我们提供各种采集架构,以满足各种用例和网络配置的需求。
要将数据采集到 Elasticsearch,请使用最符合你的需求和用例的选项。对于许多用户和用例来说,最简单的方法是使用 Elastic Agent 采集数据并将其发送到 Elasticsearch。Elastic Agent 和 Elastic Agent 集成适用于许多流行的平台和服务,是一个不错的起点。
提示 :你可以在自己的硬件上托管 Elasticsearch,也可以将数据发送到 Elastic Cloud 上的 Elasticsearch。对于大多数用户来说,Elastic Agent 直接写入 Elastic Cloud 上的 Elasticsearch 是最简单、最快捷的实现价值的方式。我们的托管 Elasticsearch 服务可在 AWS、GCP 和 Azure 上使用,你可以免费试用。
更多关于摄取架构的文章,你可以详细阅读文章 "Elastic:开发者上手指南" 中的 "Elastic Stack 架构" 章节。
添加数据到 Elasticsearch 中
你可以通过多种方式将数据导入 Elasticsearch,这称为提取或索引数据。使用 Elastic Agent、Beats、Logstash、Elastic 语言客户端、Elastic 连接器或企业搜索网络爬虫。所选的选项(或组合)取决于你是索引一般内容还是带时间戳的数据。
一般内容
- 索引 HTML 页面、目录和其他文件等内容。使用 Elastic 语言客户端将数据从应用程序直接发送到 Elasticseach。否则,请使用 Elastic 内容 connectors 或 Elastic 网络爬虫。
带时间戳的数据
- 索引带时间戳的数据的首选方法是使用 Elastic Agent。Elastic Agent 是一种向主机添加日志、指标和其他类型数据监控的单一、统一方法。它还可以保护主机免受安全威胁、查询操作系统的数据以及转发远程服务或硬件的数据。每个基于 Elastic Agent 的集成都包括默认的提取规则、仪表板和可视化,可立即开始分析你的数据。Fleet Management 使你能够从 Kibana 集中管理所有已部署的 Elastic Agent。
- 如果你的数据源没有可用的 Elastic Agent 集成,请使用 Beats 收集数据。Beats 是数据传送器,旨在从服务器收集和传送特定类型的数据。你可以为要收集的每种类型的数据安装一个单独的 Beat。某些 Beats(例如 Filebeat 和 Metricbeat)可以使用提供默认配置、Elasticsearch 采集管道定义和 Kibana 仪表板的模块。不为 Beats 提供 fleet 管理功能。
- 如果 Elastic Agent 和 Beats 都不支持你的数据源,请使用 Logstash。Logstash 是一个开源数据收集引擎,具有实时管道功能,支持各种数据源。你还可以使用 Logstash 来保存传入数据,以确保在出现采集高峰或需要将数据发送到多个目的地时数据不会丢失。
设计数据提取管道
虽然你可以将数据直接发送到 Elasticsearch,但数据提取管道通常包括其他步骤来操作数据、确保数据完整性或管理数据流。
注意:该图重点关注带时间戳的数据。
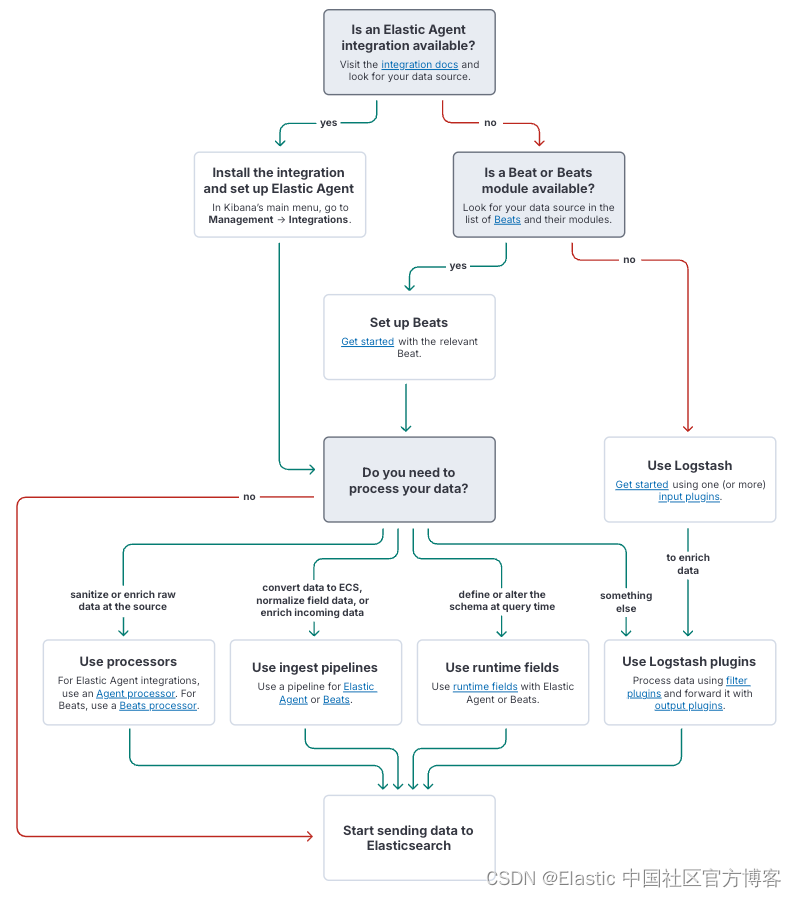
数据处理
在将数据编入索引并存储在 Elasticsearch 中之前,通常需要对其进行清理、规范化、转换或丰富。
- Elastic Agent 和 Beats 处理器使你能够在边缘处理数据。如果你需要控制通过网络发送的数据,或者需要使用主机上可用的信息丰富原始数据,这将非常有用。
- Elasticsearch 摄取管道使你能够在数据进入时对其进行处理。这避免了在你从中收集数据的主机上增加额外的处理开销。
- Logstash 使你能够避免在边缘进行重量级处理,但仍可以在将数据发送到 Elasticsearch 之前对其进行处理。这还使你能够将处理后的数据发送到多个目的地。
预处理数据的一个原因是控制编入 Elasticsearch 的数据结构 ------ 数据模式(data schema)。例如,使用摄取管道将数据映射到 Elastic Common Schema (ECS)。或者,在查询时使用运行时字段来:
- 无需了解数据的结构即可开始处理数据
- 无需重新索引数据即可向现有文档添加字段
- 覆盖索引字段返回的值
- 无需修改底层架构即可为特定用途定义字段
数据完整性
Logstash 可增强你不想丢失的重要数据的数据弹性。Logstash 提供磁盘持久队列 (persistent queue - PQ),无需外部缓冲机制即可吸收突发事件。它会尝试传递存储在 PQ 中的消息,直到传递至少成功一次。
Logstash 死信队列 (dead letter queue - DLQ) 为 Logstash 无法处理的事件提供磁盘存储,让你有机会评估它们。你可以使用 dead_letter_queue 输入插件轻松地重新处理 DLQ 事件。
数据流
如果你需要从多个 Beats 或 Elastic Agents 收集数据,请考虑使用 Logstash 作为代理。Logstash 可以从多个端点(即使在不同的网络上)接收数据,并通过单个防火墙规则将数据发送到 Elasticsearch。与为每个端点设置单独的规则相比,你可以用更少的工作获得更高的安全性。
Logstash 可以从单个管道发送到多个输出,以帮助你从数据中获取最大价值。
接下来该怎么做
我们有指南和许多实践教程,可帮助你开始将数据导入集群。
为 Elastic 解决方案导入数据
- 使用 Elastic Observability 深入了解你的应用程序和系统的行为。按照我们的指南提取各种数据类型,例如日志和指标、跟踪和 APM 以及来自 Splunk 的数据。还有几个教程可供选择。
- 使用 Elastic Security 快速检测、调查和应对整个环境中的威胁和漏洞。你可以使用 Elastic Agent 将数据提取到 Elastic Defend 集成中,或与许多其他与 Elastic Security 协同工作的集成一起使用。你还可以从 Splunk 或发送符合 ECS 的安全数据的各种第三方收集器中提取数据。
使用 Elastic Agent、Beats 和 Logstash 采集数据
对于想要构建自己的解决方案的用户,我们可以帮助你开始使用 Elasticsearch Platform 产品采集数据。
- Elastic 集成是一种将数据连接到 Elastic Stack 的简化方式。集成适用于流行的服务和平台,如 Nginx、AWS 和 MongoDB,以及许多通用输入类型,如日志文件。
- Beats 和 Elastic Agent 都可以直接或通过 Logstash 向 Elasticsearch 发送数据。你可以使用本指南来确定这些主要采集工具中的哪一个最适合你的用例。
- Fleet 在 Kibana 中提供了一个基于 Web 的 UI,用于集中管理 Elastic Agent 及其策略。
- 使用 Logstash 动态统一来自不同来源的数据,并将数据规范化到你选择的目的地。
使用 Elastic 网络爬虫、连接器提取数据
- 使用网络爬虫以编程方式从网站和知识库中发现、提取和索引可搜索内容。
- 将数据从原始数据源同步到 Elasticsearch 索引。连接器使你能够创建数据源的可搜索、只读副本。
从你的应用程序中提取数据
- 使用 Elasticsearch 语言客户端将应用程序中的数据提取到 Elasticsearch 中。
- 企业搜索编程语言客户端库为这些语言提供本机 API,以将数据提取到企业搜索、应用搜索和工作场所搜索中。
- 这些实践指南演示了如何使用 Elasticsearch 语言客户端从你的应用程序中提取数据。
操作和预处理数据
- Elasticsearch 采集管道可让你在索引之前对数据执行常见转换。
- 使用 Elastic Agent 轻量级处理器在源头解析、过滤、转换和丰富数据。
- 通过将插件(输入、输出、过滤器,有时还有编解码器)串联在一起来创建 Logstash 管道,以便在采集期间处理数据。
示例数据
如果你刚刚开始了解 Elastic,并且还没有想好具体的用例,那么你可以加载 Kibana 中的一个示例数据集。它们配有示例可视化、仪表板等,可以快速了解 Elastic 的潜力。
摄取架构
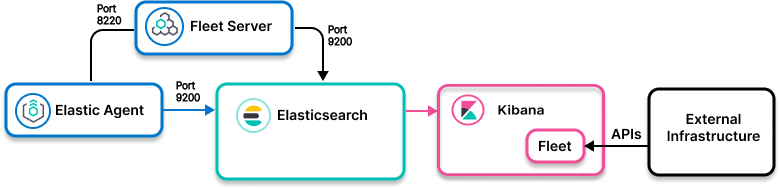
Elastic Agent 到 Elasticsearch

什么时候使用?
你的数据源可以使用 Elastic Agent 集成:
- 安装了 Elastic Agent 的软件组件
- 使用 API 进行数据收集的软件组件
Elastic Agent 经 Logstash 到 Elasticsearch

什么时候使用?
你需要 Logstash 提供的附加功能:
- Elastic Agent 和 Elasticsearch 之间的丰富
- 持久队列 (PQ) 缓冲以适应网络问题和下游不可用
- 在 Elastic Agent 对 Elastic Agent 网络外部连接有网络限制的情况下进行代理
- 数据需要根据内容路由到多个 Elasticsearch 集群和其他目的地
Elastic Agent 代理至 Elasticsearch

什么时候使用?
- Agents 具有网络限制,阻止连接到 Elastic Agent 网络之外。请注意,Logstash 作为代理是一种选择。
Elastic Agent 到 Elasticsearch,使用 Kafka 作为中间件消息队列

什么时候使用?
Kafka 是你的中间件消息队列:
- Kafka ES 接收连接器,用于从 Kafka 写入 Elasticsearch
- Logstash,用于从 Kafka 读取并路由到 Elasticsearch
Logstash 到 Elasticsearch

什么时候使用?
- 你需要从 Elastic Agent 无法读取的源(例如数据库、AWS Kinesis)收集数据。查看 Logstash 输入插件。
Elastic 物理隔离架构
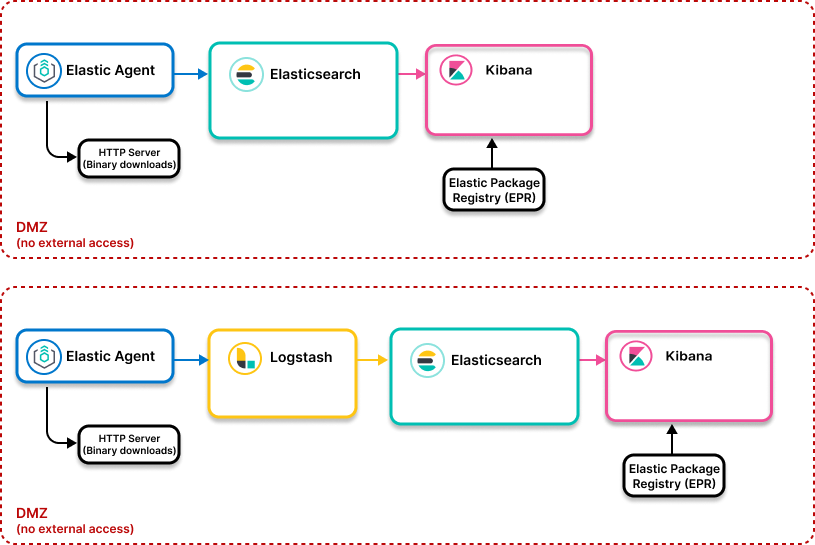
什么时候使用?
- 你想要在隔离环境中部署 Elastic Agent 和 Elastic Stack(无法访问外部网络)