
https://cvpr.thecvf.com/Conferences/2024/workshop-list06/17
https://opendrivelab.com/challenge2024/#why_these_tracks 06/17
1. End-to-End Driving at Scale
Rank1:Nvidia Hydra-MDP
End-to-end Multimodal Planning with Multi-target Hydra-Distillation
构建一个在复杂的物理世界中导航的自主系统极具挑战性。该系统必须感知其环境,并做出快速、明智的决定。乘客体验也非常重要,包括加速度、曲率、平顺性、道路附着力和碰撞时间。
原文链接:https://arxiv.org/abs/2406.06978
代码链接:https://github.com/NVlabs/Hydra-MDP
试图解决什么问题?
端到端自动驾驶,包括学习具有原始传感器输入的神经规划器,被认为是实现完全自主的有前途的方向。但最近的研究暴露了模仿学习(IL)方法的多个漏洞和局限性,特别是开环评估的固有问题,如功能失调的指标和隐式偏差。这是至关重要的,因为它不能保证安全、效率、舒适性和遵守交通规则。为了解决这个主要的局限性,一些工作提出了结合闭环指标,通过确保机器学习规划器满足基本标准,而不仅仅是模仿人类驾驶员,更有效地评估端到端自动驾驶。因此,端到端规划理想情况下是一个多目标和多模态任务,其中多目标规划涉及从开环和闭环设置中满足各种评估指标。在这种情况下,多模态表示每个指标存在多个最优解。
现有的端到端方法通常试图通过后处理来考虑闭环评估,这可能会导致额外信息的损失。同时这些不完美的输入降低了规划在闭环和开环度量下的性能,因为它们依赖于预测感知而不是地面真值GT标签。
解决方案是什么?
为了解决这些问题,作者提出了Hydra-MDP,一种新颖的师生知识蒸馏KD架构。
- Hydra-MDP以端到端的方式学习环境如何影响规划,而不是诉诸不可微分的后处理。
- 学生模型通过KD从人类和基于规则的教师那里学习适合各种评估指标的不同轨迹候选人。
- Hydra-MDP用一个多头解码器实例化多目标Hydra蒸馏,从而有效地整合了专业教师的知识。
- Hydra-MDP还具有可扩展的KD架构,允许轻松集成其他教师。
- 学生模型使用训练期间的环境观测,而教师模型使用地面真值(GT)数据。这种设置允许教师模型生成更好的规划预测,帮助学生模型有效地学习。
- 通过使用环境观察来训练学生模型,可以熟练地处理在测试期间无法获得GT感知的真实条件。

该方法在Navsim挑战赛中获得了第一名,在不同驾驶环境和条件下的泛化能力有了显著提高。
主要贡献是什么?
提出了一个通用的端到端多模态规划框架,Hydra-MDP模型能够以可扩展的方式向基于规则的规划器和人类驾驶员学习。
基本原理是什么?
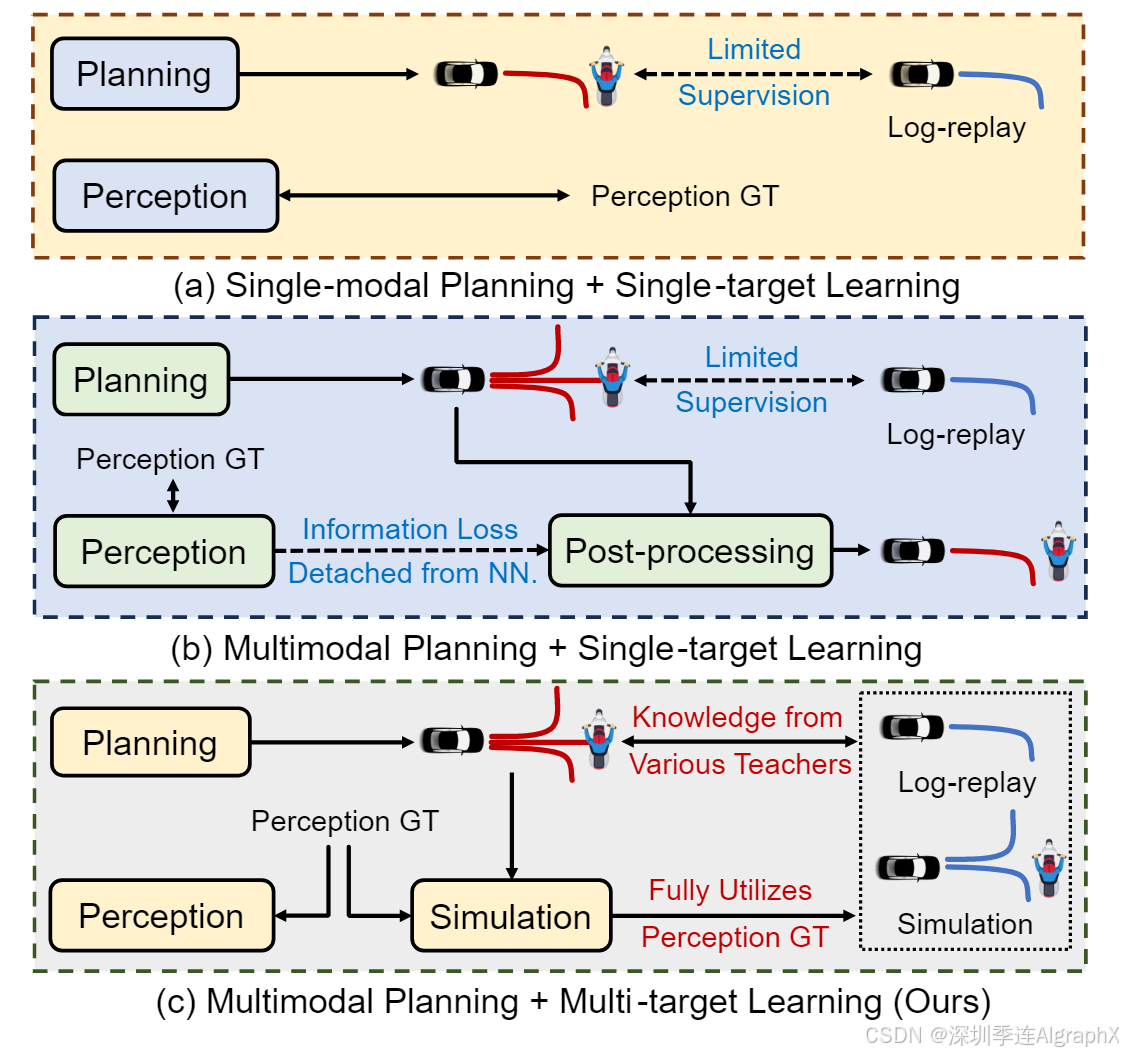
Figure 1. Comparison between End-to-end Planning Paradigms.
作者提出了C这种模式,通过神经网络同时预测各种成本(例如,碰撞成本,可驾驶区域合规成本)。这是以师生蒸馏的方式进行的,其中教师可以获得地面真值感知,但学生仅依赖传感器观察。
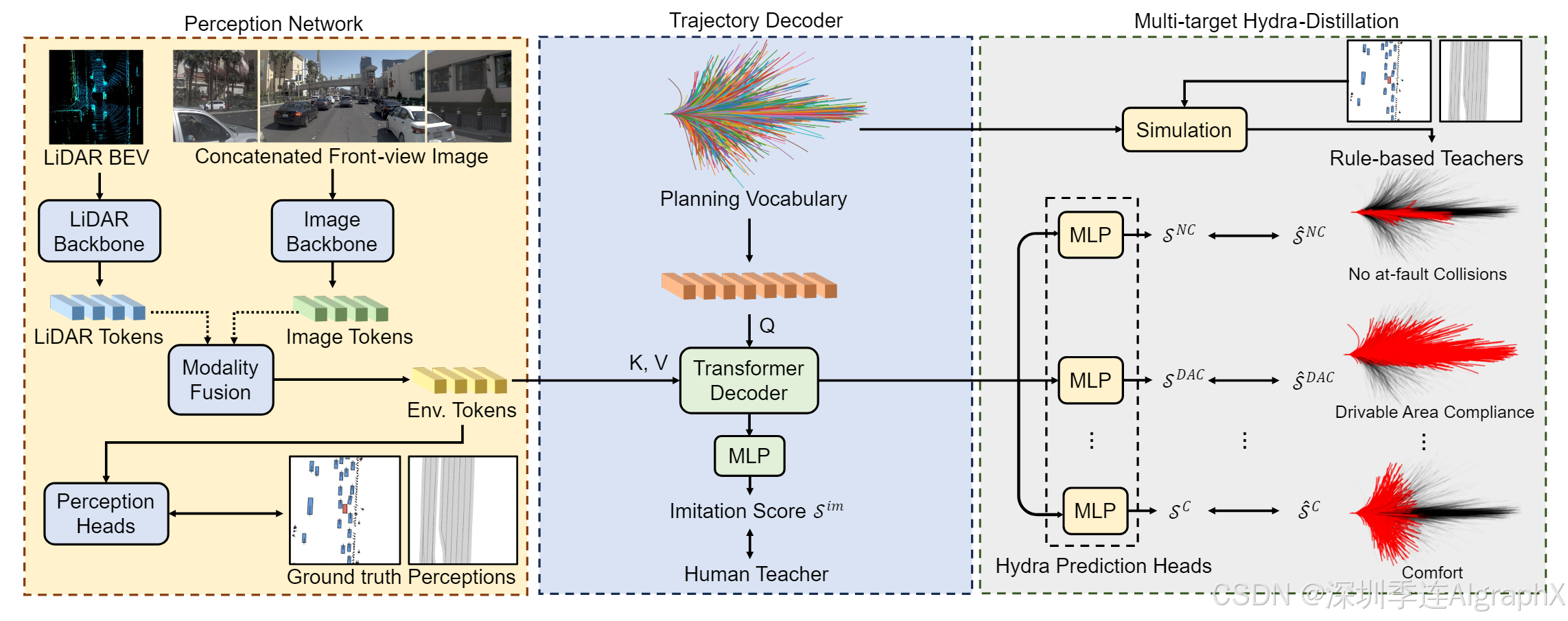
Figure 2. The Overall Architecture of Hydra-MDP
Hydra-MDP由两个网络组成:感知网络和轨迹解码器。
感知网络Perception Network
建立在基线 Transfuser 上,该基线由图像主干、LiDAR 主干和感知头组成,用于 3D 对象检测和 BEV 分割。多个Transformer层连接来自两个主干阶段的特征,从不同模式中提取有意义的信息。感知网络的最终输出包括环境标记 Fenv ,它对从图像和 LiDAR 点云派生的丰富语义信息进行编码。
轨迹解码器Trajectory Decoder
遵循VADv2,构建了一个固定规划词汇表来离散化的连续动作空间。为了构建词汇表,首先从原始的nuPlan数据库中随机抽取700K条轨迹。每条轨迹由40个时间戳组成,对应于挑战中所需的10Hz频率和4秒的未来时间范围。规划词汇表Vk是通过700K条轨迹的K-means聚类中心形成,其中k表示词汇表大小。然后,Vk被嵌入为k个潜在查询,通过多层感知机(MLP)发送到Transformer编码器层,并添加到自身状态E中。
