什么是模型微调
大模型微调是指在已经预训练好的大型语言模型基础上,使用特定的数据集进行进一步的训练,以使模型适应特定任务或领域。
根本原理在于,机器学习模型只能够代表它所接收到的数据集的逻辑和理解,而对于其没有获得的数据样本,其并不能很好地识别/理解,且对于大模型而言,也无法很好地回答特定场景下的问题。
怎么进行微调
从参数规模的角度,大模型的微调分成两条技术路线:
一条是对全量的参数,进行全量的训练,这条路径叫全量微调FFT(Full Fine Tuning)。灾难性遗忘
一条是只对部分的参数进行训练,这条路径叫PEFT(Parameter-Efficient Fine Tuning)。训练成本巨大
从训练数据的来源、以及训练的方法的角度,大模型的微调有以下几条技术路线:
监督式微调SFT(Supervised Fine Tuning):用人工标注的数据与传统机器学习中监督学习的方法对大模型进行微调
基于人类反馈的强化学习微调RLHF(Reinforcement Learning withHuman Feedback):把人类的反馈通过强化学习的方式引入到对大模型的微调中去
基于AI反馈的强化学习微调RLAIF(Reinforcement Learning with AIFeedback):这个原理大致跟RLHF类似,但是反馈的来源是AI。
Prompt Tuning
Prompt Tuning的出发点,是基座模型(Foundation Model)的参数不变,为每个特定任务,训练一个少量参数的小模型,在具体执行特定任务的时候按需调用。
Prompt Tuning的基本原理是在输入序列X之前,增加一些特定长度的特殊Token,以增大生成期望序列的概率。
Prefix Tuning
Prefix Tuning的灵感来源是:基于Prompt Engineering的实践表明,在不改变大模型的前提下,在Prompt上下文中添加适当的条件,可以引导大模型有更加出色的表现。
Prompt Tuning在Embedding环节,往输入序列X前面加特定的Token。而Prefix Tuning是在Transformer的Encoder和Decoder的网络中都加了一些特定的前缀。
LoRA
LoRA是跟Prompt Tuning和Prefix Tuning完全不相同的另一条技术路线。
LoRA背后有一个假设:我们现在看到的这些大语言模型,它们都是被过度参数化的。而过度参数化的大模型背后,都有一个低维的本质模型。
LoRA:Low-Rank Adaptation of Large Language Models
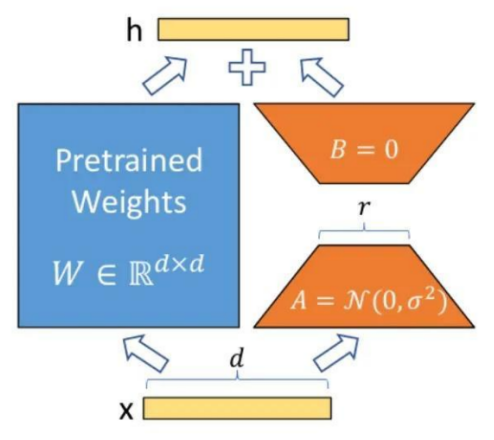
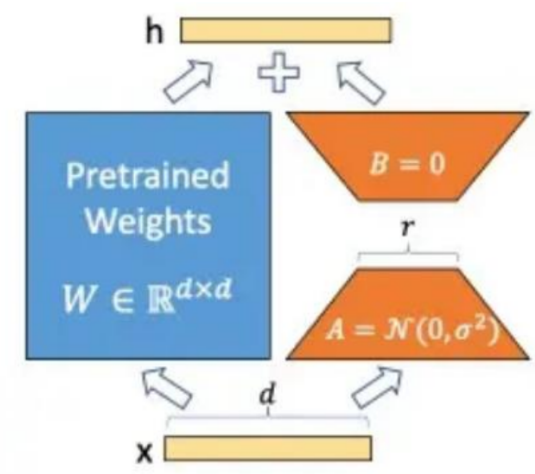
·LoRA的基本原理是冻结预训练好的模型权重参数,在冻结原模型参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。
·优点:由于这些新增参数数量较少,这样不仅finetune的成本显著下降,还能获得和全模型微调类似的效果。
·核心思想:在原始预训练语言模型旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的intrinsic rank(预训练模型在各类下游任务上泛化的过程其实就是在优化各类任务的公共低维本征(low-dimensional intrinsic)子空间中非常少量的几个自由参数)。
LoRA:Low-Rank Adaptation of Large Language Models
·训练的时候固定预训练语言模型的参数,只训练降维矩阵A与升维矩阵B。
·模型的输入输出维度不变,输出时将BA与预训练语言模型的参数叠加。
用随机高斯分布初始化A,用0矩阵初始化
B。这样能保证训练开始时,新增的通路
BA=0,从而对模型结果没有影响。它主要是通过对神经网络中各层之间的权重进行学习,来提高模型的性能。
LORA模型通过学习到前一层和后一层之间的相关性,来自动调整当前层的权重,从而提高模型的性能。
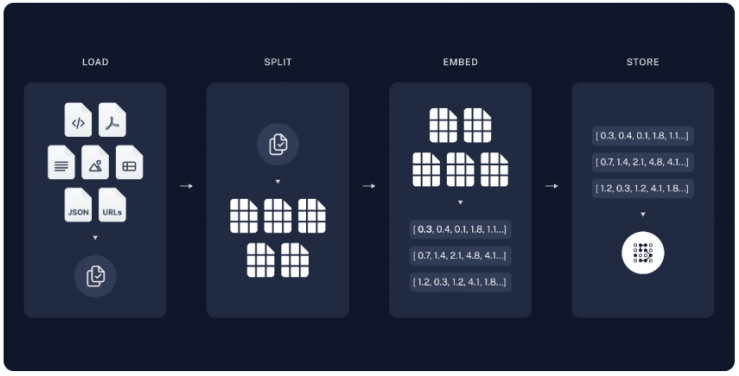
什么是RAG
RAG是一种利用额外的(通常是私有的或实时的)数据来增强大模型知识的技术。
如果想要构建能够推理私有数据或模型截止日期之后引入的数据的AI应用程序,需要使用模型所需的特定信息来增强模型的知识。引入适当的信息并将其插入模型提示的过程称为检索增强生成(RAG)。
RAG把一个信息检索组件和文本生成模型结合在一起。RAG可以微调,其内部知识的修改方式很高效,不需要对整个模型进行重新训练。
检索增强生成(RAG)
RAG会接受输入并检索出一组相关/支撑的文档,并给出文档的来源(例如维基百科)。这些文档作为上下文和输入的原始提示词组合,送给文本生成器得到最终的输出。这样RAG更加适应事实会随时间变化的情况。