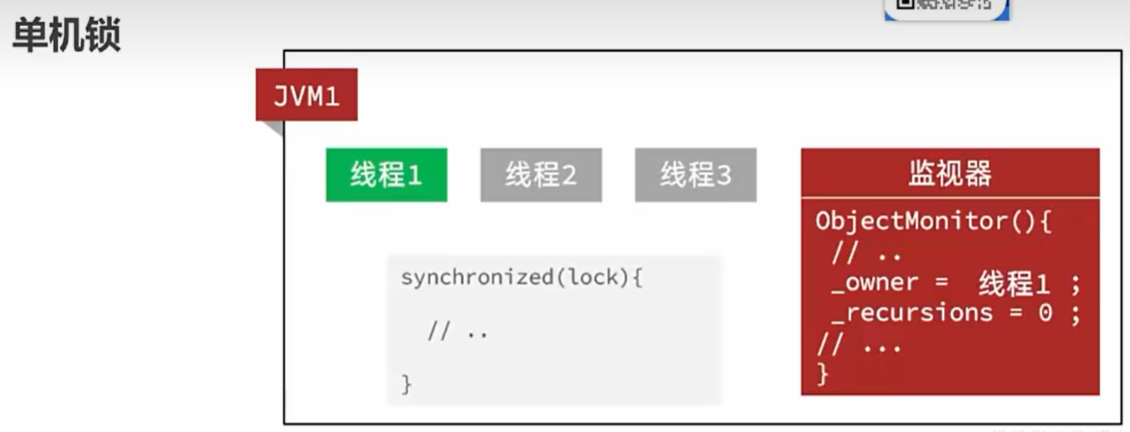
单机锁
服务器只有一个,JVM只有一个。
用synchronized加锁,对lock对象加锁,只有线程1结束,线程2,3才会开始。
再用uid避免一个线程多次进来。
分布式锁
真正上线时:
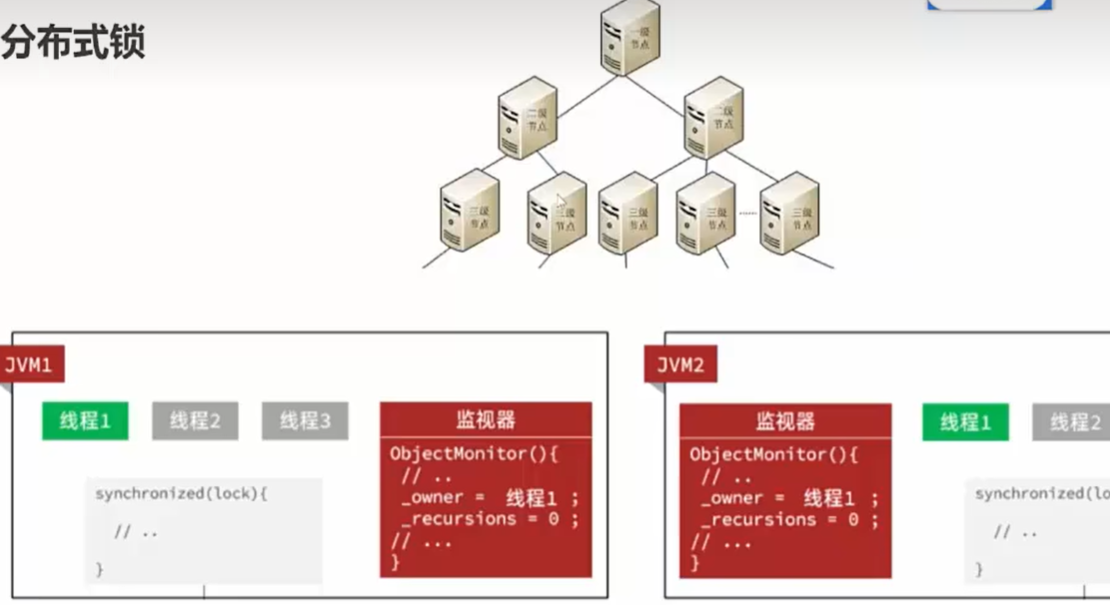 【注:这些服务器连接的是一个Redis集群(就是同一个Redis)】
【注:这些服务器连接的是一个Redis集群(就是同一个Redis)】
在一个JVM1只能锁这个服务器里的lock对象
所以用分布式锁,一个共享的锁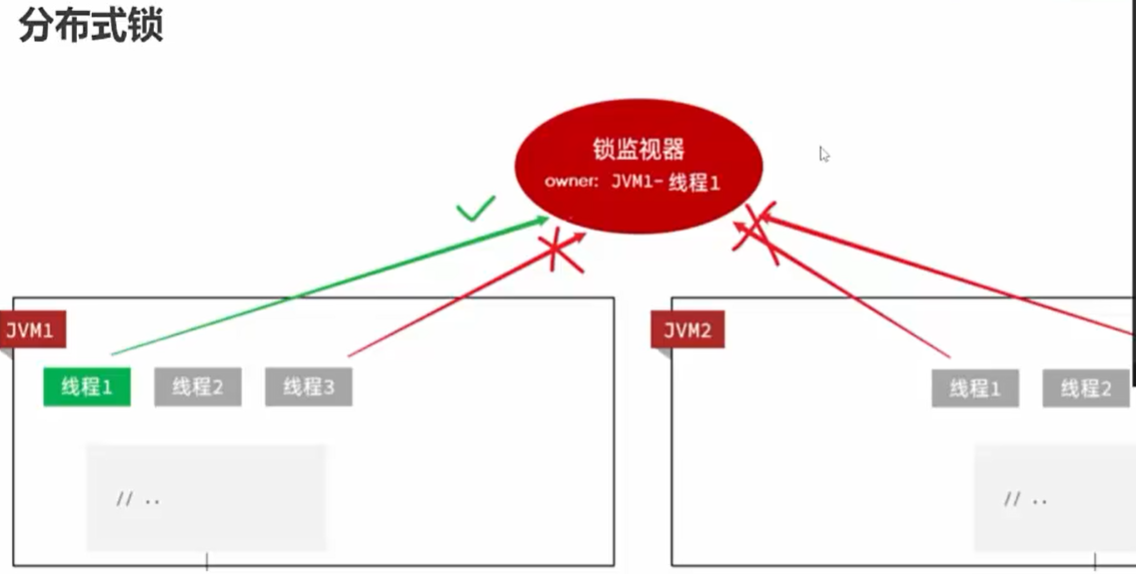
在开发应用的时候,如果需要对某一个共享变量进行多线程同步访问的时候,可以使用我们学到的锁进行处理。
为了保证一个方法或属性在高并发情况下的同一时间只能被同一个线程执行, 为了解决这个问题就需要一种跨机器的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题!
分布式锁应该具备哪些条件:
- 1、在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行;
- 2、高可用的获取锁与释放锁;
- 3、高性能的获取锁与释放锁;
- 4、具备可重入特性;
- 5、具备锁失效机制,防止死锁;
- 6、具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败。
三种方式:
- 基于数据库实现分布式锁;(很少)
- 基于缓存(Redis等)实现分布式锁; (较多)
- 基于Zookeeper实现分布式锁;
1.基于数据库的实现方式
于数据库的实现方式的核心思想是:在数据库中创建一个表,表中包含方法名等字段,并在方法名字段上创建唯一索引,想要执行某个方法,就使用这个方法名向表中插入数据,成功插入则获取锁,执行完成后删除对应的行数据释放锁。
缺点:
- 1、因为是基于数据库实现的,数据库的可用性和性能将直接影响分布式锁的可用性及性能
- 2、不具备可重入的特性,因为同一个线程在释放锁之前,行数据一直存在,无法再次成功插入数据,所以,需要在表中新增一列,用于记录当前获取到锁的机器和线程信息,在再次获取锁的时候,先查询表中机器和线程信息是否和当前机器和线程相同,若相同则直接获取锁;(没明白)
- 3、没有锁失效机制,因为有可能出现成功插入数据后,服务器宕机了,对应的数据没有被删除,当服务恢复后一直获取不到锁,所以,需要在表中新增一列,用于记录失效时间,并且需要有定时任务清除这些失效的数据;
- 4、不具备阻塞锁特性,获取不到锁直接返回失败,所以需要优化获取逻辑,循环多次去获取。
- 5、依赖数据库需要一定的资源开销,性能问题需要考虑。
2.基于Redis的实现方式
1、选用Redis实现分布式锁原因:
(1)Redis有很高的性能;
(2)Redis命令对此支持较好,实现起来比较方便
2、使用命令介绍:
(1)SETNX
SETNX key val:当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0。
(2)expire
expire key timeout:为key设置一个超时时间,单位为second,超过这个时间锁会自动释放,避免死锁。
(3)delete
delete key:删除key
在使用Redis实现分布式锁的时候,主要就会使用到这三个命令。
3、实现思想:
(1)获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
(2)获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
(3)释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
python
#连接redis
redis_client = redis.Redis(host="localhost",
port=6379,
password=password,
db=10)
