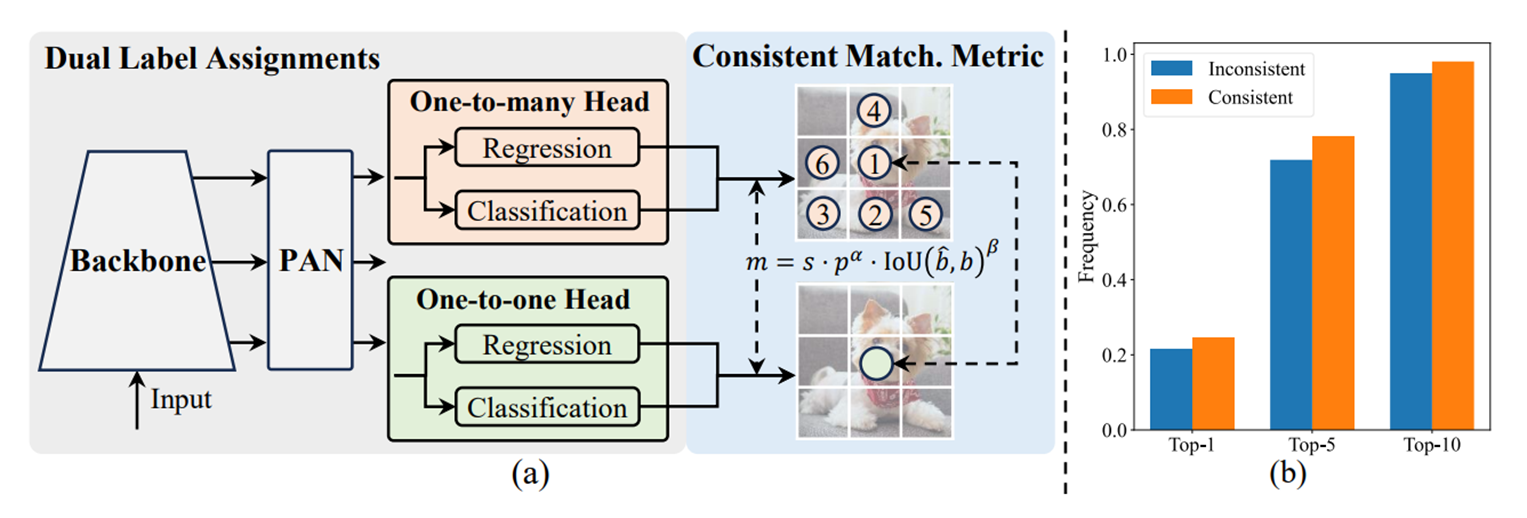
双重标签分配
与一对一多分配不同,一对一匹配只为每个地面真相分配一个预测,避免了NMS后处理。然而,这导致了较弱的监督,导致次优的准确性和收敛速度。幸运的是,这种缺陷可以通过一对一多分配来弥补。为此,作者为YOLO引入了双重标签分配,以结合两种策略的优点。
具体来说,如图2.(a)所示,作者在YOLO中增加了一个一对一的 Head 。它与原始一对一多分支保持相同的结构和采用相同的优化目标,但利用一对一匹配来获得标签分配。在训练过程中,两个 Head 与模型联合优化,使得主干和 Neck 能够享受到一对一多分配提供的丰富监督。
在推理过程中,作者丢弃一对一多 Head ,并利用一对一 Head 进行预测。这使得YOLO能够端到端部署,而不会产生任何额外的推理成本。此外,在一对一匹配中,作者采用顶部选择,其性能与匈牙利匹配4相同,但额外的训练时间更少。
一致的匹配度量
在分配过程中,一对一和多对多方法都采用一种度量来定量评估预测与实例之间的一致性水平。
以效率为导向的模型设计
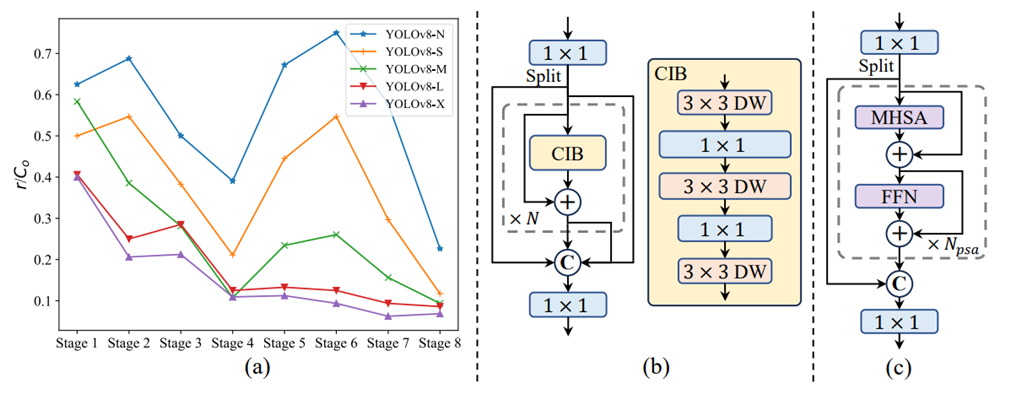
b:The compact inverted block(CIB)紧凑倒置块
在深层阶段的CIB中使用大核深度卷积。作者将CIB中的第二个33深度卷积的核大小增加到77。此外,作者采用结构重参化技术带来另一个33深度卷积分支,以减轻优化问题,而无需推理开销
c:partial self-attention(PSA)部分自注意力模块
在11卷积后均匀地将特征在通道上划分为两部分。作者只将一部分输入到由多头自注意力模块(MHSA)和前馈网络(FFN)组成的块中。然后,两部分通过11卷积进行拼接和融合。
YOLO中的组件包括Stem、下采样层、带有基本构建块的阶段和 Head 。Stem产生的计算成本很少,因此作者仅对其他三个部分进行以效率为导向的模型设计。
- 轻量级分类 Head . 在YOLOs中,分类 Head 和回归 Head 通常共享相同的架构。然而,它们在计算开销上表现出显著的差异。例如,在YOLOv8-S中,分类 Head 的FLOPs和参数数量(5.95G/1.51M)分别是回归 Head (2.34G/0.64M)的2.5倍和2.4倍。但是,在分析了分类误差和回归误差的影响(见表6)之后,作者发现回归 Head 对YOLOs的性能承担了更多的意义。
因此,作者可以减少分类 Head 的开销,而不必担心对性能造成太大伤害。因此,作者为分类 Head 采用了简单的轻量级架构,该架构包括两个深度可分离卷积(核大小为3×3),后面跟着一个1×1卷积。
- 空间-通道解耦下采样. YOLOs通常使用常规的3×3标准卷积,步长为2,同时实现空间下采样(从到)和通道转换(从到)。这引入了不可忽视的计算成本和参数数量。相反,作者建议将空间缩小和通道增加操作解耦,实现更高效的下采样。
具体来说,作者首先利用点状卷积调节通道维度,然后使用深度卷积进行空间下采样。这减少了计算成本到和参数数量到。同时,它最大化了下采样期间的信息保留,以具有竞争力的性能降低延迟。
- 秩引导的块设计. YOLO通常为所有阶段采用相同的基本构建块,例如YOLOv8中的瓶颈块。为了彻底检查YOLO的这种同质设计,作者利用内在秩31, 15来分析每个阶段的冗余性。具体来说,作者计算每个阶段最后一个基本块中最后一个卷积的数值秩,这计算的是超过阈值的奇异值数量。图3(a)展示了YOLOv8的结果,表明深层阶段和大模型容易出现更多冗余。这个观察提示,为所有阶段简单地应用相同块设计并不是最佳容量效率权衡。
准确度驱动的模型设计
作者进一步探索了大核卷积和自注意力用于准确度驱动的模型设计,旨在以最小的成本提升性能。
- 大核卷积. 采用大核深度卷积是扩大感受野和增强模型能力的一种有效方法。然而,在所有阶段简单地利用它们可能会在用于检测小物体的浅层特征中引入污染,同时也可能在高分辨率阶段引入显著的I/O开销和延迟。因此,作者提出在深层阶段的CIB中使用大核深度卷积。具体来说,作者将CIB中的第二个33深度卷积的核大小增加到77。此外,作者采用结构重参化技术带来另一个33深度卷积分支,以减轻优化问题,而无需推理开销。此外,随着模型规模的增加,其感受野自然扩大,使用大核卷积的好处减弱。因此,作者只对小型模型规模采用大核卷积。
- **部分自注意力(PSA)。**自注意力因其卓越的全局建模能力而被广泛应用于各种视觉任务中。然而,它表现出高计算复杂度和内存占用。为此,考虑到普遍存在的注意力头冗余,作者提出了一个高效的 partial self-attention (PSA) 模块设计,如图3(c)所示。
具体来说,作者在11卷积后均匀地将特征在通道上划分为两部分。作者只将一部分输入到由多头自注意力模块(MHSA)和前馈网络(FFN)组成的块中。然后,两部分通过11卷积进行拼接和融合。此外,作者遵循21将 Query 和键的维度设置为值维度的一半,并在MHSA中使用BatchNorm代替LayerNorm以便快速推理。而且,PSA只放置在具有最低分辨率的Stage 4之后,避免了自注意力二次计算复杂度过大的开销。通过这种方式,作者可以将全局表征学习能力以低计算成本融入到YOLOs中,这大大增强了模型的性能,并带来了性能的改进。