正如承诺的那样,这是最近我遇到的最有趣的想法之一的第二部分。如果你错过了,请务必观看本系列的第一部分 -神经科学家对改进神经网络的看法 - 我们讨论了双边性的生物学基础以及我们大脑的不对称性质如何带来更高的性能。
在这篇文章中,我将介绍一些人工智能研究,这些研究对这个想法有很大的希望。如果你们中有人正在寻找下一篇研究论文/项目 - 这可能是一个不错的选择。无论我的意见如何 - 我相信解决神经网络中的双边性将真正改变人工智能领域的游戏规则。
NSDT工具推荐 : Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、为什么双边性会改变现状
在我开始分析研究之前,我想花点时间谈谈我为什么如此重视双边性(bilaterality)。当然,它可能适用于生物系统,但我们希望通过为我们的 ANN 实施类似的想法来实现什么?
为了回答这个问题,让我们退一步来看看神经网络的架构对学习结果有多大的影响。简单地说,每个模型/架构决策都会对我们的系统施加一定的归纳偏差。通过选择实现某个激活函数、模型配置等,你隐式地选择优先考虑数据/域的一个方面而不是另一个方面。因此,直观地说,不同的架构设置会导致不同的结果,这是有道理的。
我可以在这里结束这一部分 - 但那有什么乐趣呢?我不得不阅读了不少论文,如果我必须阅读,你也必须阅读 ❤。所以让我们回顾一下展示架构决策的研究,以及它们如何影响模型对数据的内部表示。
让我们从很小的地方开始 - 当谈到视觉转换器与 CNN 时,我们看到它们的不同操作导致输入数据的客观不同表示。注意力机制允许 Transformers 保持"图像的全局视图",从而使它们能够提取与 ConvNets 非常不同的特征。请记住,CNN 使用内核来提取特征,这限制了它们找到局部特征的方法。注意力允许 Transformers 绕过这一点。
在图像分类基准上分析 ViTs 和 CNN 的内部表示结构,我们发现两种架构之间存在显着差异,例如 ViT 在所有层上具有更统一的表示。我们探索了这些差异是如何产生的,发现了自我注意力所起的关键作用,它能够实现全局信息的早期聚合,而 ViT 残差连接则可以将特征从较低层传播到较高层。
上面的引文摘自非常有趣的《视觉变换器是否像卷积神经网络那样看?》。它很有趣,我稍后会对此论文进行分析。重要的是下面的引文,也来自这篇论文。
...证明访问更多全局信息也会导致与 ResNet 较低层的局部接受场计算出的特征在数量上不同的特征
这超出了图像任务的范围。不久前,我们试图回答 Transformers 是否适用于时间序列预测任务(哈哈,不)。Transformer 架构的缺陷之一是它们的注意力机制,它在数据排序中引入了置换不变性(不利于 TSF)。
更重要的是,Transformer 架构的主要工作能力来自其多头自注意力机制,它具有提取长序列中成对元素之间的语义相关性的卓越能力(例如,文本中的单词或图像中的 2D 块),并且该过程是置换不变的,即无论顺序如何。然而,对于时间序列分析,我们主要感兴趣的是建模连续点集之间的时间动态,其中顺序本身通常起着最关键的作用。
对于那些特别有自虐倾向的人来说,《论深度学习模型的对称性及其内部表征》这篇论文是一篇关于这一概念的好文章。数学是精神病学的,但结论相对简单------
我们的研究表明,网络的对称性会传播到该网络的数据表示的对称性中
希望这足以让你相信架构可以直接影响模型感知数据的方式。因此,像双边性这样强大的想法值得探索。通过将某种互补风格的网络集成到同一个网络中,我们可能能够创建一种超越任何一种结构限制的架构。
说完这些,现在让我们来谈谈本期的主角------双边性论文以及我们如何扩展它。
我一直想重读雷·库兹韦尔 (Ray Kurzweil) 的《如何创造思维》一书,从中我学到的一点就是统计学在人工智能中的作用。如果每个连续的结果都会覆盖过去的结果,我可以想象偏见的结论会在几代人中积累多少。应用双边架构来保留先前知识的权重似乎是一种很好的对冲方法。