#获取一个锁
lock_name:锁定名称
acquire_time: 客户端等待获取锁的时间
time_out: 锁的超时时间
def acquire_lock(lock_name, acquire_time=10, time_out=10):
"""获取一个分布式锁"""
identifier = str(uuid.uuid4())
end = time.time() + acquire_time//当前时间+获取时间=结束时间
lock = "string:lock:" + lock_name
while time.time() < end:
if redis_client.setnx(lock, identifier):#成功设置一个lock_name的锁
# 给锁设置超时时间, 防止进程崩溃导致其他进程无法获取锁
redis_client.expire(lock, time_out)#设超时间时间
return identifier
elif not redis_client.ttl(lock):#获取键的生存时间
redis_client.expire(lock, time_out)
time.sleep(0.001)
return False
#释放一个锁
def release_lock(lock_name, identifier):
"""通用的锁释放函数"""
lock = "string:lock:" + lock_name
pip = redis_client.pipeline(True)
while True:
try:
pip.watch(lock)
lock_value = redis_client.get(lock)
if not lock_value:
return True
if lock_value.decode() == identifier:
pip.multi()
pip.delete(lock)#删除锁
pip.execute()
return True
pip.unwatch()
break
except redis.excetions.WacthcError:
pass
return False为什么不用单体锁
单体应用难以满足实际高并发访问需求,会将单体应用部署到多个tomcat实例上,由负载均衡将请求分发到不同实例上。
单体锁(synchronized、ReentrantLock)是JVM层面的锁,只能控制单个实例上的并发访问安全,多实例下依然存在数据一致性问题。
分布式锁
分布式锁指的是,所有服务中的所有线程都去获取同一把锁,但只有一个线程可以成功的获得锁,其他没有获得锁的线程必须全部等待,直到持有锁的线程释放锁。
存在问题:当前线程处理完释放其他线程的锁
问题描述:假设有多个线程,锁的过期时间10s,线程1上锁后执行业务逻辑的时长超过十秒,锁到期释放锁,线程2就可以获得锁执行,此时线程1执行完删除锁,删除的就是线程2持有的锁,线程3又可以获取锁,线程2执行完删除锁,删除的是线程3的锁,如此往后,这样就会出问题。
解决办法就是让线程只能删除自己的锁,即给每个线程上的锁添加唯一标识(UUID实现),删除锁时判断这个标识。
要让删除锁具有原子性,可以利用redis事务或lua脚本实现原子操作判断+删除。(lua脚本的执行是原子的)
java
//使用Lua脚本实现
@RequestMapping(" /deduct_stock")
public String deductStock() {
String REDIS_LOCK = "good_lock";
// 每个人进来先要进行加锁,key值为"good_lock"
String value = UUID.randomUUID().toString().replace("-","");
try{
// 为key加一个过期时间
Boolean flag = template.opsForValue().setIfAbsent(REDIS_LOCK, value,10L,TimeUnit.SECONDS);
// 加锁失败
if(!flag){
return "抢锁失败!";
}
System.out.println( value+ " 抢锁成功");
