章节内容
上一节我们完成了:
- Reduce JOIN 的介绍
- Reduce JOIN 的具体实现
- Driver
- Mapper
- Reducer
- 运行测试
背景介绍
这里是三台公网云服务器,每台 2C4G,搭建一个Hadoop的学习环境,供我学习。
之前已经在 VM 虚拟机上搭建过一次,但是没留下笔记,这次趁着前几天薅羊毛的3台机器,赶紧尝试在公网上搭建体验一下。
注意,如果你和我一样,打算用公网部署,那一定要做好防火墙策略,避免不必要的麻烦!!!
请大家都以学习为目的,也请不要对我的服务进行嗅探或者攻击!!!
但是有一台公网服务器我还运行着别的服务,比如前几天发的:autodl-keeper 自己写的小工具,防止AutoDL机器过期的。还跑着别的Web服务,所以只能挤出一台 2C2G 的机器。那我的配置如下了:
- 2C4G 编号 h121
- 2C4G 编号 h122
- 2C2G 编号 h123

Hive简介
Hive 是基于 Hadoop的一个数据仓库,可以将结构化的数据文件映射为一张表,类似于RDBMS中的表,并提供SQL查询的功能,Hive是由FaceBook开源,用于解决海量结构化日志的数据统计。
- Hive本质:将SQL转换为MapReduce任务进行执行
- 底层是由HDFS来提供支持的
- Hive对数据更新不友好,主要是读多写少的

