人工智能-NLP简单知识汇总01
1.1自然语言处理的基本概念
自然语言处理难点:
- 语音歧义
- 句子切分歧义
- 词义歧义
- 结构歧义
- 代指歧义
- 省略歧义
- 语用歧义
总而言之:!!语言无处不歧义
1.2自然语言处理的基本范式
1.2.1基于规则的方法
通过词汇、形式文法等制定的规则引入语言学知识,从而完成相应的自然语言处理任务
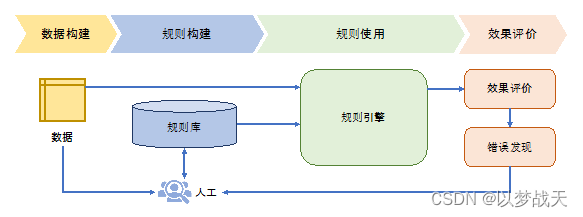
对于机器翻译任务可以构造如下规则库:
if 汉语主语=我 then 英语主语 = I
if 英语主语=I then 英语 be动词 = am/was
if 汉语 = 苹果 and 没有修饰量词 then 英语 = apples就是基于固定规则,优缺点显而易见
1.2.2基于机器学习的方法
将自然语言处理任务转化为某种分类任务
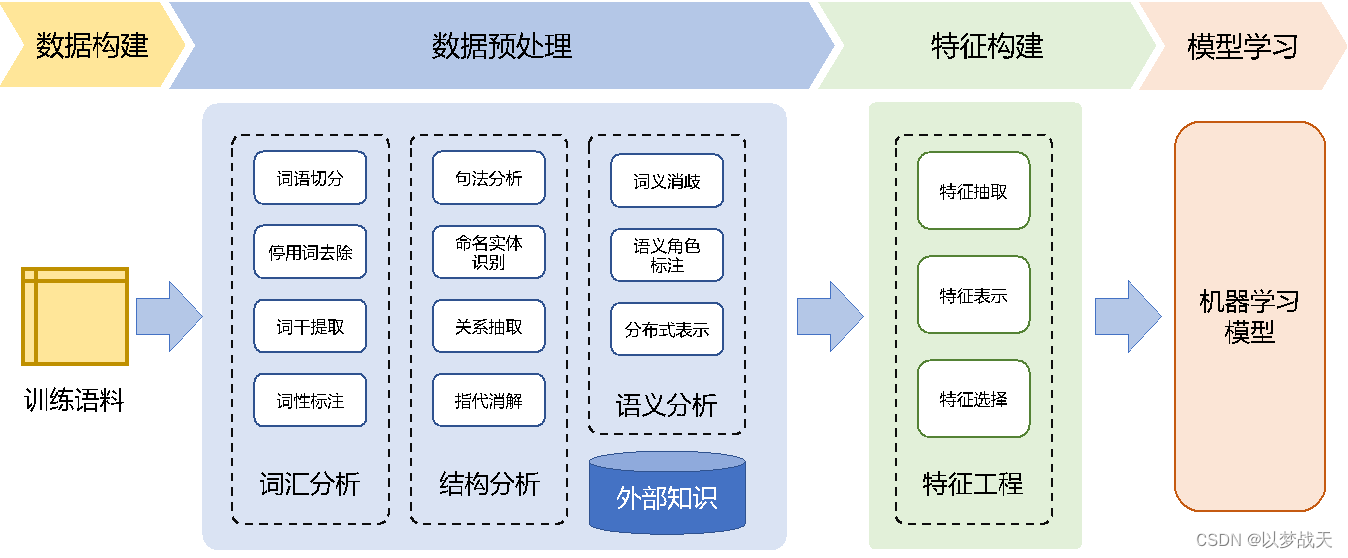
-
数据构建既是构建语料库(Corpus)
-
数据预处理既是简单的数据处理划分。
-
特征构建阶段是提取对于机器学习模型有用的特征。
-
模型学习阶段既是选择合适的机器学习模型,确定学习准则,训练模型参数。
需要人工处理的特别多
