以操作数据。由于运行时字段不需要你索引字段,因此你可以非常灵活地修改脚本及其功能。如果你已经使用 Painless exectute API 测试了 dissect 模式,则可以在运行时字段中使用该 Painless 脚本。
首先,像上一节一样将 message 字段添加为 wildcard 类型,但也要添加 @timestamp 作为日期,以防你想在其他用例中对该字段进行操作:
DELETE my-index
PUT /my-index/
{
"mappings": {
"properties": {
"@timestamp": {
"format": "strict_date_optional_time||epoch_second",
"type": "date"
},
"message": {
"type": "wildcard"
}
}
}
}如果你想使用 dissect 模式提取 HTTP 响应代码,你可以创建一个运行时字段,如 http.response:
PUT my-index/_mappings
{
"runtime": {
"http.response": {
"type": "long",
"script": """
String response=dissect('%{clientip} %{ident} %{auth} [%{@timestamp}] "%{verb} %{request} HTTP/%{httpversion}" %{response} %{size}').extract(doc["message"].value)?.response;
if (response != null) emit(Integer.parseInt(response));
"""
}
}
}映射要检索的字段后,将日志数据中的几条记录索引到 Elasticsearch 中。以下请求使用 bulk API将原始日志数据索引到 my-index 中:
POST /my-index/_bulk?refresh=true
{"index":{}}
{"timestamp":"2020-04-30T14:30:17-05:00","message":"40.135.0.0 - - [30/Apr/2020:14:30:17 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"}
{"index":{}}
{"timestamp":"2020-04-30T14:30:53-05:00","message":"232.0.0.0 - - [30/Apr/2020:14:30:53 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"}
