您可以使用以下说明从文件创建图形。本文档介绍了:
- 包含从文件加载图形的函数的当前分支的信息
- 使图形从文件创建的函数的说明
- 作为输入的加载函数的CSV文件的结构,以及相关的注意事项
以及从文件加载国家和城市的简单源代码示例。
用户可以通过两个步骤加载图形:
- 在第一步加载顶点
- 在第二步加载边
在从文件加载数据之前,用户必须创建图形和标签。
加载图形函数
以下是从文件创建顶点和边的函数的详细信息。
使用函数 load_labels_from_file 从CSV文件加载顶点。
load_labels_from_file('<graph name>', '<label name>', '<file path>');通过添加第四个参数,用户可以排除id字段。当文件中没有id字段时使用此参数。
load_labels_from_file('<graph name>', '<label name>', '<file path>', false);函数 load_edges_from_file 可用于从CSV文件加载边。请查看以下文件结构。
load_edges_from_file('<graph name>', '<label name>', '<file path>');CSV格式说明
以下是顶点和边的CSV文件结构的说明。
顶点的CSV文件应该格式化如下:
id: 文件的第一列,所有值都应为正整数。当id_field_exists为 false 时,此字段是可选的。但是,当id_field_exists不为 false 时,应该存在。- 属性:所有其他列包含顶点的属性。标题行应包含属性名称。
类似地,边的CSV文件应格式化如下:
start_id:边的起始节点的节点ID。此ID应该存在于nodes.csv文件中。start_vertex_type:节点的类别。end_id:边将结束的节点的ID。end_vertex_type:节点的类别。- 属性:边的属性。标题应包含属性名称。
示例文件可以在 regress/age_load/data 目录中查看。
示例SQL脚本
加载并创建图形:
LOAD 'age';
SET search_path TO ag_catalog;
SELECT create_graph('agload_test_graph');创建标签 Country 并从CSV文件加载顶点。请注意,此CSV文件包含id字段。
SELECT create_vlabel('agload_test_graph','Country');
SELECT load_labels_from_file('agload_test_graph',
'Country',
'age/regress/age_load/data/countries.csv');创建标签 City 并从CSV文件加载顶点。请注意,此CSV文件包含id字段。
SELECT create_vlabel('agload_test_graph','City');
SELECT load_labels_from_file('agload_test_graph',
'City',