String result = template.opsForValue().get("goods:001");
int total = result == null ? 0 : Integer.parseInt(result);
if (total > 0) {
// 如果在此处需要调用其他微服务,处理时间较长。。。
int realTotal = total - 1;
template.opsForValue().set("goods:001", String.valueOf(realTotal));
System.out.println("购买商品成功,库存还剩:" + realTotal + "件, 服务端口为8002");
return "购买商品成功,库存还剩:" + realTotal + "件, 服务端口为8002";
} else {
System.out.println("购买商品失败,服务端口为8002");
}
return "购买商品失败,服务端口为8002";
}finally {
// 谁加的锁,谁才能删除
// 也可以使用redis事务
// https://redis.io/commands/set
// 使用Lua脚本,进行锁的删除
Jedis jedis = null;
try{
jedis = RedisUtils.getJedis();
//lua脚本命令:
String script = "if redis.call('get',KEYS[1]) == ARGV[1] " +
"then " +
"return redis.call('del',KEYS[1]) " +
"else " +
" return 0 " +
"end";
Object eval = jedis.eval(script, Collections.singletonList(REDIS_LOCK), Collections.singletonList(value));
if("1".equals(eval.toString())){
System.out.println("-----del redis lock ok....");
}else{
System.out.println("-----del redis lock error ....");
}
}catch (Exception e){
}finally {
if(null != jedis){
jedis.close();
}
}
}
}
}使用Redisson简化操作
Redis提供的Redisson组件实现Redis锁。
Redisson原理:
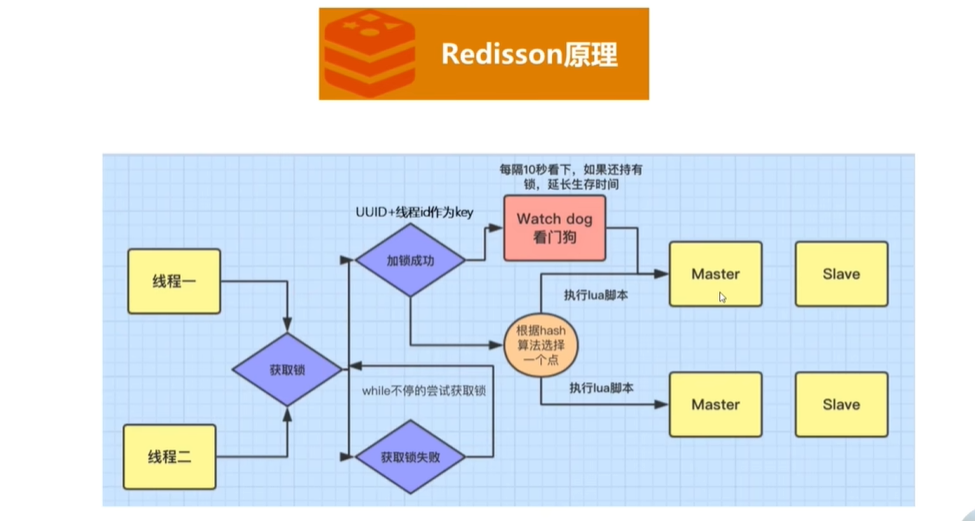
这里UUID+线程ID应该是VALUE, KEY是商品ID
线程去获取锁,锁的VALUE是UUID+线程ID来保证锁和当前形成绑定怒会释放其他线程的锁
当前线程获取锁成功开始处理业务时,内部会有watch dog看门狗,每隔10s看当前线程是否还持有锁,如果持有则给锁延长生存时间。
Redission执行流程如下:(只要线程一加锁成功,就会启动一个watch dog看门狗,它是一个后台线程,会每隔10秒检查一下(锁续命周期就是设置的超时时间的三分之一),如果线程还持有锁,就会不断的延长锁key的生存时间。因此,Redis就是使用Redisson解决了锁过期释放,业务没执行完问题。当业务执行完,释放锁后,再关闭守护线程,
RedLock解决Redis集群主从不同步数据丢失问题
Redisson使用主从集群模式,主节点挂掉,从节点没有同步到锁的情况:
使用RedLock,针对Redis中所有节点来进行同步,能够保证超过半数的Redis加锁了才算加锁成功,从而保证并发安全。
用户限流,防止同一用户多次秒杀
使用布隆过滤器记录用户和商品ID 来解决。
当用户参与秒杀时,判断是否ID是否记录存在布隆过滤器中,不存在证明该用户是第一次参与秒杀改商品,放行继续后续业务;
过滤器中存在,则禁止继续秒杀。
java
import cn.hutool.bloomfilter.BitMapBloomFilter;
import com.alibaba.fastjson.JSON;