为了将Fenv中的环境线索纳入考虑,利用了Transformer解码器。同时,使用日志回放Log-Replay轨迹,实现了一个基于距离交叉熵损失来模仿人类驾驶员。这种模仿目标的直观想法是奖励接近人类驾驶行为的轨迹提案。
Multi-target Hydra-Distillation
虽然仿真目标为规划者提供了一定线索,但在闭环设置下,模型无法将规划决策与驾驶环境联系起来,因而导致碰撞、离开可驾驶区域等故障。为了提高端到端规划器闭环性能,提出了多目标Hydra-Distillation,这是一种学习策略,可以将规划器与基于仿真的指标结合起来。
蒸馏过程通过两步扩展了学习目标:
(1)对整个训练数据集的规划词汇Vk进行离线仿真;
(2)在训练过程中对Vk中的每条轨迹引入仿真分数监督。利用二元交叉熵损失,将基于规则的驾驶知识提取到端到端规划器中。
推理Inference
给定预测的仿真分数和度量子分数,计算了一个集合代价来衡量给定场景下每条轨迹被选择的可能性。通过网格搜索得到最优的权重组合,最后选择总成本最低的轨迹。
后处理Post-processing
提出了两种模型集成技术:编码器混合集成和子分数集成。前者使用线性层组合来自不同视觉编码器的特征,而后者计算来自独立模型的子分数加权和以进行轨迹选择。
实验效果怎么样?
如表1所示,Hydra-MDP相对于基线有绝对的优势。
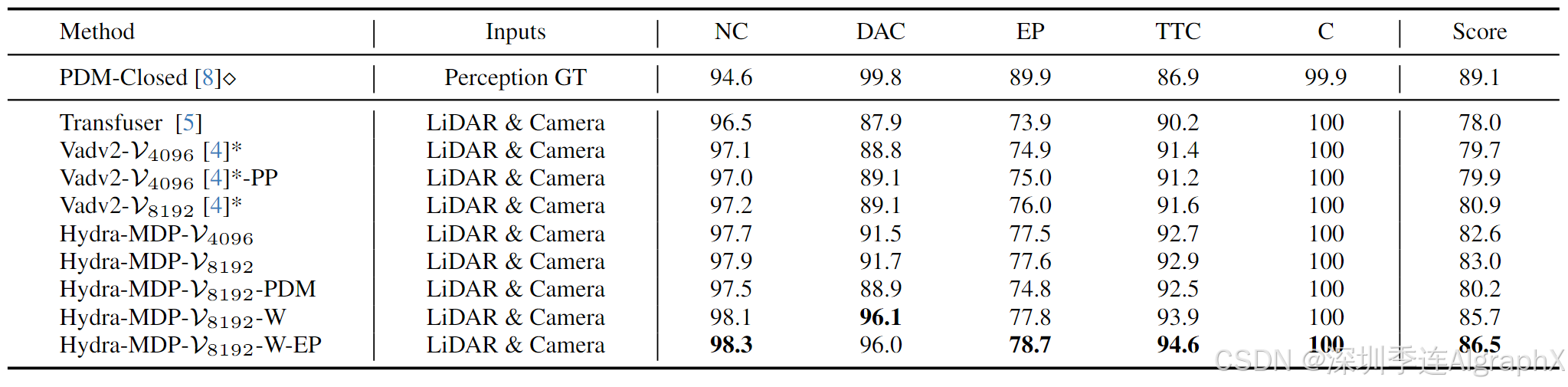
表2展示了使用ViT-L和V2-99作为图像主干的情况。

Rank2:零一汽车
End-to-End Autonomous Driving Using Vision Language Model
该方法仅使用一个摄像头,并在排行榜上成为最佳仅使用摄像头解决方案,证明了基于VLM方法的有效性和端到端驾驶任务的潜力。
2. Mapless Driving
在没有高精地图的情况下,自动驾驶汽车需要高水平的场景理解能力,本赛道旨在探索道路场景地图推理与生成能力的极限。将多视角图像和导航地图作为输入信息,神经网络不仅要输出车道和交通元素的检测结果,同时还须输出车道之间、车道和交通元素之间的拓扑关系。
由5个子任务组成,包括3个检测任务和2个拓扑推理任务
- Lanesegment-车道
- Area-道路边界
- 人行横道、2D交通元素检测
- 车道和车道拓扑关系
- 车道和交通元素拓扑关系
Rank1:朗歌科技 LGmap
LGmap: Local-to-Global Mapping Network for Online Long-Range Vectorized HD Map Construction
https://opendrivelab.github.io/Challenge%202024/mapless_LGmap.pdf
本文介绍了一种新颖的在线映射管道 LGmap,它擅长远程时间模型。首先,作者提出了对称视图转换(SVT),这是一种混合视图转换模块。本方法克服了前向稀疏特征表示的局限性,并利用深度感知和 SD 先验信息。其次,提出了分层时间融合(HTF)模块。它使用来自局部到全局的时间信息,这使得构建具有高稳定性的远程高清地图成为可能。最后,提出了一种新颖的人行横道 ped-crossing 重采样。简化的 ped-crossing 表示加速了基于实例注意力的解码器收敛性能。
总之,该方法结合了前、后投影策略、SD地图融合及深度监督,实现从近及远的地图融合。同时,提出了一个适用于长短距在线地图绘制流程,融合了流处理和堆叠策略。
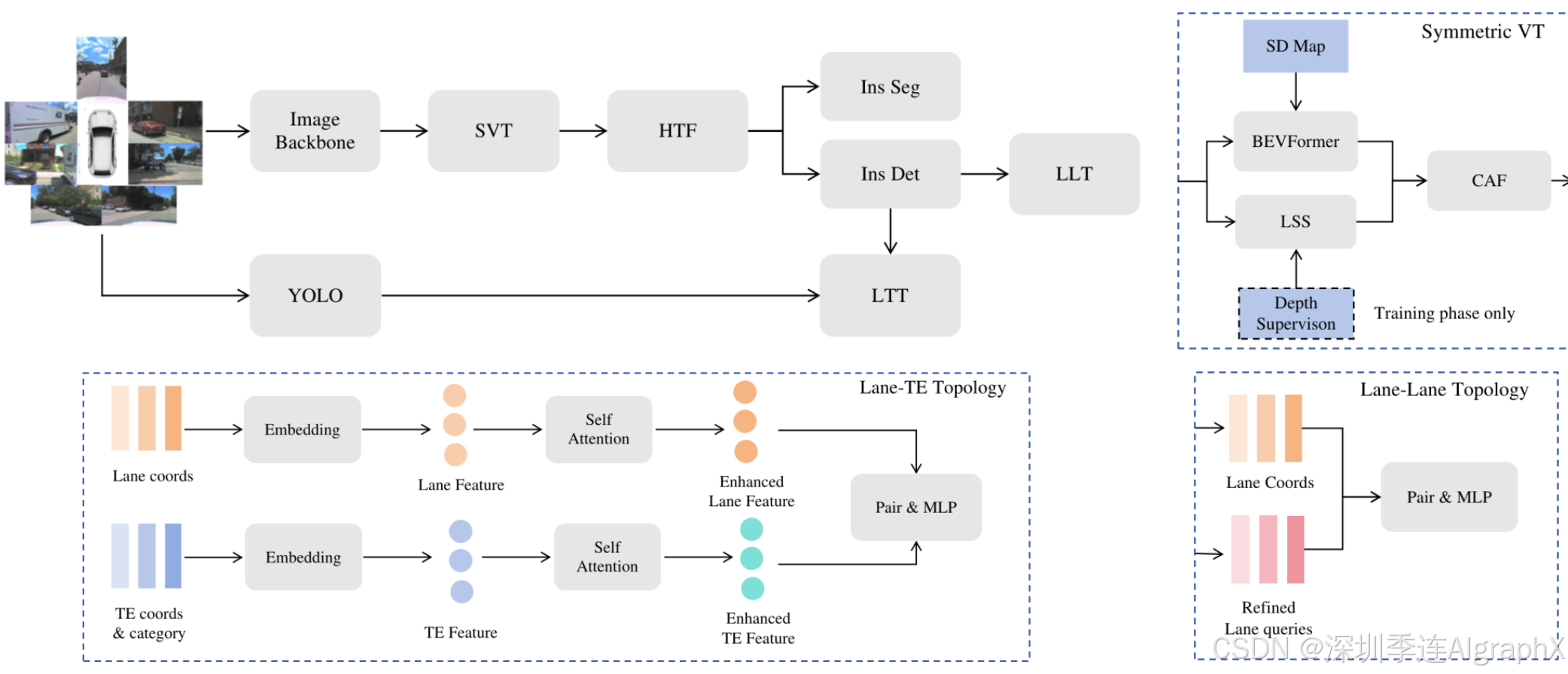
Figure 1. The overall model architecture of LGmap. The entire model is consists of mainly six components: a image backbone equipped with SVT(Symmetric View Transformation), a hierarchical temporal fusion(HTF) module, a unified instance detection and segmentation predictor, a traffic elements detector(YOLO), a Lane-Lane Topology(LLT) and a Lane-Traffic topology(LTT).
