任务描述
知识点:安装配置Kafka
重 点: 安装配置Kafka
难 点:无
内 容:
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
- 通过O的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
- 支持通过Kafka服务器和消费机集群来分区消息。
- 支持Hadoop并行数据加载。
本任务主要内容是Kafka的下载安装(参考相关文档)。
任务指导
Apache Kafka是由Apache软件基金会开发的一个开源消息系统项目,由Scala和Java写成。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。它提供了类似于JMS的特性,但是在设计实现上完全不同。Kafka进行消息保存时会根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,Kafka集群有多个Kafka实例组成,每个实例(Server)称为Broker。无论是Kafka集群,还是Producer和Consumer都依赖ZooKeeper来保证系统的可用性,并保存一些集群元(Meta)信息。
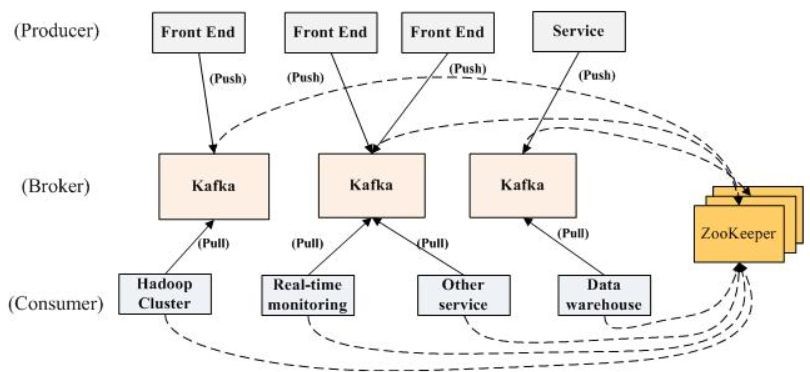
一个典型的Kafka集群中包含若干Producer(可以是Web前端FET,或者是服务器日志等),若干Broker(Kafka支持水平扩展,一般Broker数量越多,集群吞吐率越高),若干ConsumerGroup,以及一个ZooKeeper集群。Kafka通过Zookeeper管理Kafka集群配置:选举Kafka Broker的Leader,以及在Consumer Group发生变化时进行Rebalance,因为Consumer消费Kafka topic的Partition的offsite信息是存在ZooKeeper的。Producer使用push模式将消息发布到Broker,Consumer使用pull模式从Broker订阅并消费消息。
1、核心概念:
- **消息:**Message是指在生产者、服务端和消费者之间传输的数据。
- **消息代理:**Message Broker是指该MQ的服务端或者服务器。
