参考文章
【Docker安装部署Kafka+Zookeeper详细教程】_linux arm docker安装kafka-CSDN博客
Docker搭建kafka+zookeeper
打开我们的docker的镜像源配置
vim /etc/docker/daemon.json
配置
{
"registry-mirrors": "https://widlhm9p.mirror.aliyuncs.com"
}
下面的那个insecure是我自己虚拟机的,不用理会

拉取镜像
然后开始拉取我们的zookeeper镜像和我们的kafka镜像
这个是我们的zookeeper镜像,没有指定版本默认就是拉取最新的版本
docker pull zookeeperkafka镜像
docker pull wurstmeister/kafka因为我们的docker不同容器之间的网络是互相隔开的,所以我们要创建一个共同使用的网络
让不同容器都加入这个网络
docker network create创建我们的网络
然后那个zookeeper_network是我们自定义的网络名称
docker network create --driver bridge zookeeper_networkkafka是依赖于zookeeper的所以我们要先安装zookeeper
我们先用run来创建一个zookeeper容器
docker run -d --name zookeeper1 --network zookeeper_network -p 2181:2181 zookeeper-d 是后台运行
--name 是我们自定义容器的名字 我定义的名字是zookeeper1
--network
是指定我们的网络环境,我们刚刚创建的网络环境名字叫zookeeper_network,所以我们要让容器加入这个网络
-p 是指定我们的容器暴露给外部的端口 2181:2181是指虚拟机(或服务器)的2181端口与容器内部的2181端口做映射
最后面的那个zookeeper 是我们的使用的镜像源的名称
一般是zookeeper:xxx来执行使用镜像源的版本,如果不指定版本默认用的就是最新版本
查看我们创建的网络环境的地址
docker inspect zookeeper_network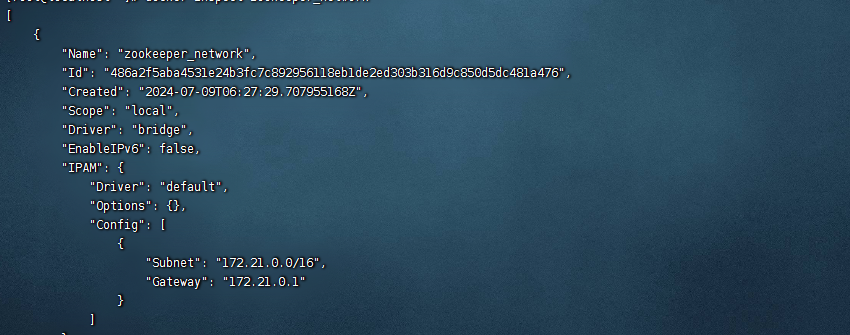
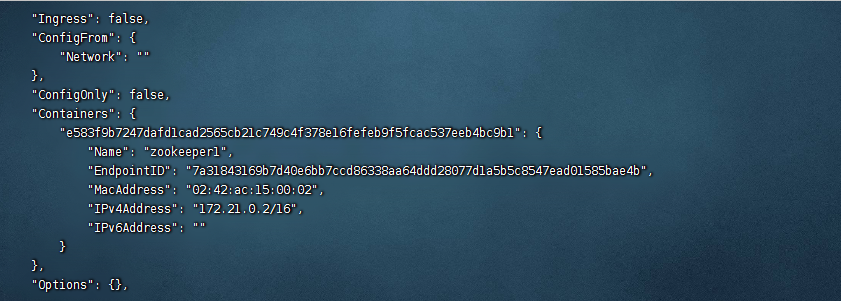
那个IPv4就是我们的网络环境的地址,这是我的网络环境的地址
我的是12.21.0.2,这个ip地址是要记住方便后面使用的
创建一个kafka容器
这段代码有点长,根子自己改吧
# 启动kafka
docker run -d --name kafka1 --network zookeeper_network -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=<zookeeperIP地址>:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://<宿主机IP地址>:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 wurstmeister/kafka解释
KAFKA_ZOOKEEPER_CONNECT 后面写的是我们的之前的网络的地址
KAFKA_ADVERTISED_LISTENERS=PLAINTEXT 我们的虚拟机(服务器)的本机的地址
不知道本机地址可以输入 ip addr来查看本机地址

这样子就搭建完成了
SpringBoot集成kafka
首先就是springboot和kafka的版本兼容了

然后我们引入两个kafka的依赖
<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>3.2.0</version> </dependency>
自己对着自己的版本来
自己看b站视频,9分钟就搞定了
63-kafka-集成-Java场景-SpringBoot_哔哩哔哩_bilibili
然后开始写我们的application.yml配置文件

