目录
- [1. why RNN](#1. why RNN)
- [2. RNN](#2. RNN)
- [3. pytorch RNN layer](#3. pytorch RNN layer)
-
- [3.1 基本单元](#3.1 基本单元)
- [3.2 nn.RNN](#3.2 nn.RNN)
-
- [3.2.1 函数说明](#3.2.1 函数说明)
- [3.2.2 单层pytorch实现](#3.2.2 单层pytorch实现)
- [3.2.3 多层pytorch实现](#3.2.3 多层pytorch实现)
- [3.3 nn.RNNCell](#3.3 nn.RNNCell)
-
- [3.3.1 函数说明](#3.3.1 函数说明)
- [3.3.2 单层pytorch实现](#3.3.2 单层pytorch实现)
- [3.3.3 多层pytorch实现](#3.3.3 多层pytorch实现)
- 4.完整代码
1. why RNN
以淘宝的评论为例,判断评论是正面还是负面的,如下图:

上图中每个单词用一个线性层来表示,最后再聚合,每个单词都有一个单独的w和b。
这种方法的问题:
- 对于长句子甚至是一段文章来说,就很难表示了,因为要用很多线性层和参数表示
- 没有语境信息
比如:
我不喜欢数学,如果没看到不,只看到喜欢,理解的意思就完全不一样了,因此对于一个句子来说,必须有一个语境信息,才能正确理解句子的意思。
为了解决上述问题,RNN增加了权值共享和一个用于保存语境信息的memory h
2. RNN
如下图:
第一个单词不仅考虑到了x输入还考虑到了初始化输入,通过这两个输入产生了一个语境信息h1,第二个单词不仅考虑当前单词的输入还要考虑上一个单词的语境信息h1,以此类推。


RNN的核心就是有个语境信息ht,这个语境信息根据当前的输入和上次的语境信息ht-1不断更新自我,并不断向前传。
展开图如下:

3. pytorch RNN layer
3.1 基本单元
下图展示了ht的计算过程,假设句子长度为5,batch是3,每个单词用100维向量表示,h0初始值用20维表示,最终得到h(t+1)维度为3,20


上图中rnn=nn.RNN(100,10),100是feature len,10表示hidden len。
输出参数中rnn.weight_hh_10.shape=》hidden len, hidden len
rnn.weight_ih_10.shape=》hidden len, feature len
3.2 nn.RNN
3.2.1 函数说明
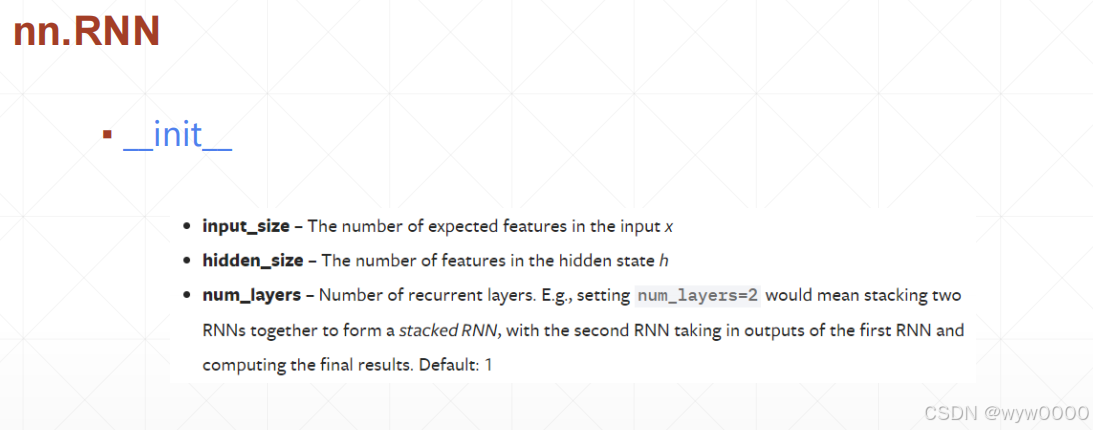
input_size-输入x的维度
hidden_size-h的维度
num_layers-有几次,默认1