- **消息生产者:**Message Producer负责产生消息并发送消息到meta服务器。
- **消息消费者:**Message Consumer负责消息的消费。
- **消息的主题:**Message Topic由用户定义并在Broker上配置。Producer发送消息到某个Topic下,Consumer从某个Topic下消费消息。
- **主题的分区:**Partition可以把一个Topic分为多个分区。每个分区是一个有序的、不可变的、顺序递增的Commit Log。
- **消费者分组:**Consumer Group由多个消费者组成,共同消费一个Topic下的消息,每个消费者消费部分消息。这些消费者组成一个组,拥有同一个分组名称,也称作消费者集群。
- **偏移量:**分区中的消息都有一个递增的id,称之为Offset。唯一标识了分区中的消息。
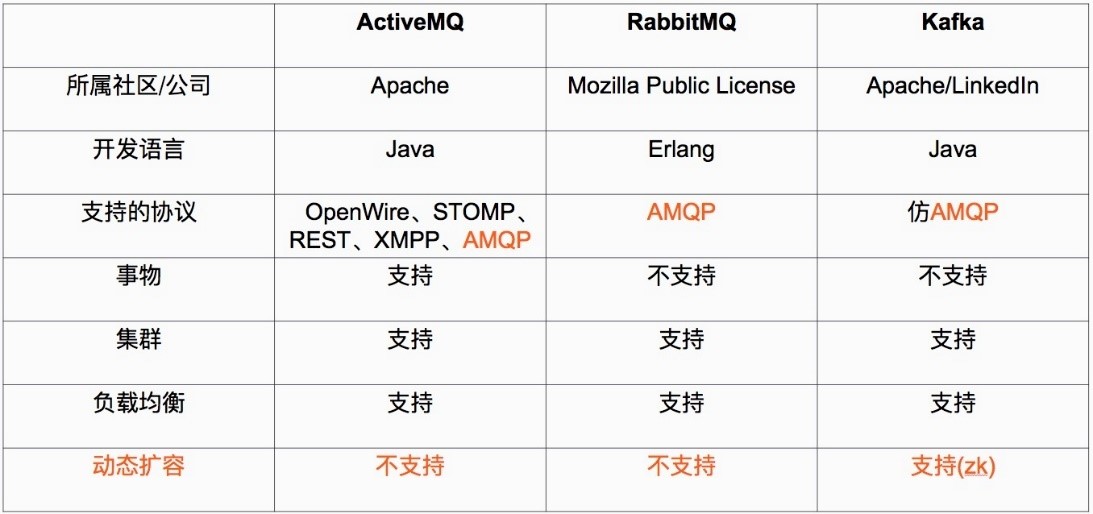
2、Kafka和其他主流分布式消息系统的对比:
任务实现
在node1节点上安装配置Kafka,然后再使用【scp】命令,将安装目录分发到其他节点(node2、node3)。
1、可以从官网下载Kafka安装包 ,当前环境已经提供了Kafka的安装包,存放在 /opt/software目录下。
-
在node1上解压安装Kafka
[root@node1 ~]# cd /opt/software
[root@node1 software]# tar -xzf kafka.tar.gz -C /opt/module/
2、在node1系统环境变量/etc/profile
[root@node1 software]# vi /etc/profile-
在文件末尾添加如下配置:
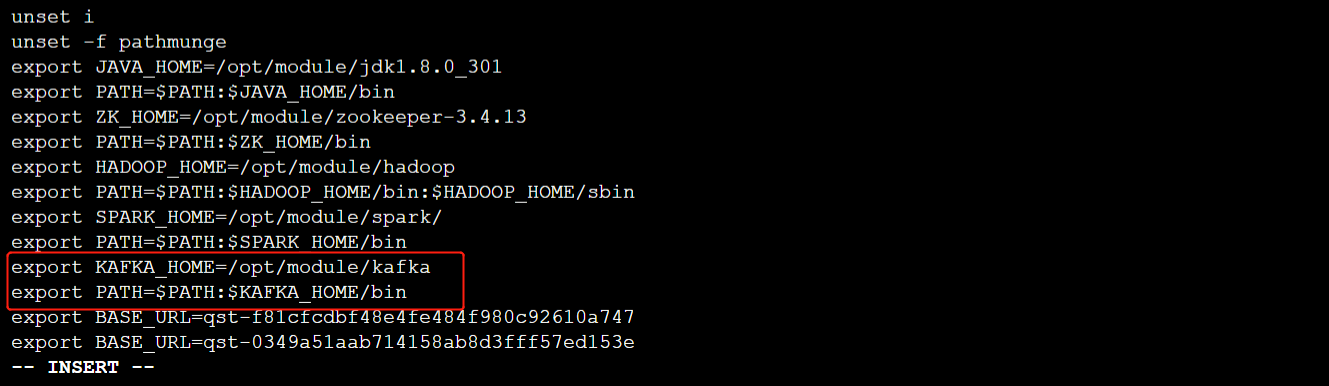
export KAFKA_HOME=/opt/module/kafka
export PATH=PATH:KAFKA_HOME/bin
-
使用【source】命令,使/etc/profile配置生效
[root@node1 software]# source /etc/profile
3、配置Kafka
-
为Kafka创建数据目录
[root@node1 software]# cd $KAFKA_HOME
