李宏毅深度学习笔记
RNN
在 RNN 里面,每一次隐藏层的神经元产生输出的时候,该输出会被存到记忆元。下一次有输入时,这些神经元不仅会考虑输入 x1, x2,还会考虑存到记忆元里的值。
记忆元可简称为单元,记忆元的值也可称为隐状态
RNN 可以是深层的。比如把 x丢进去之后,它可以通过一个隐藏层,再通过第二个隐藏层,以此类推 (通过很多的隐藏层) 才得到最后的输出。每一个隐藏层的输出都会被存在记忆元里面,在下一个时间点的时候,每一个隐藏层会把前一个时间点存的值再读出来,以此类推最后得到输出,这个过程会一直持续下去。
简单循环网络(Simple Recurrent Network,SRN),也称为 Elman 网络,即把隐藏层的值存起来,在下一个时间点在读出来
Jordan 网络存的是整个网络输出的值,它把输出值在下一个时间点在读进来,把输出存到记忆元里。
双向循环神经网络,循环神经网络还可以是双向。可以同时训练一个正向的循环神经网络,又可以训练一个逆向的循环神经网络,然后把这两个循环神经网络的隐藏层拿出来,都接给一个输出层得到最后的 y。
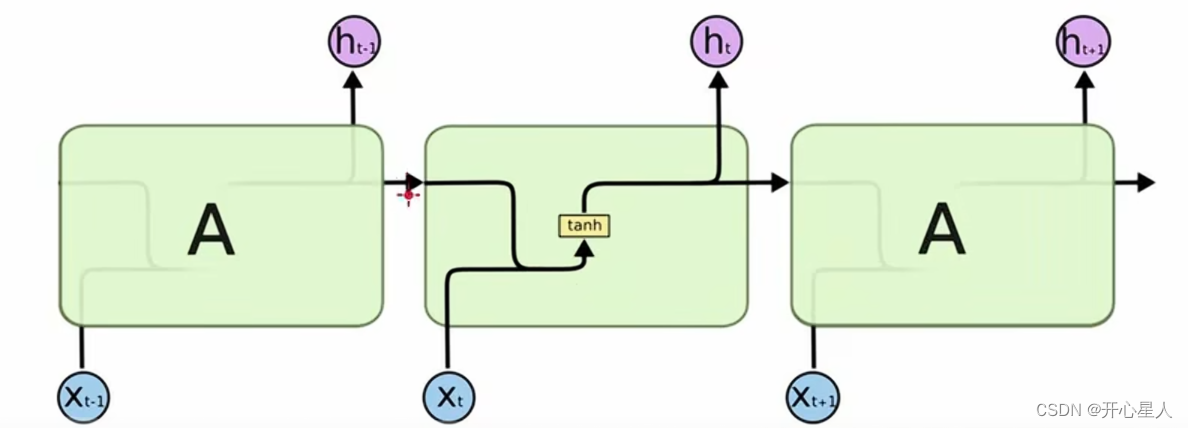
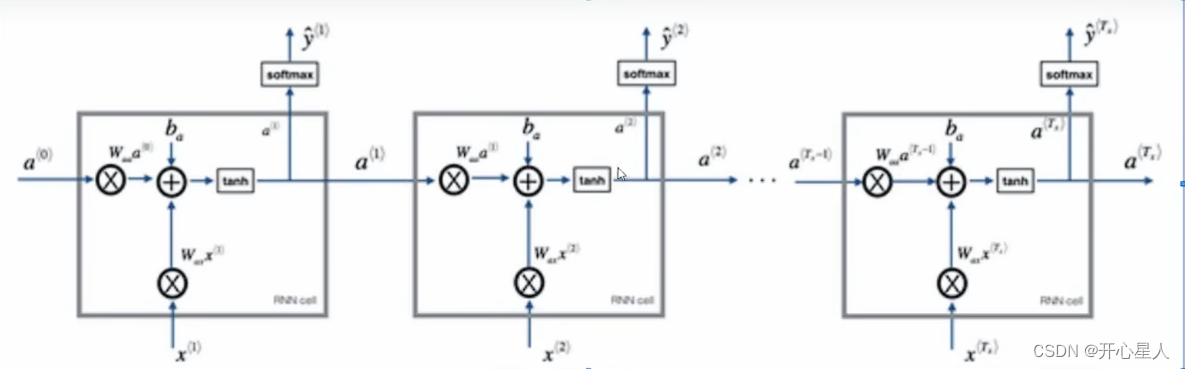
内部运算过程
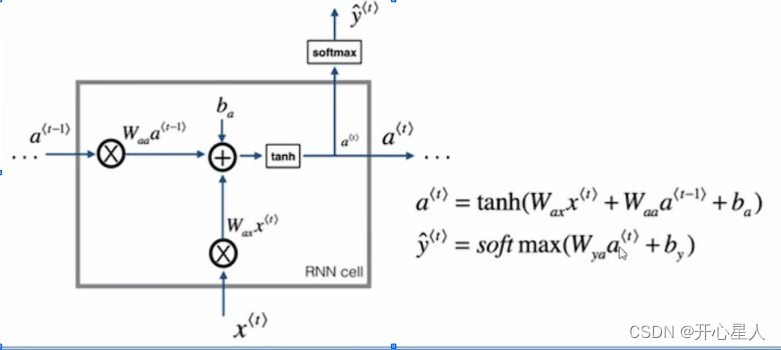
RNN特点:
1、串联结构,体现出"前因后果",后面结果的生成,要参考前面的信息