{"index":{}}
{"timestamp":"2020-04-30T14:31:12-05:00","message":"26.1.0.0 - - [30/Apr/2020:14:31:12 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"}
{"index":{}}
{"timestamp":"2020-04-30T14:31:19-05:00","message":"247.37.0.0 - - [30/Apr/2020:14:31:19 -0500] \"GET /french/splash_inet.html HTTP/1.0\" 200 3781"}
{"index":{}}
{"timestamp":"2020-04-30T14:31:22-05:00","message":"247.37.0.0 - - [30/Apr/2020:14:31:22 -0500] \"GET /images/hm_nbg.jpg HTTP/1.0\" 304 0"}
{"index":{}}
{"timestamp":"2020-04-30T14:31:27-05:00","message":"252.0.0.0 - - [30/Apr/2020:14:31:27 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"}
{"index":{}}
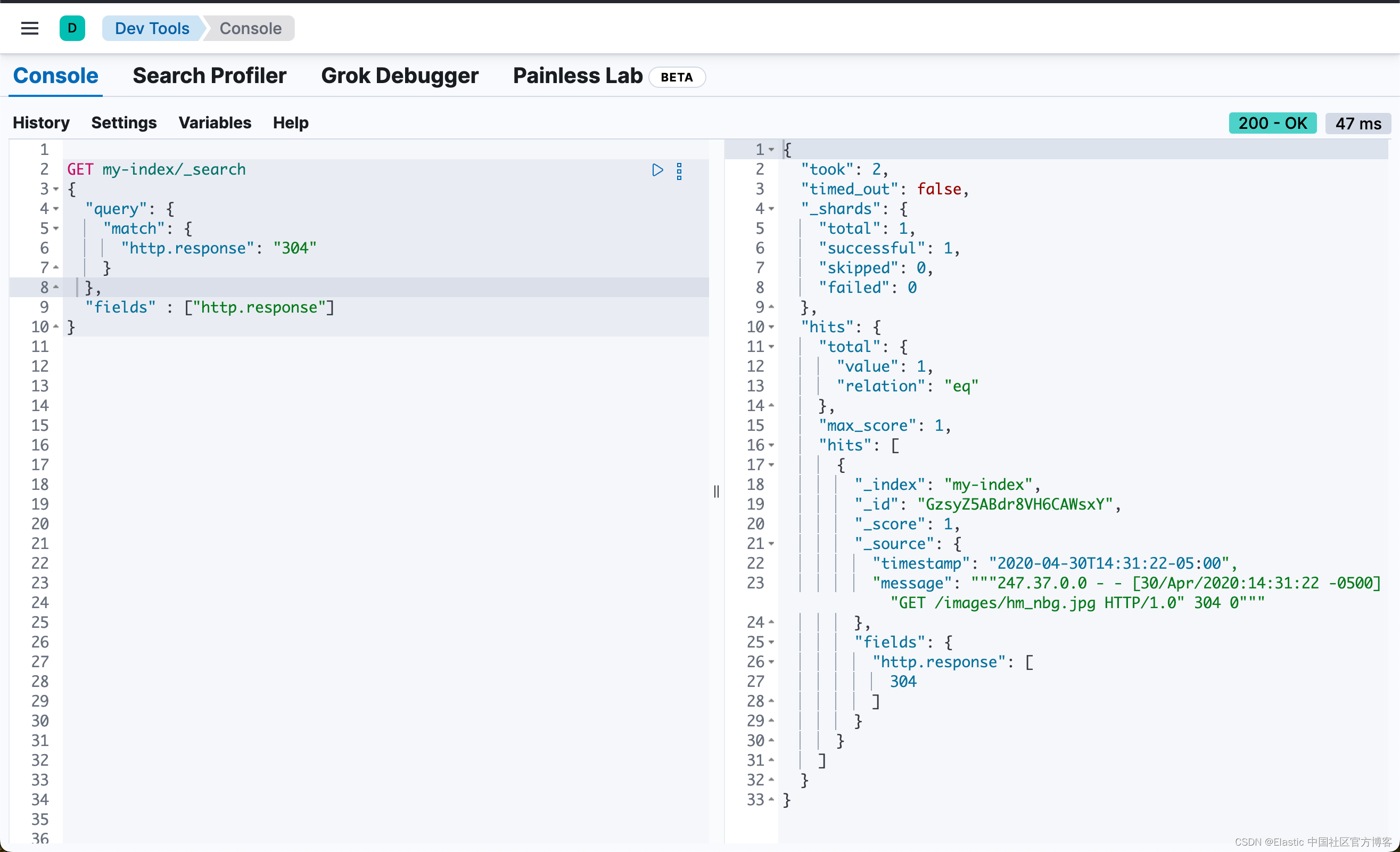
{"timestamp":"2020-04-30T14:31:28-05:00","message":"not a valid apache log"}你可以定义一个简单的查询来搜索特定的 HTTP 响应并返回所有相关字段。使用 search API 的 fields 参数来检索 http.response 运行时字段。
GET my-index/_search
{
"query": {
"match": {
"http.response": "304"
}
},
"fields" : ["http.response"]
}
或者,你可以在搜索请求的上下文中定义相同的运行时字段。运行时定义和脚本与先前在索引映射中定义的完全相同。只需将该定义复制到搜索请求的 "runtime_mappings" 部分下,并包含与运行时字段匹配的查询即可。此查询返回的结果与先前在索引映射中为 http.response 运行时字段定义的搜索查询相同,但仅限于此特定搜索的上下文:
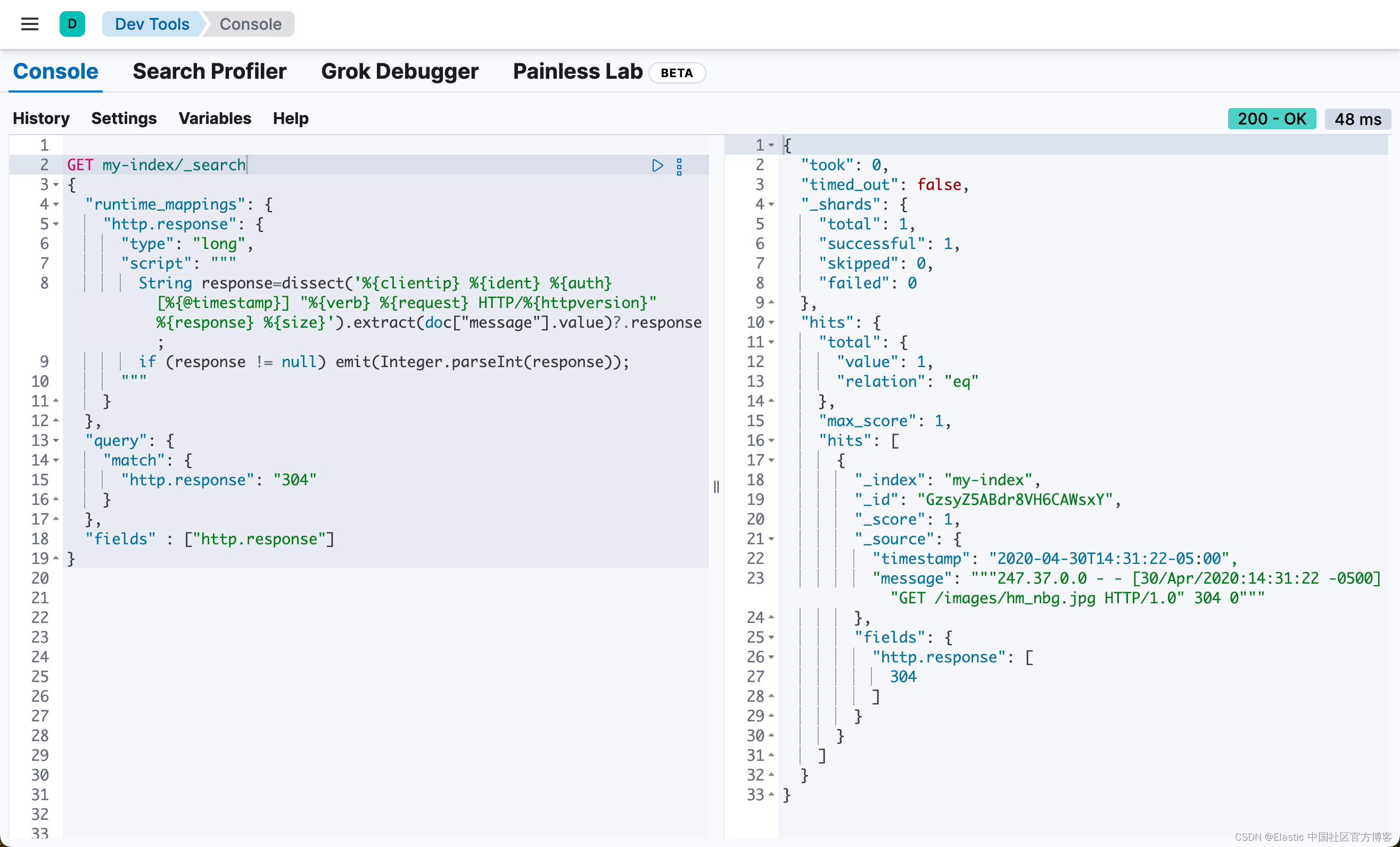
GET my-index/_search
{
"runtime_mappings": {
"http.response": {
"type": "long",
"script": """
String response=dissect('%{clientip} %{ident} %{auth} [%{@timestamp}] "%{verb} %{request} HTTP/%{httpversion}" %{response} %{size}').extract(doc["message"].value)?.response;
if (response != null) emit(Integer.parseInt(response));
"""
}
},
"query": {
"match": {
"http.response": "304"
}
},
"fields" : ["http.response"]
}
Grokking grok
Grok 是一种支持可重复使用别名表达式的正则表达式方言。Grok 非常适合处理 syslog 日志、Apache 和其他 Web 服务器日志、mysql 日志以及通常为人类而非计算机使用而编写的任何日志格式。
Grok 位于 Oniguruma 正则表达式库之上,因此任何正则表达式在 grok 中都是有效的。Grok 使用这种正则表达式语言来命名现有模式并将它们组合成与你的字段匹配的更复杂的模式。
Grok 模式
Elastic Stack 附带许多预定义的 grok 模式,可简化 grok 的使用。重复使用 grok 模式的语法采用以下形式之一:
%{SYNTAX} %{SYNTAX:ID} %{SYNTAX:ID:TYPE}
| 条目 | 描述 |
|---|---|
| SYNTAX | 将与你的文本匹配的模式的名称。例如,NUMBER 和 IP 都是默认模式集中提供的模式。NUMBER 模式匹配 3.44 之类的数据,而 IP 模式匹配 55.3.244.1 之类的数据。 |
| ID | 你为匹配的文本片段指定的标识符。例如,3.44 可能是事件的持续时间,因此您可以将其称为 duration。字符串 55.3.244.1 可能标识发出请求的 client。 |
| TYPE | 你想要转换命名字段的数据类型。支持的类型包括 int、long、double、float 和 boolean。 |
例如,假设你有如下消息数据:
3.44 55.3.244.1第一个值是一个数字,后面跟着一个看起来像是 IP 地址的东西。你可以使用以下 grok 表达式匹配此文本:
%{NUMBER:duration} %{IP:client}迁移到 Elastic Common Schema (ECS)
为了简化迁移到 Elastic Common Schema (ECS) 的过程,除了现有模式之外,还提供一组新的符合 ECS 的模式。新的 ECS 模式定义捕获符合该模式的事件字段名称。
ECS 模式集包含旧集的所有模式定义,并且是直接替换。使用 ecs-compatability 设置切换模式。
新功能和增强功能将添加到符合 ECS 的文件中。旧模式可能仍会收到向后兼容的错误修复。
在 Painless 脚本中使用 grok 模式
你可以将预定义的 grok 模式合并到 Painless 脚本中以提取数据。要测试你的脚本,请使用 Painless exectute API 的 field contexts 文或创建包含脚本的运行时字段。运行时字段提供了更大的灵活性并接受多个文档,但如果你在测试脚本的集群上没有写入权限,Painless execute API 是一个不错的选择。
如果你需要帮助构建 grok 模式以匹配你的数据,请使用 Kibana 中的 Grok 调试器工具。有关 Grok 的使用,请阅读文章 "Logstash:日志解析的 Grok 模式示例"。
例如,如果你正在处理 Apache 日志数据,则可以使用 %{COMMONAPACHELOG} 语法,该语法可以理解 Apache 日志的结构。示例文档可能如下所示:
"timestamp":"2020-04-30T14:30:17-05:00","message":"40.135.0.0 - -
[30/Apr/2020:14:30:17 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"要从消息字段中提取 IP 地址,你可以编写一个包含 %{COMMONAPACHELOG} 语法的 Painless 脚本。你可以使用 Painless 执行 API 的 ip 字段上下文测试此脚本,但我们改用运行时字段。
根据示例文档,索引 @timestamp 和 message 字段。为了保持灵活性,请使用通配符作为 message 的字段类型:
DELETE my-index
PUT /my-index/
{
"mappings": {
"properties": {
"@timestamp": {
"format": "strict_date_optional_time||epoch_second",
"type": "date"
},
"message": {
"type": "wildcard"
}
}
}
}接下来,使用 bulk API 将一些日志数据索引到 my-index 中。
