来源:ICLR2023/实验室师兄/北航
方向:文本表示学习
开源地址:https://github.com/BDBC-KG-NLP/ICLR2023-Gradient-Dissipation.git
摘要
对比学习被广泛应用于视觉表示学习(VRL)和 句子表示学习(SRL)等领域。考虑到VRL和SRL在负样本数量和评价重点方面的差异,我们认为在VRL中获得的可靠结果可能不完全延续到SRL 。在这项工作中,我们考虑在SRL中探究解耦形式的适用性,即对齐(alignment)和均匀性(uniformity)。
通过联合优化STS任务上的对齐和均匀性 而获得的句子表示与通过使用对比损失 而获得的句子表示之间存在性能差距 。在训练过程中,对齐和均匀性的联合优化 容易发生过拟合,而这不会发生在对比损失上。
根据梯度范数的变化 对其进行分析,发现在对比损失中存在"梯度耗散"的特性,并认为这是防止过拟合的关键。我们在两种分解形式的四个优化目标上模拟了对比损失的相似的"梯度耗散",并在STS任务上获得了与对比损失相同甚至更好的性能。
介绍
之前的对比学习分解工作主要在VRL中进行,主要依赖于负例数量趋近于无穷,但VRL中一般使用较大的负例数量(比如65536),因此已有工作也需要讨论。
最近SRL中也有不少工作使用对比学习,但是SRL的评估除了VRL常用的外部协议(下游分类任务),还需要着重评估STS这样的内部协议(因为语义相似度质量优化本来就是预训练语言模型表示学习损失函数的目标,且外部协议已经被证明在SRL中可以较好完成)
部分SRL工作也尝试使用对齐均匀性来评估模型,但SRL中一般都使用较小的负例数量。本文发现了使用对齐和均匀性联合优化目标A&U(alignment and uniformity)或类似的DCL(decoupled contrastive loss)目标会带来比对比学习更差的性能,会导致过拟合。
本文关注于梯度耗散 ,即对比学习中,当负例被推开的距离正例足够远 时,梯度会迅速下降并逐渐消失 。而当负样例数目较小时,对于A&U或DCL都没有出现类似的现象
本文设计两个损失函数,都使用了梯度耗散作为训练目标,并在STS和TR任务上获得与对比学习相当或更好的效果。从而证明当负样例数目较小时,SRL中梯度耗散对于对比学习非常重要。
准备工作