下面是配置文件的全部+解析
其实和普通mq差不多
也就是配置生产者和消费者和一些过期时间超时时间
 重点在于那个missing-topics-fatal
重点在于那个missing-topics-fatal
主题不存在的话,我们是否还要成功启动
我自己的写的默认的主题是test,但是我还没在kafka里面创建,kafka里面还没有这个叫test的主题
所以我启动的时候,报错然后失败了
spring: kafka: bootstrap-servers: 192.168.88.130:9092 #Kafka 集群的地址和端口号 producer: acks: all #生产者发送消息时, Kafka 集群需要确认的确认级别。all 表示需要所有 broker 确认消息已经写入 batch-size: 16384 #生产者在发送消息时, 会先缓存一些消息, 达到 batch-size 后再批量发送。这个参数设置了批量发送的大小。 buffer-memory: 33554432 #生产者用于缓存消息的内存大小 key-serializer: org.apache.kafka.common.serialization.StringSerializer #定义了消息 key 和 value 的序列化方式。 value-serializer: org.apache.kafka.common.serialization.StringSerializer #定义了消息 key 和 value 的序列化方式。 retries: 0 consumer: group-id: test #消费者组ID #消费方式: 在有提交记录的时候,earliest与latest是一样的,从提交记录的下一条开始消费 # earliest:无提交记录,表示从最早的消息开始消费 #latest:无提交记录,从最新的消息的下一条开始消费 auto-offset-reset: earliest #当消费者没有提交过 offset 时, 从何处开始消费消息 enable-auto-commit: true #是否自动提交偏移量offset auto-commit-interval: 1s #前提是 enable-auto-commit=true。自动提交 offset 的间隔时间 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer #定义了消息 key 和 value 的反序列化方式 value-deserializer: org.apache.kafka.common.serialization.StringDeserializer #定义了消息 key 和 value 的反序列化方式 max-poll-records: 2 #一次 poll 操作最多返回的消息数量 properties: #如果在这个时间内没有收到心跳,该消费者会被踢出组并触发{组再平衡 rebalance} #消费者与 Kafka 服务端的会话超时时间 session.timeout.ms: 120000 #最大消费时间。此决定了获取消息后提交偏移量的最大时间,超过设定的时间(默认5分钟),服务端也会认为该消费者失效。踢出并再平衡 #消费者调用 poll 方法的最大间隔时间 max.poll.interval.ms: 300000 #消费者发送请求到 Kafka 服务端的超时时间 #配置控制客户端等待请求响应的最长时间。 #如果在超时之前没有收到响应,客户端将在必要时重新发送请求, #或者如果重试次数用尽,则请求失败。 request.timeout.ms: 60000 #订阅或分配主题时,允许自动创建主题。0.11之前,必须设置false allow.auto.create.topics: true #消费者向协调器发送心跳的间隔时间。 #poll方法向协调器发送心跳的频率,为session.timeout.ms的三分之一 heartbeat.interval.ms: 40000 #每个分区里返回的记录最多不超max.partitions.fetch.bytes 指定的字节 #0.10.1版本后 如果 fetch 的第一个非空分区中的第一条消息大于这个限制 #仍然会返回该消息,以确保消费者可以进行 #每个分区最多拉取的消息字节数。 #max.partition.fetch.bytes=1048576 #1M listener: #当enable.auto.commit的值设置为false时,该值会生效;为true时不会生效 #manual_immediate:需要手动调用Acknowledgment.acknowledge()后立即提交 #ack-mode: manual_immediate 手动 ACK 的方式。 #如果监听的主题不存在, 是否启动失败。 missing-topics-fatal: false #如果至少有一个topic不存在,true启动失败。false忽略 #消费方式, single 表示单条消费, batch 表示批量消费 #type: single #单条消费?批量消费? #批量消费需要配合 consumer.max-poll-records type: batch #并发消费的线程数 concurrency: 2 #配置多少,就为为每个消费者实例创建多少个线程。多出分区的线程空闲 #默认的主题名称 template: default-topic: "test" #springboot启动的端口号 server: port: 9999 #这个是java项目启动的端口
基本案例
这是常量类
指定了一个topic和group
主题和分组id
groupid是消费者组的唯一标识
这个视频9分钟看懂kafka
小朋友也可以懂的Kafka入门教程,还不快来学_哔哩哔哩_bilibili
生产者

我们这个Autowired自动注入,会根据我们的配置文件的配置来自动注入

@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
produces里面指定我们前端传的是json格式

我们往这个标题发送我们的消息,其实这个就是我们的常量类里面写的"test"

消费者

@KafkaListener(topics = SpringBootKafkaConfig.TOPIC_TEST, groupId = SpringBootKafkaConfig.GROUP_ID)
public void topic_test(List<String> messages, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
for (String message : messages) {
//因为这个String是Json,所以我们可以转回Object对象,其实是转成JsonObject对象
final JSONObject entries = JSONUtil.parseObj(message);
System.out.println(SpringBootKafkaConfig.GROUP_ID + " 消费了: Topic:" + topic + ",Message:" + entries.getStr("name"));
//ack.acknowledge();
}
}我们用List<String>来接收,因为可能一个消费者接收多条消息

指定消费者监听的主题topic
以及指定消费者的唯一标识GROUP_ID
这些其实都是自己在常量类里面自己写好的
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic
这个是得到我们的主题topic的名字

我用apifox调试之后,成功执行了


kafka的图形化工具
这里介绍一个免费的开源项目KafkaKing
Releases · Bronya0/Kafka-King (github.com)
里面还能指定中文