2、所有特征共享同一套参数。面对不同的输入(两个方面),能学到不同的相应的结果;极大减少了训练参数量;输入和输出数据在不同例子中可以有不同的长度
RNN学习方式
梯度下降用在前馈神经网络里面我们要用一个有效率的算法称为反向传播 。循环神经网络里面,为了要计算方便,提出了反向传播的进阶版,即随时间反向传播(BackPropagation Through Time,BPTT)。BPTT 跟反向传播其实是很类似的,只是循环神经网络它是在时间序列上运作,所以 BPTT 它要考虑时间上的信息
损失函数可以自定义(如二分类任务可以使用交叉熵)
RNN梯度爆炸和梯度消失:https://blog.csdn.net/qq_41020633/article/details/124044086
LSTM
长短时记忆网络(Long Short-Term Memory,LSTM)长时间的短期记忆。是一种循环神经网络(RNN)的变体,旨在解决传统RNN在处理长序列时的梯度消失和梯度爆炸问题。LSTM引入了一种特殊的存储单元和门控机制,以更有效地捕捉和处理序列数据中的长期依赖关系。
之前的循环神经网络,它的记忆元在每一个时间点都会被洗掉,只要有新的输入进来,每一个时间点都会把记忆元洗掉,所以的短期是非常短的,但如果是长时间的短期记忆元,它记得会比较久一点,只要遗忘门不要决定要忘记,它的值就会被存起来。
LSTM 有三个门,当外界某个神经元的输出想要被写到记忆元里面的时候,必须通过一个输入门 ,输入门要被打开的时候,才能把值写到记忆元里面。输出的地方也有一个输出门 ,输出门会决定外界其他的神经元能否从这个记忆元里面把值读出来。输入门和输出门的开关是神经网络自己学的,其可以自己学什么时候要把输入门打开,什么时候要把输入门关起来。遗忘门决定什么时候记忆元要把过去记得的东西忘掉。这个遗忘门什么时候会把存在记忆元的值忘掉,什么时候会把存在记忆元里面的值继续保留下来,这也是网络自己学到的。
整个 LSTM 可以看成有 4 个输入、1 个输出。在这 4 个输入中,一个是想要被存在记忆元的值,但不一定能存进去,还有操控输入门的信号、操控输出门的信号、操控遗忘门的信号,有着四个输入但它只会得到一个输出。
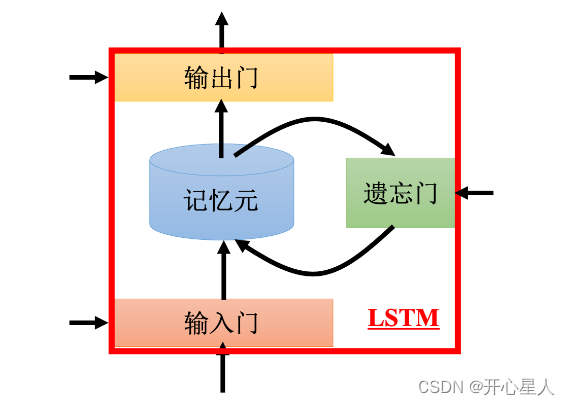
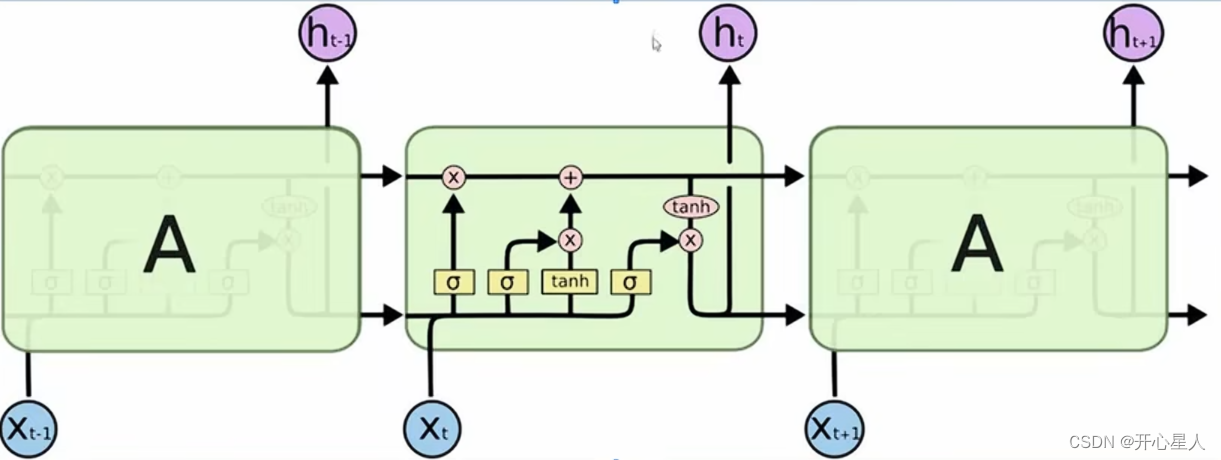
内部运算过程
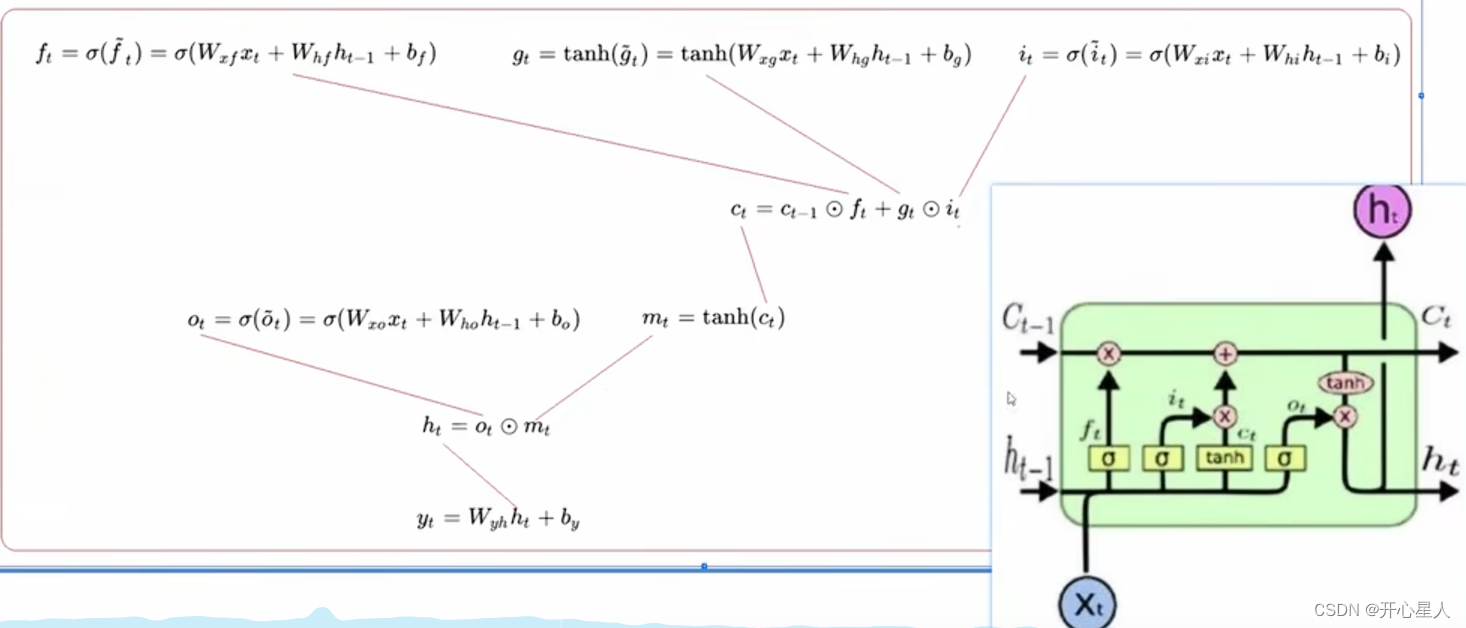
gt是图上的ct;h是状态,c是记忆单元
fi是遗忘门,fi的值可能为0或1。fi × Ct-1 ,所以fi决定是否遗忘之前的记忆 Ct-1
输入输出门也是同理,带公式即可理解
GRU
门控循环单元(Gated Recurrent Unit,GRU)是 LSTM 稍微简化的版本,它只有两个门。虽然少了一个门,但其性能跟 LSTM 差不多,少了 1/3 的参数,也是比较不容易过拟合。