Encoder
当前主要有两种类型的视图转换,前向投影LSS和后向投影BEVFormer。Lift-Splat-Shoot,做前向投影,利用深度分布来模拟每个像素深度的不确定性,擅长几何信息提取,但缺点是离散的和稀疏的BEV表示。BEVFormer做后向投影,将3D点投影回2D图像,擅长语义信息,限制是由于遮挡而导致的 3D 和 2D 空间之间的虚假相关性。
为了解决这些问题,作者引入了一个对称视图转换SVT。每个相机的深度图是由同步激光雷达点云生成的。LSS 仅在训练阶段利用深度监督。给定场景的 SD 图,沿着每条折线均匀采样固定数量的点。使用正弦嵌入,BEVFormer 在每个编码器层上使用来自视觉输入特征在 SD 地图特征表示之间应用交叉注意。
为了融合不同特征的BEV表示,使用了通道注意融合模块CAF。
Decoder
为了处理具有不同形状先验的不同地图元素,作者使用额外的分割任务扩展了实例检测解码器。受益于像素级分类任务和区域级回归任务,提出了基于统一Transformer解码器(例如检测和分割)。额外的分割分支加速了实例特征嵌入的收敛性能。
Temporal fusion
目前主流的时序融合方法主要是堆叠式stacking和流式streaming两种。基于流式的时序融合,有一定的局部地图记忆能力,计算和存储消耗小,并且存在遗忘的问题。基于堆叠式的时序融合,可以灵活地做长距离地图信息的融合,但是存在线性增长的计算和存储消耗。
流策略促进了更长的时间关联,因为传播的隐藏状态编码了所有历史信息。但是 convGRU 等时间融合器仍然可能面临遗忘问题。堆叠策略可以整合来自特定前一帧的特征,为远程信息融合提供了灵活性。计算成本与融合帧数呈线性关系。作者提出了一种新的分层时间融合(HTF)。分层时间融合充分利用了流策略的局部融合能力和堆叠策略的远程融合能力。与堆叠策略相比,它最小化了内存和延迟成本。在这里,提出了两种HTF、流流流策略和流堆叠策略的变体,如图2所示。对于流堆叠策略,在训练阶段从最新的M个前一帧中随机选择N帧进行堆叠模式层。并在测试阶段以一定的距离步长选择N帧。
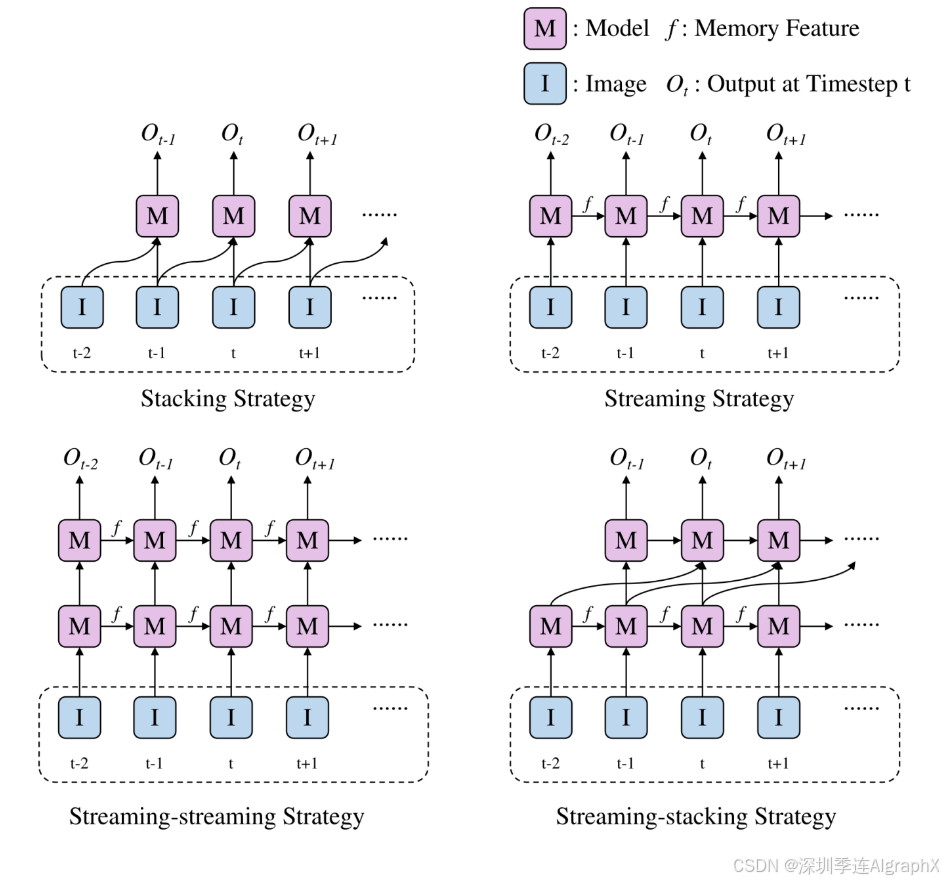
Figure 2. Stacking strategy and streaming strategy are same as StreamMapNet's summary. In order to demonstrate the effectiveness of long-range stacking for streaming-stacking strategy in figure, the stacking previous frame interval parameter is set to 2. Stacking strategy only fuses one previous frame in this figure, and actually it may fuse more than one frame.
Area
基于关键点的人行横道矢量化表达
人行横道ped crossing是3D道路元素检测中的一个主要类别,在数学定义上是个封闭的四边形。MapTR方法中的矢量化表达形式,是做等间隔的20个点的采样(下图左),这样存在的问题是采样点可能不在角点上,会产生信息损失,不能精确地表达几何形状;MachMap采用了4个角点的表达形式(下图中),但他们是建模成分割任务,通过对分割结果做后处理的方式得到,不是端到端的方法。受Machmap的启发,LGmap的ped-crossing表示保留了四个角作为关键点,这是基本的形状先验。在每条边上等间隔采样4个辅助点的形式(下图右),这样关键点+辅助点的组合形式,既保证了精确的几何形状,又能以检测的形式端到端地输出矢量化结果。保留角有利于实例查询嵌入。

Figure 3. The ped crossing form of MapTR, MachMap and LGmap.