上图中forward函数的返回值中
htnum layers, b, h dim=》是最后时间戳所有memory(h)的状态
outseq len, b, h dim=》是所有时间错最后一个memory(h)的状态
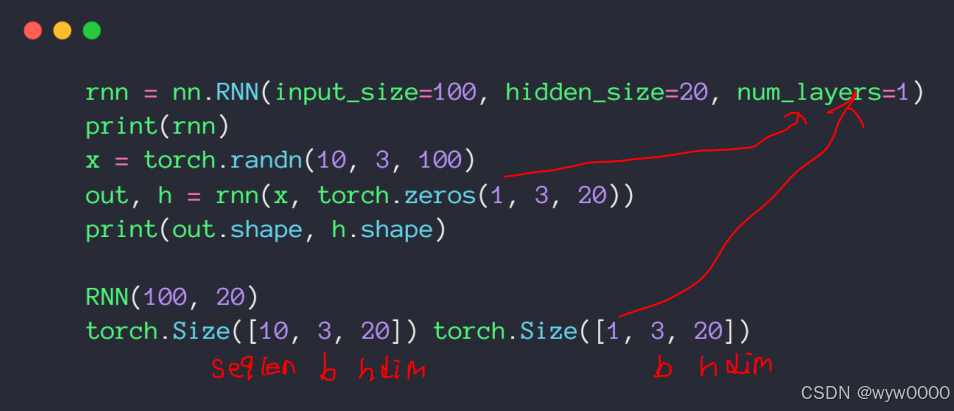
3.2.2 单层pytorch实现
3.2.3 多层pytorch实现
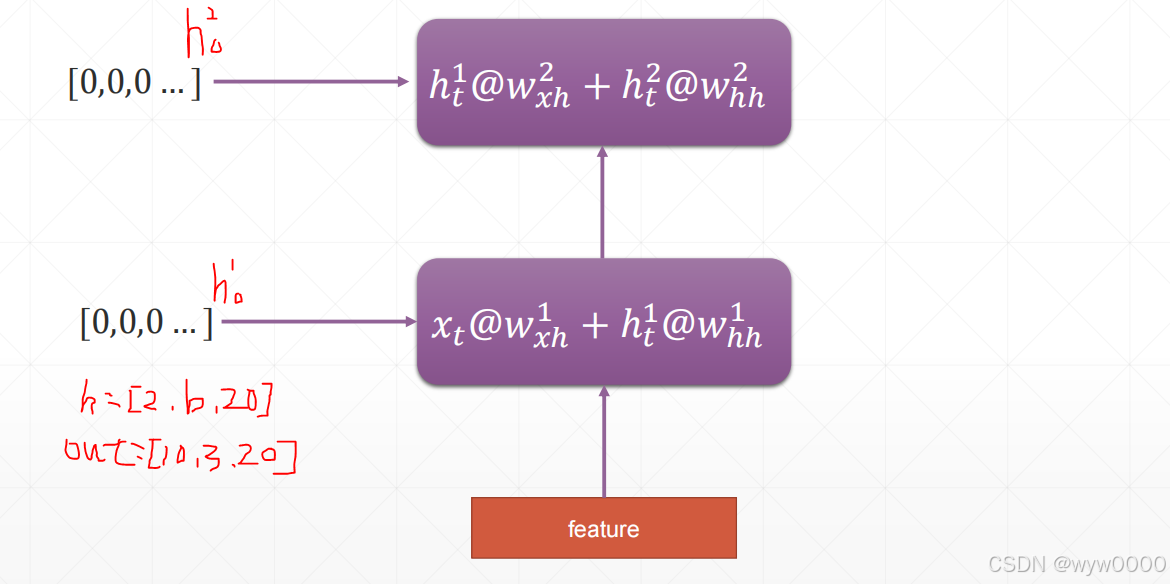
上图为2层RNN,h变由1层的1,3,20变为]2,3,20(num_layer,b, h dim),out和1层一样是10,3,20

下图为4层RNN,pytorch代码实现,注意一下输出shape的变化

3.3 nn.RNNCell
3.3.1 函数说明
nn.RNNCell与nn.RNN的初始化参数是完全一致

但是输入输出就不一样了,如下图:

3.3.2 单层pytorch实现
从pytorch代码可以看出,nn.RNNCell是循环处理每个单词,每次自更新h1

3.3.3 多层pytorch实现
下图为2层nn.RNNCell的pytorch代码,注意1层的h dim与2层的input dim必须一致,下图都是30
从代码中也可以看出第1层的h1作为第2层的输入参与更新h2。

4.完整代码
python
import torch
from torch import nn
from torch import optim
from torch.nn import functional as F
def main():
rnn = nn.RNN(input_size=100, hidden_size=20, num_layers=1)
print(rnn)
x = torch.randn(10, 3, 100)
out, h = rnn(x, torch.zeros(1, 3, 20))
print(out.shape, h.shape)
rnn = nn.RNN(input_size=100, hidden_size=20, num_layers=4)
print(rnn)
x = torch.randn(10, 3, 100)
out, h = rnn(x, torch.zeros(4, 3, 20))
print(out.shape, h.shape)
# print(vars(rnn))
print('rnn by cell')
cell1 = nn.RNNCell(100, 20)
h1 = torch.zeros(3, 20)
for xt in x:
h1 = cell1(xt, h1)
print(h1.shape)
cell1 = nn.RNNCell(100, 30)
cell2 = nn.RNNCell(30, 20)
h1 = torch.zeros(3, 30)
h2 = torch.zeros(3, 20)
for xt in x:
h1 = cell1(xt, h1)
h2 = cell2(h1, h2)
print(h2.shape)
print('Lstm')
lstm = nn.LSTM(input_size=100, hidden_size=20, num_layers=4)
print(lstm)
x = torch.randn(10, 3, 100)
out, (h, c) = lstm(x)
print(out.shape, h.shape, c.shape)
print('one layer lstm')
cell = nn.LSTMCell(input_size=100, hidden_size=20)
h = torch.zeros(3, 20)
c = torch.zeros(3, 20)
for xt in x:
h, c = cell(xt, [h, c])
print(h.shape, c.shape)
print('two layer lstm')
cell1 = nn.LSTMCell(input_size=100, hidden_size=30)
cell2 = nn.LSTMCell(input_size=30, hidden_size=20)
h1 = torch.zeros(3, 30)
c1 = torch.zeros(3, 30)
h2 = torch.zeros(3, 20)
c2 = torch.zeros(3, 20)
for xt in x:
h1, c1 = cell1(xt, [h1, c1])
h2, c2 = cell2(h1, [h2, c2])
print(h2.shape, c2.shape)
if __name__ == '__main__':
main()