一.RAG 基本架构
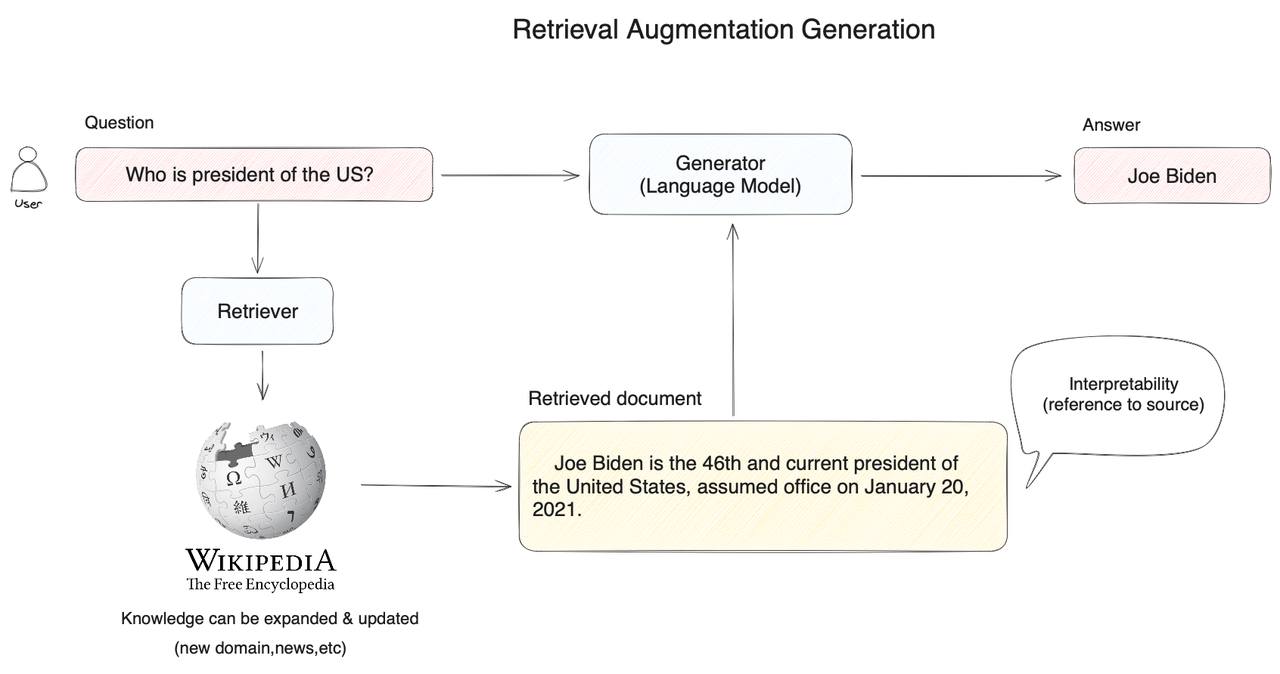
当用户提问 "美国总统是谁?" 时,系统并不是将问题直接交给大模型来回答,而是先将用户问题在知识库中进行向量搜索,通过语义相似度匹配的方式查询到相关的内容(拜登是美国现任第46届总统...),然后再将用户问题和搜索到的相关知识提供给大模型,使得大模型获得足够完备的知识来回答问题,以此获得更可靠的问答结果。
二.混合检索
1.为什么需要混合检索
向量检索优势:复杂语义的文本查找,相近语义理解,多语言理解,多模态理解,容错性。传统关键词搜索优势:精确匹配,少量字符的匹配,倾向低频词汇的匹配。向量检索和关键词检索在检索领域各有其优势。混合检索通过多个检索系统的组合,实现了多个检索技术之间的互补。
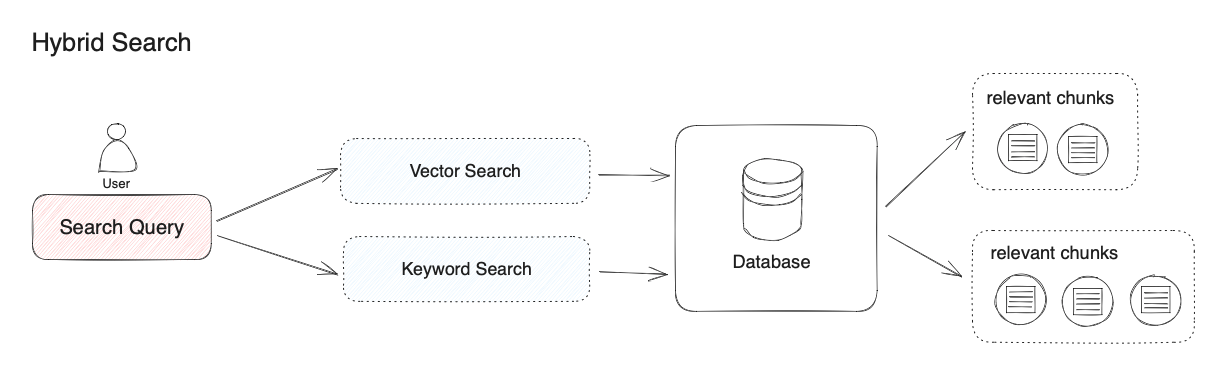
2.向量检索
通过生成查询嵌入并查询与其向量表示最相似的文本分段。