Lane segments
基于回归分支的中心线输出,引入偏移分支来预测左右车道边界的偏移量,并引入两个分类分支来预测车道边界的属性,参考LaneSegNet。
Traffic elements
利用YOLOv8作为基础2D检测器,另外利用YOLOv9进行模型集成。基于OpenlaneV2数据集,提出了一系列数据增强,不包括HSV和水平翻转,因为这些技巧可能会导致红绿灯的混淆和交通标志的方向。数据集中类别的分布高度不平衡,有些类别相差一个数量级。此外,在测试集上生成的伪标签可以改善结果。采用尺度范围为 0.7-1.4 的测试时间增强 (TTA) 来提高小物体和大物体的召回率。
Lane-Lane topology
使用TopoMLP方法。首先,将中心线坐标传递给 MLP,并将它们添加到细化的查询特征中。最后,应用 MLP 来执行拓扑分类。
Lane-Traffic topology
使用中心线的坐标,以及交通元素盒中的坐标和类别。由于没有使用特征嵌入,使用车道段和交通元素的地面真实数据来训练拓扑模型。通过与上游检测模型解耦,使拓扑的训练和预测过程更加方便。由于交集的复杂性,使用自关注来促进元素之间的信息交换,获得相对关系。
拓扑推理,首先分别提取3D道路元素和2D交通元素的检测结果,然后使用多层感知机做特征的映射,最后将两组特征拼接起来,预测对应的拓扑关系矩阵。这里,考虑到路口场景的拓扑关系复杂性,车道和交通元素的特征分别添加了自注意力机制,使得元素之间的信息有了交互和传播,更有助于拓扑关系的推理。
Loss functions
首先,采用与MapTR相同的分类损失、点对点损失和边缘方向损失。其次,采用与MapTRv2相同的图像分割辅助密度预测损失和深度预测损失。第三,采用BEV实例分割损失。最后,采用几何三维损失。与GeMap忽略z轴的几何损失不同,将欧几里德损失维度从2d扩展到3d。
Rank2:小米 mapless-xiaomiev
Leveraging SD Map to Assist the OpenLane Topology
https://opendrivelab.github.io/Challenge 2024/mapless_XIAOMIEV.pdf
SD地图具有成本效益,可广泛用于人类和自动驾驶系统。考虑到SD地图固有的基本道路几何、车道信息和连通性,作者试图探索其与多视图图像的互补信息,以解决Open-Lane拓扑问题。如图1所示,SD地图提供了基本的道路布局和几何信息,这些信息有助于指导构建更详细的高清地图。为此,首先设计了一个SD地图编码器,对SD地图中的矢量化元素进行编码,并在Bird Eye's View (BEV)特征的指导下进行编码,以提供丰富的空间上下文信息。然后将增强的SD地图标记进一步集成到车道检测头中,作为更好的道路布局感知额外模式。
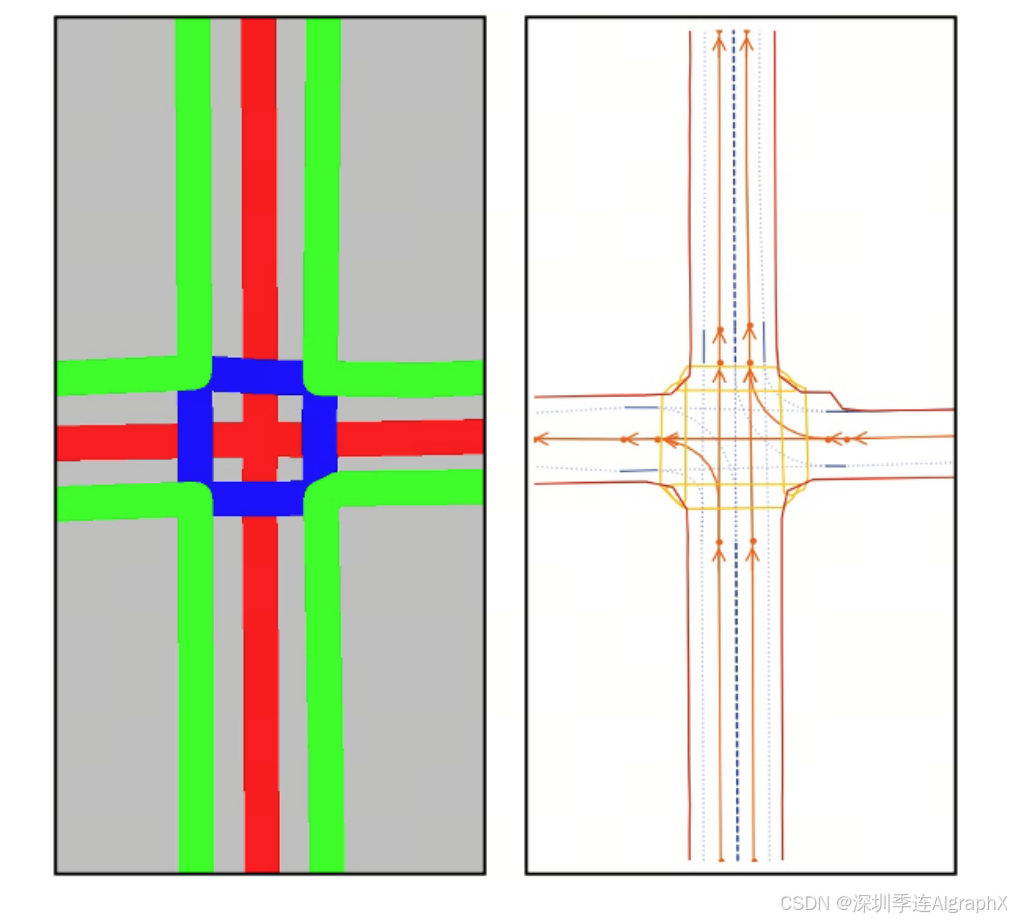
Figure 1. The left image is a sample SD map, and the right one is its corresponding HD map ground-truth. Though the SD map has relatively limited details, it provides a high-level description of the road in a coarse manner, which is important for distant or complex scenes.
此外,作者还提出了车道检测头动态位置编码方案,以进一步提高性能。传统上,位置编码被表述为可学习的标记,并且在检测头的不同车道注意层保持固定。然而,这种静态困境不利于提供精确的定位信息,影响了定位精度。注意到中间层车道点已经满足了更明确和精确位置线索。在逐层架构中,每一层预测的车道点自然会以从粗到精的方式进行细化,从而为底层驾驶场景提供更准确的位置信息。此外,车道点在不同的场景中也会发生变化。在这两个观测值的激励下,作者基于参考点的中间输出更新每个车道注意层位置编码,从而获得更精确的位置感知和更高检测精度。
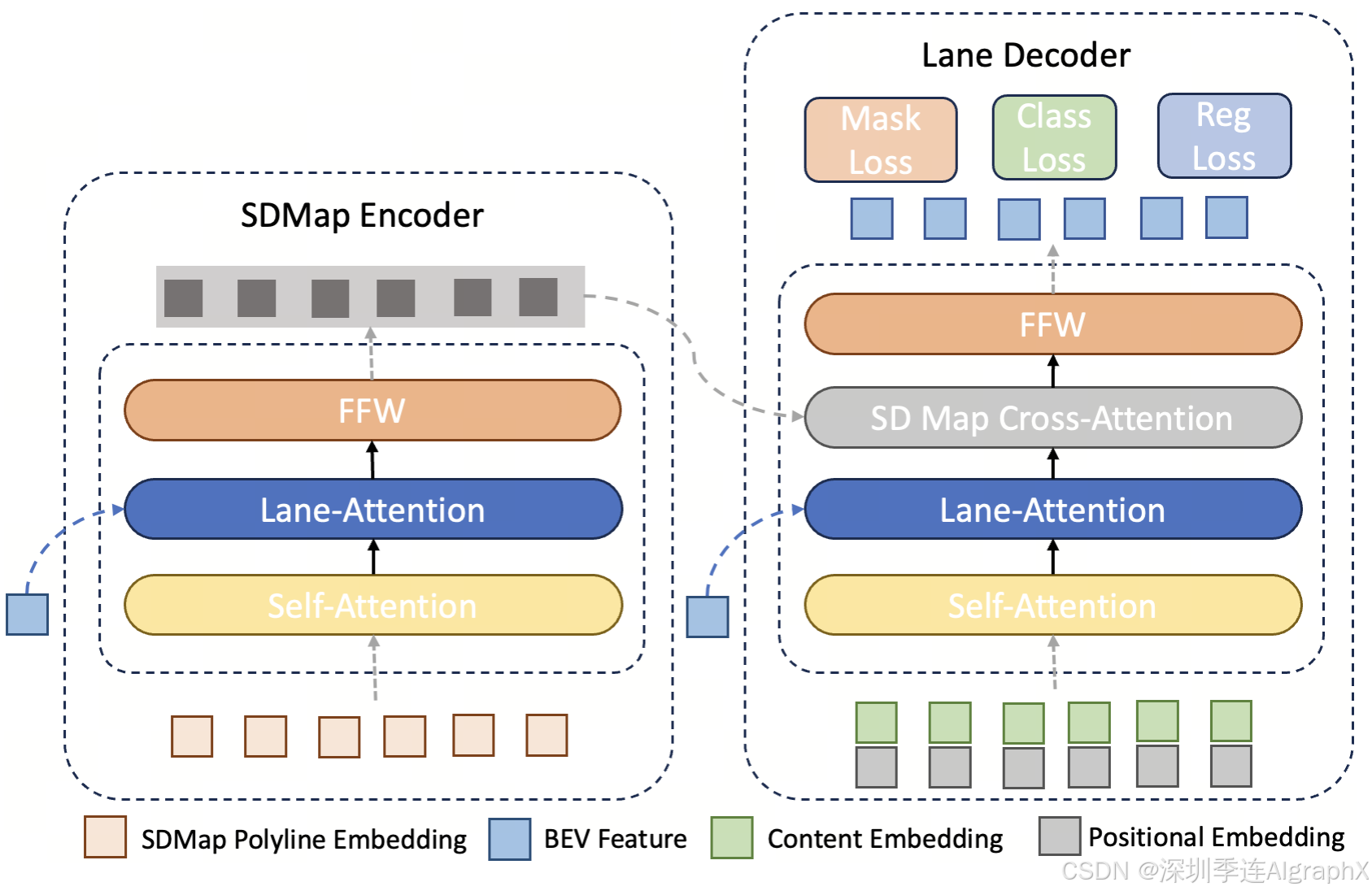
Figure 2. The architecture of our proposed SD map Encoder and Lane Decoder. The SD map Encoder is based on transformer with the cross-attention layer be replaced with the Lane-Attention layer to better preserve the structural information from the BEV feature map. The lane decoder is also built upon transformer, with an additional cross-attention layer to absorb the output of the SD map encoder for road layout information.