'age/regress/age_load/data/cities.csv');创建标签 has_city 并从CSV文件加载边。
SELECT create_elabel('agload_test_graph','has_city');
SELECT load_edges_from_file('agload_test_graph', 'has_city',
'age/regress/age_load/data/edges.csv');检查图是否已正确加载:
SELECT table_catalog, table_schema, table_name, table_type
FROM information_schema.tables
WHERE table_schema = 'agload_test_graph';
SELECT COUNT(*) FROM agload_test_graph."Country";
SELECT COUNT(*) FROM agload_test_graph."City";
SELECT COUNT(*) FROM agload_test_graph."has_city";
SELECT COUNT(*) FROM cypher('agload_test_graph', $$MATCH(n) RETURN n$$) as (n agtype);
SELECT COUNT(*) FROM cypher('agload_test_graph', $$MATCH (a)-[e]->(b) RETURN e$$) as (n agtype);创建没有文件中id字段的顶点
创建标签 Country2 并从CSV文件加载顶点。请注意,此CSV文件不包含id字段。
SELECT create_vlabel('agload_test_graph','Country2');
SELECT load_labels_from_file('agload_test_graph',
'Country2',
'age/regress/age_load/data/countries.csv',
false);创建标签 City2 并从CSV文件加载顶点。请注意,此CSV文件不包含id字段。
SELECT create_vlabel('agload_test_graph','City2');
SELECT load_labels_from_file('agload_test_graph',
'City2',
'age/regress/age_load/data/cities.csv',
false);检查图是否已正确加载,并在自动创建的id和从文件中选择的id之间执行差异分析。
Country 和 City 标签是在文件中包含id字段的情况下创建的。
Country2 和 City2 标签是在文件中不包含id字段的情况下创建的。
SELECT COUNT(*) FROM agload_test_graph."Country2";
SELECT COUNT(*) FROM agload_test_graph."City2";