import org.springframework.amqp.core.MessageProperties;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.web.bind.annotation.CrossOrigin;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import javax.servlet.http.HttpServletResponse;
import java.util.Map;
import java.util.UUID;
@RestController
@CrossOrigin //开启跨域支持
public class SpikeController {
@Autowired
private RabbitTemplate rabbitTemplate;
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private BitMapBloomFilter bitMapBloomFilter;
@GetMapping("spike/{userId}/{goodsId}")
public Object doSpike(@PathVariable Integer userId
, @PathVariable Integer goodsId, HttpServletResponse response) {
//设置商品的唯一标识
String spikeId = userId + "-" + goodsId;
//判断是否已经参与过
if (bitMapBloomFilter.contains(spikeId)) {
return "你已参加过秒杀活动,请选择其他秒杀商品";
}
//判断库存
Long stoke = Long.parseLong(redisTemplate.opsForValue().get(goodsId + "stock"));
if (stoke < 1) {
return "该商品已被抢购一空,请选择其他商品";
}
//参与过秒杀,添加到过滤器中
bitMapBloomFilter.add(spikeId);
//封装发送信息
Map<String, Integer> spikeMessage = Map.of("userId", userId, "goodsId", goodsId);
//发送消息
rabbitTemplate.convertAndSend("", "spike-web", JSON.toJSONString(spikeMessage), message -> {
MessageProperties messageProperties = message.getMessageProperties();
String messageId = UUID.randomUUID().toString().replaceAll("-", "");
messageProperties.setMessageId(messageId);
return message;
});
return "正在拼命抢购中,请稍后查看订单详情...";
}
}3.基于ZooKeeper的实现方式
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。
基于ZooKeeper实现分布式锁的步骤如下:
(1)创建一个目录mylock;
(2)线程A想获取锁就在mylock目录下创建临时顺序节点;
(3)获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁;
(4)线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点;
(5)线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
优点:具备高可用、可重入、阻塞锁特性,可解决失效死锁问题。
缺点:因为需要频繁的创建和删除节点,性能上不如Redis方式。