总的来说,方法分为四个连续的部分。
- 首先,给定多视图输入图像,使用BEVFormer构建BEV特征。
- 其次,基于BEV特征,构建SD地图编码器,提取具有跨模态交互的SD- map特征。
- 第三,引入了一种新的集成方法,可以进一步提高性能。
- 最后,利用多层感知器(MLP)将拓扑关系与道路元素检测解耦,提高了拓扑预测精度。
SD地图编码器,车道解码器和拓扑预测是作者的主要贡献。
SD Map Encoder
给定SD图,目标是使用改进的Transformer解码器从折线中提取跨模态特征,如图2所示。
Lane Decoder
利用增强的SD地图特征和BEV特征,构建车道解码器来预测道路要素的坐标。采用带通道注意实现的Transfromer解码器构造通道解码器。为了获得跨模态对齐,在每个车道注意层之后堆叠一个额外的SD地图交叉注意层,以合并SD地图特征。如图3。
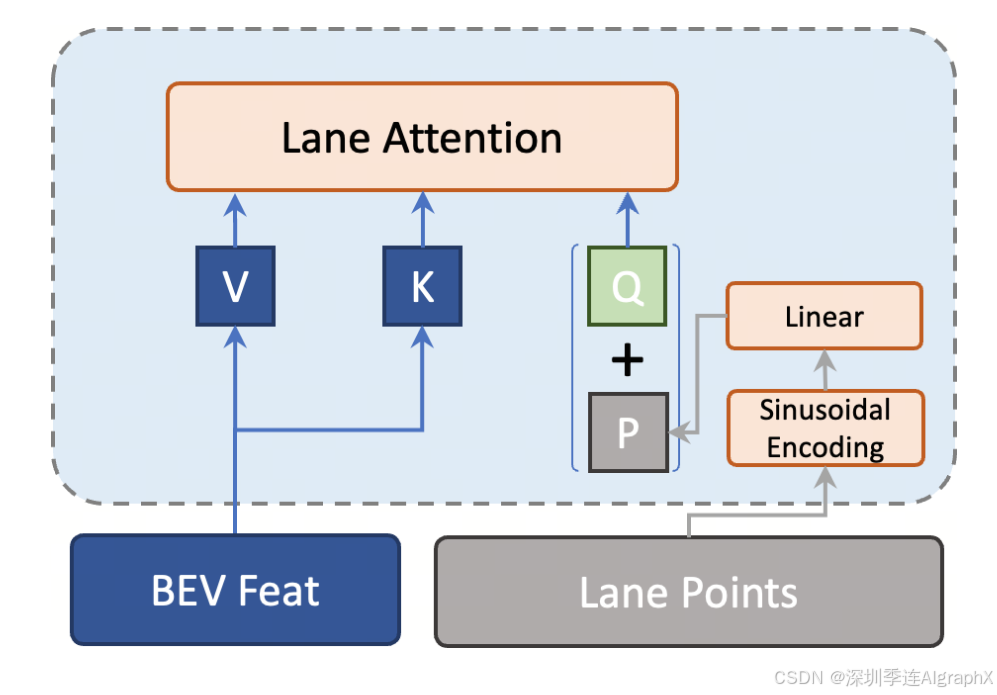
Figure 3. The dynamic positional encoding scheme which updates the positional encoding for each lane attention layer in the lane detection head based on predicted lane points of previous layer.
Topology Prediction
大多数现有方法在多任务框架中推断道路拓扑以及道路元素检测任务。然而,在拓扑预测任务中,正(相关元素)和负(非相关元素)样本的数量高度不平衡,这使得在多任务框架中难以训练和微调。为了更好地处理拓扑预测任务中的不平衡问题,作者提出将其与多任务框架解耦,并在后续阶段基于信道解码器的检测结果进行解决。
采用类似TopoMLP的多层感知器模型对不同训练参数的车道-车道拓扑和车道-元素拓扑进行预测。该MLP的输入由两部分组成:第一部分是车道解码器的预测,该解码器满足道路之间的几何信息。为了进一步补充几何特征,还考虑了一条车道端点到另一条车道起点之间的距离。两条车道的起点和终点越近,它们就越有可能在拓扑上相连。在车道元素拓扑预测方面,利用前视摄像头中交通元素的边界框坐标和摄像头的外在参数对交通元素信息进行编码。
3. Predictive World Model
Rank1:中国科学技术大学
The 1st-Place Solution for CVPR 2024 Autonomous Grand Challenge Track on Predictive World Model
https://opendrivelab.github.io/Challenge 2024/predictive_USTC_IAT_United.pdf
作者引入了一个世界模型,该模型可以根据当前状态预测未来的状态。首先利用具有多个摄像机视图的高质量自动驾驶数据集进行自监督训练。接下来,改进竞争基线来预测未来点云。具体来说,首先使用预训练的 BEV 编码器作为特征提取器,并在 BEV 编码器内增强时间对齐模块。然后,利用潜在渲染算子来提取更独特和有代表性的特征,并提高 Transformer 解码器中的注意力机制。最后,输出预测的未来点云。
作者重点改进了BEV编码器和Transformer解码器关键模块。
- 与BEVFormer类似,BEV编码器由6层组成,每层遵循传统的Transformer结构,但有三个自定义设计的改进措施:BEV查询、空间交叉注意和时间自我注意。具体来说,BEV 查询是基于网格的可学习参数,旨在通过注意力机制从多摄像头视图中查询 BEV 空间中的特征。空间交叉注意和时间自我注意是与BEV查询结合使用的注意层,分别从多摄像头图像和历史BEVs的时间特征中定位和聚合空间特征。主要改进时间注意模块来实现BEV时间对齐和融合。
- Transformer解码器,其以自回归方式预测时间戳t∈{1,2,...}处的未来BEV特征。随后,利用预测头将BEV特征投影到3D占用体积中,确保环境的精确空间表示。在Transformer Encoder中的时间交叉注意中,还将先前的改进应用于时间模块。
作者提出多阶段框架和两阶段点云预测方法,结合多视角自监督训练和对比学习技术,有效提取了BEV特征,并通过时间交叉注意力机制的优化,提升了模型对未来点云数据的预测能力。此外,作者还通过BEV查询、空间交叉注意力和时间自注意力机制,有效整合了多相机图像空间和时间特征,提高了多相机系统的准确性和鲁棒性。
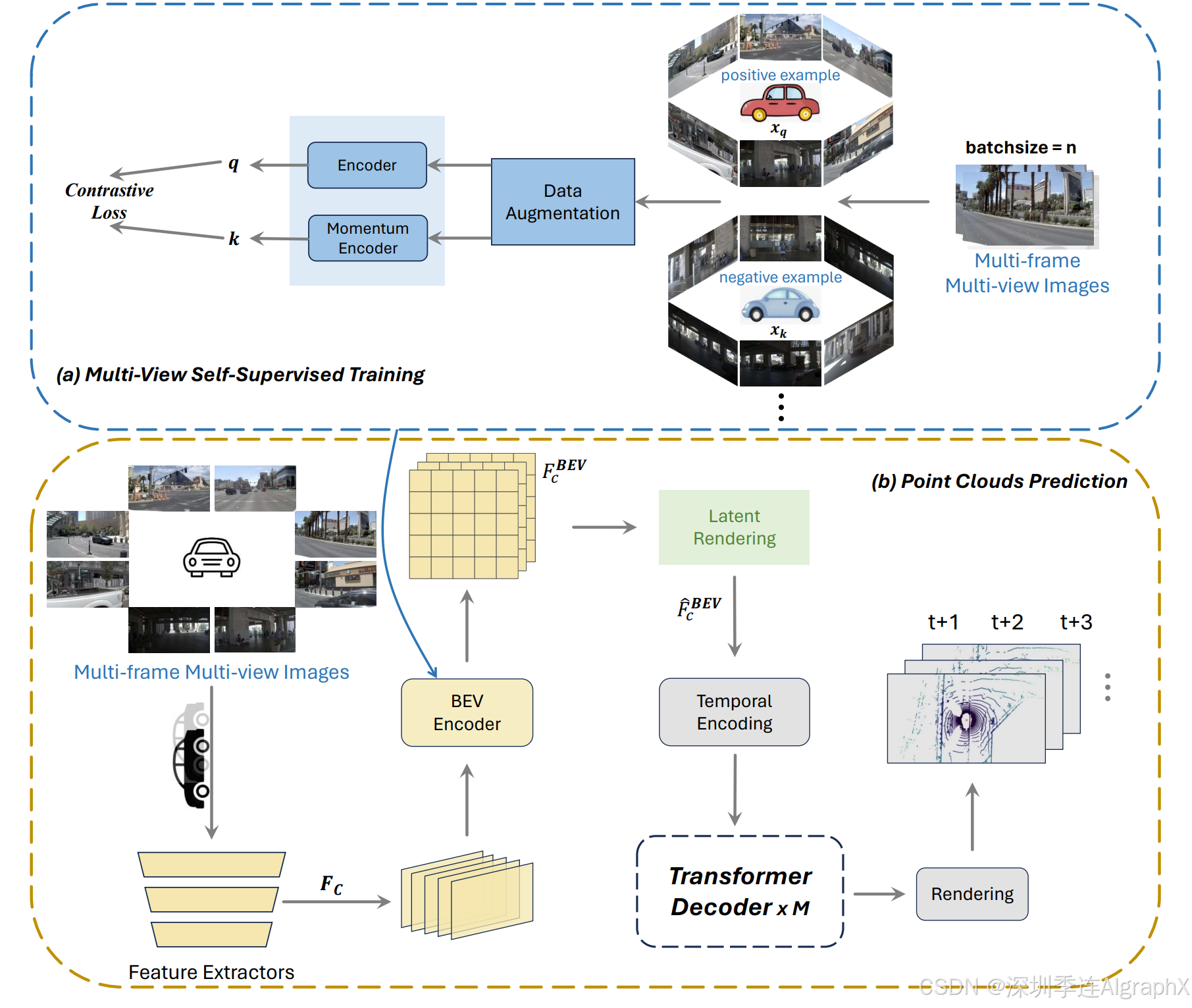
Figure 2. The architecture of our proposed method. We present a two-stage framework. (a) Multi-View Self-Supervised Training: We use contrastive learning to train multi-view camera images; (b) Point Clouds Prediction: We input the multi-view image to be trained, we read the BEV Encoder pre-trained in the previous stage, and output the final point clouds prediction through each subsequent module.