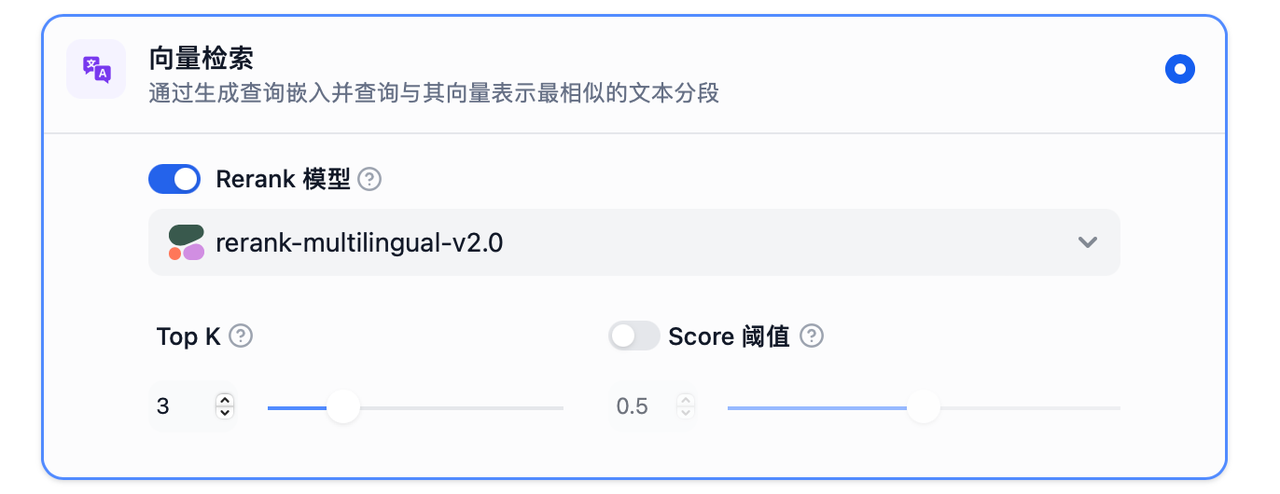
TopK:用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。
Score 阈值:用于设置文本片段筛选的相似度阈值,即:只召回超过设置分数的文本片段。系统默认关闭该设置,即不会对召回的文本片段相似值过滤。打开后默认值为 0.5 。
Rerank 模型:可以在"模型供应商"页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开"Rerank 模型",系统会在语义检索后对已召回的文档结果再一次进行语义重排序,优化排序结果。设置 Rerank 模型后,TopK 和 Score 阈值设置仅在 Rerank 步骤生效。
3.全文检索
索引文档中的所有词汇,从而允许用户查询任意词汇,并返回包含这些词汇的文本片段。
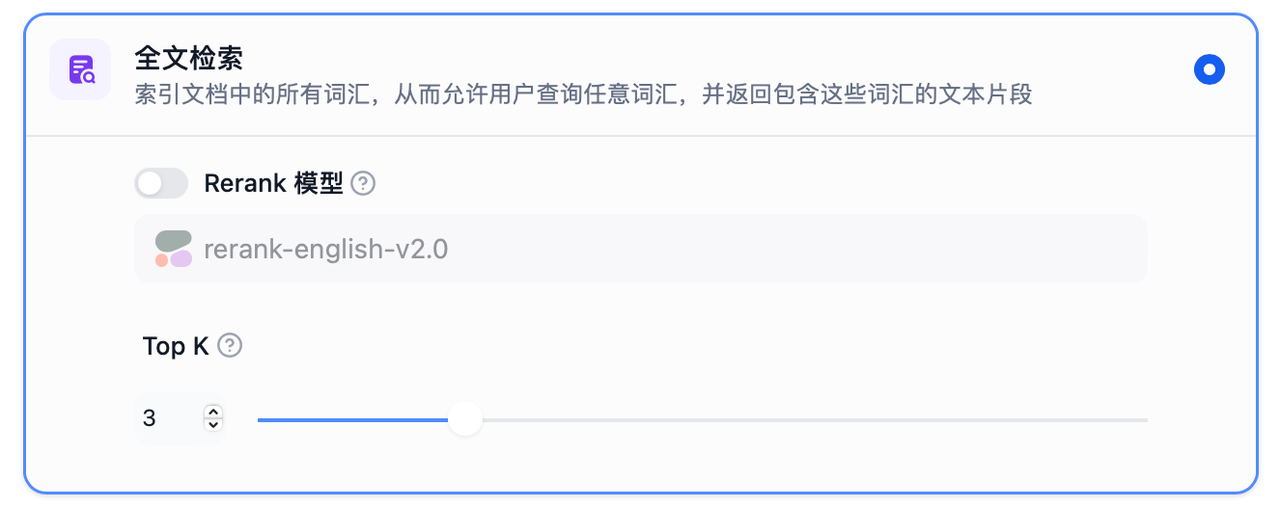