对比损失 。 h ^ i \hat h_i h^i 表示锚点的向量, h ^ i ′ \hat h_i' h^i′ 表示锚点的一个增强样本,即正例, h ^ j \hat h_j h^j 和 h ^ j ′ \hat h_j' h^j′ 是负例。在一些工作中证明了句子表示质量对于负样例数量N不敏感,比较小的数量 比如63也可以达到和更大的数量相同效果。
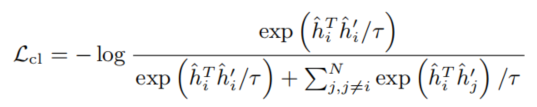
对齐和均匀性 (A&U)1。对齐性计算了两个向量之差的2范数的 1 α \frac 1 \alpha α1 次方。均匀性计算了每个样本对之间的高斯势核(Gaussian potential kernel)
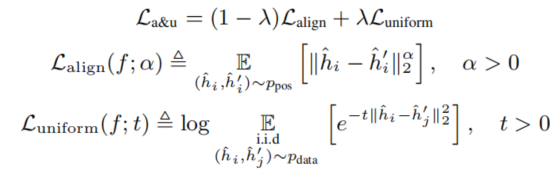
解耦对比学习 (DCL)2。去除了对比学习分母中的正例对那一项
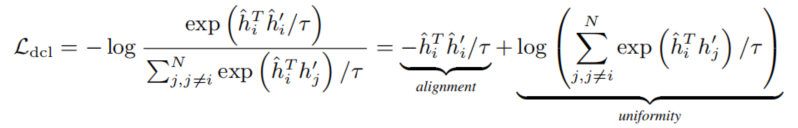
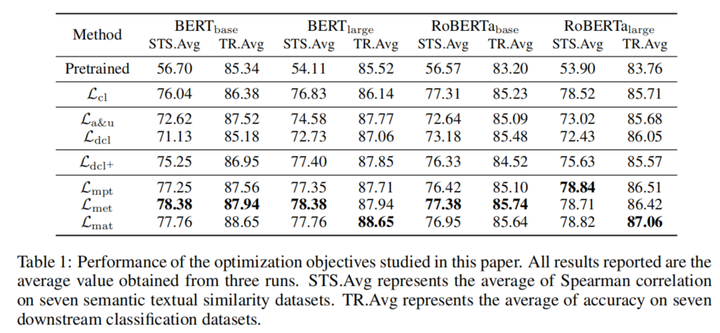
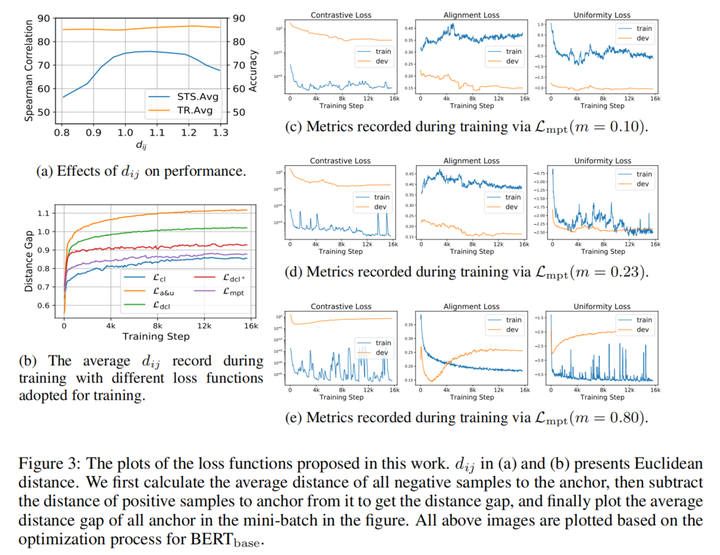
不同损失在STS和TR分类任务的效果。得出结论:
- STS任务提升显著而TR提升不明显。
- 分解损失在TR任务上与CL性能相当,但STS上存在一定距离
对齐和均匀性的不足
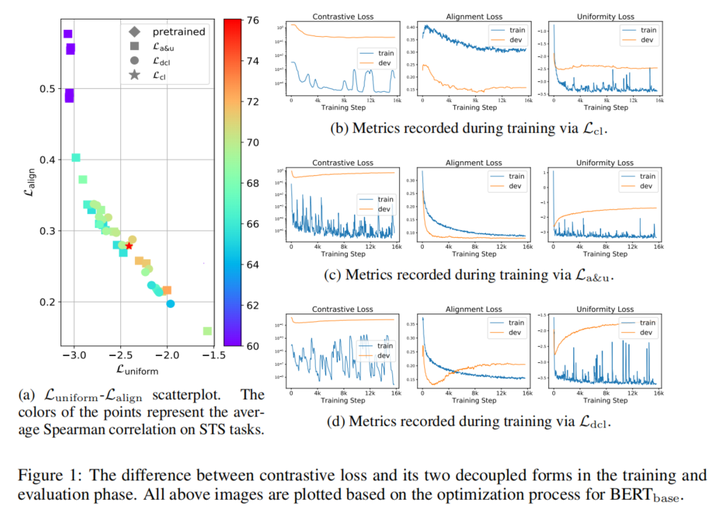
根据图1(a),当对齐和均匀性指标接近 时,STS性能却相差较大 。根据b图,A&U与DCL的对齐和均匀性损失在开发集上都先下降后上升,出现了过拟合
对三个损失的梯度求模,得到
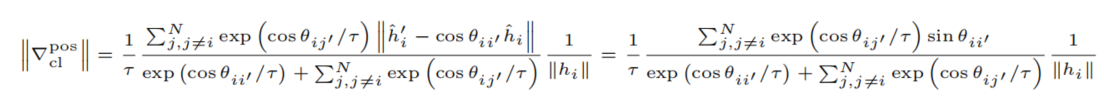
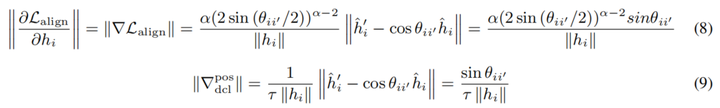
发现对比损失的梯度项里有 θ i j ′ \theta_{ij'} θij′ 而另外两个损失里没有,因此对于CL来说,训练过程中只有 θ i j ′ \theta_{ij'} θij′ 远大于 θ i i ′ \theta_{ii'} θii′ 的样例会接收梯度。但是对于其他两个损失,除了 θ i i ′ \theta_{ii'} θii′ 很小的样例,其他样例都会接收梯度。
对于超球面中几何距离,梯度耗散可以解释为,CL在减小正例对距离的情况下,保持了正例对和负例对距离,而其他损失仅仅减小了正例对距离。
实验