Rank2:华为 / 香港中文大学 D2 -World
D2 -World: An Efficient World Model through Decoupled Dynamic Flow
4. Occupancy and Flow
Rank1:浪潮信息
3D Occupancy and Flow Prediction based on Forward View Transformation
https://opendrivelab.github.io/Challenge 2024/occ_IEIT-AD.pdf
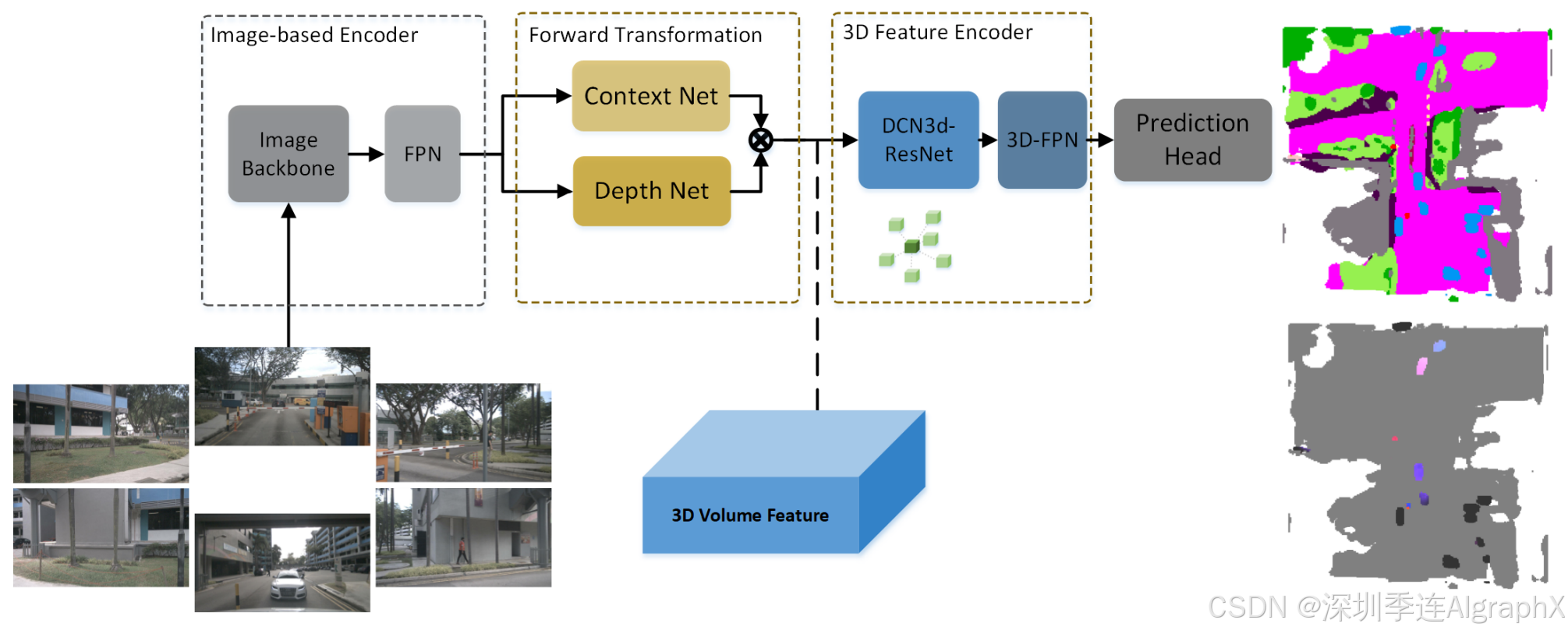
Figure 1. Overall architecture. The view transformation is based on the forward projection strategy (LSS ,BEVDepth ). The 3D feature encoder utilizes the deformable 3D convolution core. Prediction results encompass the occupancy semantics and flow. The color in the flow map indicates voxel orientation and the intensity reflects the velocity magnitude. Background voxels are depicted in gray to distinguish them from foreground objects.
Rank2:澳门大学 / 嬴彻科技
AdaOcc: Adaptive Forward View Transformation and Flow Modeling for 3D Occupancy and Flow Prediction
5. Multi-View 3D Visual Grounding
Rank1:清华大学 / 联想 DenseG
DenseG: Alleviating Vision-Language Feature Sparsity in Multi-View 3D Visual Grounding
https://opendrivelab.github.io/Challenge 2024/multiview_THU-LenovoAI.pdf

本文介绍了一种通过多角度定位和逻辑调整来提高目标对象描述准确性的方法。首先,通过利用场景中物体的多种位置关系,确保足够的可靠锚点来减少干扰。其次,对于依赖于视角的文本,采用相反视角重新表述并调整空间关系;对于不依赖于视角的文本,则通过增加锚点来丰富上下文。最后,确保所有修改,包括新增的位置关系和视角,都具备高度的准确性。这种方法旨在保持目标对象及其位置关系的一致性,从而提高整体描述的准确性和可靠性。
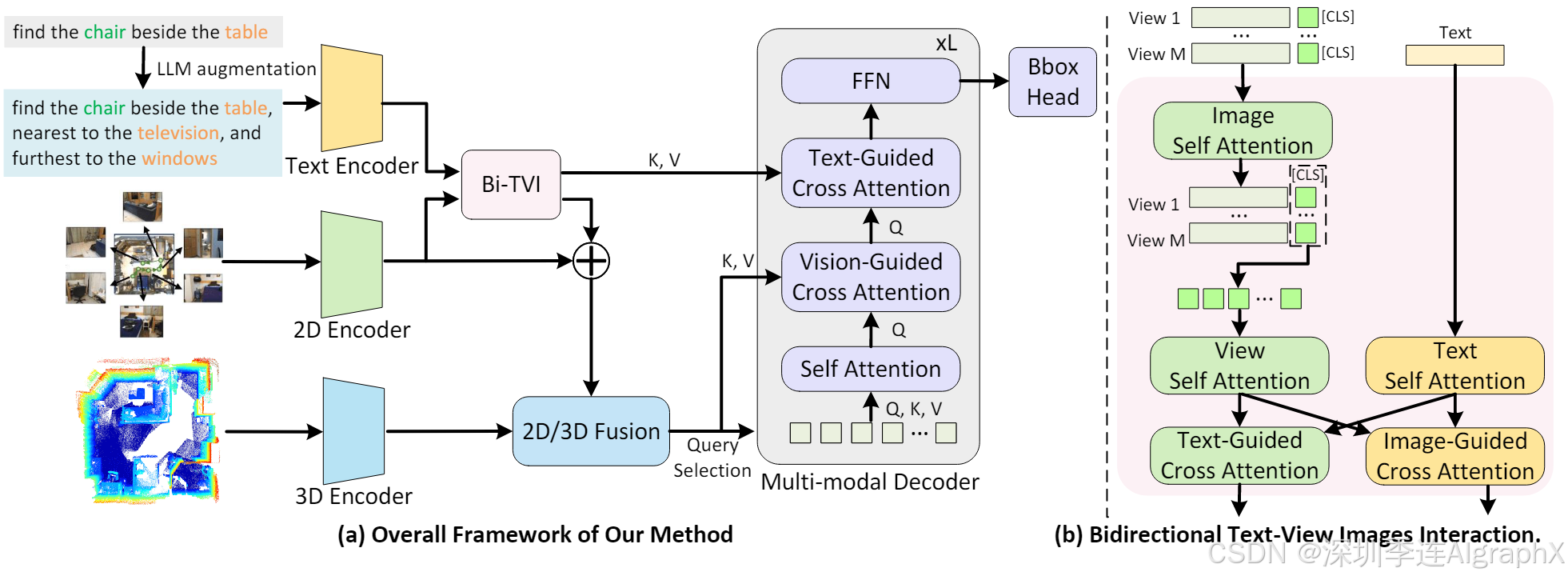
鉴于 EmbodiedScan 在多视图 3D 视觉基础中的出色性能,提出了本论文模块。
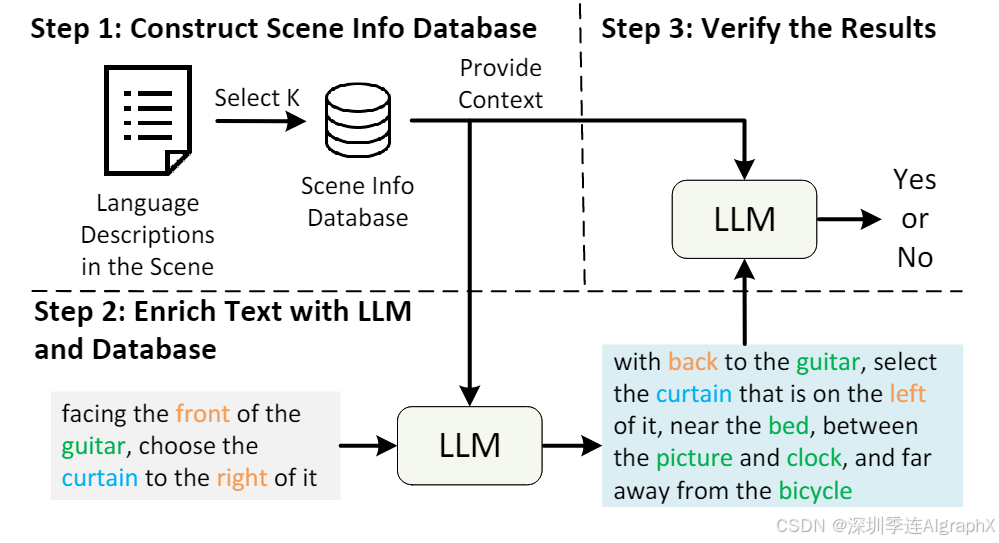
Figure 3. LLM Augmentation Pipeline.