TopK:用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。
Rerank 模型:可在"模型供应商"页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开"Rerank 模型",系统会在全文检索后对已召回的文档结果再一次进行语义重排序,优化排序结果。设置 Rerank 模型后,TopK 和 Score 阈值设置仅在 Rerank 步骤生效。
4.混合检索
同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果,需配置 Rerank 模型 API。
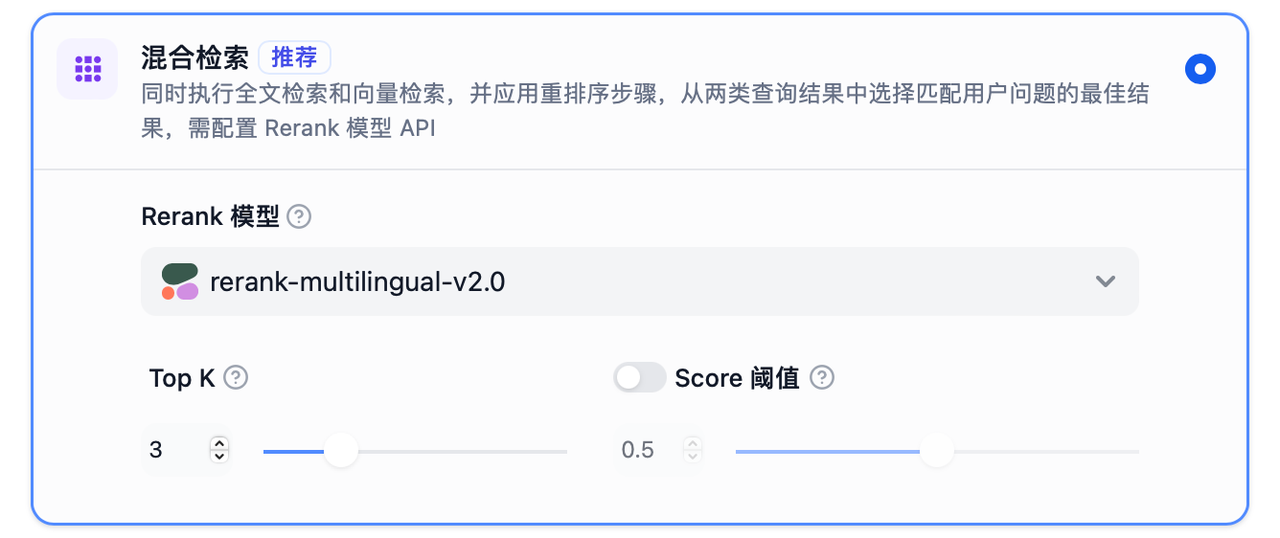
TopK:用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。