Hive优点
- 学习成本低,类似于 SQL 语言
- 可处理海量数据,底层有 MapReduce 支持
- 可水平扩展,基于 Hadoop
- 支持自定义函数
- 良好的容错性,某个节点错误后,HQL 仍然可以正常运行
- 统一的元数据管理:表、字段、类型 等等
Hive缺点
- HQL 表达能力有限
- 迭代计算无法表达
- Hive 执行效率不高
- 自动生成的MR程序 有些不够智能
- Hive调优困难
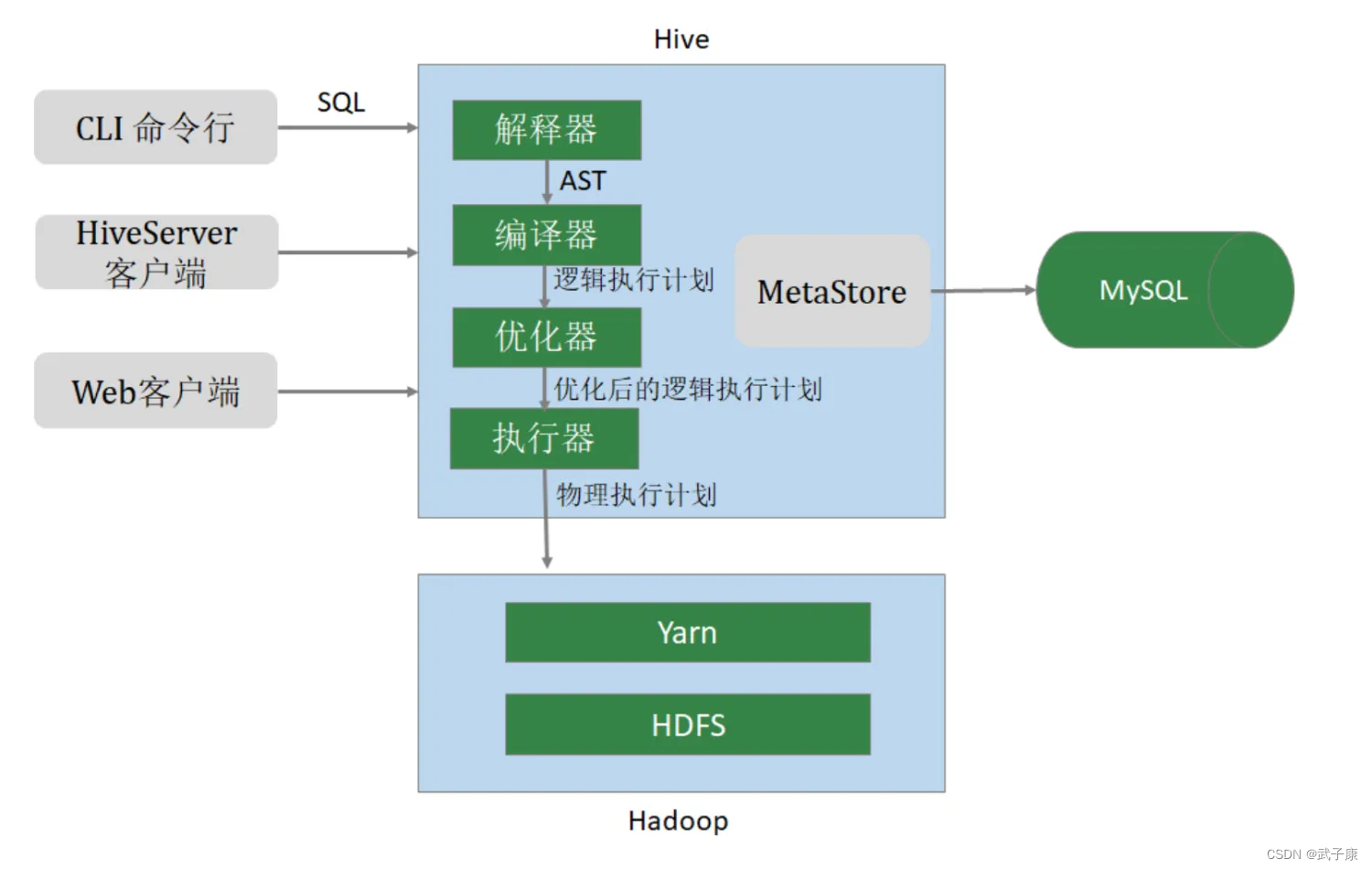
Hive架构
安装配置
前置要求
- 三台Hadoop集群
- Hive下载安装
- MySQL 或者 MariaDB
下载Hive
https://archive.apache.org/dist/hive/hive-2.3.9/
当前我计划,把 Hive 安装到 h122 节点上。122空闲比较多。
shell
cd /opt/software使用wget下载
shell
wget -O apache-hive-2.3.9-bin.tar.gz https://archive.apache.org/dist/hive/hive-2.3.9/apache-hive-2.3.9-bin.tar.gz
解压移动
shell
cd /opt/software
