Langchain3:Langchain架构演进与功能扩展:流式事件处理、事件过滤机制、回调传播策略及装饰器应用
1. Langchain的演变
v0.1: 初始版本,包含基本功能。
-
从0.1~0.2完成的特性:
- 通过事件流 API 提供更好的流式支持。
- 标准化工具调用支持Tools Calling。
- 标准化的输出结构接口。
- @chain 装饰器,更容易创建 RunnableLambdas。
- 在 Python 中对许多核心抽象的更好异步支持。
- 在 AIMessage 中包含响应元数据,方便访问底层模型的原始输出。
- 可视化 runnables 或 langgraph 应用的工具。
- 大多数提供商之间的聊天消息历史记录互操作性。
- 超过 20 个 Python 流行集成的合作伙伴包。
-
LangChain 的未来发展
- 持续致力于 langgraph 的开发(向langgraph迁移),增强代理架构的能力。
- 重新审视 vectorstores 抽象,以提高可用性和可靠性。
- 改进文档和版本化文档。
- 计划在 7 月至 9 月之间发布 0.3.0 版本,全面支持 Pydantic 2,并停止对 Pydantic 1 的支持。
注意:自 0.2.0 版本起,langchain 不再依赖 langchain-community。langchain-community 将依赖于 langchain-core 和 langchain。
- 具体变化
从 0.2.0 版开始,langchain 必须与集成无关。这意味着,langchain 中的代码默认情况下不应实例化任何特定的聊天模型、llms、嵌入模型、vectorstores 等;相反,用户需要明确指定这些模型。
以下这些API从0.2版本起要显式的传递LLM
langchain.agents.agent_toolkits.vectorstore.toolkit.VectorStoreToolkit
langchain.agents.agent_toolkits.vectorstore.toolkit.VectorStoreRouterToolkit
langchain.chains.openai_functions.get_openapi_chain
langchain.chains.router.MultiRetrievalQAChain.from_retrievers
langchain.indexes.VectorStoreIndexWrapper.query
langchain.indexes.VectorStoreIndexWrapper.query_with_sources
langchain.indexes.VectorStoreIndexWrapper.aquery_with_sources
langchain.chains.flare.FlareChain
langchain.indexes.VectostoreIndexCreator以下代码已被移除
langchain.natbot.NatBotChain.from_default removed in favor of the from_llm class method.-
@tool修饰符:
@tool
def my_tool(x: str) -> str:
"""Some description."""
return "something"print(my_tool.description)
0.2前运行结果会是:my_tool: (x: str) -> str - Some description. 0.2后的运行结果是:Some description.
更多内容见langchain 0.2 :https://python.langchain.com/v0.2/docs/versions/v0_2/deprecations/
LangChain 简化了 LLM 应用程序生命周期的每个阶段:
开发:使用 LangChain 的开源构建块、组件和第三方集成构建您的应用程序。使用LangGraph构建具有一流流媒体和人机交互支持的状态代理。生产化:使用LangSmith检查、监控和评估您的链,以便您可以不断优化和自信地部署。部署:使用LangGraph Cloud将您的 LangGraph 应用程序转变为可用于生产的 API 和助手。
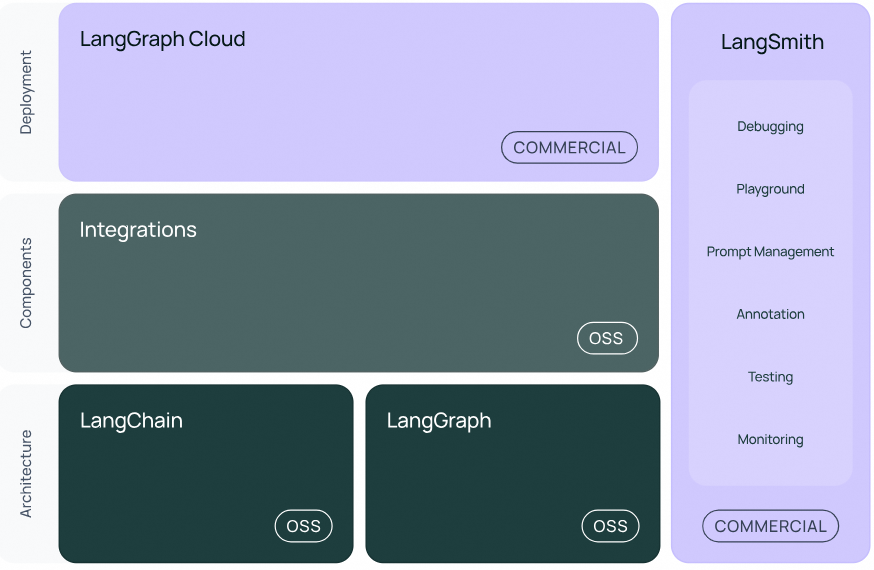
该框架目前将自身定位为覆盖LLM应用开发全生命周期的框架。包含开发、部署、工程化三个大方向,在这三个大方向,都有专门的产品或产品集:
开发阶段:主要是python和javascript两种语言的SDK,配合开放的社区组件模板,来便捷的实现跨LLM的APP开发工程化或产品化阶段:主要是以LangSmith为代表的产品,集监控、playground、评估等功能于一身部署阶段:主要是LangServer产品,基于fastapi封装的LLM API服务器。
基本的方向是开发员的SDK和组件来壮大社区,然后通过类似LangSmith等工具产品实现商业化。
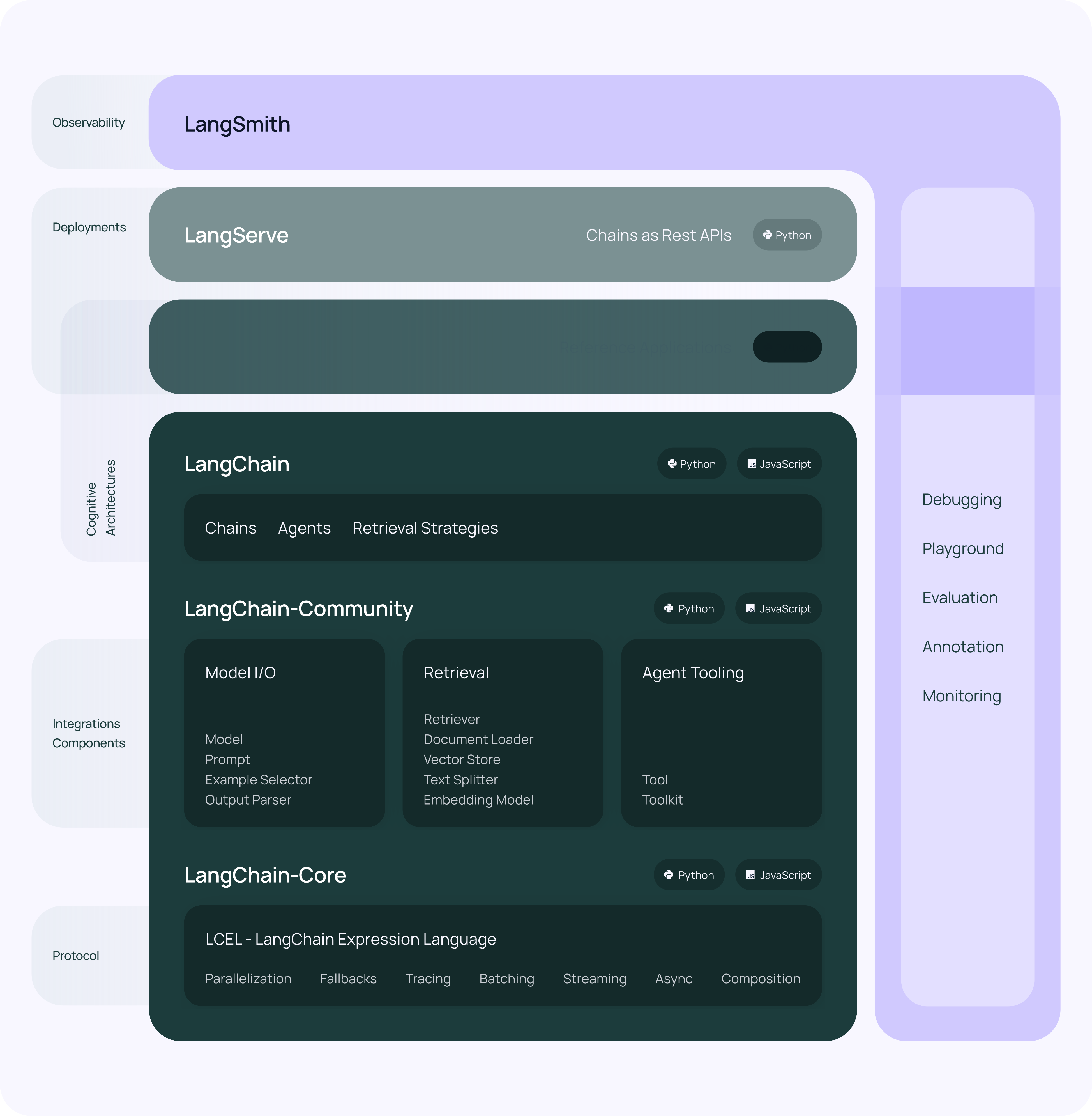
langchain-core:主要的SDK依赖包,包括基本的抽象结构和LECL脚本语言。langchain-community:第三方集成。- 合作伙伴包(例如langchain-openai、langchain-anthropic等):一些集成被进一步拆分成自己的仅依赖于的轻量级包langchain-core。
langchain:构成应用程序认知架构的链、代理和检索策略(剥离后只有Chains、Agents、以及构成应用程序认知结构的检索策略)。LangGraph:通过将步骤建模为图中的边和节点,使用 LLM 构建强大且有状态的多参与者应用程序。与 LangChain 顺利集成,但可以在没有 LangChain 的情况下使用。【多Agents框架的实现】LangServe:将 LangChain 链部署为 REST API。LangSmith:功能很多包括提示词模板聚合、监控、调试、评测LLM等等,部分功能会收费。
2. 如何迁移到0.2.x版本
- 安装 0.2.x 版本的 langchain-core、langchain,并将可能使用的其他软件包升级到最新版本。(例如,langgraph、langchain-community、langchain-openai 等)。
- 验证代码是否能在新软件包中正常运行(例如,单元测试通过)。
- 安装最新版本的 langchain-cli,并使用该工具将代码中使用的旧导入替换为新导入。
- 手动解决所有剩余的弃用警告。
- 重新运行单元测试。
- 如果正在使用 astream_events,请查看如何迁移到 astream events v2。
- 如何迁移到0.2.x - 升级依赖包
0.2版本对依赖包做了较大调整,详细参照下表:

-
如何迁移到0.2.x - 使用langchain-cli工具
安装该工具pip install langchain-cli
langchain-cli --version # <-- 确保版本至少为 0.0.22
注意,该工具并不完美,在迁移前你应该备份好你的代码。使用的时候您需要运行两次迁移脚本,因为每次运行只能应用一次导入替换。
#例如,您的代码仍然使用
from langchain.chat_models import ChatOpenAI
#第一次运行后,您将得到:
from langchain_community.chat_models import ChatOpenAI
#第二次运行后,您将得到:
from langchain_openai import ChatOpenAIang-cli的其他命令:
#See help menu
langchain-cli migrate --help
#Preview Changes without applying
langchain-cli migrate --diff [path to code]
#run on code including ipython notebooks
#Apply all import updates except for updates from langchain to langchain-core
langchain-cli migrate --disable langchain_to_core --include-ipynb [path to code]3.基于runnables的流式事件支持
大模型在推理时由于要对下一个字的概率进行计算,所以无论多么牛逼的LLM,在推理的时候或多或少都有一些延迟,而这种延迟在类似Chat的场景里,体验非常不好,除了在LLM上下功夫外,提升最明显的就是从用户体验着手,采用类似流式输出的方式,加快反馈提升用户体验,让用户感觉快乐很多,这也是为什么chatG{T会采用这种类似打字机效果的原因。流式在langchain前面版本已经支持不少,在0.2版本里,主要是增加了事件支持,方便开发者对流可以有更细致的操作颗粒度。
- 流的主要接口
我们知道从0.1大版本开始,langchain就支持所谓的runnable协议,为大部分组件都添加了一些交互接口,其中流的接口有:- 同步方式的stream以及异步的astream:他们会以流的方式得到chain的最终结果。
- 异步方式的astream_event和astream_log:这两个都可以获得到流的中间步骤和最终结果。
3.1 直接使用大模型输出流
python
from langchain_community.chat_models import ChatZhipuAI
import os
os.environ["ZHIPUAI_API_KEY"] = "zhipuai_api_key"
model = ChatZhipuAI(
model="glm-4",
temperature=0,
streaming=True,
)
chunks = []
async for chunk in model.astream("你好关于降本增效你都知道什么?"): #采用异步比同步输出更快
chunks.append(chunk)
print(chunk.content, end="|", flush=True)- 结果
python
#异步输出
降|本|增效|是企业|为了|提高|市场|竞争力|、|优化|资源配置|、|提升|经济效益|而|采取|的一系列|措施|。|其|核心|是|降低|成本|、|提高|效率|,|具体|来说|,|包括|以下几个方面|:
1|.| **|成本|控制|**|:|企业|通过|精细|化管理|,|严格控制|生产|成本|,|减少|不必要的|开支|。|比如|,|优化|供应链|管理|,|降低|原材料|采购|成本|;|提高|能源|利用|效率|,|减少|能源|消耗|;|精|简|人员|结构|,|提高|劳动|生产|率|等|。
2|.| **|技术创新|与|研发|**|:|通过|技术创新|和|研发|,|改进|生产工艺|,|提高|产品质量|,|降低|单位|产品|成本|。|同时|,|新技术|、|新|产品的|开发|也能|提升|企业的|市场竞争|力和|盈利|能力|。
3|.| **|管理|优化|**|:|优化|企业|内部|管理|流程|,|提高|决策|效率|和管理|效率|。|如|实施|信息化|管理|,|提高|数据处理|速度|和|准确性|,|减少|人为|错误|和|重复|劳动|。
4|.| **|市场|与|销售|策略|调整|**|:|根据|市场|变化|调整|销售|策略|,|优化|产品|结构|,|提高|高|附加值|产品的|比重|,|增强|市场|适应|能力和|盈利|能力|。
5|.| **|资金|运作|**|:|合理|规划和|优化|企业|融资|结构|,|降低|财务|成本|。|比如|,|通过|发行|低|利率|债券|等方式|筹集|资金|,|减少|利息|支出|。
6|.| **|规模|效应|**|:|扩大|生产|规模|,|实现|规模|经济|,|降低|单位|成本|。
以下|是根据|提供的|参考|信息|,|对|几|家企业|降|本|增效|措施|的具体|案例分析|:
-| **|山东|钢铁|**|:|面临|行业|困境|,|山东|钢铁|通过|增持|公司|股份|增强|市场|信心|,|同时|实施|包括|提高|增量|、|降低|费用|、|加强|采购|优化|销售等|在内的|多项|措施|,|并通过|财务|手段|降低|贷款|利率|,|成功|发行|低成本|融资|券|。
-| **|银|轮|股份|**|:|公司|通过|持续推进|降|本|增效|措施|,|提升|运营|效率|,|改善|海外|工厂|运营|,|提升|盈利|能力|,|并通过|加大|研发|投入|,|强化|技术|产品|优势|。
-| **|山|鹰|国际|**|:|通过|提升|产能|利用率|,|持续|推动|降|本|增效|和|精益|生产|,|优化|运营|资金|,|降低|管|销|费用|。
-| **|野|马|电池|**|:|公司|优化|营销|网络|布局|,|加强|销售|推广|,|同时|推进|精细|化管理|,|全面|降|本|增效|,|提高|运营|效率|。
-| **|丽|尚|国|潮|**|:|在|消费|复苏|背景下|,|公司|通过|优化|商业模式|,|实施|精细化|运营|管理|,|提升|业务|效率和|盈利|能力|。
-| **|白银|有色|**|:|通过|强化|内部|管理|,|多|措|并举|降|本|增效|、|开源|节|流|,|提升|经济效益|,|改善|经营|状况|。
这些|案例|表明|,|降|本|增效|是|企业在|各种|市场|环境下|提升|竞争力|、|保证|可持续发展|的重要|途径|。||3.2 Chain中的流输出
python
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
import os
os.environ["ZHIPUAI_API_KEY"] = "xxx"
model = ChatZhipuAI(
model="glm-4",
temperature=0,
streaming=True,
)
prompt = ChatPromptTemplate.from_template("告诉我一个关于{topic}的笑话")
parser = StrOutputParser()
chain = prompt | model | parser
async for chunk in chain.astream({"topic": "裁员"}):
print(chunk, end="|", flush=True)
python
有一天|,|公司|老板|走进|办公室|,|对所有|员工|说|:"|我|有个|好消息|和一个|坏|消息|要|告诉大家|。"|员工|们|紧张|地|等待着|,|老板|接着|说|:"|坏|消息|是|,|我们|公司|要|裁员|了|。"|大家|一片|沉默|,|这时|老板|又|笑着说|:"|好消息|是|,|我们|公司|要|裁员|了|,|你们|终于|可以|摆脱|这些|无聊|的工作|,|去|追求|自己的|梦想|了|!"|员工|们|面|面|相|觑|,|其中|一个人|小|声|嘀|咕|:"|那|我还是|先|回去|做|一下|简历|吧|。"|这个|笑话|虽然|有些|黑色|幽默|,|但也|反映了|裁员|这个|话题|在|职场|中的|敏感性|。|希望大家|在|现实生活中|都能|顺利|度过|各种|职场|挑战|。||3.3 高级使用:在chain中使用流式输出json结构
很多时候的实际场景是,我们希望接口输出的是一个json结构,这样在前端应用层面会比较灵活,但是如果是流式输出,很可能因为字符结构没有输出结束会导致json报错,这种情况可以这样处理:
python
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.output_parsers import JsonOutputParser
import os
os.environ[
"ZHIPUAI_API_KEY"] = "key"
model = ChatZhipuAI(
model="glm-4",
temperature=0,
streaming=True,
)
#异步方法
import asyncio
async def my_async_function():
chain = (model | JsonOutputParser())
async for text in chain.astream("输出 JSON 格式的法国、西班牙和日本国家及其人口列表。 "
'使用一个外键为 "countries "的 dict,其中包含一个国家列表。'
"每个国家都应有 `name` 和 `population`键"):
print(text, flush=True)
async def main():
await my_async_function()
asyncio.run(main()) #In plain Python
#await main() # In jupyter jupyter 已经运行了loop,无需自己激活,采用await()调用即可- 结果
python
{}
{'countries': []}
{'countries': [{}]}
{'countries': [{'name': ''}]}
{'countries': [{'name': 'France'}]}
{'countries': [{'name': 'France', 'population': 67}]}
{'countries': [{'name': 'France', 'population': 673}]}
{'countries': [{'name': 'France', 'population': 673900}]}
{'countries': [{'name': 'France', 'population': 67390000}]}
{'countries': [{'name': 'France', 'population': 67390000}, {}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': ''}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain'}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 46}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 467}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 467330}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 46733038}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 46733038}, {}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 46733038}, {'name': ''}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 46733038}, {'name': 'Japan'}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 46733038}, {'name': 'Japan', 'population': 125}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 46733038}, {'name': 'Japan', 'population': 1258}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 46733038}, {'name': 'Japan', 'population': 125880}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 46733038}, {'name': 'Japan', 'population': 125880000}]}看到流的输出总是保持这合法的json结构,从而避免了报错,如果我们期待在这种结构下,可以以流式来取到国家名称该怎么做?是的这里就要在Json输出后,继续处理。
python
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.output_parsers import JsonOutputParser
import os
os.environ[
"ZHIPUAI_API_KEY"] = "9a0"
model = ChatZhipuAI(
model="glm-4",
temperature=0,
streaming=True,
)
#异步方法
import asyncio
#自定义函数用来过滤上一步的输入
async def _extract_country_names_streaming(input_stream):
"""A function that operates on input streams."""
country_names_so_far = set()
async for input in input_stream:
if not isinstance(input, dict):
continue
if "countries" not in input:
continue
countries = input["countries"]
if not isinstance(countries, list):
continue
for country in countries:
name = country.get("name")
if not name:
continue
if name not in country_names_so_far:
yield name
country_names_so_far.add(name)
async def my_async_function():
# 在json输出后,调用自定义函数用来过滤国家这个字段
chain = model | JsonOutputParser() | _extract_country_names_streaming
async for text in chain.astream("输出 JSON 格式的法国、西班牙和日本国家及其人口列表。 "
'使用一个外键为 "countries "的 dict,其中包含一个国家列表。'
"每个国家都应有 `name` 和 `population`键"):
#以|符号分割开字符
print(text, end="|", flush=True)
async def main():
await my_async_function()
asyncio.run(main())
python
Franc| Spain| Japan|3.4 不支持流式的组件处理(检索器)
并不是所有的组件都支持流式输出,比如检索器就不支持,在原生的langchain中,当你给不支持stram的组件调用流接口时,一般不会有打字机效果,而是和使用invoke效果差不多。而当你使用LCEL去调用类似检索器组件的时候,它依然可以搞出来打字机效果,这也是为什么要尽量使用LCEL的原因。我们看个例子:
#安装依赖
pip install faiss-cpu
python
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import OpenAIEmbeddings
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
vectorstore = FAISS.from_texts(
["harrison worked at kensho", "harrison likes spicy food"],
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()
chunks = [chunk for chunk in retriever.stream("where did harrison work?")]
chunks原生的检索器在这种情况下只会返回最终结果,并没有流的效果:
[[Document(page_content='harrison worked at kensho'),
Document(page_content='harrison likes spicy food')]]而使用LCEL调用后,则可以输出中间的过程:
python
retrieval_chain = (
{
"context": retriever.with_config(run_name="Docs"),
"question": RunnablePassthrough(),
}
| prompt
| model
| StrOutputParser()
)
for chunk in retrieval_chain.stream(
"Where did harrison work? " "Write 3 made up sentences about this place."
):
print(chunk, end="|", flush=True)- 全代码【智谱llM+百川词嵌入模型】
python
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.output_parsers import JsonOutputParser
from langchain_community.embeddings import BaichuanTextEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
import os
os.environ[
"ZHIPUAI_API_KEY"] = "7c182nN"
model = ChatZhipuAI(
model="glm-4",
temperature=0,
streaming=True,
)
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
embeddings=BaichuanTextEmbeddings(baichuan_api_key="sk-175510")
vectorstore = FAISS.from_texts(
["harrison worked at kensho", "harrison likes spicy food"],
embedding=embeddings,
)
retriever = vectorstore.as_retriever()
retrieval_chain = (
{
"context": retriever.with_config(run_name="Docs"),
"question": RunnablePassthrough(),
}
| prompt
| model
| StrOutputParser()
)
for chunk in retrieval_chain.stream(
"Where did harrison work? " "Write 3 made up sentences about this place."
):
print(chunk, end="|", flush=True)
python
H|arrison| worked| at| Kens|ho|,| a| cutting|-edge| technology| company| known| for| its| innovative| AI| solutions|.|
1|.| Kens|ho| is| renowned| for| its| vibrant| work| culture|,| where| employees| are| encouraged| to| think| outside| the| box| and| push| the| boundaries| of| technology|.
2|.| The| office| environment| at| Kens|ho| is| dynamic| and| fast|-paced|,| with| a| strong| emphasis| on| collaboration| and| continuous| learning|.
3|.| Kens|ho| is| located| in| a| state|-of|-the|-art| facility|,| boasting| impressive| amenities| and| a| sleek|,| modern| design| that| fost|ers| creativity| and| productivity|.||4. v0.2的核心特性:流中的事件支持
如要使用该特性,你首先要确认自己的langchain_core版本等于0.2
python
import langchain_core
langchain_core.__version__
#'0.2.18'官方给到了一些注意事项:
- 使用流要尽量使用异步方式编程。
- 如果你自定义了函数一定要配置callback。
- 不使用LCEL的话尽量使用.astram来访问LLM。
langchain将流的过程细化,并在每个阶段给了开发者一个事件钩子,每个阶段都可以获取输出结果:

4.1 在chatmodel中使用:
python
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.output_parsers import JsonOutputParser
import os
os.environ[
"ZHIPUAI_API_KEY"] = "7epjHnN"
model = ChatZhipuAI(
model="glm-4",
temperature=0,
streaming=True,
)
#异步方法
import asyncio
async def my_async_function():
events = []
async for event in model.astream_events("hello", version="v2"):
events.append(event)
print(events[:3])
async def main():
await my_async_function()
#asyncio.run(main())
await main()注意:version=v2这个参数表明events事件流依然是一个beta API,后面肯定还有更改,所以商业应用要慎重!该参数只在 langchain-core>=0.2.0作用!
- 结果
python
[{'event': 'on_chat_model_start', 'data': {'input': 'hello'}, 'name': 'ChatZhipuAI', 'tags': [], 'run_id': 'c87b9c20-6dbf-41d3-989a-0b609c0b3fb4', 'metadata': {'ls_model_type': 'chat'}, 'parent_ids': []}, {'event': 'on_chat_model_stream', 'run_id': 'c87b9c20-6dbf-41d3-989a-0b609c0b3fb4', 'name': 'ChatZhipuAI', 'tags': [], 'metadata': {'ls_model_type': 'chat'}, 'data': {'chunk': AIMessageChunk(content='Hello', id='run-c87b9c20-6dbf-41d3-989a-0b609c0b3fb4')}, 'parent_ids': []}, {'event': 'on_chat_model_stream', 'run_id': 'c87b9c20-6dbf-41d3-989a-0b609c0b3fb4', 'name': 'ChatZhipuAI', 'tags': [], 'metadata': {'ls_model_type': 'chat'}, 'data': {'chunk': AIMessageChunk(content=' 👋!', id='run-c87b9c20-6dbf-41d3-989a-0b609c0b3fb4')}, 'parent_ids': []}]4.2 在Chain中的使用:
python
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.output_parsers import JsonOutputParser
import os
os.environ[
"ZHIPUAI_API_KEY"] = "7cjHnN"
model = ChatZhipuAI(
model="glm-4",
temperature=0,
streaming=True,
)
#异步方法
import asyncio
async def my_async_function():
chain = (model | JsonOutputParser())
num_events = 0
async for event in chain.astream_events(
"输出 JSON 格式的法国、西班牙和日本国家及其人口列表。 "
'使用一个外键为 "countries "的 dict,其中包含一个国家列表。'
"每个国家都应有 `name` 和 `population`键",
version="v2",
):
#筛选event
kind = event["event"]
if kind == "on_chat_model_stream":
print(
f"Chat model chunk: {repr(event['data']['chunk'].content)}",
flush=True,
)
if kind == "on_parser_stream":
print(f"Parser chunk: {event['data']['chunk']}", flush=True)
num_events += 1
if num_events > 30:
# Truncate the output
print("...")
break
async def main():
await my_async_function()
#asyncio.run(main())
await main()Chat model chunk: '以下是'
Chat model chunk: '按照'
Chat model chunk: '您'
Chat model chunk: '的要求'
Chat model chunk: ','
Chat model chunk: '以'
Chat model chunk: ' JSON'
Chat model chunk: ' 格'
Chat model chunk: '式'
Chat model chunk: '表示'
Chat model chunk: '法国'
Chat model chunk: '、'
Chat model chunk: '西班牙'
Chat model chunk: '和'
Chat model chunk: '日本'
Chat model chunk: '国家'
Chat model chunk: '及其'
Chat model chunk: '人口'
Chat model chunk: '的一个'
Chat model chunk: '示例'
Chat model chunk: ':\n\n'
Chat model chunk: 'json'
Chat model chunk: '\n{\n '
Parser chunk: {}
Chat model chunk: ' "'
Chat model chunk: 'countries'
Chat model chunk: ':'
...5.事件过滤
结合事件以及配置参数,可以很方便的找出你想要的阶段数据
通过定义名字实现事件的筛选,后续想要使用的块
python
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.output_parsers import JsonOutputParser
import os
os.environ[
"ZHIPUAI_API_KEY"] = "key"
model = ChatZhipuAI(
model="glm-4",
temperature=0,
streaming=True,
)
#异步方法
import asyncio
async def my_async_function():
chain = model.with_config({"run_name": "model"}) | JsonOutputParser().with_config(
{"run_name": "my_parser"}
)
num_events = 0
async for event in chain.astream_events(
"输出 JSON 格式的法国、西班牙和日本国家及其人口列表。 "
'使用一个外键为 "countries "的 dict,其中包含一个国家列表。'
"每个国家都应有 `name` 和 `population`键",
version="v2",
include_names=["my_parser"],
):
print(event)
max_events += 1
if max_events > 10:
# Truncate output
print("...")
break
async def main():
await my_async_function()
asyncio.run(main())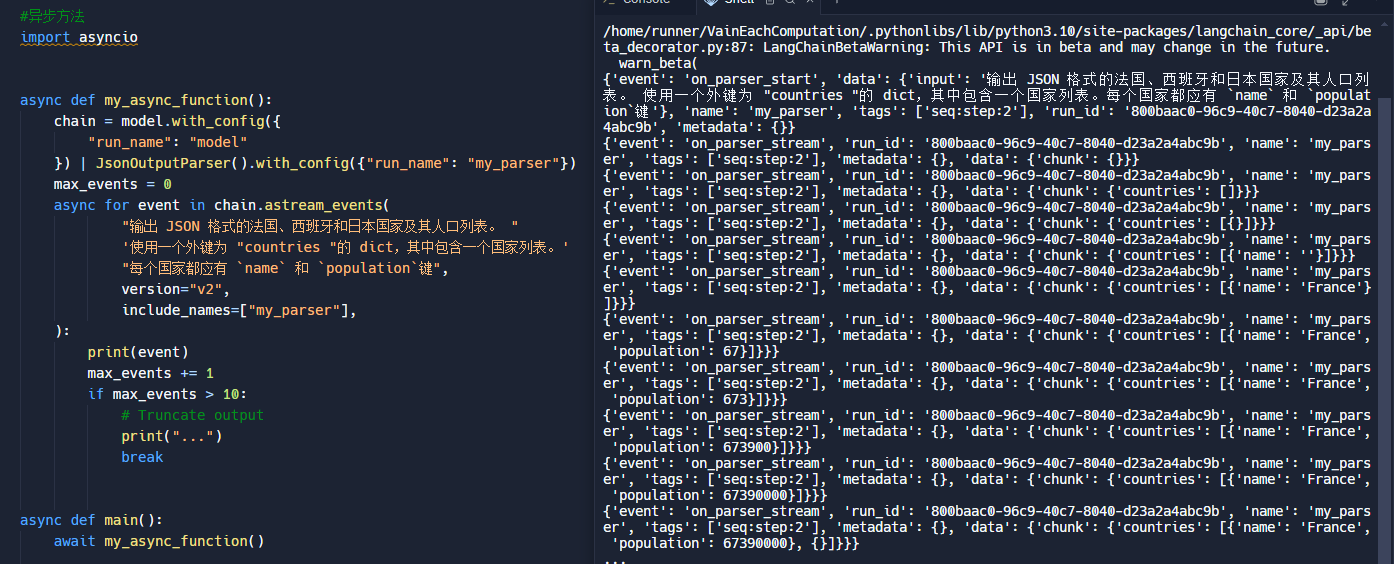
6.回调传播
在工具中使用调用可运行项,则需要将回调传播到可运行项;否则,不会生成任何流事件。
python
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.output_parsers import JsonOutputParser
import os
os.environ[
"ZHIPUAI_API_KEY"] = "key"
model = ChatZhipuAI(
model="glm-4",
temperature=0,
streaming=True,
)
from langchain_core.runnables import RunnableLambda
from langchain_core.tools import tool
#反转单词
def reverse_word(word: str):
return word[::-1]
reverse_word = RunnableLambda(reverse_word)
@tool
def correct_tool(word: str, callbacks):
"""A tool that correctly propagates callbacks."""
return reverse_word.invoke(word, {"callbacks": callbacks})
async for event in correct_tool.astream_events("hello", version="v2"):
print(event)
python
{'event': 'on_tool_start', 'data': {'input': 'hello'}, 'name': 'correct_tool', 'tags': [], 'run_id': '97cd4122-e699-4a54-8370-699ed9e6cdb4', 'metadata': {}, 'parent_ids': []}
{'event': 'on_chain_start', 'data': {'input': 'hello'}, 'name': 'reverse_word', 'tags': [], 'run_id': '9e6635fe-879f-4b74-9c23-8de768b49a39', 'metadata': {}, 'parent_ids': ['97cd4122-e699-4a54-8370-699ed9e6cdb4']}
{'event': 'on_chain_end', 'data': {'output': 'olleh', 'input': 'hello'}, 'run_id': '9e6635fe-879f-4b74-9c23-8de768b49a39', 'name': 'reverse_word', 'tags': [], 'metadata': {}, 'parent_ids': ['97cd4122-e699-4a54-8370-699ed9e6cdb4']}
{'event': 'on_tool_end', 'data': {'output': 'olleh'}, 'run_id': '97cd4122-e699-4a54-8370-699ed9e6cdb4', 'name': 'correct_tool', 'tags': [], 'metadata': {}, 'parent_ids': []}更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。