上面是对本文第 1 部分的评论。感谢 Daniel Kurland 的精彩分享。
2、如何将双边性应用于神经网络
《双侧大脑深度学习与半球特化》的作者在将双边性应用于神经网络方面做了大量工作。让我们来看看他们的方法和结果。
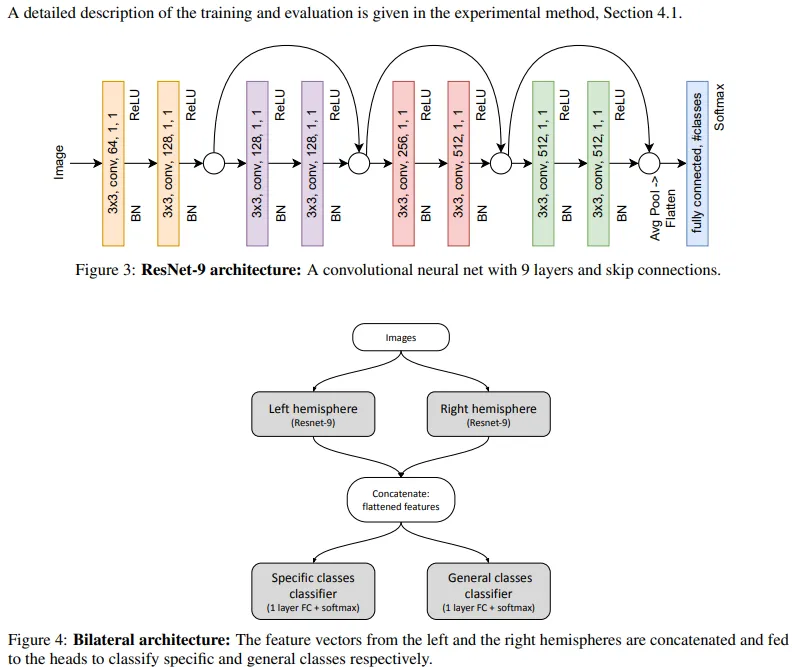
首先要理解的是他们的设置。所提出的架构基于 ResNet-9 模型,该模型因其在分类和简单性方面的良好性能而被选中。为了模拟两个半球,我们使用了两个不同的 ResNet 模型(我知道这很令人震惊)。为了进行实验,我们比较了以下模型(第一个是双边模型,其余的是基线)-
- 具有特化的双边性- 我们用不同的目标训练模型,"左半球在特定类别上进行训练,右半球在一般类别上进行训练"。这是什么意思?一般类别是:海洋生物,而特定类别是:企鹅、海豹、鲨鱼等。这类似于我们的大脑,右半球模拟一般性,左半球更具体。
- 无专业化的双边性------"为了更好地理解专业化的作用,我们将双边模型与没有专业化的等效网络进行了比较。我们训练了整个网络(两个半球和头部),而没有首先明确地在各个半球中诱导专业化。"
- 单腔网络------双边性使模型拥有更多的计算资源。为了解释这一点,作者还使用了两个更大的单一模型,其中两个头部分别用于一般和特定类别。更具体地说,他们使用了"预定义的 18 层和 34 层 ResNet 架构。18 层网络的可训练参数数量与双边网络大致相同,而 34 层网络的可训练参数数量大约是其两倍。"
- 集成模型------你可能知道,集成模型是机器学习中性能的秘诀。而这种双边模型是一种集成。因此,与其他集成进行比较也很重要,以便更清楚地了解专业化与其他因素的影响。为了理解差异化专业化和传统集成之间的区别,我们比较了两个不同的模型,一个是 2 模型集成,一个是 5 模型集成。为了构建集成,我们使用了一种常见的方法,即训练 10 个单腔 ResNet-9 模型,并选择前 k 个(k 分别为 2 和 5)。集成在训练和推理中的输出是模型的平均输出。
这些模型必须相互竞争才能确定谁是王者。对于喜欢视觉效果的人来说,可以在下面看到一般架构。
我喜欢他们模拟专业化的方法,因为它相当简单和优雅。未来的扩展可能是使用不同的架构,一个具有更密集的局部连接,另一个具有更宽的连接(可能使用跳过连接)。要真正改变,我们需要调整梯度下降的单向性,朝着在多个方向上调整权重的协议发展。这并非易事,但它将是未来探索的绝佳途径。
为了查看从两个专门模型中提取的特征之间的差异,作者使用了两种技术。首先,他们利用梯度相机(Grad-Cam)可视化。我们知道双侧网络和各个半球利用卷积层的编码特征来预测类标签。为了了解提取的特征如何有助于分类,我们使用 Grad-Cam 库可视化了模型预测类别时卷积层上的平均梯度流。梯度热图突出显示了两个半球和整个网络(两个头部的平均值)的焦点区域。你可以在下面看到 grad-cam 可视化效果。

这是通过计算相同标签图像特征的余弦相似度得分来补充的。它们应该具有相似的特征,因此测量网络不同部分的特征相似度应该很有启发性。以下是特征的可视化-

图 10:场景 1 的余弦相似度分布:双边网络是正确的,左半球和右半球是错误的。许多对(相同标签)在左右半球具有不同的(值更接近 0)特征,这可以从靠近原点的点的密度中看出。连接的特征也不相似,但双边网络提高了许多点的相似度。每个点都是一对具有相同标签的图像。x 轴表示左半球的相似度,y 轴表示右半球的相似度。颜色表示组合表示中的相似度。此外,左半球和右半球的单变量边际分布以双变量分布上方和侧面的直方图显示。
有了这些设置,让我们进入正题。这种架构与竞争对手相比表现如何?这就是事情变得令人兴奋的地方。
Grad-Cam 图像显示,左半球提取的局部特征比右半球多。不同的学习目标使它们能够捕捉环境的不同方面。总体而言,特征集大于一个具有一个目标的网络。有趣的是,即使左半球明确地针对特定的类别标签进行训练,它提取的特征对一般类别也很有帮助。右半球的情况正好相反......