POST /my-index/_bulk?refresh
{"index":{}}
{"timestamp":"2020-04-30T14:30:17-05:00","message":"40.135.0.0 - - [30/Apr/2020:14:30:17 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"}
{"index":{}}
{"timestamp":"2020-04-30T14:30:53-05:00","message":"232.0.0.0 - - [30/Apr/2020:14:30:53 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"}
{"index":{}}
{"timestamp":"2020-04-30T14:31:12-05:00","message":"26.1.0.0 - - [30/Apr/2020:14:31:12 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"}
{"index":{}}
{"timestamp":"2020-04-30T14:31:19-05:00","message":"247.37.0.0 - - [30/Apr/2020:14:31:19 -0500] \"GET /french/splash_inet.html HTTP/1.0\" 200 3781"}
{"index":{}}
{"timestamp":"2020-04-30T14:31:22-05:00","message":"247.37.0.0 - - [30/Apr/2020:14:31:22 -0500] \"GET /images/hm_nbg.jpg HTTP/1.0\" 304 0"}
{"index":{}}
{"timestamp":"2020-04-30T14:31:27-05:00","message":"252.0.0.0 - - [30/Apr/2020:14:31:27 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"}
{"index":{}}
{"timestamp":"2020-04-30T14:31:28-05:00","message":"not a valid apache log"}在运行时字段中整合 grok 模式和脚本
现在,你可以在包含 Painless 脚本和 grok 模式的映射中定义一个运行时字段。如果模式匹配,脚本将发出匹配 IP 地址的值。如果模式不匹配(clientip != null),脚本只会返回字段值而不会崩溃。