Rerank 模型:可在"模型供应商"页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开"Rerank 模型",系统会在混合检索后对已召回的文档结果再一次进行语义重排序,优化排序结果。设置 Rerank 模型后,TopK 和 Score 阈值设置仅在 Rerank 步骤生效。
5.创建数据集时设置检索模式
通过进入"数据集->创建数据集"页面并在检索设置中设置不同的检索模式:
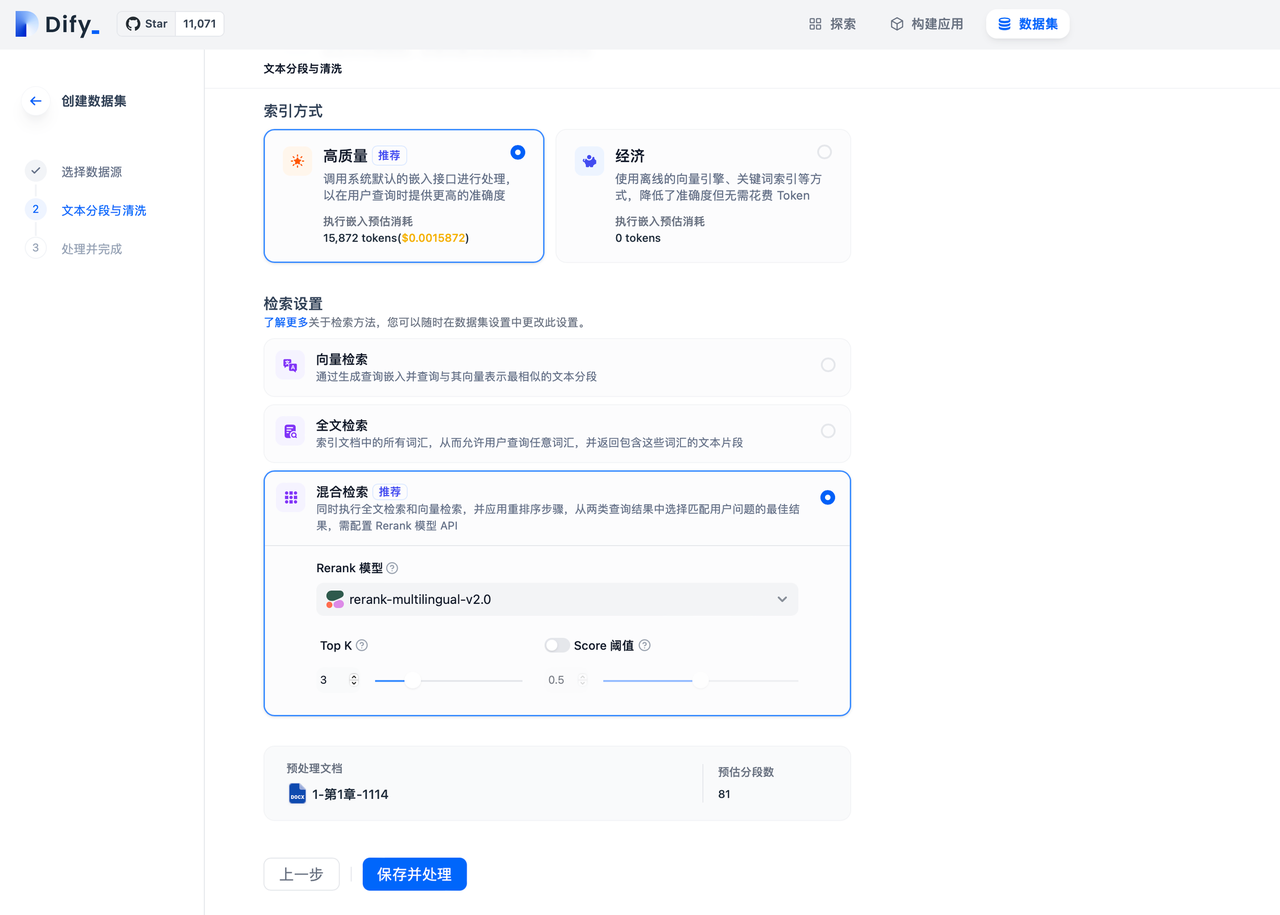
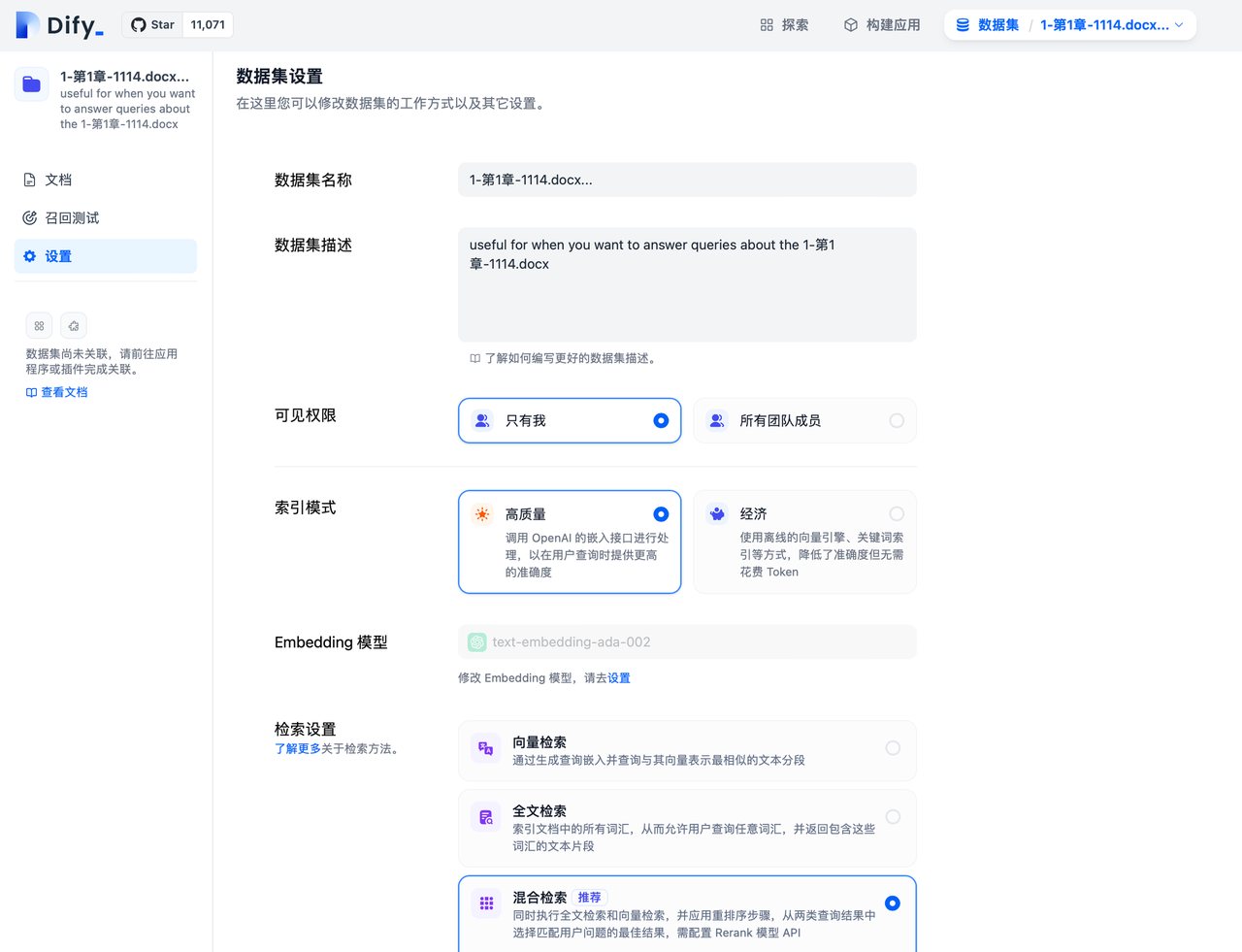
6.数据集设置中修改检索模式
通过进入"数据集->选择数据集->设置"页面中可以对已创建的数据集修改不同的检索模式。
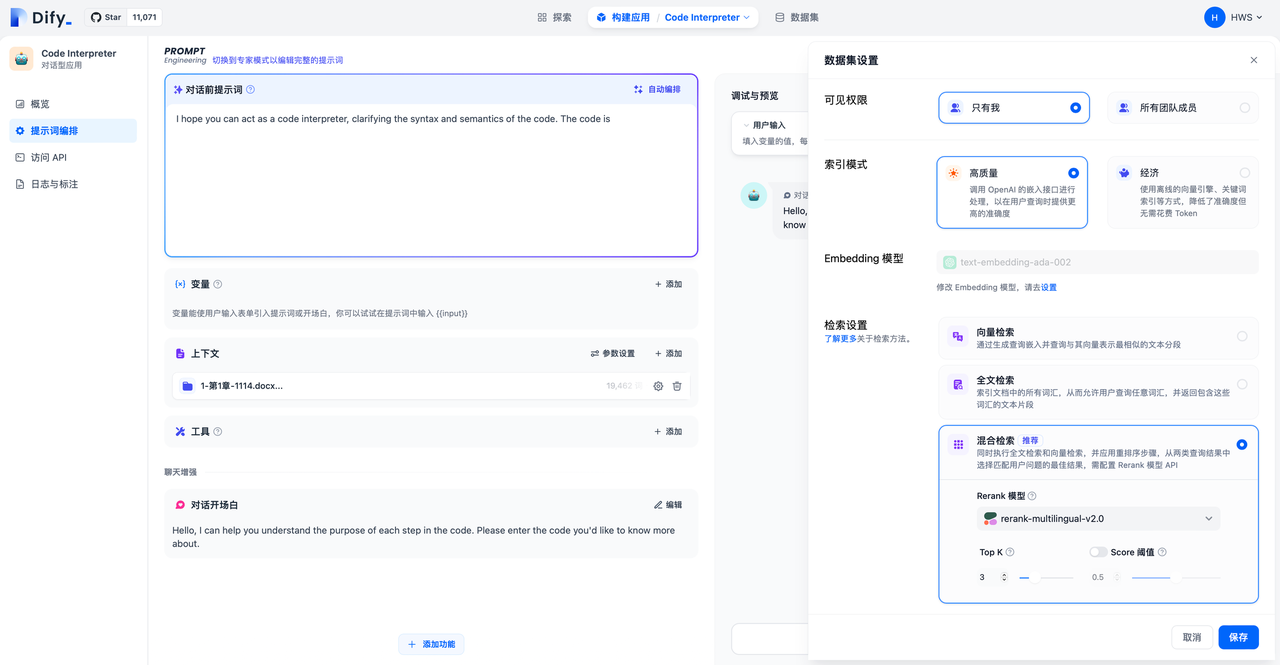
7.提示词编排中修改检索模式
通过进入"提示词编排->上下文->选择数据集->设置"页面中可以在创建应用时修改不同的检索模式。
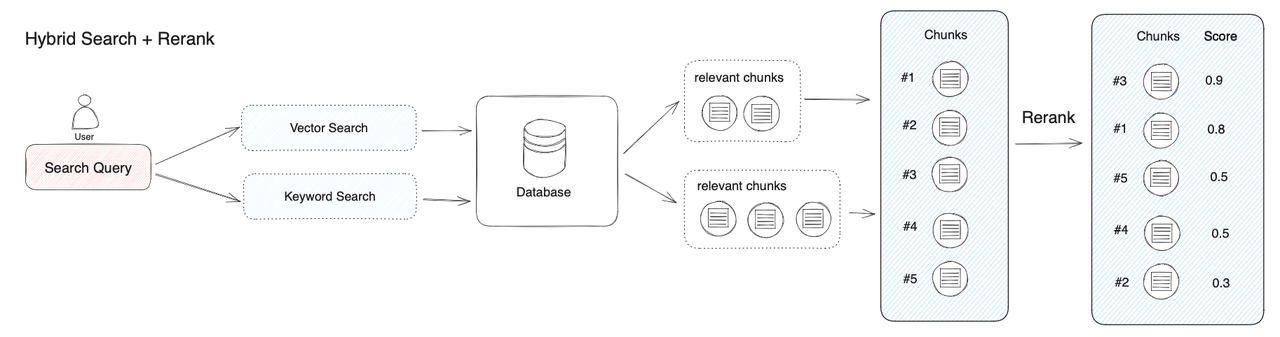
三.重排序
1.为什么需要重排序
重排序模型会计算候选文档列表与用户问题的语义匹配度,根据语义匹配度重新进行排序,从而改进语义排序的结果。其原理是计算用户问题与给定的每个候选文档之间的相关性分数,并返回按相关性从高到低排序的文档列表。常见的 Rerank 模型如:Cohere rerank、bge-reranker 等。重排序一般都放在搜索流程的最后阶段,非常适合用于合并和排序来自不同检索系统的结果。
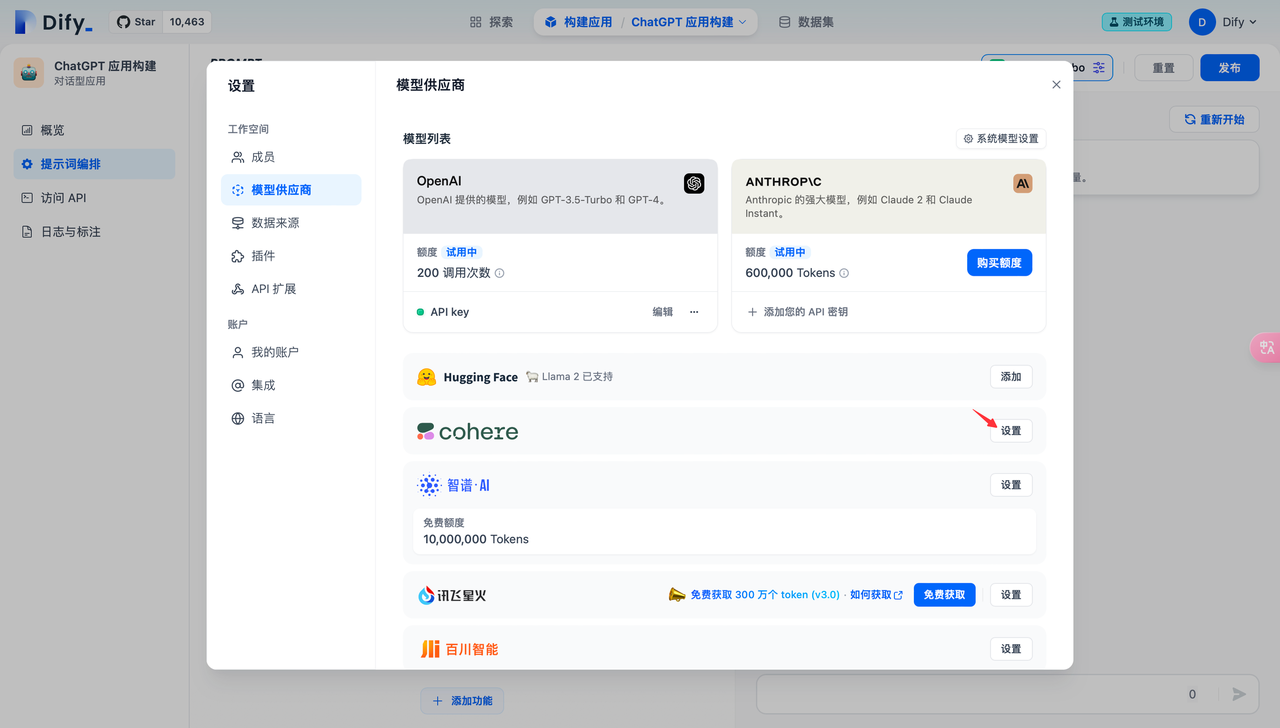
2.如何配置 Rerank 模型
Dify 目前已支持 Cohere Rerank 模型,通过进入"模型供应商-> Cohere"页面填入 Rerank 模型的 API 秘钥:
3.如何获取 Cohere Rerank 模型
登录:https://cohere.com/rerank,在页内注册并申请 Rerank 模型的使用资格,获取 API 秘钥。
4.数据集检索模式中设置 Rerank 模型
通过进入"数据集->创建数据集->检索设置"页面并在添加 Rerank 设置。除了在创建数据集可以设置 Rerank ,也可在已创建的数据集设置内更改 Rerank 配置,在应用编排的数据集召回模式设置中更改 Rerank 配置。
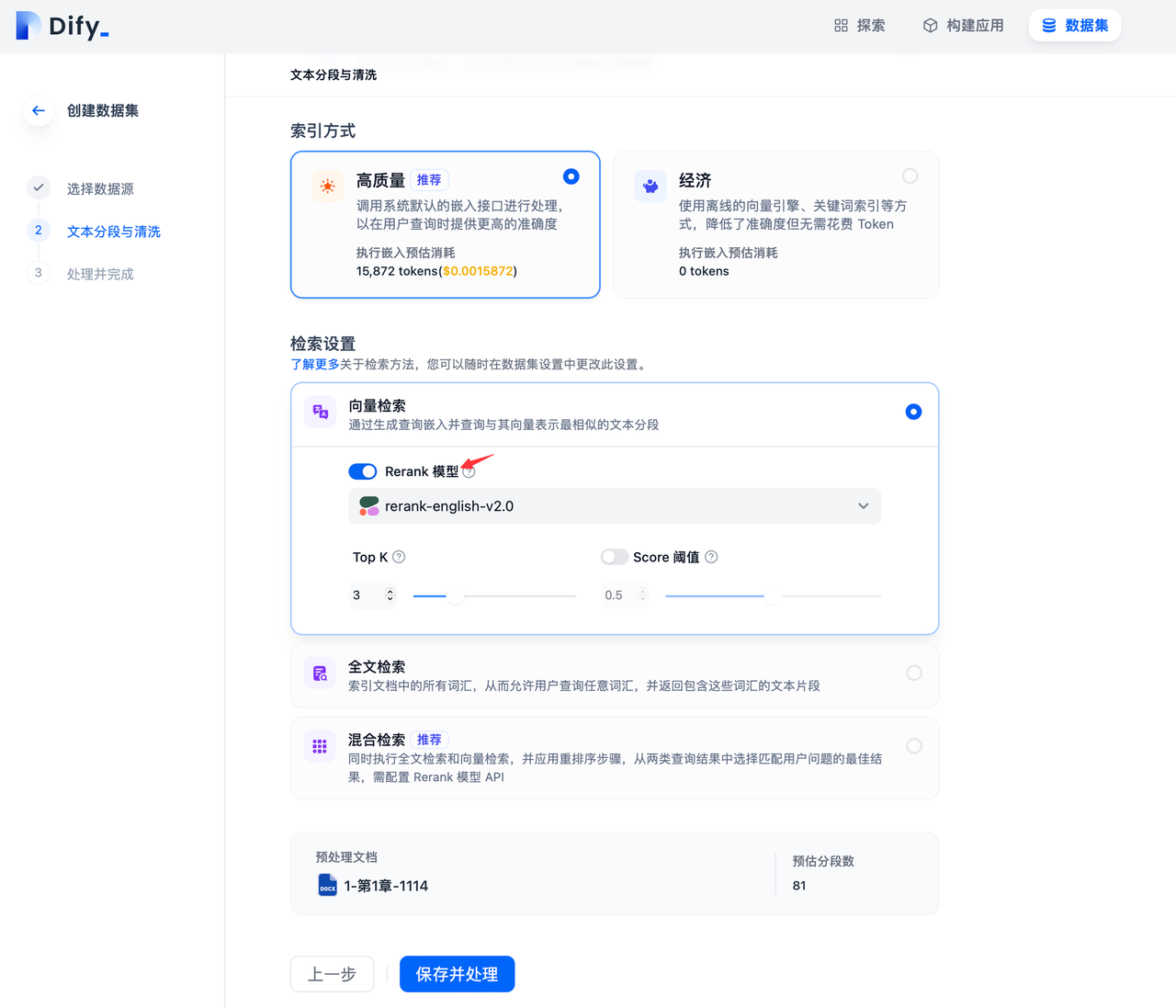
TopK:用于设置 Rerank 后返回相关文档的数量。
Score 阈值:用于设置 Rerank 后返回相关文档的最低分值。设置 Rerank 模型后,TopK 和 Score 阈值设置仅在 Rerank 步骤生效。
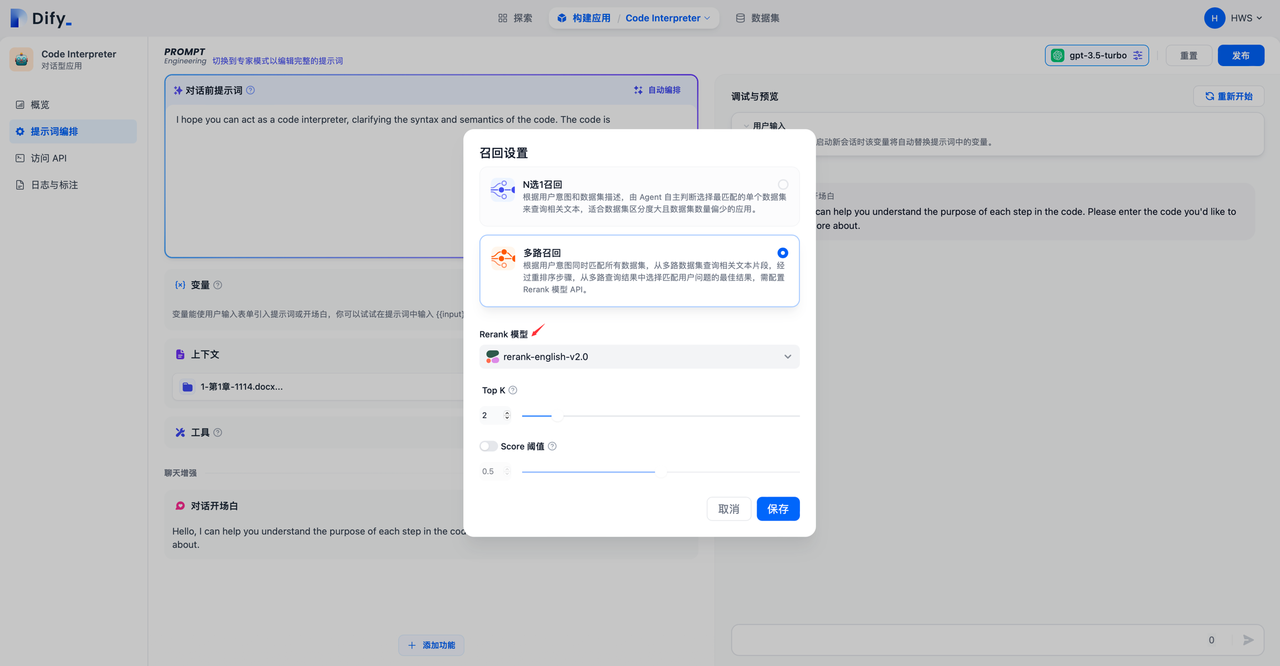
5.数据集多路召回模式中设置 Rerank 模型
通过进入"提示词编排->上下文->设置"页面中设置为多路召回模式时需开启 Rerank 模型。
四.召回模式
当用户构建知识库问答类的 AI 应用时,如果在应用内关联了多个数据集,Dify 在检索时支持两种召回模式:N选1召回模式和多路召回模式。
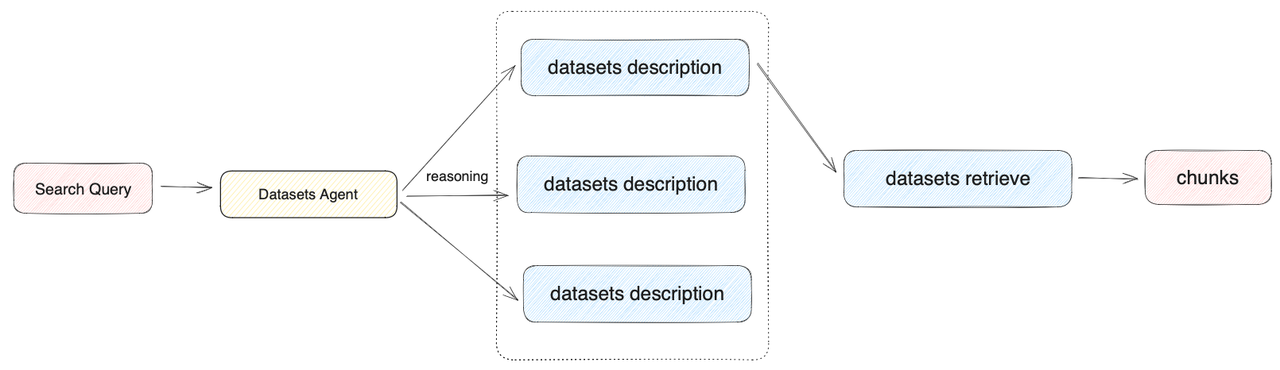
1.N选1召回模式
在用户上传数据集时,系统将自动为数据集创建一个摘要式的描述。为了在该模式下获得最佳的召回效果,可以"数据集->设置->数据集描述"中查看到系统默认创建的摘要描述,并检查该内容是否可以清晰的概括数据集的内容。根据用户意图和数据集描述,由 Agent 自主判断选择最匹配的单个数据集来查询相关文本,适合数据集区分度大且数据集数量偏少的应用。
提示:OpenAI Function Call已支持多个工具调用,Dify将在后续版本中升级该模式为"N选M召回"。
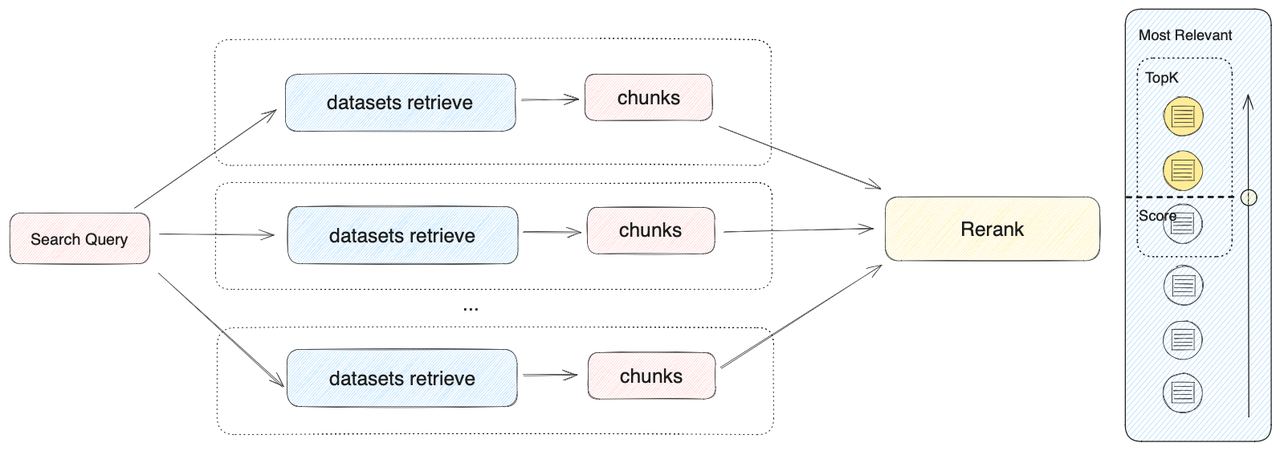
2.多路召回模式(推荐)
根据用户意图同时匹配所有数据集,从多路数据集查询相关文本片段,经过重排序步骤,从多路查询结果中选择匹配用户问题的最佳结果,需配置 Rerank 模型 API。在多路召回模式下,检索器会在所有与应用关联的数据集中去检索与用户问题相关的文本内容,并将多路召回的相关文档结果合并,并通过 Rerank 模型对检索召回的文档进行语义重排序。
参考文献
1 检索增强生成(RAG):https://docs.dify.ai/v/zh-hans/learn-more/extended-reading/retrieval-augment
2 知识库:https://docs.dify.ai/v/zh-hans/guides/knowledge-base
3 Unstructured:https://docs.unstructured.io/welcome
4 dify源码解析-RAG:https://zhuanlan.zhihu.com/p/704341817