SELECT id FROM agload_test_graph."Country" LIMIT 10;
SELECT id FROM agload_test_graph."Country2" LIMIT 10;
SELECT * FROM cypher('agload_test_graph', $$MATCH(n:Country {iso2 : 'BE'})
RETURN id(n), n.name, n.iso2 $$) as ("id(n)" agtype, "n.name" agtype, "n.iso2" agtype);
SELECT * FROM cypher('agload_test_graph', $$MATCH(n:Country2 {iso2 : 'BE'})
RETURN id(n), n.name, n.iso2 $$) as ("id(n)" agtype, "n.name" agtype, "n.iso2" agtype);
SELECT * FROM cypher('agload_test_graph', $$MATCH(n:Country {iso2 : 'AT'})
RETURN id(n), n.name, n.iso2 $$) as ("id(n)" agtype, "n.name" agtype, "n.iso2" agtype);
SELECT * FROM cypher('agload_test_graph', $$MATCH(n:Country2 {iso2 : 'AT'})
RETURN id(n), n.name, n.iso2 $$) as ("id(n)" agtype, "n.name" agtype, "n.iso2" agtype);
SELECT drop_graph('agload_test_graph', true)使用公有云服务
一些公有云的提供了免安装的数据库服务,无需自己部署。以MemFireCloud为例
直接连接
每个MemFire Cloud应用内置一个完整的Postgres数据库,你可以使用任何支持Postgres的工具来连接到数据库。你可以在控制台内的数据库设置中获取连接信息:
- 来到左侧菜单栏的
设置部分 - 点击
数据库 - 启用数据库直连
- 找到应用的
连接信息
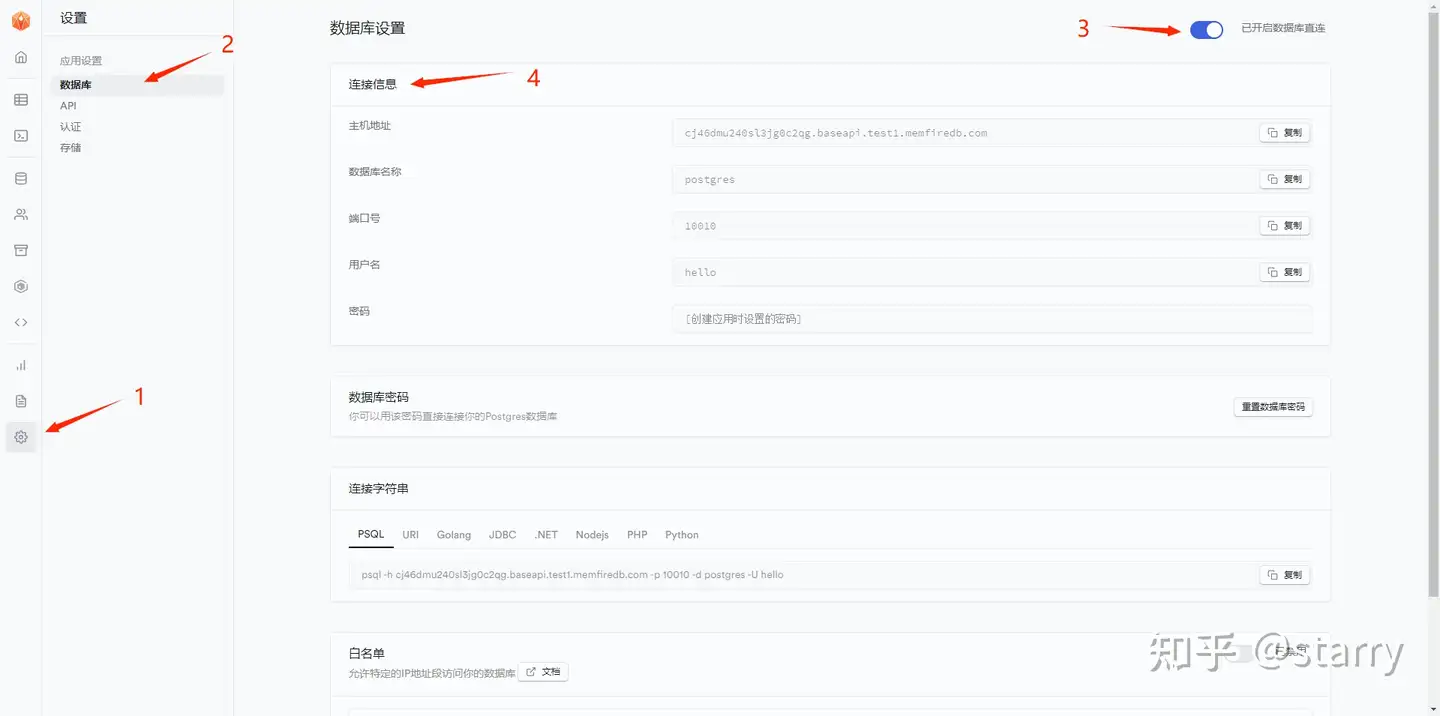
开启直连
白名单
MemFire Cloud内置白名单功能,开启白名单后,只允许白名单内的IP地址段访问你的数据库。关闭白名单后,访问你数据库的IP地址不受限制,即任何IP地址只要有连接信息都可以与你的数据库进行直连。 在进行白名单配置时,要遵循CIDR规则。MemFire Cloud中白名单功能 默认是关闭的,需用户手动开启。
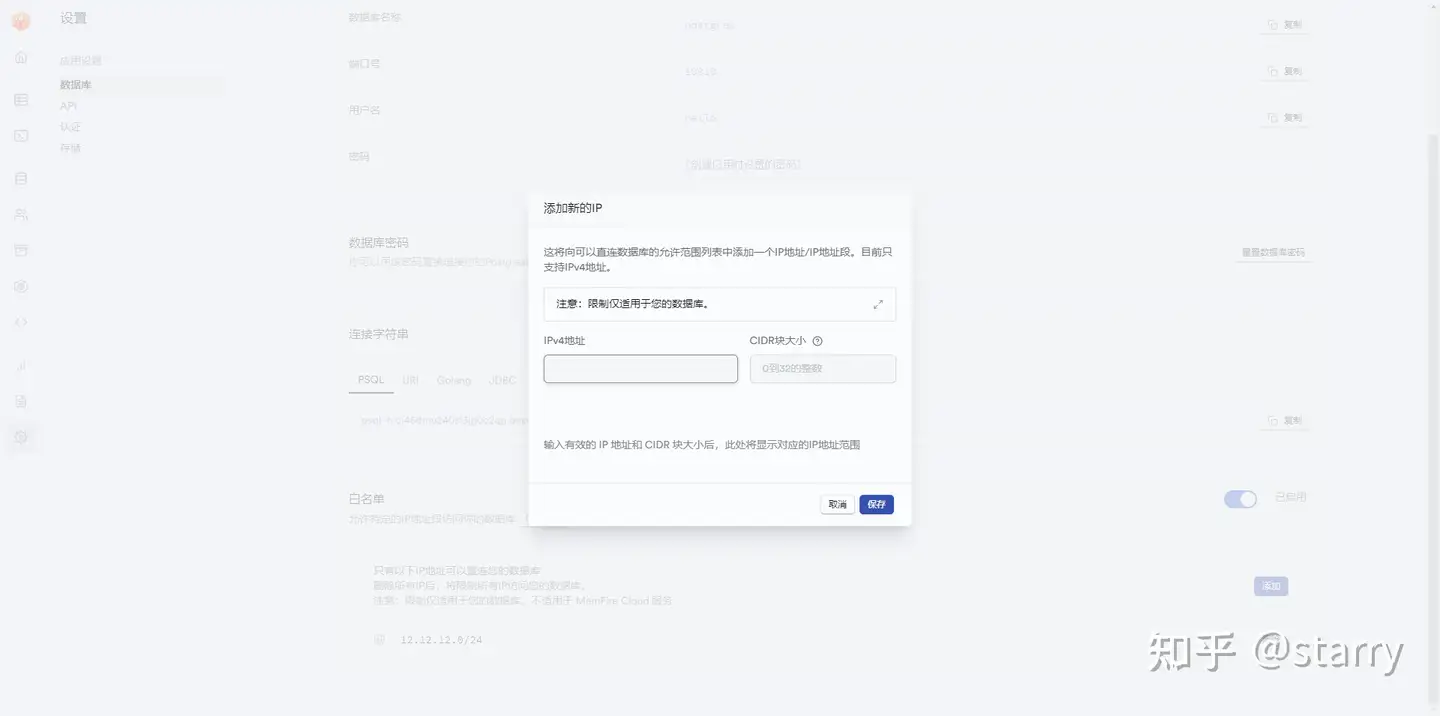
配置白名单
通过数据库客户端连接数据库,可以执行图操作
CREATE EXTENSION age;
LOAD 'age';
SET search_path = ag_catalog, "$user", public;