PUT my-index/_mappings
{
"runtime": {
"http.clientip": {
"type": "ip",
"script": """
String clientip=grok('%{COMMONAPACHELOG}').extract(doc["message"].value)?.clientip;
if (clientip != null) emit(clientip);
"""
}
}
}或者,你可以在搜索请求的上下文中定义相同的运行时字段。运行时定义和脚本与之前在索引映射中定义的完全相同。只需将该定义复制到搜索请求的 "runtime_mappings" 部分下,并包含与运行时字段匹配的查询即可。此查询返回的结果与你在索引映射中为 http.clientip 运行时字段定义搜索查询的结果相同,但仅限于此特定搜索的上下文:
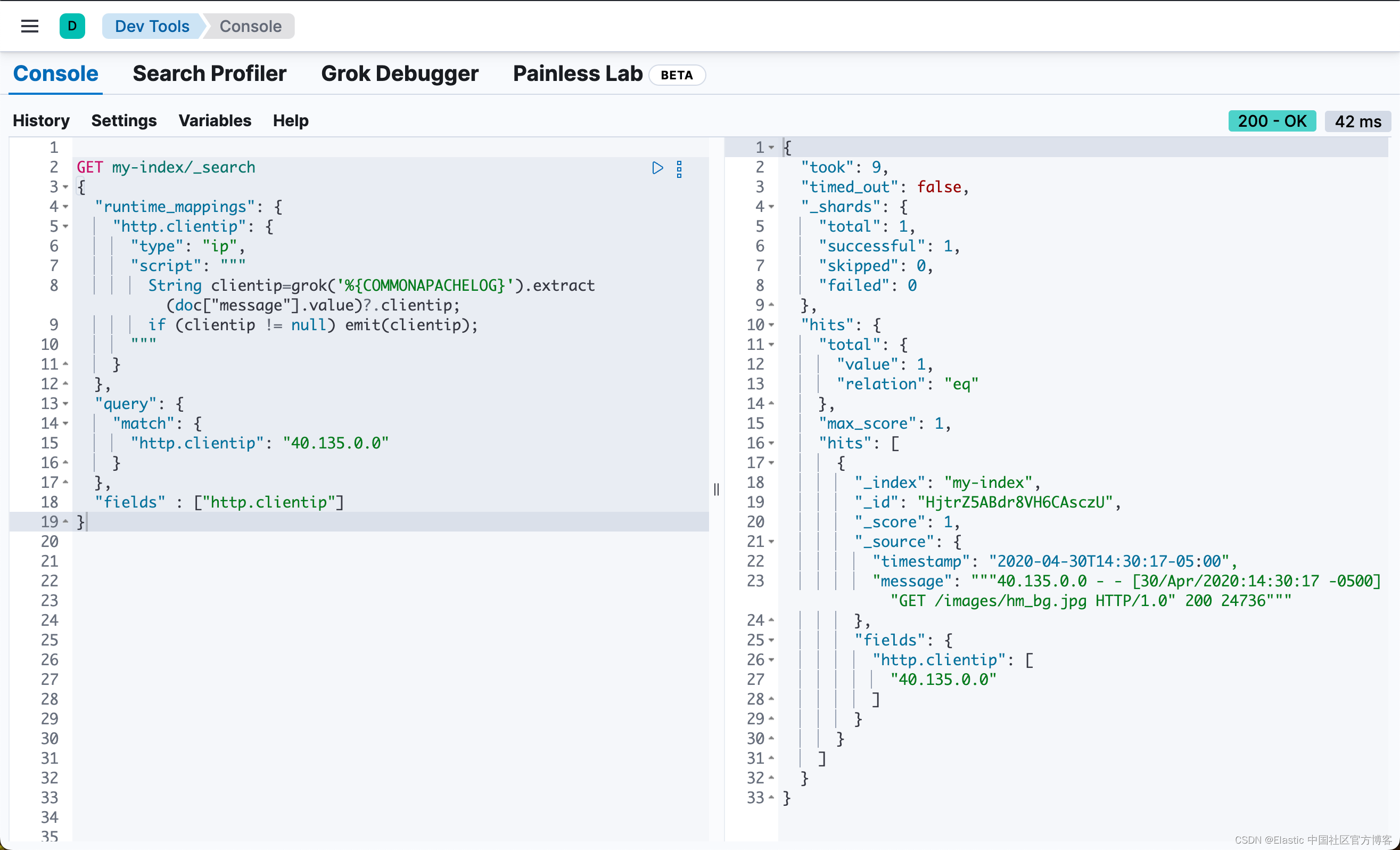
GET my-index/_search
{
"runtime_mappings": {
"http.clientip": {
"type": "ip",
"script": """
String clientip=grok('%{COMMONAPACHELOG}').extract(doc["message"].value)?.clientip;
if (clientip != null) emit(clientip);
"""
}
},
"query": {
"match": {
"http.clientip": "40.135.0.0"
}
},
"fields" : ["http.clientip"]
}
返回计算结果
使用 http.clientip 运行时字段,您可以定义一个简单的查询来搜索特定的 IP 地址并返回所有相关字段。_search API 上的 fields 参数适用于所有字段,甚至包括那些未作为原始 _source 的一部分发送的字段:
GET my-index/_search
{
"query": {
"match": {
"http.clientip": "40.135.0.0"
}
},
"fields" : ["http.clientip"]
}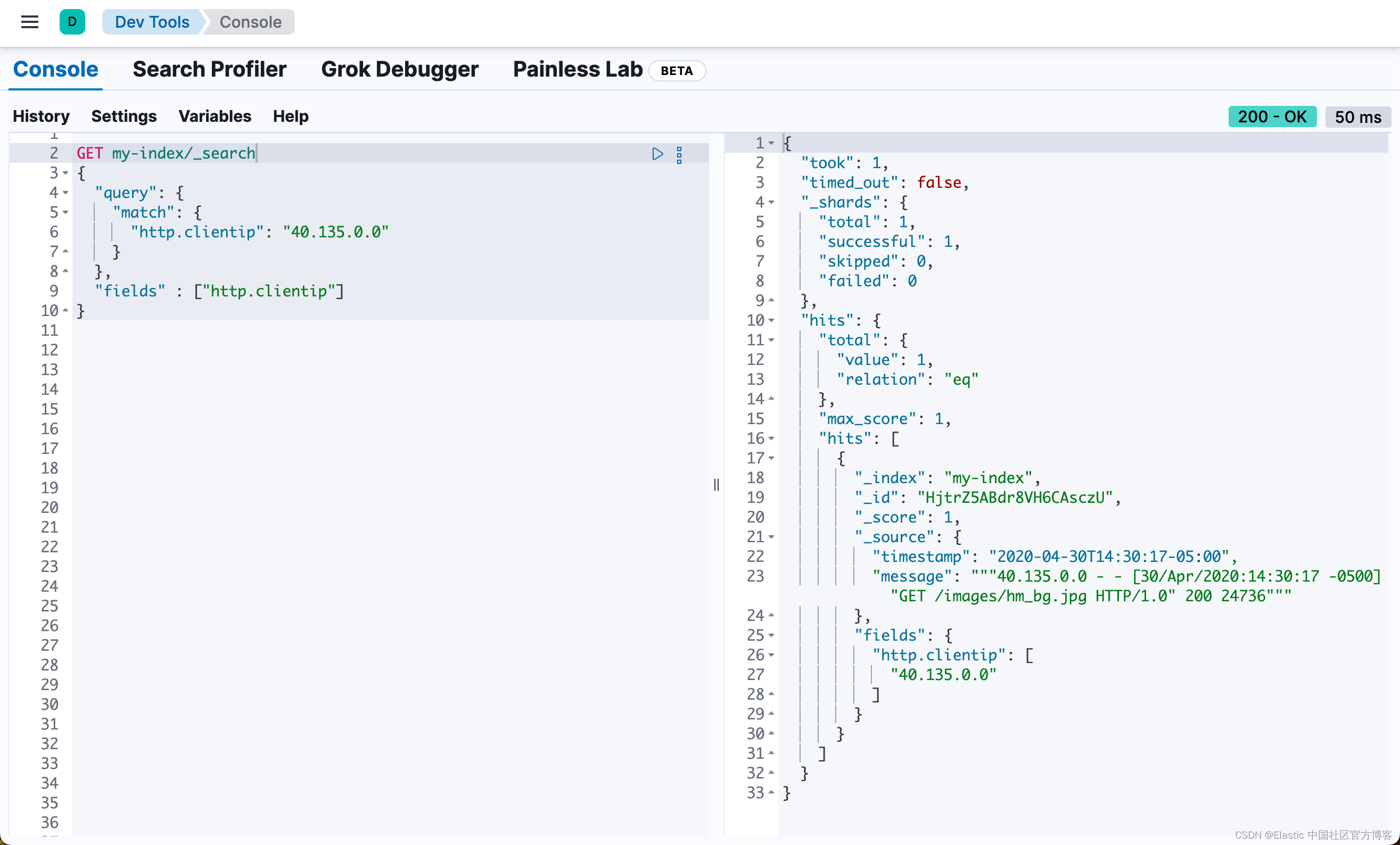
响应包含您在搜索查询中指出的特定 IP 地址。Painless 脚本中的 grok 模式在运行时从 message 字段中提取了此值。
请继续阅读文章 "Elasticsearch:Painless scripting 语言(二)"。