6. Driving with Language
Rank1:南京大学
Driving with InternVL
https://opendrivelab.github.io/Challenge 2024/language_NJU-ImagineLab.pdf
(类似论文比较多,在这里不再赘述)
Submissions with Offline Label
Rank1:华东师范大学
The System Description of CPS Team for Track on Driving with Language of CVPR 2024 Autonomous Grand Challenge
https://opendrivelab.github.io/Challenge 2024/language_CPS.pdf
通过结合视觉语言模型(VLMs)和深度估计技术,基于LLaVA模型,结合LoRA和DoRA方法,并使用DriveLM-nuScenes数据集训练,成功提升了自动驾驶系统的决策能力。该系统能够融合视觉与语言信息,实现准确的环境感知和可泛化、可解释的驾驶行为。
此外,作者还利用nuScenes 2数据集和DepthAnything模型,进一步提升了目标深度信息的精度,并通过转化为文本距离描述,使深度信息更易于应用。

Rank2:长安汽车 BeVLM
BeVLM: GoT-based Integration of BEV and LLM for Driving with Language
https://opendrivelab.github.io/Challenge 2024/language_ADLM.pdf
BeVLM通过BEV编码器提取视觉特征,并通过适配器模块与文本特征对齐,实现了对摄像头视角和重要物体位置的敏感捕捉。通过将BEV表示与文本上下文融合,增强了LLM与多视图视觉数据之间的一致性。其次,作者还开发了一种融合音频和文本特征的VQA系统,增加问答(QA)对,以促进跨模式对齐,弥合不同模式之间的差距。最后,设计了一个思维图(GoT)方案,使多模态LLM能够全面理解视觉和文本上下文。
实验表明,BeVLM能有效提升自动驾驶任务中语言模型对4D特征的理解能力,为跨模态理解提供了新的解决方案。
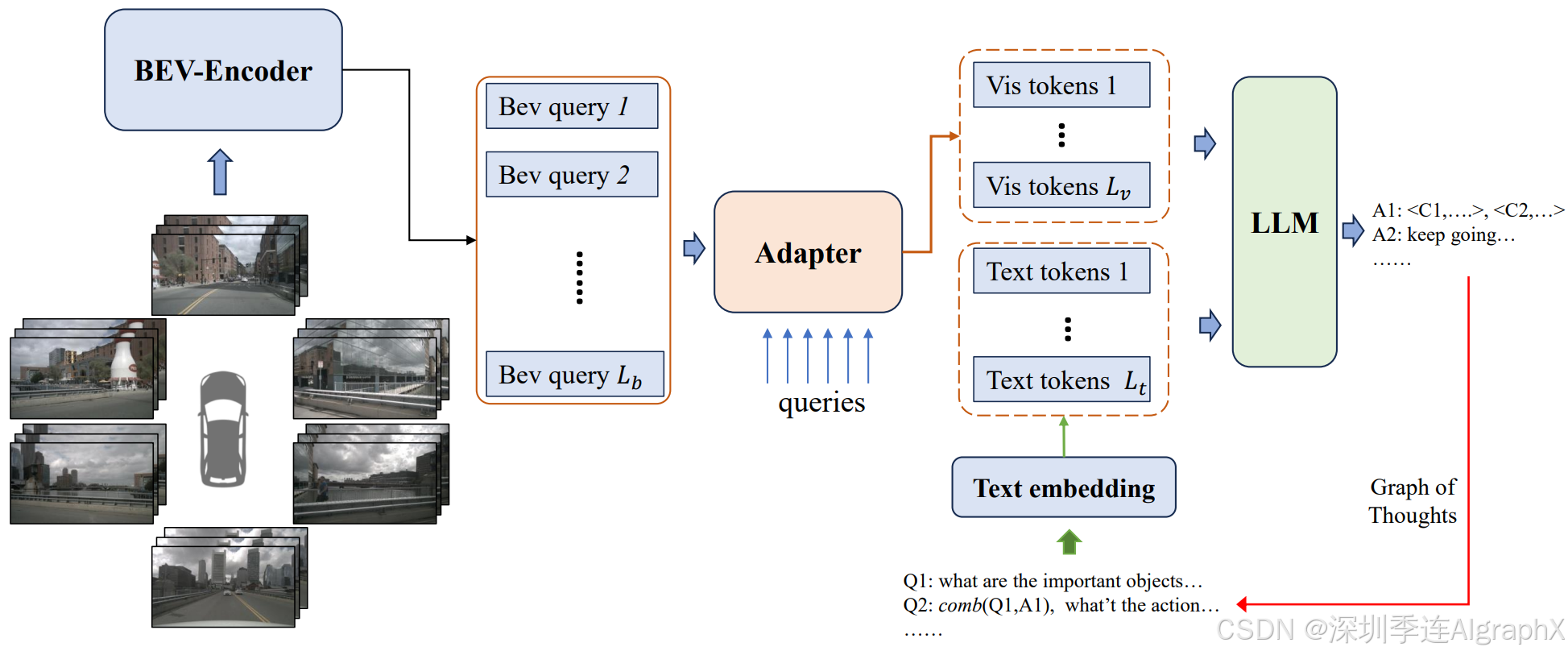
Figure 1. The pipeline of our BeVLM. Our method takes multi-view images as input and extracts features separately using the BEV encoder. Next, we utilize an adapter to extract visual tokens, aligning visual features with textual features. Finally, we input all features into the LLM to obtain the answer.
7. CARLA Autonomous Driving Challenge
***7.1 传感器-***CarLLaVA
Rank1:英国 Wayve / University of Tübingen
CarLLaVA: Vision language models for camera-only closed-loop driving
https://opendrivelab.github.io/Challenge%202024/carla_LLM4AD.pdf
CarLLaVA 使用 LLaVA VLM 的视觉编码器和 LLaMA 架构作为主干,仅使用相机输入实现了最先进的闭环驾驶性能,并且不需要复杂或昂贵的标签。
CarLLaVA采用了一种半解耦的输出表示方式,既包含路径预测(path predictions)也包含航点(waypoints),从而在横向控制上利用路径的优势,在纵向控制上利用航点的优势。
-
仅使用相机传感器且无需昂贵的标签:方法仅使用相机输入,消除了对鸟瞰图(BEV)、深度或语义分割等额外昂贵标签的需求。这种无需标签的方法减少了对大量标注数据集的依赖,使其更容易在实际车辆上部署。
-
视觉语言预训练:方法利用了在互联网规模视觉语言数据上预训练的LLaVA-NeXT视觉编码器,驾驶性能得到了显著提升。
-
高分辨率输入:CLIP视觉编码器的默认分辨率不足以支持高质量驾驶。类似于LLaVA,本文将输入图像分割成小块,使VLM能够访问驾驶图像中的细节,如远处的交通信号灯和行人。与LLaVA不同的是,本文不使用小分辨率的全局块,以减少token的数量。
-