[root@node1 kafka]# mkdir kafka-logs -
然后打开config目录下的server.properties文件,修改日志目录为刚刚创建的目录:
[root@node1 kafka]# cd $KAFKA_HOME/config
[root@node1 config]# vi server.properties -
找到并修改如下配置的值,其中broker.id的值需要保证在整个集群中是唯一的
broker.id=1
log.dirs=/opt/module/kafka/kafka-logs
zookeeper.connect=node1:2181,node2:2181,node3:2181 -
将Kafka和环境变量拷贝到node2、node3并修改broker.id的值
[root@node1 config]# cd /opt/module/
[root@node1 module]# scp -rq kafka node2:/opt/module/
[root@node1 module]# scp -rq kafka node3:/opt/module/
[root@node1 module]# scp -rq /etc/profile node2:/etc/
[root@node1 module]# scp -rq /etc/profile node3:/etc/ -
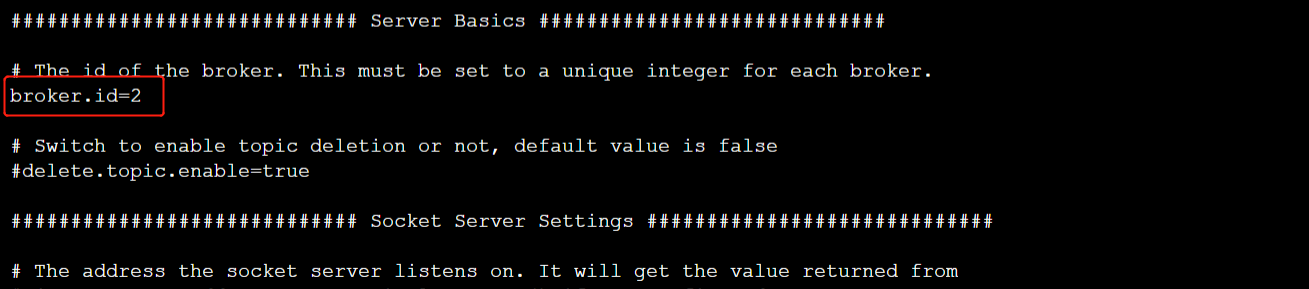
在node2修改kafka的配置文件server.properties,将broker.id的值修改为2
[root@node2 ~]# source /etc/profile
[root@node2 ~]# cd $KAFKA_HOME/config
[root@node2 config]# vi server.properties -
修改后broker.id的值如下
-
在node3修改kafka的配置文件server.properties,将broker.id的值修改为3
[root@node3 ~]# source /etc/profile
[root@node3 ~]# cd $KAFKA_HOME/config
[root@node3 config]# vi server.properties -
修改后broker.id的值如下
