任务描述
任务内容为安装和配置Kafka集群。
任务指导
Kafka是大数据生态圈中常用的消息队列框架
具体安装步骤如下:
解压缩Kafka的压缩包
配置Kafka的环境变量
修改Kafka的配置文件,Kafka的配置文件存放在Kafka安装目录下的config中
验证Kafka
任务实现
1、解压Kafka
在【master1】上解压缩包
[root@master1 ~]# cd /opt/software
[root@master1 software]# tar -xzf kafka_2.12-2.4.1.tgz -C /opt/app/2、在【master1】编辑系统环境变量/etc/profile
[root@master1 ~]# vi /etc/profile在文件末尾添加如下配置
export KAFKA_HOME=/opt/app/kafka_2.12-2.4.1
export PATH=$PATH:$KAFKA_HOME/bin执行【source /etc/profile】重新加载环境变量
3、配置Kafka
为Kafka创建数据目录
[root@master1 ~]# source /etc/profile
[root@master1 ~]# cd $KAFKA_HOME
[root@master1 kafka_2.12-2.4.1]# mkdir kafka-logs然后打开config目录下的server.properties文件,修改日志目录为刚刚创建的目录:
[root@master1 kafka_2.12-2.4.1]# cd $KAFKA_HOME/config
[root@master1 config]# vi server.properties修改如下配置的值,其中broker.id的值需要保证在整个集群中是唯一的
broker.id=1
listeners=PLAINTEXT://master1:9092
log.dirs=/opt/app/kafka_2.12-2.4.1/kafka-logs
zookeeper.connect=master1:2181,slave1:2181,slave2:2181在【master1】启动Kafka的后台守护进程
[root@master1 ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties4、验证Kafka
1)创建topic,创建名为test的topic,分区数1,副本1
[root@master1 ~]# kafka-topics.sh --create --zookeeper master1:2181,slave1:2181,slave2:2181 --replication-factor 1 --partitions 1 --topic test2)查看topic的状态
[root@master1 ~]# kafka-topics.sh --describe --zookeeper master1:2181,slave1:2181,slave2:2181 --topic test3)在【master1】开启一个生产者发送消息
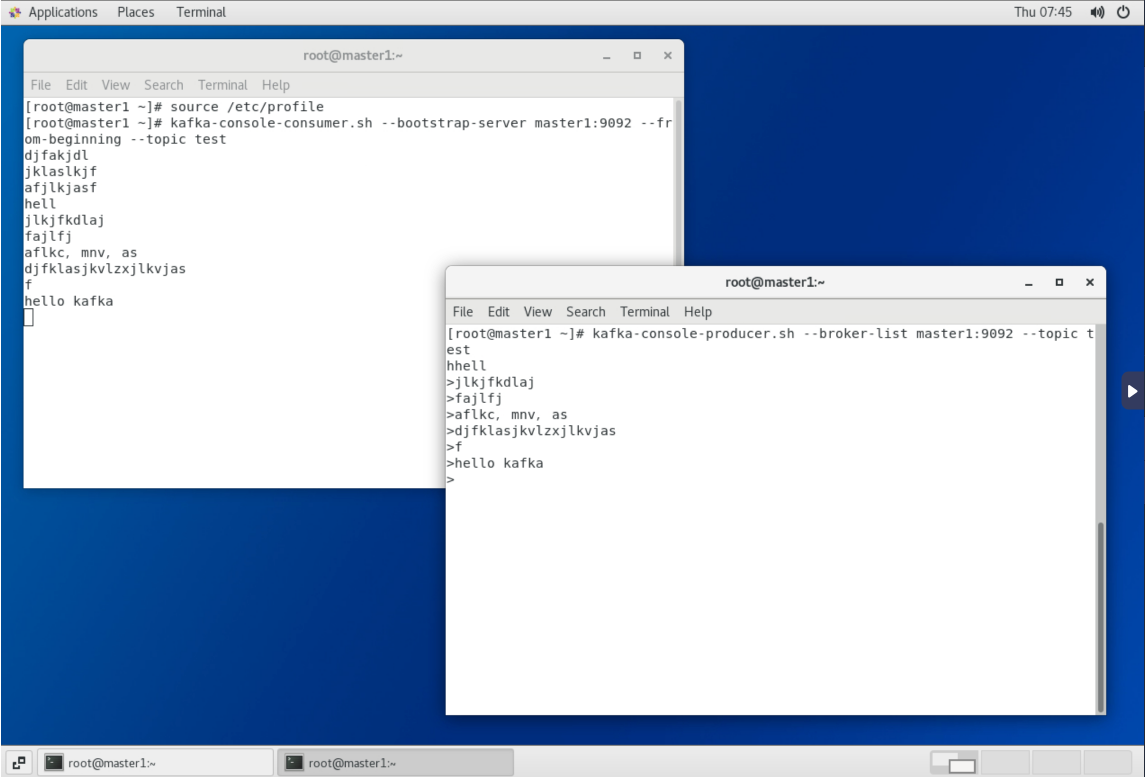
[root@master1 ~]# kafka-console-producer.sh --broker-list master1:9092 --topic test4)在【master1】再打开一个消费者消费消息
[root@master1 ~]# kafka-console-consumer.sh --bootstrap-server master1:9092 --from-beginning --topic test参数from-beginning表示从第一条消息开始读取