对DCL损失观察发现:(1)DCL损失会逐渐下降到负数(2)梯度耗散只有当负例对夹角比正例对夹角足够大时才会发生
对于DCL损失,可以利用ReLU加入梯度耗散得到DCL+损失函数
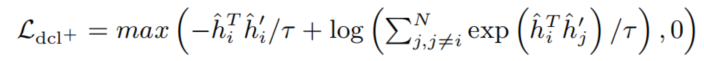
求梯度可以发现,损失小于等于0时梯度范数为0,否则为一个正数
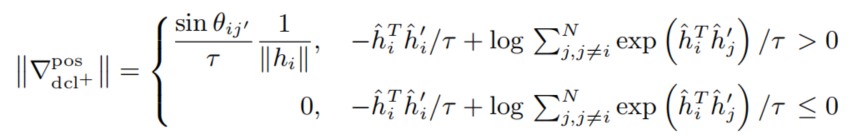
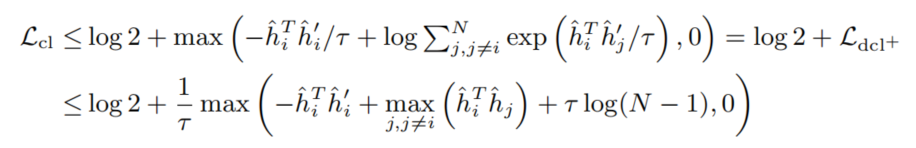
有趣的是,DCL+和log2的和,刚好是CL的上界。利用CL损失上界得到三元间隔损失(Triplet Loss),命名为MAT(Minimum Angle Triplet Loss),将余弦相似度替换为其他形式得到MET(Minimum Euclidean distance Triplet Loss)和MAT(Minimum Angle Triplet Loss),通过证明这三种方法都可以获得较好效果,从而说明是梯度耗散而不是具体的距离度量函数起作用
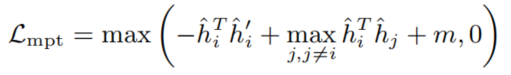
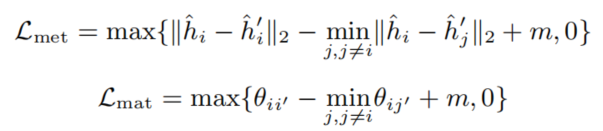
梯度耗散的时机很重要,过早的梯度耗散可能导致欠拟合,过迟的梯度耗散可能导致过拟合(3(e)和1(d)很接近)
大家好,我是NLP研究者BrownSearch,如果你觉得本文对你有帮助的话,不妨点赞 或收藏 支持我的创作,您的正反馈是我持续更新的动力!如果想了解更多LLM/检索 的知识,记得关注我!
引用
1Wang T, Isola P. Understanding contrastive representation learning through alignment and uniformity on the hypersphereC//International Conference on Machine Learning. PMLR, 2020: 9929-9939.
2Yeh C H, Hong C Y, Hsu Y C, et al. Decoupled contrastive learningC//European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 668-684.