高效训练方法:提出了一种高效的训练方法,显著减少了训练时间。
-
半解耦输出表示:提出了一种半解耦(Semi-Disentangled)表示方式,包含时间条件航点(waypoints)和空间条件路径航点(path waypoints),从而实现更好的控制。
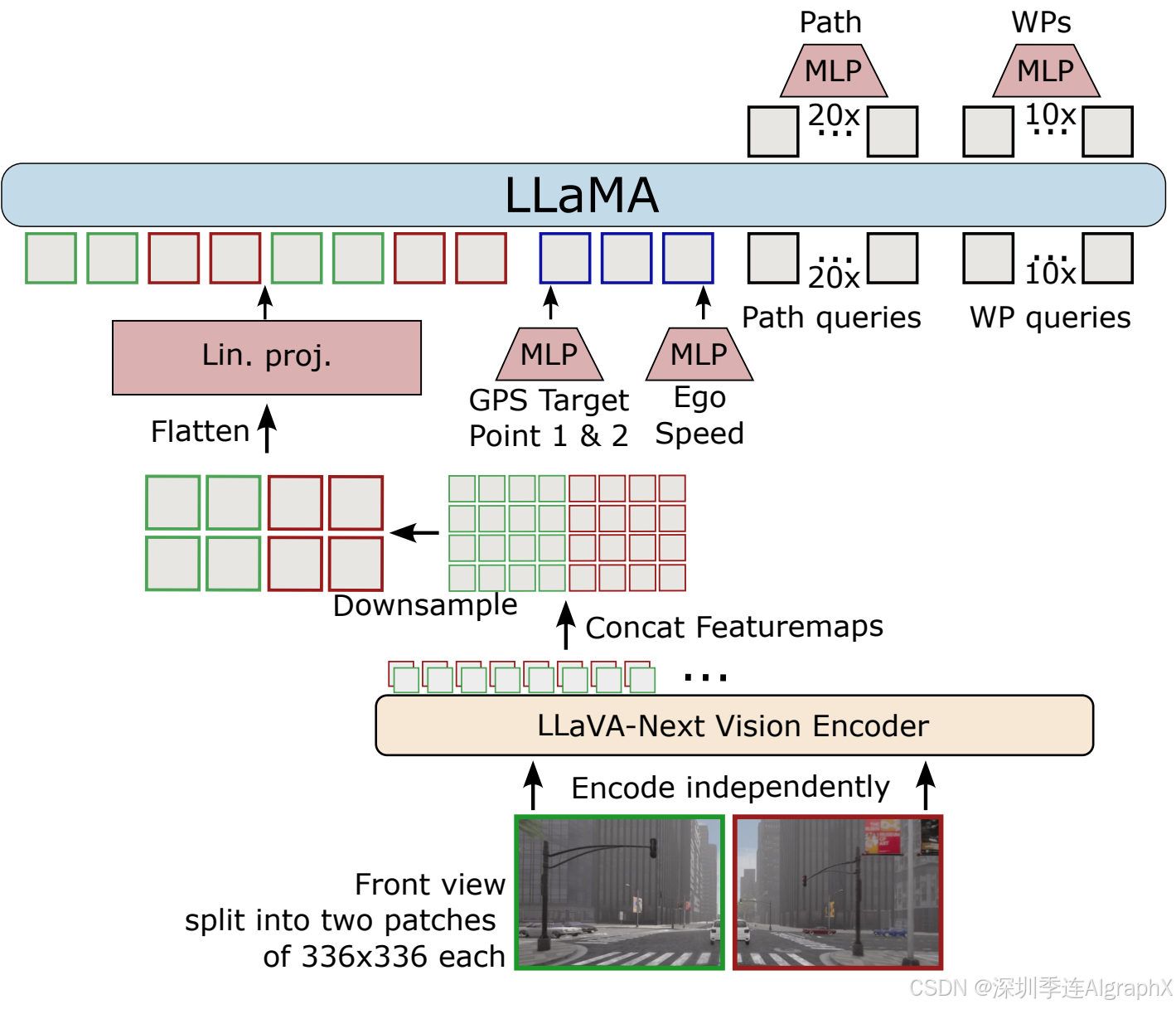
Figure 1. CarLLaVA base model architecture. 图像被分割成两部分,每部分独立编码后再拼接,降采样并投射到一个预训练的大型语言模型中。输出采用了一种半解耦的表示方式,包含时间条件的航点和空间条件的路径航点,以实现更好的控制。
Input/Output Representation
模型输入包括相机图像、下两个目标点和自我车辆的速度。对于输出,使用半解耦表示,其中既有纵向控制的时间条件航点和PID控制器,也有横向控制的空间条件路径航点和PID控制器。对于纵向控制,与直接预测控制相比,使用标准的时间条件航点来更好地避免碰撞。另外还尝试了目标速度分类和GRU,但这些方法表现不佳。
HD-Vision Encoder
为了对相机图像进行编码,作者使用了LLaVA-NeXT视觉编码器,特别是CLIPViT-L-336px模型,这是最高分辨率的训练CLIP模型。为了以高于336x336的分辨率利用CLIP预训练,使用了LLaVA的anyres技术。使用VLM不仅提供了强大的功能,而且还提供了方便查询VLM以识别在图像特征中捕获的信息的优势。
Adapter
为了减少由于LLaMA transformer的二次复杂度而造成的计算开销,作者将特征映射的采样减少到令牌数量的一半。在平面化flattening之后,使用线性投影层将视觉特征映射到语言模型的嵌入空间。为了对目标点和自车速度进行编码,在标准化层之后使用多层感知器(MLP)。此外,为不同的视图添加了相机编码(模型C2T1),并在使用多个时间步长的图像时添加了时间编码(仅适用于模型C1T2)。
LM-Decoder
使用LLaMA架构作为解码器。除了传感器输入令牌之外,还使用可学习的查询来生成路径和航点。在输出特征之上的MLP生成航点差异。这些差异的累积和产生最终的航点,这些航点在训练过程中使用均方误差(MSE)损失进行监督。对于生成语言解释的初步结果,在生成路径和航点后对语言解释进行自动回归采样。在训练期间,输入标记化的解释并使用标准的语言建模(LM)损失。使用预训练Tiny LLaMA模型的tokenizer and LM-head。

Figure 2. Qualitative examples of generated language. Red: predicted path, Green: predicted waypoints, Blue: Target Points
7.2 地图
Rank1:德国 University of Tübingen
Hidden Biases of End-to-End Driving Datasets
https://opendrivelab.github.io/Challenge%202024/carla_Tuebingen%20AI.pdf
作者系统地分析了训练数据集,从而得出了新的见解:
- 专家风格显着影响下游策略绩效。
- 在复杂的驾驶数据集上,不应根据类频率等简单标准对帧进行加权。
- 与以前的帧相比,估计一个帧是否改变了目标标签,可以在不丢失重要信息的情况下减小数据集大小。
作者采用TransFuser模型,并结合PDM-Lite规划器,应对高速行驶和动态障碍物处理等新挑战。通过数据过滤、优化数据集,为自动驾驶数据集设计和模型训练提供了新的视角。
此外,还使用动态自行车模型将提案转化为自动驾驶车辆预期序列边界框,该方法结合了端到端模仿学习,并通过模拟边界框相交情况来评估自车运动,有效提升了自动驾驶系统的安全性和准确性。
在CARLA 2.0 Town13地图上,通过拆分和精细评估,为自动驾驶模型的场景适应性提供了更准确的评估方法。
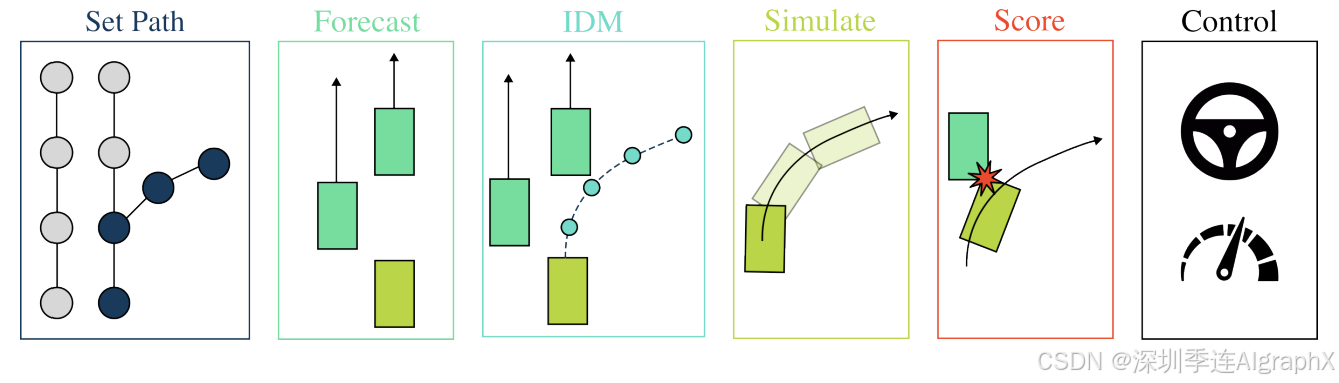
Figure 1. PDM-Lite. This open-source rule-based planner solves all 38 scenarios of CARLA Leaderboard 2.0.
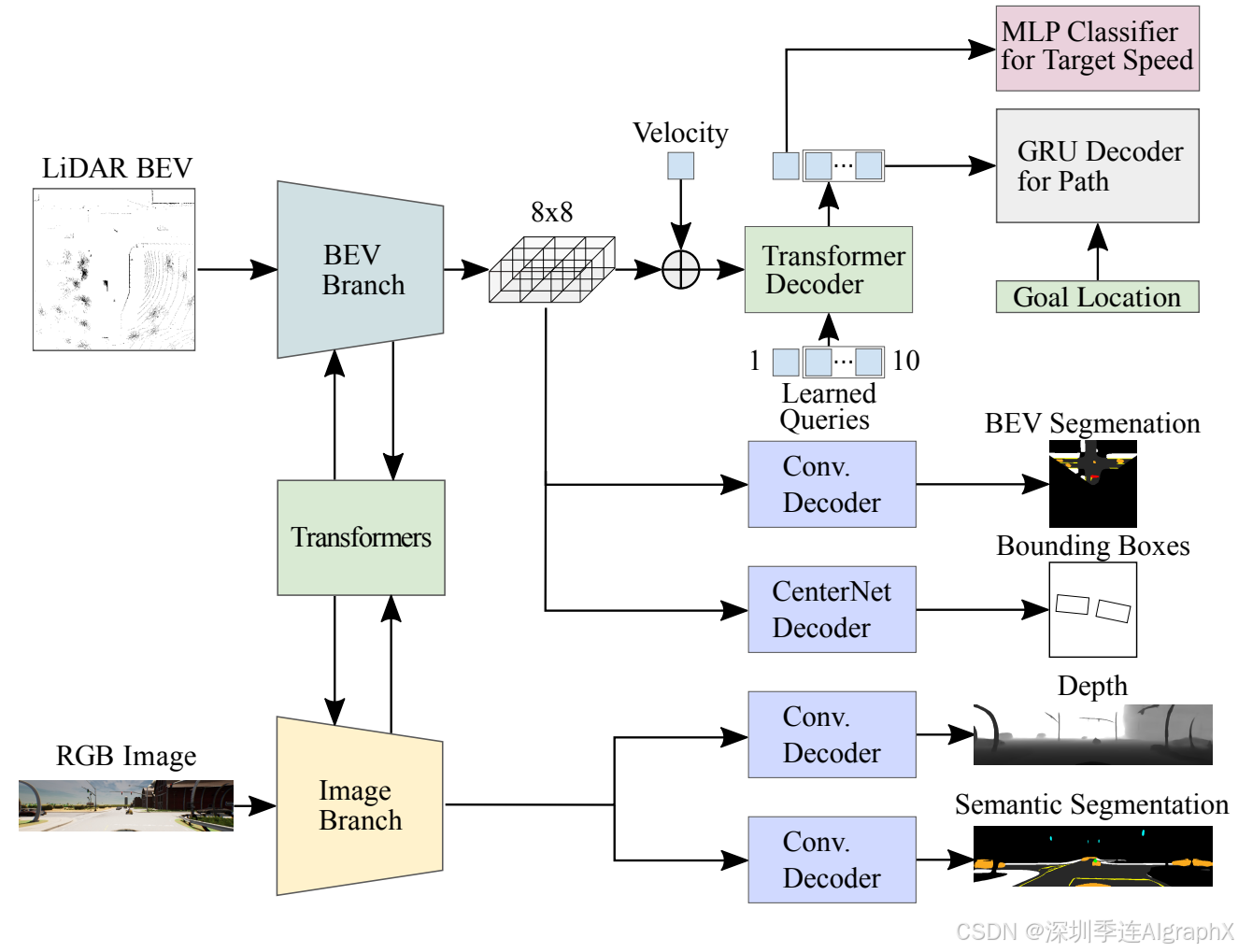
Figure 2. TF++ 8. This end-to-end imitation learning approach is the best publicly available baseline for CARLA.