总之,专业化创造了更高的特征多样性。网络主管以任务相关的方式有选择地对左半球和右半球实施一种加权注意力,从而改善整体类别预测。
为什么双腔结构有帮助?
3、专业化和双边性真的能提高神经网络的性能吗?
简而言之 - 是的。看看专业化架构与竞争对手的比较。一定要控制好你的荷尔蒙,因为这些结果看起来真的很漂亮 -

唯一具有可比性能的竞争对手是 5 模型组合 - 但成本要高得多。

我非常希望看到这如何扩展到对抗性学习和检测等相关任务中。也许这将是后续论文的一部分。鉴于这些结果,我认为我们有一个相当有力的概念证明。
最后,让我们谈谈可以扩展这个想法的一些方法。
4、未来的双边性
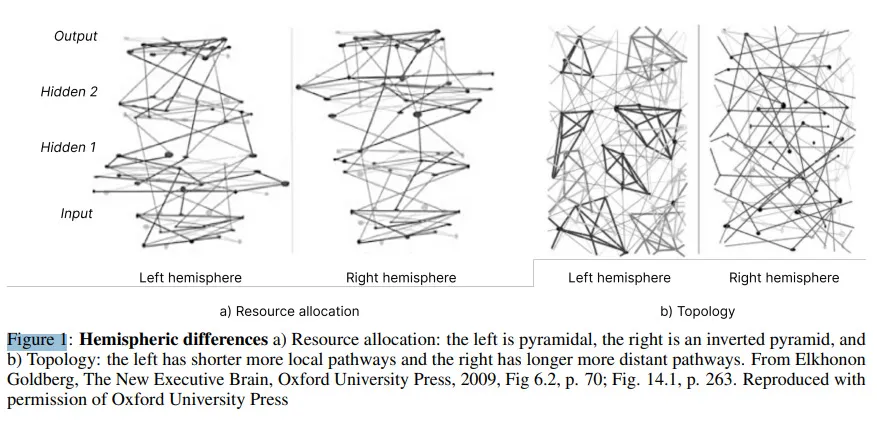
如前所述,未来探索最有希望的途径之一是创建一个更细致入微的权重更新机制,反映我们的神经元和连接一起激发的更复杂方式。作者还提出了几项极好的建议(基于神经科学)------"复制循环连接、半球之间更复杂的生物启发相互作用、模仿半球之间已知的基质差异(如拓扑差异)、资源分配(见图 1)和在无监督的情况下诱导专业化的实验。"
作者还提到了如何利用这种专业化来开发物理机器人,因为它可能与运动技能有关。右半球可以是一个通才,可以在初学者时执行不熟悉的任务,而左半球则随着时间的推移成为专家。代理将能够接受新任务,而不会对它们感到无能为力。目前,持续强化学习领域并不专注于避免表现不佳,而是最大限度地提高最佳表现。然而,在现实生活中,代理必须避免自己和周围人的死亡和严重伤害(也适用于物理机器人和虚拟人工智能代理)。
最后,双边主义融入更多架构将是一件令人着迷的事情,看看这个想法如何很好地扩展到不同的挑战和领域。
原文链接: