学习了使用MindSpore在部分wine数据集上进行KNN实验,包括实验目的、K近邻算法原理、实验环境、数据处理、模型构建、模型预测等内容。
基本原理 :
K近邻算法(KNN)是一种用于分类和回归的非参数统计方法,其基本思想是通过计算样本与所有训练样本的距离,找出最接近的k个样本,根据这些样本的类别进行投票,票数最多的类就是分类结果。KNN的三个基本要素包括K值、距离度量和分类决策规则。在分类问题中,预测算法的流程是先找出距离待测样本最近的k个样本,统计每个类别的样本个数,最终分类结果为样本个数最多的类。在回归问题中,对样本的回归预测输出值为所有邻居的标签均值或带样本权重的均值。距离的定义常用欧氏距离,使用时需对特征向量的每个分量归一化。
数据库选用 :
选用了Wine数据集,该数据集是对来自意大利同一地区但来自三个不同品种的葡萄酒进行化学分析的结果,包含了13种属性和178个样本。数据可以从Wine数据集官网或华为云OBS中下载。
训练的过程:
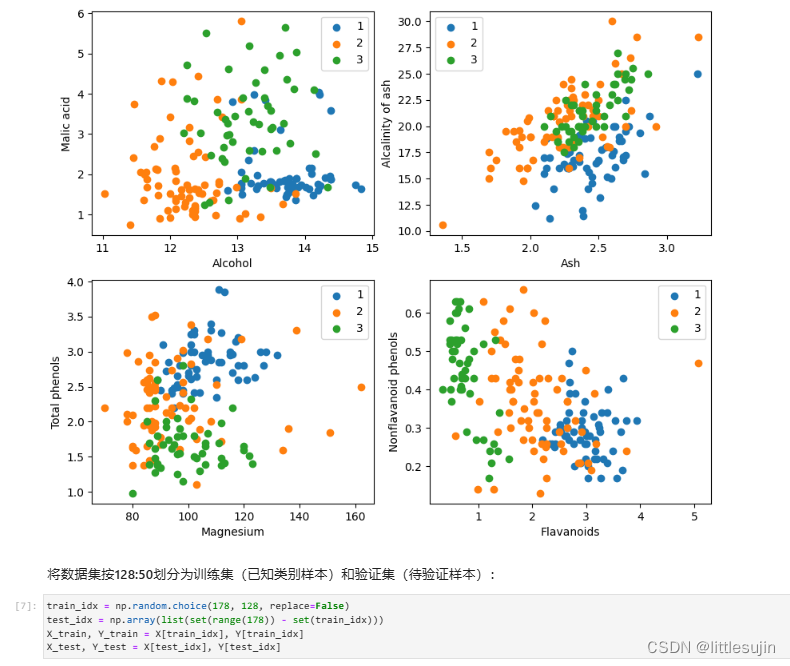
- 数据准备:通过从官网或华为云OBS下载wine.data文件获取数据集,并将数据集按128:50划分为训练集和验证集。
- 数据读取与处理:导入所需的Python库,配置运行信息,读取Wine数据集,将数据集的13个属性作为自变量X,3个类别作为因变量Y,并取样本的某两个属性进行2维可视化。
- 模型构建 - 计算距离:利用MindSpore提供的算子,通过矩阵运算同时计算输入样本x和已明确分类的其他样本X_train的距离,并计算出top k近邻。
- 模型预测:在验证集上验证KNN算法的有效性,取k = 5,计算预测结果与真实标签的准确率。
训练的结果 :
验证精度接近80%,说明KNN算法在该3分类任务上有效,能根据酒的13种属性判断出酒的品种。
代码记录如下:
【腾讯文档】K近邻算法实现红酒聚类