1.2.3基于深度学习的方法
将特征学习和预测模型融合,通过优化算法使得模型自动地学习出好的特征表示,并基于此进行结果预测
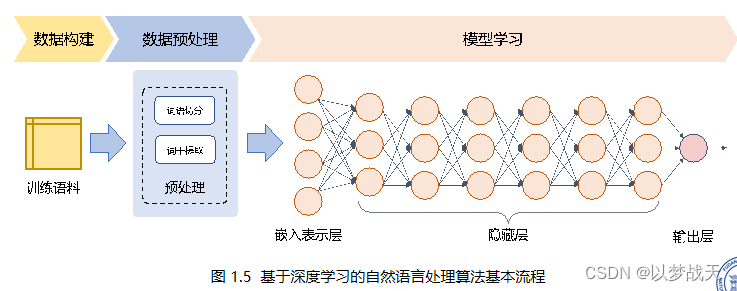
- 数据预处理简单
- 通过多层特征转换,将原始数据转换为更加抽象的表示。可以在一定程度上完全代替人工设计的特征。也称为:表示学习。
- 利用自监督任务进行预处理,通过海量的数据得到更加通用语言表示,根据下游任务进行网络调整。
1.2.4基于大模型的方法
将大量各类型自然语言处理任务,统一为生成式自然语言理解框架
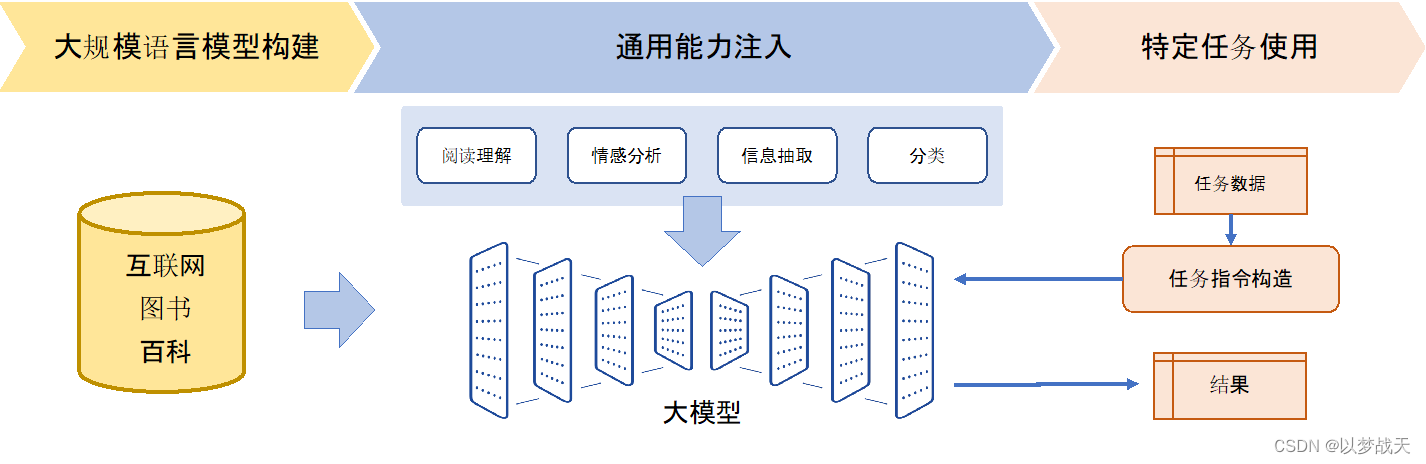
- 在大规模语言模型构建阶段,通过大量的文本内容,训练模型长文本的建模能力,使得模型具有语言生成能力,并使得模型获得隐式的世界知识。
- 在通用能力注入阶段,利用包括阅读理解、情感分析、信息抽取等现有任务的标注数据,结合人工设计的指令词对模型进行多任务训练,从而使得模型具有很好的任务泛化能力。
- 特定任务使用阶段则变得非常简单,由于模型具备了通用任务能力,只需要根据任务需求设计任务指令,将任务中所需处理的文本内容与指令结合,然后就可以利用大模型得到所需结果。