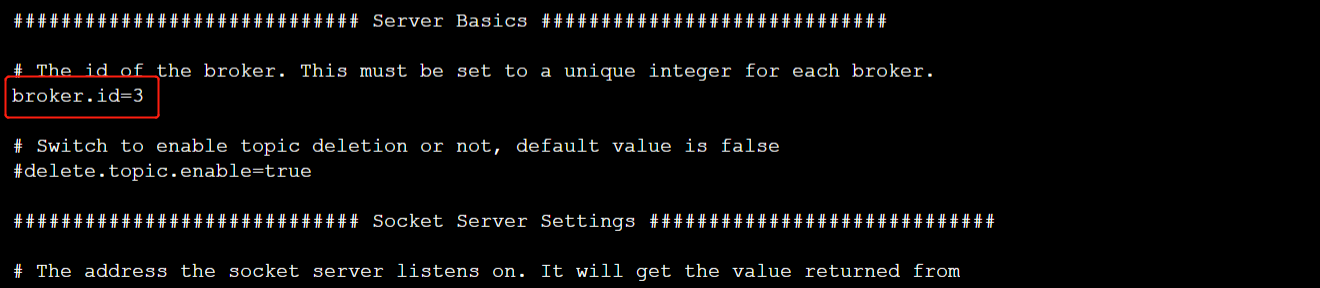
-
分别在node1、node2、node3启动Kafka的后台守护进程
[root@node1 ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties

[root@node2 ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
[root@node3 ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
4、验证Kafka
-
创建topic,创建名为test的topic,分区数1,副本1
[root@node1 ~]# kafka-topics.sh --create --zookeeper node1:2181,node2:2181,node3:2181 --replication-factor 1 --partitions 1 --topic test
-
查看topic的状态
[root@node1 ~]# kafka-topics.sh --describe --zookeeper node1:2181,node2:2181,node3:2181 --topic test

-
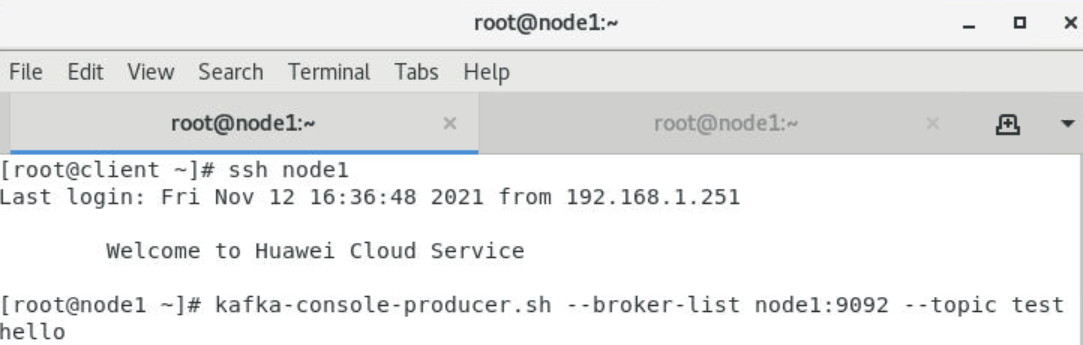
在client客户端节点上打开一个终端,使用ssh命令连接到node1,发送消息
[root@client~]# ssh node1
[root@node1 ~]# kafka-console-producer.sh --broker-list node1:9092 --topic test
-
在client客户端节点上重新打开一个终端,使用ssh命令连接到node1的消费消息
[root@client~]# ssh node1
[root@node1 ~]# kafka-console-consumer.sh --bootstrap-server node1:9092 --from-beginning --topic test
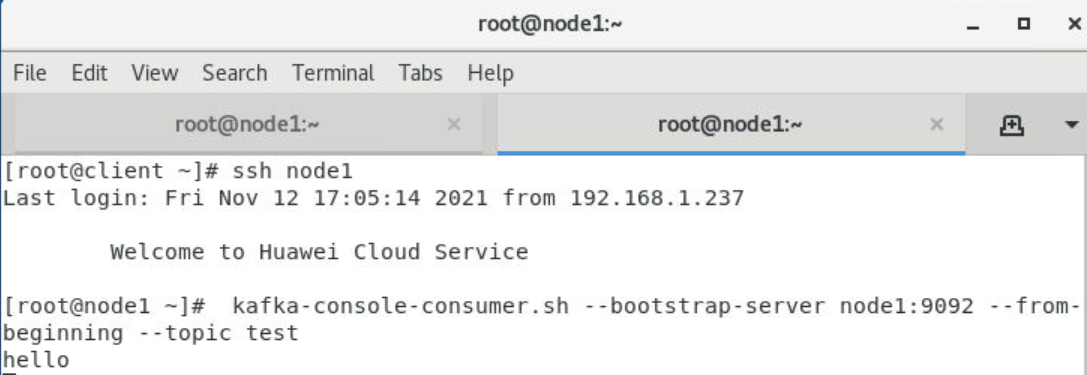
**参数说明:**参数from-beginning表示从第一条消息开始读取。