tar zxvf apache-hive-2.3.9-bin.tar.gz -C ../servers/
cd ../servers
ls
环境变量
shell
vim /etc/profile在环境变量中,加入如下内容
shell
# hive
export HIVE_HOME=/opt/servers/apache-hive-2.3.9-bin
export PATH=$PATH:$HIVE_HOME/bin填写内容如下:

刷新环境变量
shell
source /etc/profile修改配置
shell
cd $HIVE_HOME/conf
修改 hive-site.xml
shell
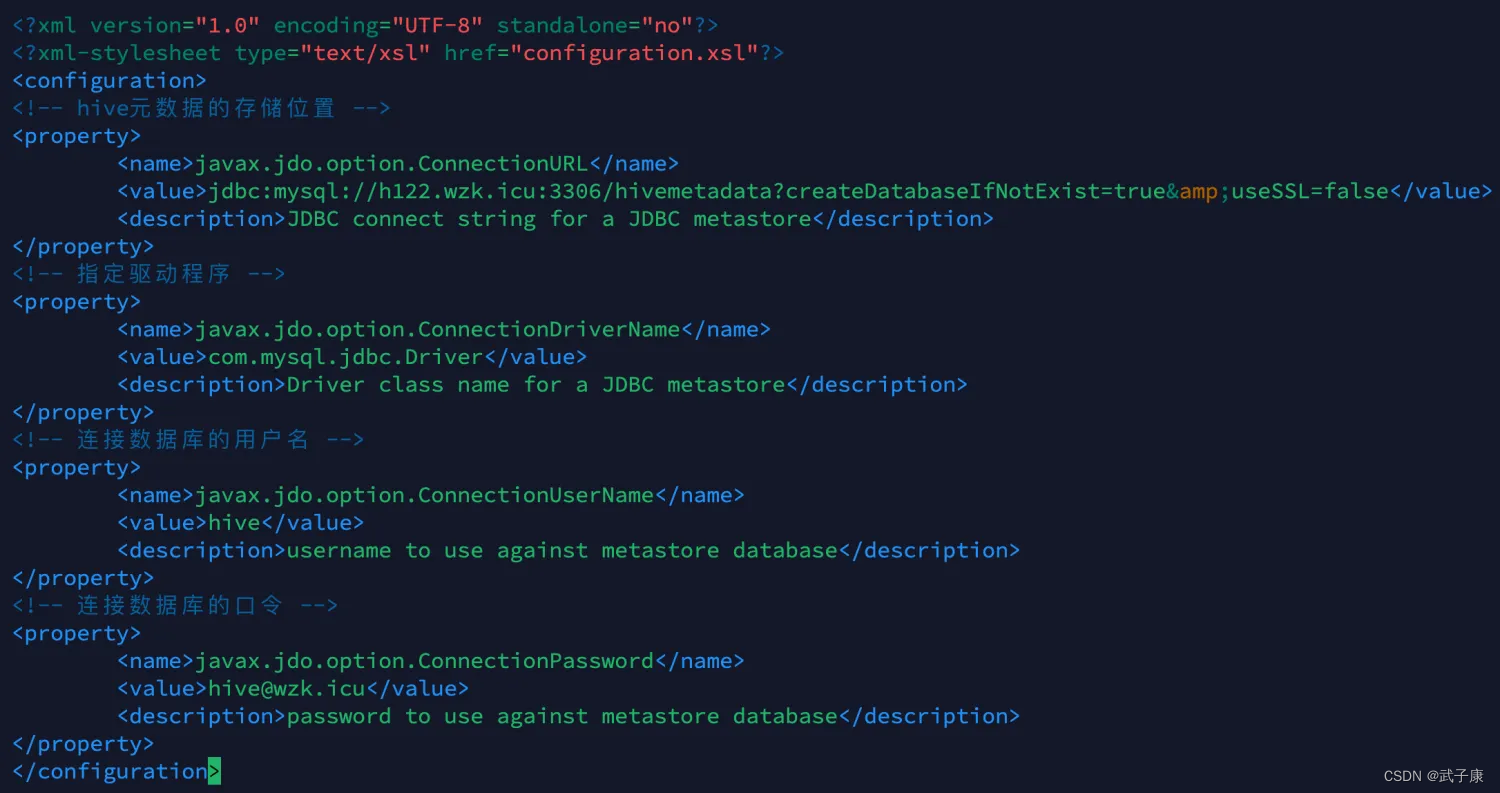
vim hive-site.xml注意如下配置,应该按照实际情况,修改成你的。
xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- hive元数据的存储位置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://h122.wzk.icu:3306/hivemetadata?createDatabaseIfNotExist=true&useSSL=false</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<!-- 指定驱动程序 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!-- 连接数据库的用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<!-- 连接数据库的口令 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive@wzk.icu</value>
<description>password to use against metastore database</description>
</property>
</configuration>填写的结果如下图:
MariaDB
直接安装
当前我是 Ubuntu 的机器,可以直接安装:
shell
sudo apt install mariadb-server
启动服务
shell
sudo systemctl start mariadb安全配置
shell
sudo mysql_secure_installation
建立用户
进入数据库,执行如下的指令。
sql
CREATE USER 'hive'@'%' IDENTIFIED BY '你的密码';
GRANT ALL ON *.* TO 'hive'@'%';
FLUSH PRIVILEGES;查询执行的结果
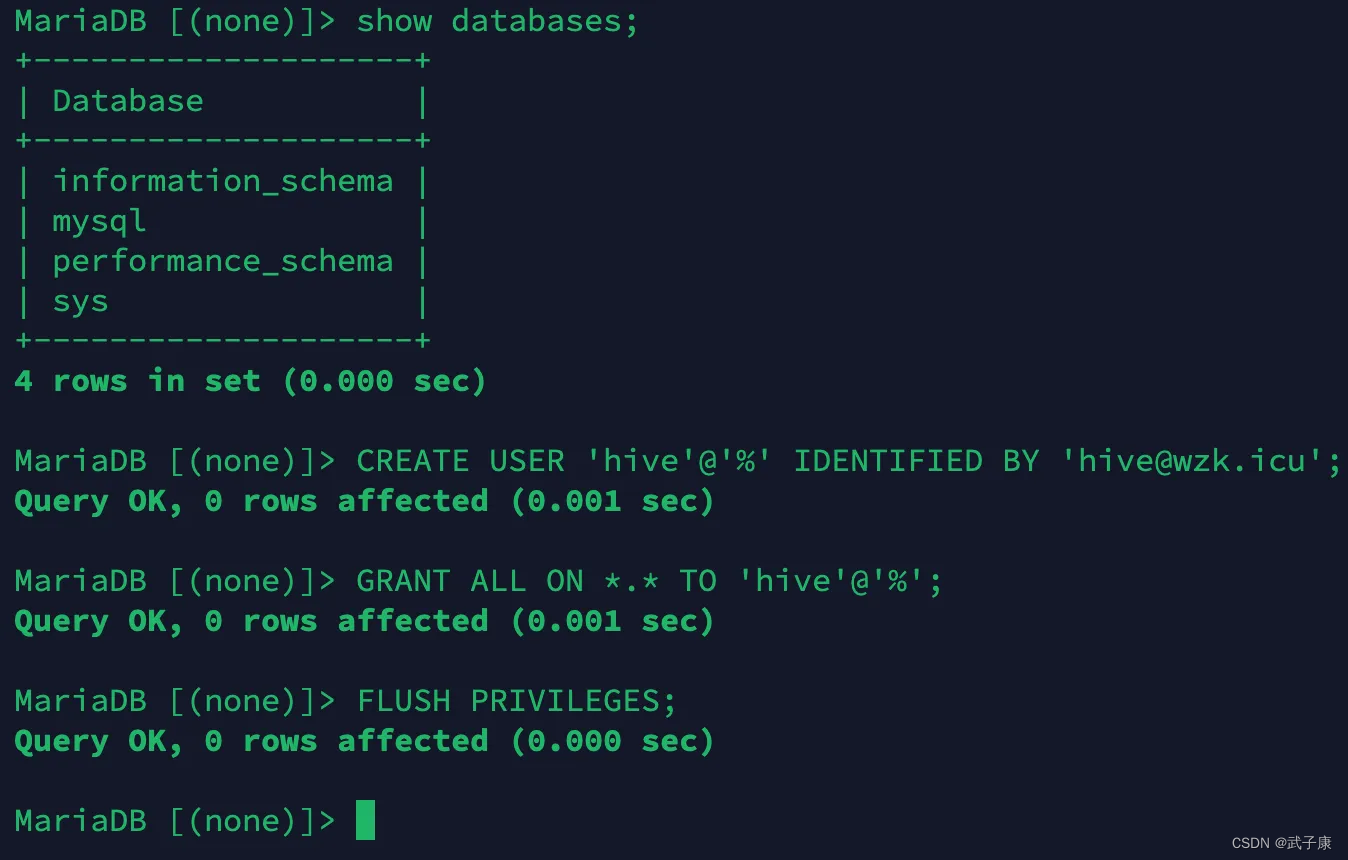
远程访问
shell
vim /etc/mysql/mariadb.conf.d/50-server.cnf修改 bind-address
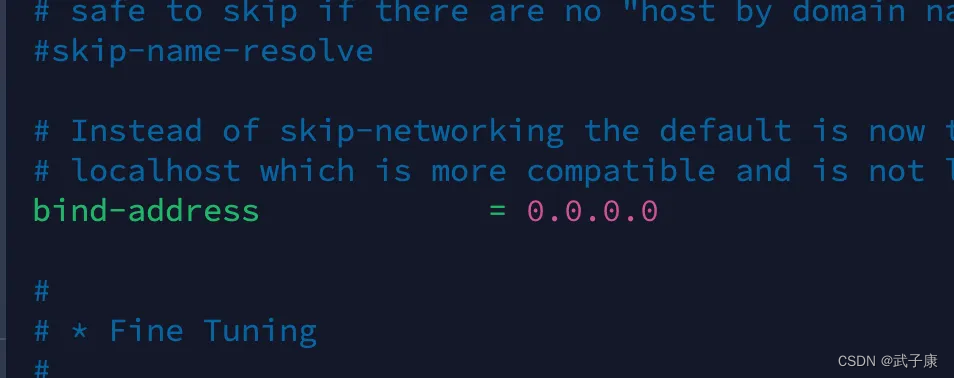
创建ROOT用户,开启远程访问。
sql
CREATE USER '你的用户'@'%' IDENTIFIED BY '你的密码';查看当前的表信息
sql
SELECT Host, User FROM mysql.user;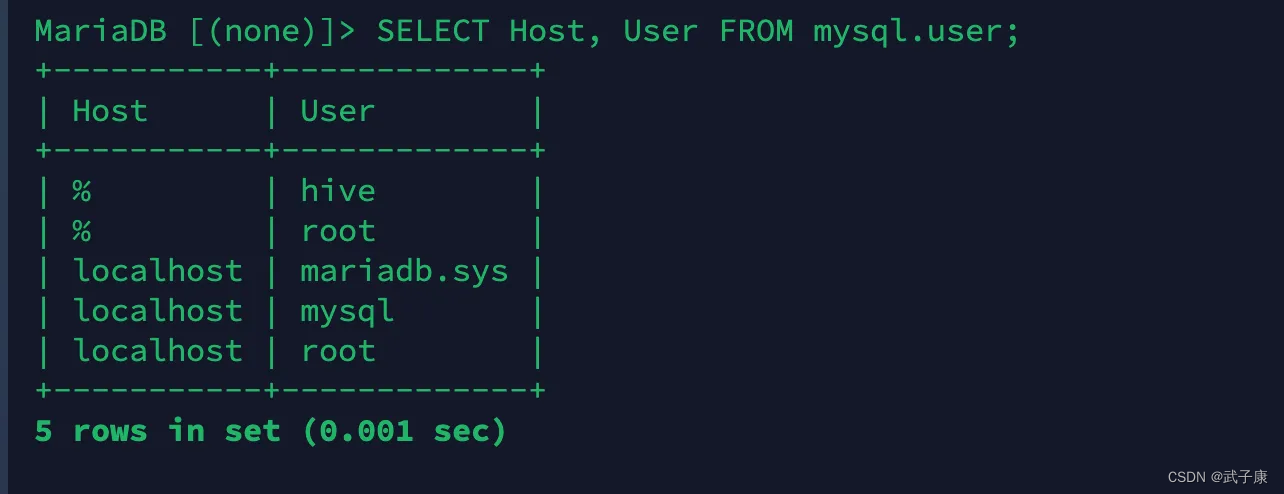
刷新权限
shell
FLUSH PRIVILEGES;初始化
我们需要给Hive一个链接的Jar包,平常我们写JDBC的时候,也会用到:
shell
把mysql-connector-java-8.0.19.jar拷贝到 $HIVE_HOME/lib在Hive节点上,运行如下指令:
shell
schematool -dbType mysql -initSchema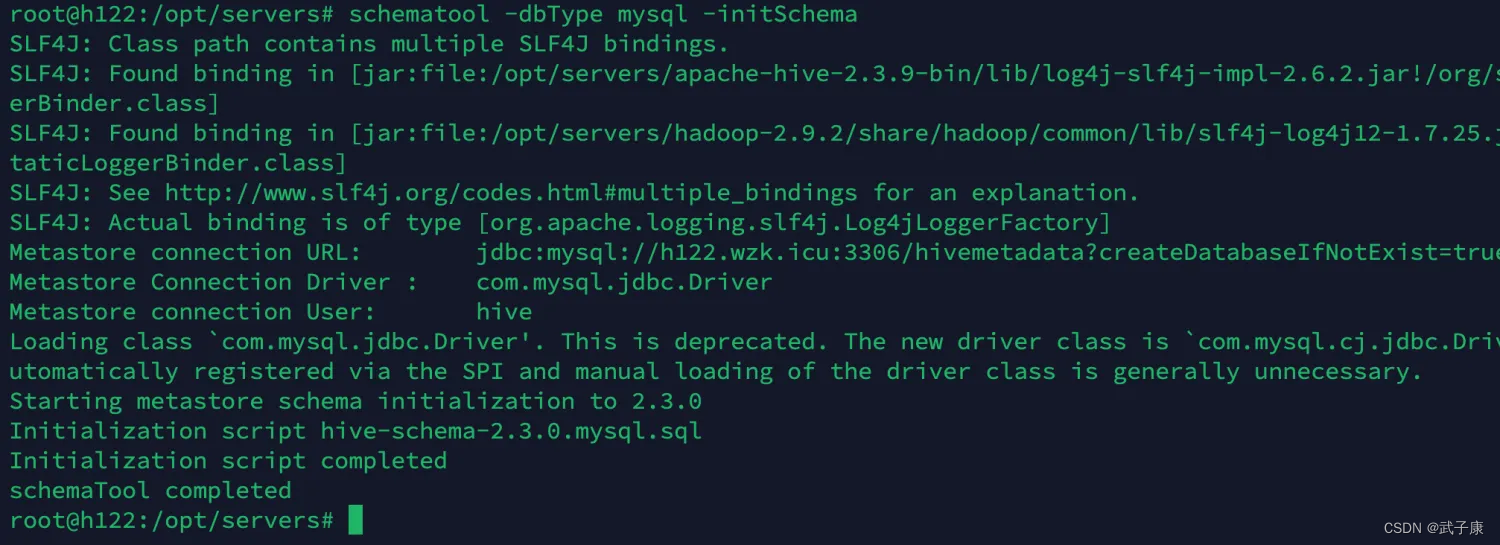
查看结果
连接我们的数据库,可以看到如下的情况:
